フェイルオーバーは、データベースガバナンスにとって最も重要なデータベースプラクティスの1つです。本番環境で大規模なデータベースを管理する場合だけでなく、システムにアクセスするときはいつでも、特にアプリケーションレベルで、システムを常に利用できるようにする場合にも役立ちます。
フェイルオーバーを実行する前に、データベースインスタンスが特定の要件を満たしている必要があります。実際、これらの要件は高可用性にとって非常に重要です。データベースインスタンスが満たす必要のある要件の1つは、冗長性です。冗長性により、フェイルオーバーを進めることができます。この場合、冗長性は、レプリカ(セカンダリ)ノード、またはスタンバイノードまたはホットスタンバイノードとして機能するレプリカのプールからのフェイルオーバー候補を持つように設定されます。候補は、最も進んだノードまたは最新のノードに基づいて、手動または自動で選択されます。通常、ホットスタンバイレプリカは、データベースがディスクからインデックスを取得するのを防ぐことができるため、ホットスタンバイレプリカが必要になります。これは、ホットスタンバイがデータベースバッファプールにインデックスを設定することが多いためです。
フェイルオーバーは、リカバリプロセスが発生したことを説明するために使用される用語です。リカバリプロセスの前に、これは、プライマリ(またはマスター)データベースノードがクラッシュ後、自然災害後、ハードウェア障害後、またはネットワークパーティション分割が発生した可能性がある場合に発生します。これらは、フェイルオーバーが発生する可能性がある最も一般的なケースです。通常、リカバリプロセスは自動的に進行し、前述のように最も望ましい最新のセカンダリ(レプリカ)を検索します。
フェイルオーバー中のリカバリプロセスは自動ですが、プロセスを自動化する必要がなく、手動プロセスが引き継ぐ必要がある場合があります。多くの場合、データベースのスタック全体を構成するテクノロジーに関連する主な考慮事項は複雑さです。自動フェイルオーバーと手動フェイルオーバーを混在させることもできます。
