データベースを効率的に運用するには、データベースのパフォーマンスに関する洞察が必要です。すべてが順調に進んでいる場合、これは明らかではないかもしれませんが、問題が発生するとすぐに、情報へのアクセスが問題を迅速かつ正確に診断するのに役立ちます。
すべてのデータベースは、内部ステータスデータの一部をユーザーが利用できるようにします。 MySQLでは、ほとんどの場合、「SHOWSTATUS」と「SHOWGLOBAL STATUS」を実行し、「SHOW ENGINE INNODB STATUS」を実行し、information_schemaテーブルをチェックし、新しいバージョンでは、performance_schemaテーブルをクエリすることでこのデータを取得できます。

これらの方法は、日常業務では便利とは言えないため、さまざまな監視およびトレンド分析ソリューションが人気を博しています。 Nagios / Icingaのようなツールは、ホスト/サービスを監視し、サービスが許容範囲外になったときにアラートを出すように設計されています。 CactiやMuninなどの他のツールは、ホスト/サービス情報をグラフィカルに表示し、パフォーマンスと使用状況の履歴コンテキストを提供します。 ClusterControlは、これら2種類の監視を組み合わせているため、ClusterControlが提示する情報と、それをどのように解釈する必要があるかを見ていきます。
Galera Cluster(CodershipによるMySQL Galera Cluster、MariaDB Cluster、またはPercona XtraDB Cluster)を使用している場合は、ClusterControlの[概要]タブに次のセクションがあることに気付いたかもしれません。
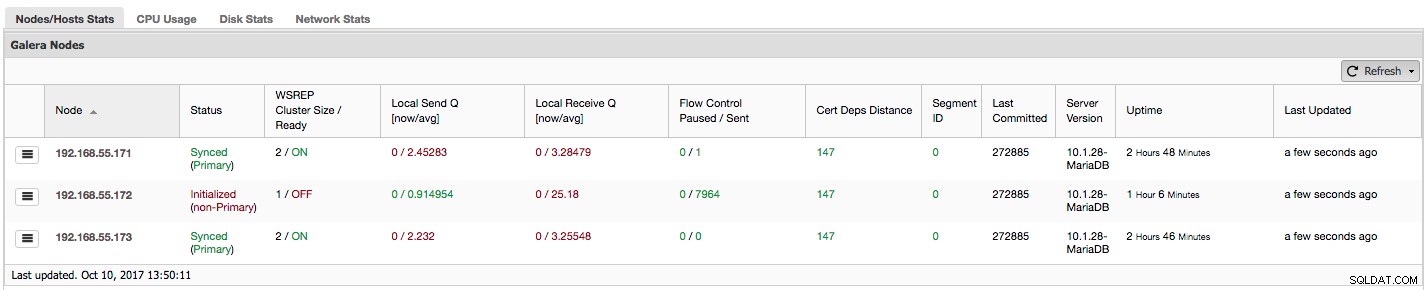
ここにあるデータの種類を段階的に見ていきましょう。
最初の列には、ノードとそのIPアドレスのリストが含まれています。他に言うことはほとんどありません。
2番目の列はさらに興味深いものです。ノードのステータス( wsrep_local_state_comment )について説明しています。 状態)。ノードはさまざまな状態になる可能性があります:
