MySQLの高可用性を実現するための最も一般的な方法の1つは、レプリケーションです。レプリケーションは何年も前から存在しており、GTIDの導入によりはるかに安定しました。ただし、これらの改善があっても、さまざまな理由でレプリケーションプロセスが中断する可能性があります。たとえば、書き込みがスレーブに直接送信されたためにマスターとスレーブが同期していない場合です。レプリケーションの問題をどのようにトラブルシューティングし、どのように修正しますか?
このブログ投稿では、レプリケーションに関する一般的な問題のいくつかと、ClusterControlを使用してそれらを修正する方法について説明します。最初のものから始めましょう。
ほとんどのMySQLDBAは通常、この種の問題をキャリアの中で少なくとも1回は見ます。さまざまな理由で、スレーブが破損したり、マスターとの同期が停止したりする可能性があります。これが発生した場合、トラブルシューティングを開始するために最初に行うことは、メッセージのエラーログを確認することです。ほとんどの場合、エラーメッセージは、エラーログで、またはSHOWSLAVESTATUSクエリを実行することで簡単に追跡できます。
SHOWSTATUSSLAVEの次の例を見てみましょう。
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0バイナリログからデータを読み取るときに、エラーがマスターから致命的なエラー1236を取得したことに関連していることがはっきりとわかります。'どのbinlogファイルでもスレーブから要求されたGTID状態が見つかりませんでした。おそらく、スレーブの状態が古すぎて、必要なbinlogファイルが削除されています。つまり、エラーが本質的に示しているのは、データに不整合があり、必要なバイナリログファイルがすでに削除されているということです。
これは、レプリケーションプロセスが機能しなくなる良い例の1つです。 SHOW SLAVE STATUSの他に、ClusterControlのクラスターの「Overview」タブでステータスを追跡することもできます。では、ClusterControlでこれを修正するにはどうすればよいですか?試すには2つのオプションがあります:
-
「ノードアクション」からスレーブを再起動してみてください
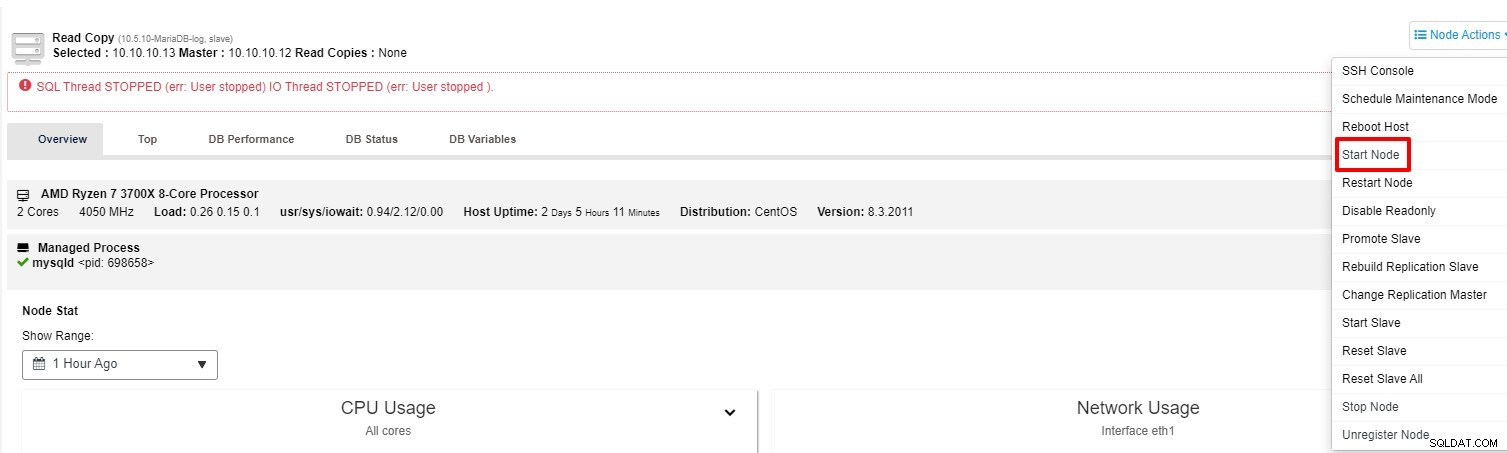