データベースの管理に関する日常的な考慮事項のほとんどでは、自動フェイルオーバーに関する懸念の大部分は実際には些細なことではありません。問題が発生した場合に備えて、自動フェイルオーバーを実装およびセットアップすると便利なことがよくあります。複雑さをカバーしているので有望に聞こえますが、高度なフェイルオーバーメカニズムがあり、フェイルオーバーソフトウェアまたはテクノロジーのフックとして結び付けられている「pre」イベントと「post」イベントが含まれます。
これらの事前イベントと事後イベントは、フェイルオーバーを最終的に進める前に実行するチェックまたは特定のアクションのいずれかを考え出します。フェイルオーバーが完了した後、フェイルオーバーが最終的に成功することを確認するためのクリーンアップがいくつか行われます。 1。幸い、自動フェイルオーバーだけでなく、スクリプトの前後のフックを適用する機能を備えたツールも利用できます。
このブログでは、ClusterControl(CC)自動フェイルオーバーを使用し、スクリプトの前後のフックの使用方法と、それらがどのクラスターに適用されるかについて説明します。
ClusterControlレプリケーションフェイルオーバー
ClusterControlフェイルオーバーメカニズムは、MySQLバリアント(MySQL / Percona Server / MariaDB)に適用可能な非同期レプリケーションに効率的に適用できます。 PostgreSQL/TimescaleDBクラスターにも適用できます-ClusterControlはストリーミングレプリケーションをサポートしています。 MongoDBおよびGaleraクラスターには、独自のデータベーステクノロジーに組み込まれた自動フェイルオーバー用の独自のメカニズムがあります。 ClusterControlがデータベースの自動リカバリとフェイルオーバーを実行する方法の詳細をご覧ください。
ClusterControlフェイルオーバーは、ノードとクラスターのリカバリー(自動リカバリーが有効になっている)でない限り機能しません。つまり、これらのボタンは緑色である必要があります。

ドキュメントには、これらの構成オプションを使用して/を有効にできると記載されています。以下を無効にします:
| enable_cluster_autorecovery=<ブール整数> |
|
| enable_node_autorecovery=<ブール整数> |
|
$ systemctl restart cmon