- 初期化-ノードは稼働していますが、クラスターの一部ではありません。たとえば、ネットワークの問題が原因である可能性があります。
- 参加中-ノードはクラスターへの参加を処理中であり、他のノードの1つから状態転送を受信または要求しています。
- ドナー/非同期-ノードは、クラスターに参加している他のノードへのドナーとして機能します。
- 参加-ノードはクラスターに参加していますが、コミットされた書き込みセットに追いつくのに忙しいです;
- 同期済み-ノードは正常に動作しています。
括弧内の同じ列には、クラスターステータス( wsrep_cluster_status )があります。 状態)。 3つの異なる状態を持つことができます:
- プライマリ-ノード間の通信が機能しており、クォーラムが存在します(ノードの大部分が使用可能です)
- Non-Primary-ノードはクラスターの一部でしたが、何らかの理由で、クラスターの他の部分との接続を失いました。その結果、このノードは非アクティブと見なされ、クエリを受け入れません
- 切断-ノードはグループ通信を確立できませんでした。
「WSREPクラスターサイズ/準備完了」は、ノードが認識しているクラスターサイズと、ノードがクエリを受け入れる準備ができているかどうかを示します。非プライマリコンポーネントは、サイズが1のクラスターを作成し、wsrepの準備はオフになっています。
上のスクリーンショットを見て、Galeraについて何を示しているかを見てみましょう。 3つのノードを見ることができます。それらのうちの2つ(192.168.55.171と192.168.55.173)は完全に正常であり、両方とも「同期」されており、クラスターは「プライマリ」状態になっています。現在、クラスターは2つのノードで構成されています。ノード192.168.55.172は「初期化」されており、「非プライマリ」コンポーネントを形成します。これは、このノードがクラスターとの接続を失ったことを意味します。おそらく、何らかのネットワークの問題です(実際、iptablesを使用して、192.168.55.171と192.168.55.173の両方からこのノードへのトラフィックをブロックしました)。