-
スレーブがまだ機能していない場合は、「レプリケーションスレーブの再構築」ジョブを実行できます。 「ノードアクション」から
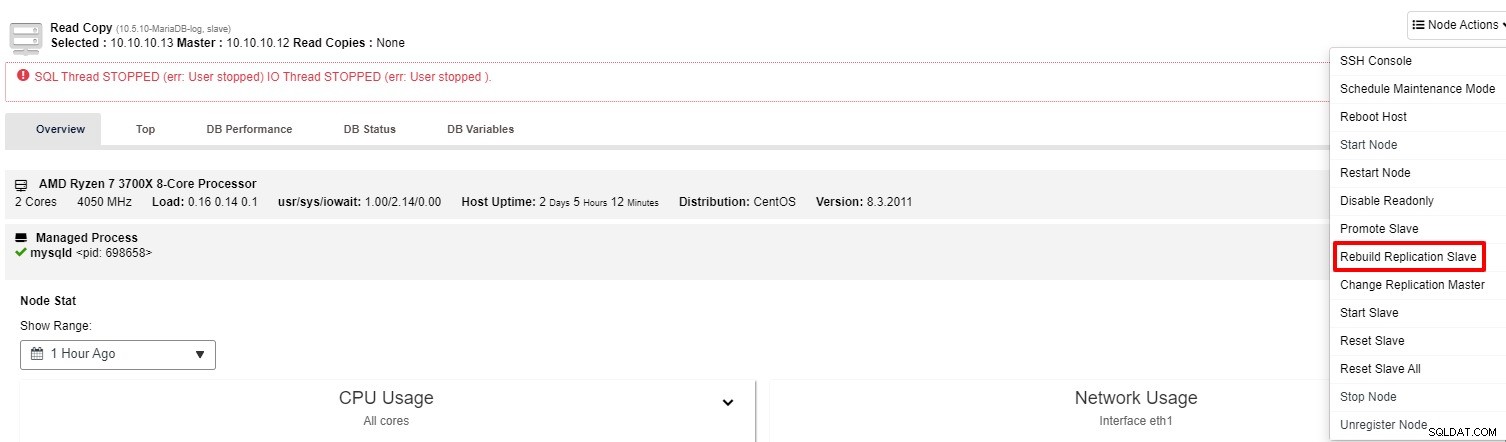
ほとんどの場合、2番目のオプションで問題が解決します。 ClusterControlはマスターのバックアップを取り、データを復元することによって壊れたスレーブを再構築します。データが復元されると、スレーブはマスターに接続され、追いつくことができます。
以下に示すように、スレーブを再構築する手動の方法も複数あります。詳細については、このリンクを参照することもできます。
-
Mysqldumpを使用して一貫性のないMySQLスレーブを再構築する
-
Mydumperを使用して一貫性のないMySQLスレーブを再構築する
-
スナップショットを使用して一貫性のないMySQLスレーブを再構築する
-
XtrabackupまたはMariabackupを使用して一貫性のないMySQLスレーブを再構築する
時間の経過とともに、安定性とセキュリティを維持するために、OSまたはデータベースにパッチを適用またはアップグレードする必要があります。特にメジャーアップグレードのダウンタイムを最小限に抑えるためのベストプラクティスの1つは、特定のノードでアップグレードが正常に実行された後、スレーブの1つをマスターに昇格させることです。
これを実行することにより、アプリケーションを新しいマスターにポイントすることができ、マスター/スレーブレプリケーションは引き続き機能します。それまでの間、安心して旧マスターのアップグレードを進めることもできます。 ClusterControlを使用すると、レプリケーションがグローバルトランザクションIDベースまたは略してGTIDベースとして構成されている場合にのみ、数回クリックするだけで実行できます。データの損失を防ぐために、古いマスターが正しく動作している場合に備えて、アプリケーションのクエリを停止することをお勧めします。奴隷を昇進させることができるのはこれだけではありません。マスターノードがダウンしている場合は、このアクションを実行することもできます。
ClusterControlがない場合、スレーブを昇格させるためのいくつかの手順があります。各ステップを実行するには、いくつかのクエリも必要です。
-
マスターを手動で削除する
-
マスターになる最も高度なスレーブを選択し、準備します