このブログでは、主にスクリプトの前後のフックの使用方法に焦点を当てています。これは、高度なレプリケーションフェイルオーバーにとって本質的に大きな利点です。
前述のように、PostgreSQL / TimescaleDBの非同期(準同期を含む)レプリケーションとストリーミングレプリケーションを使用するMySQLバリアントは、このメカニズムをサポートしています。 ClusterControlには、スクリプトの前後のフックに使用できる次の構成オプションがあります。基本的に、これらの構成オプションは、構成ファイルを介して設定することも、Web UIを介して設定することもできます(これについては後で扱います)。
ドキュメントには、スクリプトの前後のフックを使用してフェイルオーバーメカニズムを変更できる次の構成オプションが記載されています。
| Replication_pre_failover_script = |
|
| Replication_post_failover_script = |
|
| Replication_post_unsuccessful_failover_script = |
|
技術的には、/ etc / cmon.d / cmon_
$ systemctl restart cmonまたは、<クラスターの選択>→[設定]→[ランタイム構成]に移動して、構成オプションを設定することもできます。以下のスクリーンショットを参照してください:
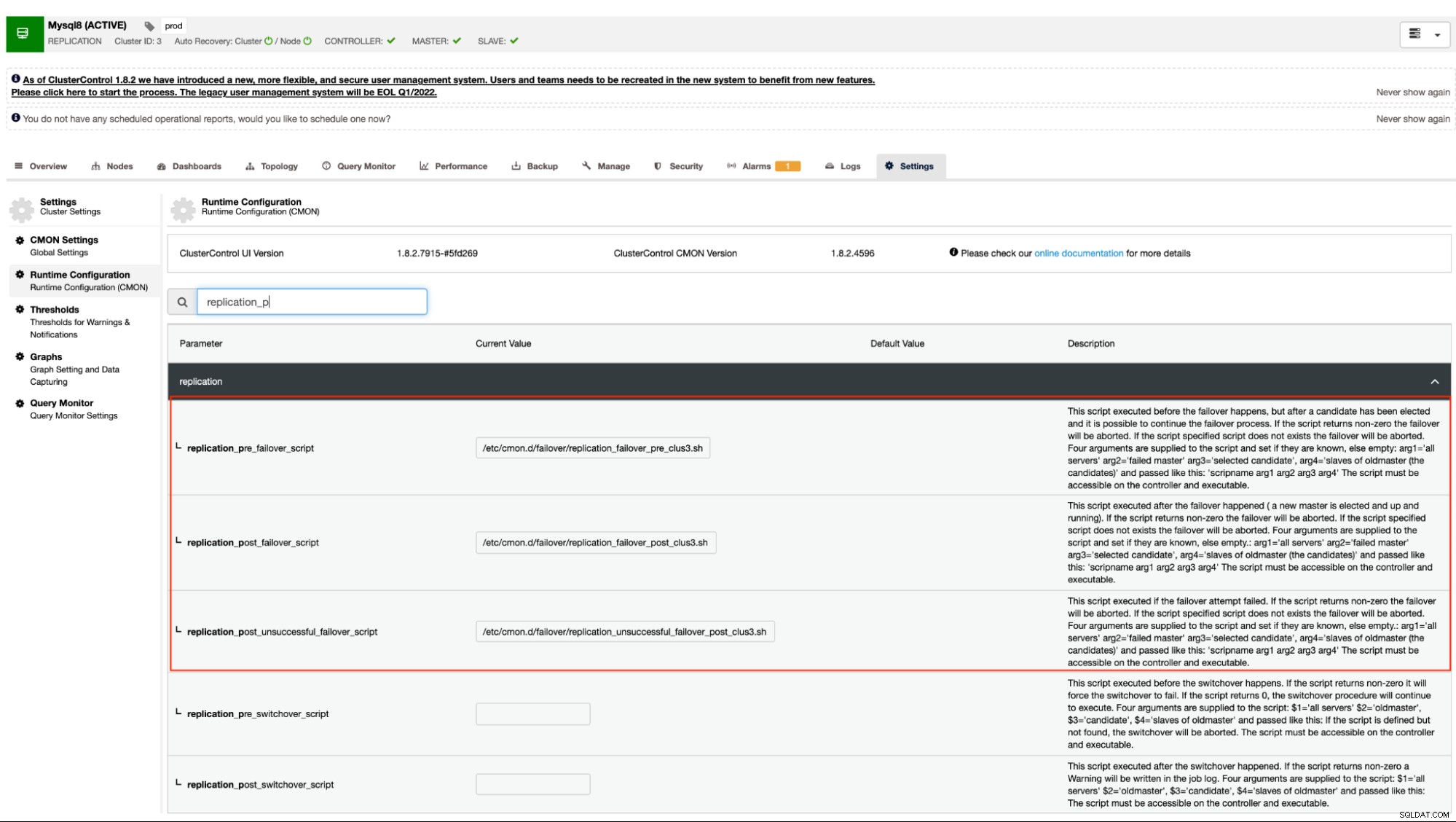
このアプローチでは、cmonサービスを再起動してからでないと、スクリプト前後のフックのこれらの構成オプションに加えられた変更。
理想的には、前後のスクリプトフックは、ClusterControlがデータベース設定の複雑さを管理できなかった高度なフェイルオーバーが必要な場合に専用になります。たとえば、セキュリティが強化されたさまざまなデータセンターを実行していて、ネットワークに到達できないというアラートが誤検知アラームではないかどうかを判断したい場合です。プライマリとスレーブが相互に到達できるかどうか、またはその逆が可能かどうかを確認する必要があります。また、ClusterControlホストに向かうデータベースノードからも到達できるかどうかを確認する必要があります。
この例でそれを実行し、それからどのように利益を得ることができるかを示しましょう。