ここで少し立ち止まって、GaleraClusterが内部でどのように機能するかを説明する必要があります。このブログ投稿の範囲外であるため、あまり詳細には触れませんが、次の列に示されているデータの重要性を理解するには、ある程度の知識が必要です。
Galeraは、「仮想的に」同期するマルチマスタークラスターです。これは、データが「仮想的に」同時にノード間で転送されることを期待する必要があり(遅延スレーブに関する厄介な問題がなくなる)、クラスター内の任意のノードに書き込むことができることを意味します(スレーブをマスターに昇格させることに関する厄介な問題がなくなります)。 )。これを実現するために、Galeraはwritesets(クラスター全体に複製される変更のアトミックセット)を使用します。書き込みセットには、いくつかの行の変更と、ロックに関するデータなどの追加の必要な情報を含めることができます。
クライアントがCOMMITを発行すると、MySQLが実際に何かをコミットする前に、書き込みセットが作成され、認証のためにクラスター内のすべてのノードに送信されます。すべてのノードは、変更をコミットできるかどうかをチェックします(変更は、その間に別のノードで直接実行される他の書き込みに干渉する可能性があるため)。はいの場合、データは実際にMySQLによってコミットされ、そうでない場合、ロールバックが実行されます。
覚えておくべき重要なことは、通常のレプリケーションのスレーブと同様に、ノードのパフォーマンスが異なる可能性があるという事実です。一部のノードは他のノードよりも優れたハードウェアを備えている場合もあれば、他のノードよりも負荷が高い場合もあります。それでも、Galeraは、「仮想」同期を維持するために、書き込みセットを短時間で迅速に処理することを要求しています。レプリケーションを抑制し、低速のノードがクラスターの残りの部分に追いつくことができるメカニズムが必要です。