-
他のスレーブを新しいマスターに再接続します
-
古いマスターをスレーブに変更する
それでも、ClusterControlを使用してスレーブをプロモートする手順は数回クリックするだけです。クラスター>ノード>スレーブノードを選択>以下のスクリーンショットのようにスレーブをプロモートします:
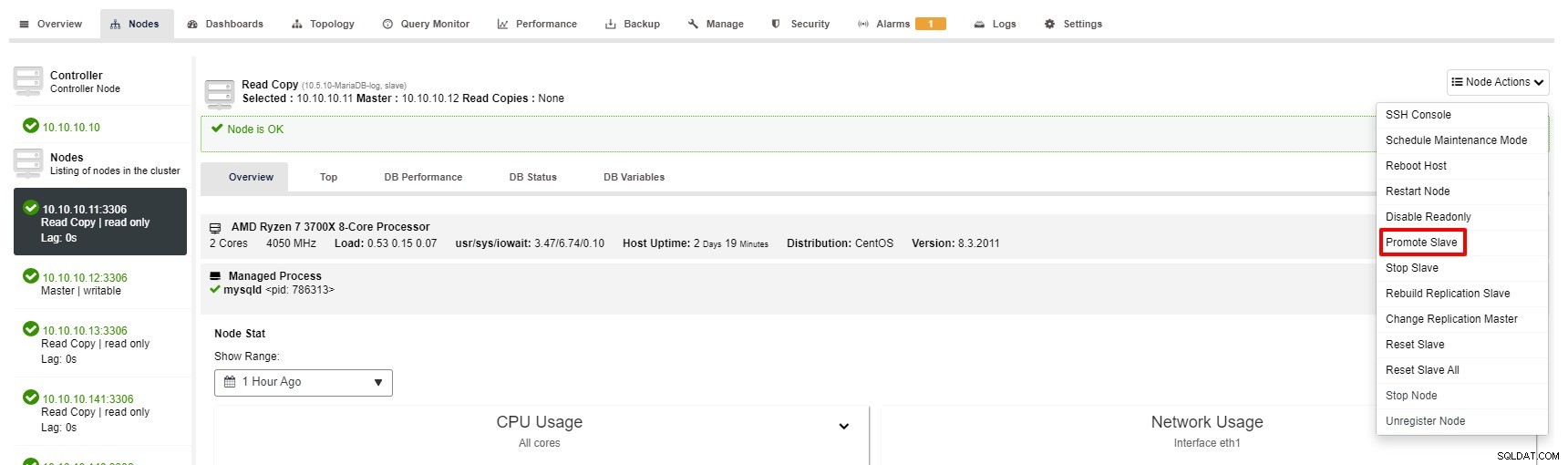
実行するトランザクションが大きいが、データベースがダウンしているとします。どれだけ注意を払っても、これはおそらくレプリケーション設定にとって最も深刻または重大な状況です。これが発生すると、データベースは1回の書き込みを受け入れることができなくなります。これは悪いことです。その上、もちろん、アプリケーションは正しく機能しません。
ClusterControlで使用できる「自動回復」クラスター機能のおかげで、フェイルオーバープロセスを自動化できます。シングルクリックで有効または無効にできます。名前のとおり、必要に応じてクラスタートポロジ全体を表示します。たとえば、マスタースレーブレプリケーションでは、使用可能なスレーブの数に関係なく、常に少なくとも1つのマスターが稼働している必要があります。マスターが使用できない場合、マスターは自動的にスレーブの1つを昇格させます。
上のスクリーンショットでは、「自動回復」がクラスターとノードの両方で有効になっていることがわかります。トポロジでは、現在のマスターIPアドレスが10.10.10.11であることに注意してください。テスト目的でマスターノードを停止するとどうなりますか?
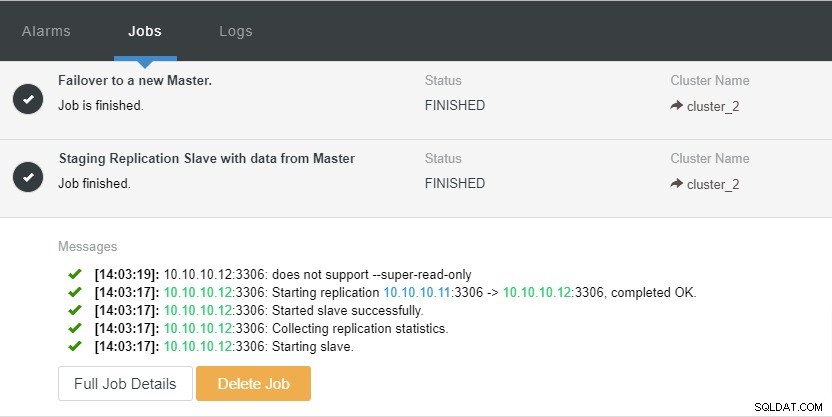
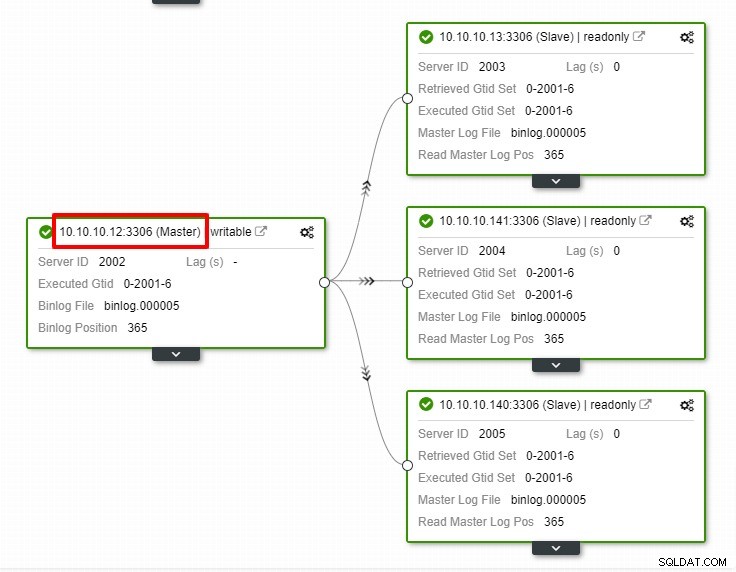
ご覧のとおり、IP10.10.10.12のスレーブノードは自動的にマスターにプロモートされ、レプリケーショントポロジが再構成されます。 ClusterControlは、手動で行うのではなく、もちろん多くの手順を必要としますが、煩わしさを解消することで、レプリケーションのセットアップを維持するのに役立ちます。
レプリケーションで不幸な事態が発生した場合でも、修正は非常に簡単で、ClusterControlを使用する手間が少なくなります。 ClusterControlは、レプリケーションの問題を迅速に回復するのに役立ち、データベースの稼働時間を増やします。