この例では、プライマリとレプリカのみを含むMariaDBレプリケーションクラスターを使用しています。 ClusterControlによって管理され、フェイルオーバーを管理します。
ClusterControl =192.168.40.110
プライマリ(debnode5)=192.168.30.50
レプリカ(debnode9)=192.168.30.90
プライマリノードで、以下のようにスクリプトを作成します。
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"/opt/pre_failover.shが実行可能であることを確認してください。つまり
$ chmod +x /opt/pre_failover.sh次に、このスクリプトを使用してcronを介して関与させます。この例では、ファイル/etc/cron.d/ccfailoverを作成し、次の内容を使用しています。
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shレプリカでは、ホスト名を変更する以外は、プライマリに対して行った次の手順を使用します。以下のレプリカにあるものを参照してください。
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControlの前後のスクリプト
このデモンストレーションでは、cluster_idは3です。ドキュメントで前述したように、これらのスクリプトはCCコントローラーホストに存在する必要があります。したがって、私の/etc/cmon.d/cmon_3.cnfには、次のものがあります。
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.sh一方、次の「事前」フェイルオーバースクリプトは、両方のノードがCCコントローラーホストに到達できたかどうかを判別します。以下を参照してください:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
次に、プライマリノードのネットワーク停止をシミュレートして、どのように反応するかを見てみましょう。プライマリノードで、レプリカおよびCCコントローラーとの通信に使用されるネットワークインターフェイスを停止します。