「ローカル送信Q[now/avg]」列と「ローカル受信Q[now/avg]」列を見てみましょう。各ノードには、書き込みセットを送受信するためのローカルキューがあります。これにより、ノードがトラフィックに追いつかない場合に一度に処理できなかった書き込みとキューデータの一部を並列化できます。 SHOW GLOBAL STATUSには、両方のキューを表す8つのカウンター、キューごとに4つのカウンターがあります。
- wsrep_local_send_queue -送信キューの現在の状態
- wsrep_local_send_queue_min -フラッシュステータス以降の最小値
- wsrep_local_send_queue_max -フラッシュステータス以降の最大値
- wsrep_local_send_queue_avg -フラッシュステータス以降の平均
- wsrep_local_recv_queue -受信キューの現在の状態
- wsrep_local_recv_queue_min -フラッシュステータス以降の最小値
- wsrep_local_recv_queue_max -フラッシュステータス以降の最大値
- wsrep_local_recv_queue_avg -フラッシュステータス以降の平均
上記のメトリックは、ClusterControl-> Performance-> DB Status:
の下でノード間で統合されます。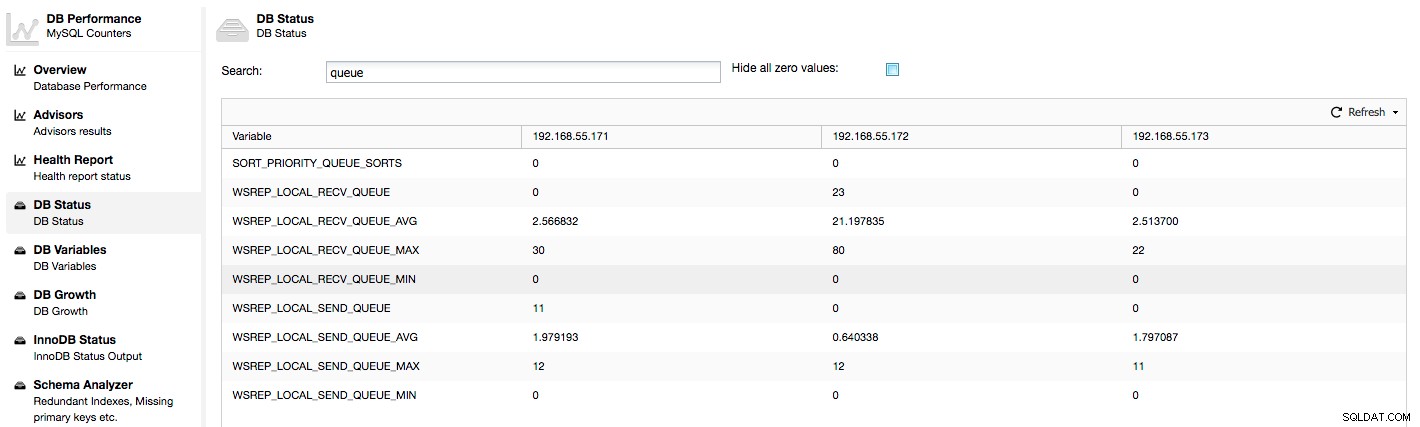
ClusterControlは、「現在」および「平均」カウンターを表示します。これらは単一の数値として最も意味があるためです(キューの現在の状態を説明する変数に基づいてカスタムグラフを作成することもできます)。キューの1つが上昇していることがわかると、これは、ノードがレプリケーションに追いつくことができず、他のノードが追いつくために速度を落とさなければならないことを意味します。その特定のノードのワークロードを調査することをお勧めします。プロセスリストで長時間実行されるクエリを確認し、CPU使用率やI/OワークロードなどのOS統計を確認してください。そのノードからクラスターの残りの部分にトラフィックの一部を再配布することも可能かもしれません。
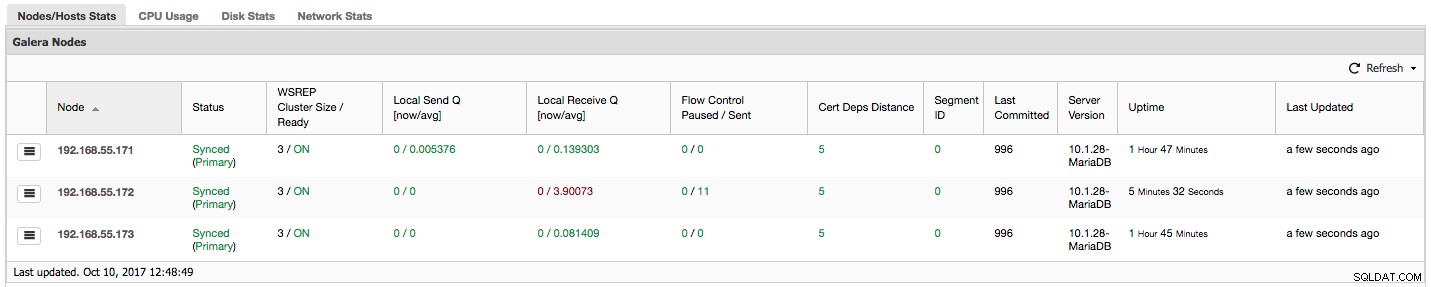