example@sqldat.com:~# ip link set enp0s8 downフェイルオーバーの最初の試行中に、CCは/etc/cmon.d/failover/replication_failover_pre_clus3.shにあるプリスクリプトを実行できました。以下の仕組みをご覧ください:
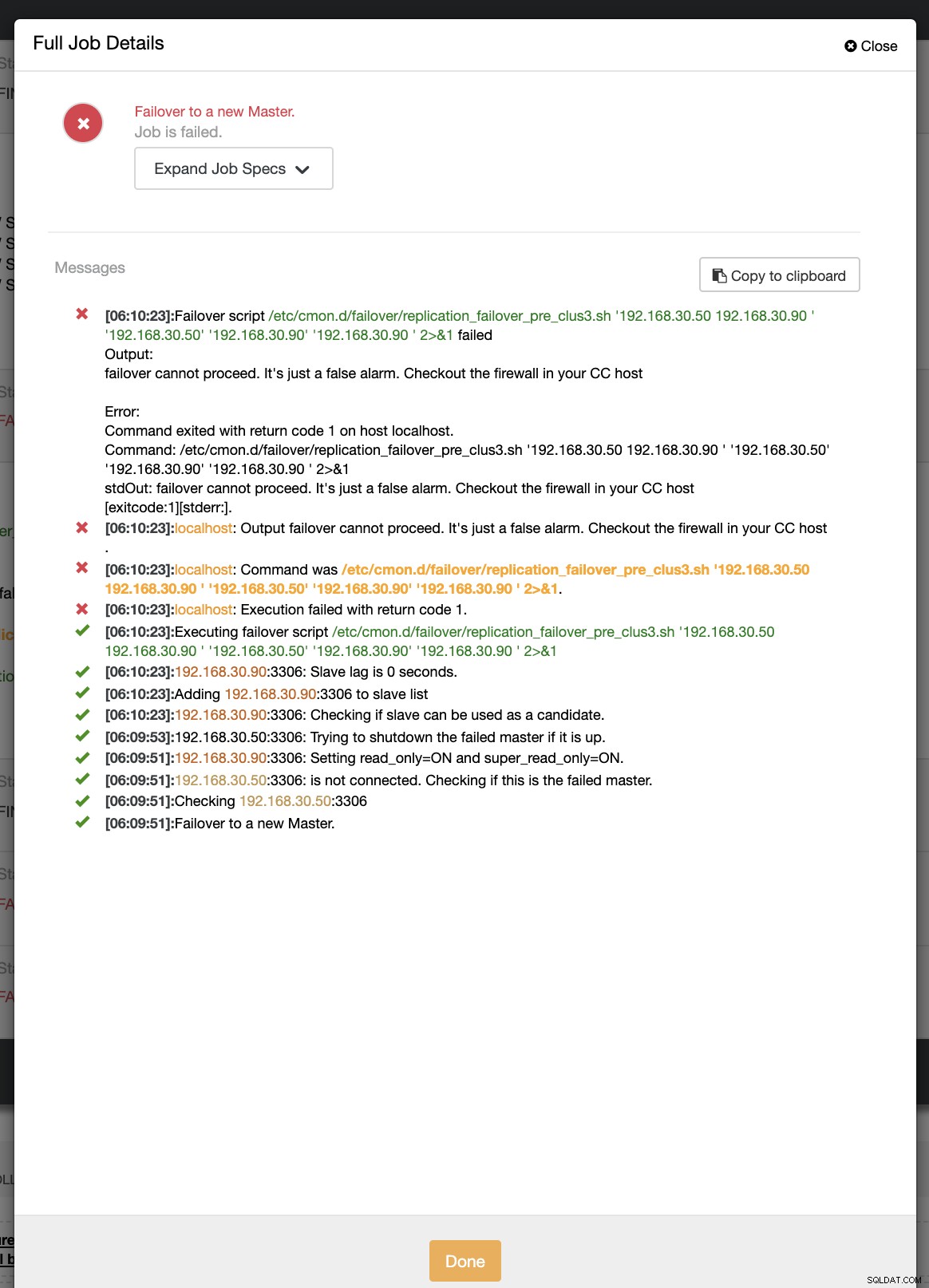
明らかに、ログに記録されたタイムスタンプがまだ1分以内であるか、プライマリがCCコントローラーに接続できたのはほんの数秒前であるため失敗します。明らかに、実際のシナリオを扱っている場合、これは完璧なアプローチではありません。ただし、ClusterControlは、期待どおりにスクリプトを完全に呼び出して実行することができました。さて、それが実際に1分以上(つまり> 60秒)に達した場合はどうでしょうか?
2回目のフェイルオーバーの試行では、タイムスタンプが60秒を超えているため、真陽性と見なされます。つまり、意図したとおりにフェイルオーバーする必要があります。 CCはそれを完全に実行し、意図したとおりにポストスクリプトを実行することさえできました。これは、ジョブログで確認できます。以下のスクリーンショットを参照してください:
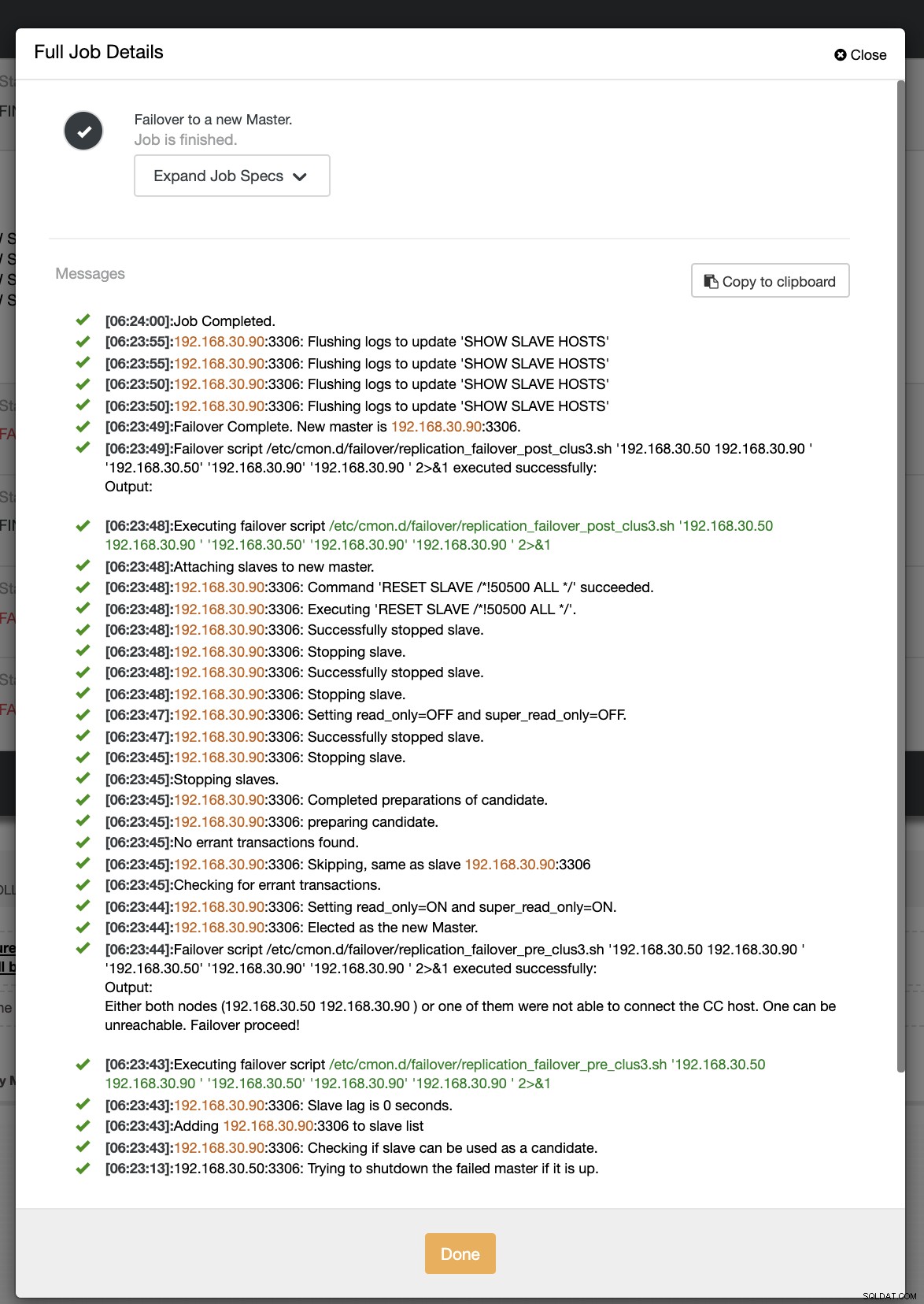
投稿スクリプトが実行されたかどうかを確認すると、ログを作成できました期待どおりにCC/tmpディレクトリにあるファイル
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtargsを使用したクラスター3でのフェイルオーバー後のスクリプト:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
これで、トポロジが変更され、フェイルオーバーが成功しました!
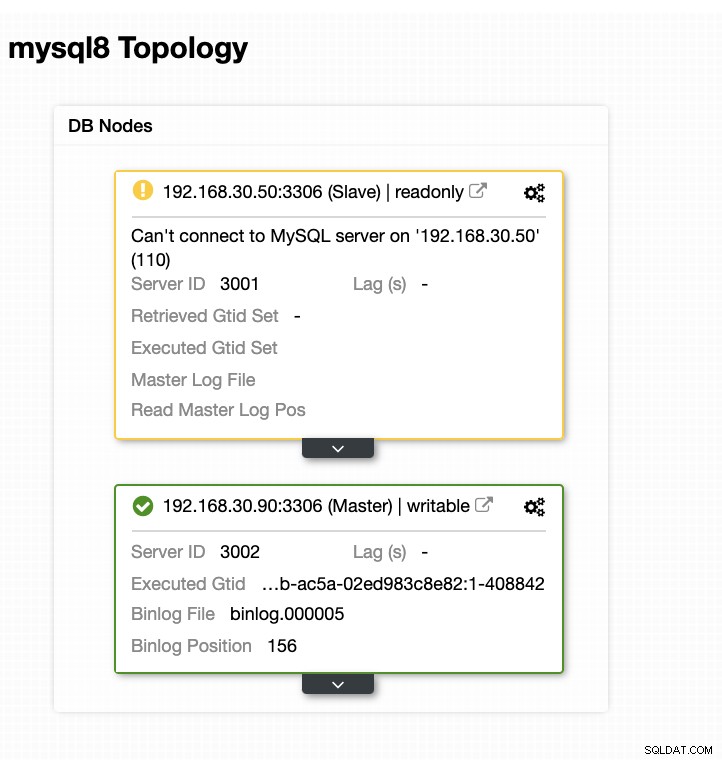
複雑なデータベース設定の場合、高度なフェイルオーバーが必要な場合は、事前/事後スクリプトが非常に役立ちます。 ClusterControlはこれらの機能をサポートしているため、それがいかに強力で役立つかを示しました。制限はありますが、特に実稼働環境で物事を達成可能で有用なものにする方法は常にあります。