「フロー制御の一時停止」には、負荷が大きすぎるために特定のノードがレプリケーションを一時停止しなければならなかった時間の割合に関する情報が表示されます。ノードがワークロードに対応できない場合、ノードはフロー制御パケットを他のノードに送信し、書き込みセットの送信を制限する必要があることを通知します。スクリーンショットでは、ノード192.168.55.172の値は「0.30」です。これは、他のノードが必要とするライトセット認証率に追いつくことができなかったために、このノードがレプリケーションを一時停止しなければならなかった時間のほぼ30%を意味します(または、より単純で、書き込みが多すぎます!)。ご覧のとおり、「Local Receive Q [avg]」は、この事実も示しています。
次の列の「送信されたフロー制御」は、特定のノードがクラスターに送信したフロー制御パケットの数に関する情報を提供します。ここでも、クラスターの速度を低下させているのはノード192.168.55.172であることがわかります。
この情報で何ができるでしょうか?ほとんどの場合、低速ノードで何が起こっているかを調査する必要があります。 CPU使用率を確認し、I/Oパフォーマンスとネットワーク統計を確認します。この最初のステップは、私たちが直面している問題の種類を評価するのに役立ちます。
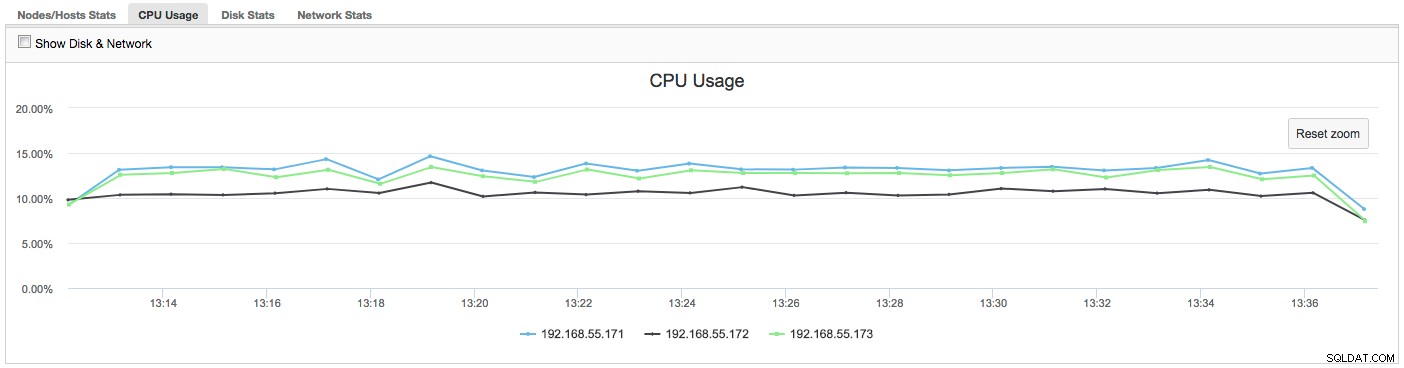
この場合、[CPU使用率]タブに切り替えると、CPU使用率が高いことが問題の原因であることが明らかになります。次のステップは、PROCESSLIST([Query Monitor]-> [Running Queries]-> [filter by 192.168.55.172])を調べて、問題のあるクエリをチェックすることにより、原因を特定することです。
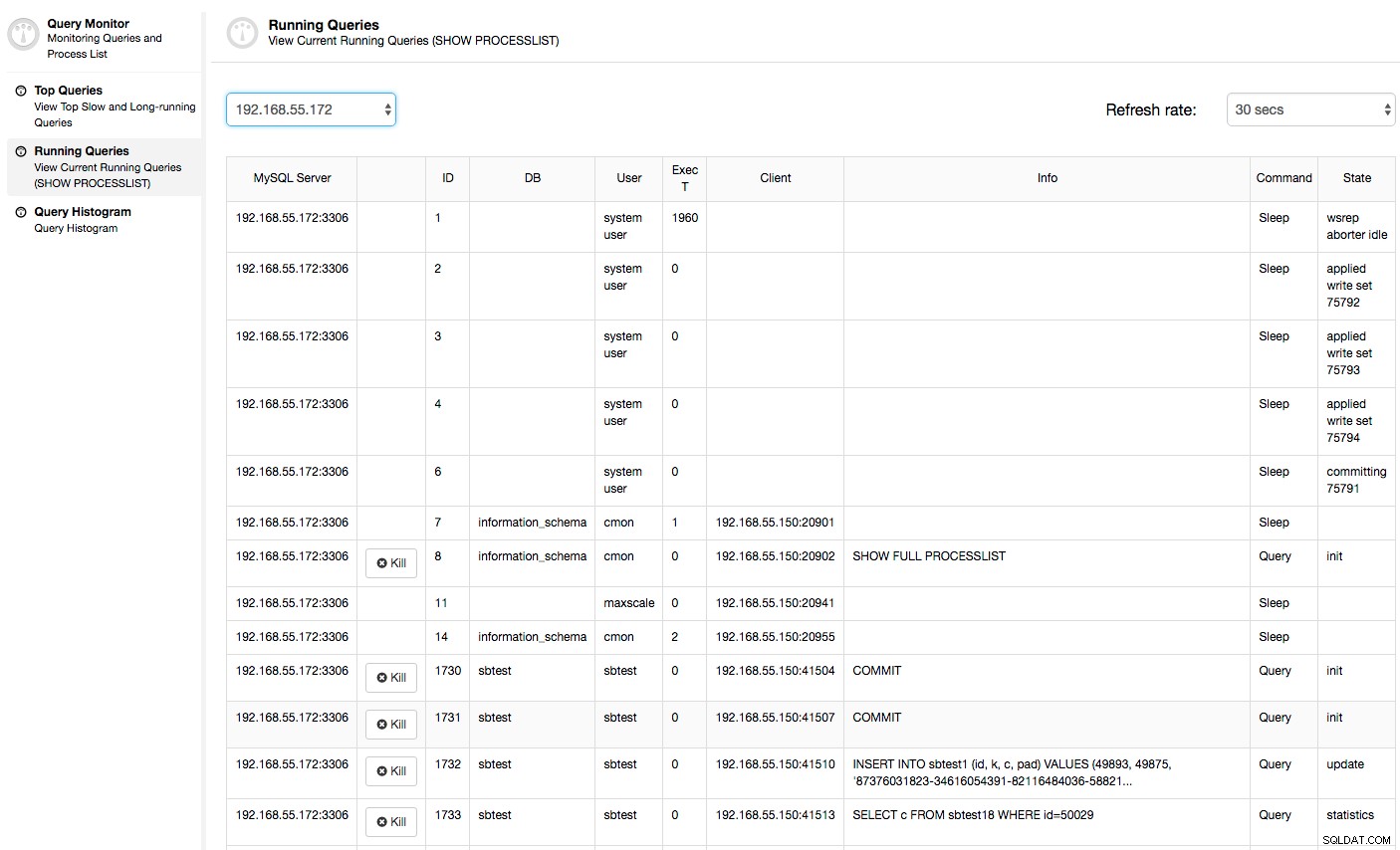
または、オペレーティングシステム側([ノード]-> 192.168.55.172-> [上])からノードのプロセスをチェックして、負荷がGalera/MySQL以外の何かによって引き起こされていないかどうかを確認します。
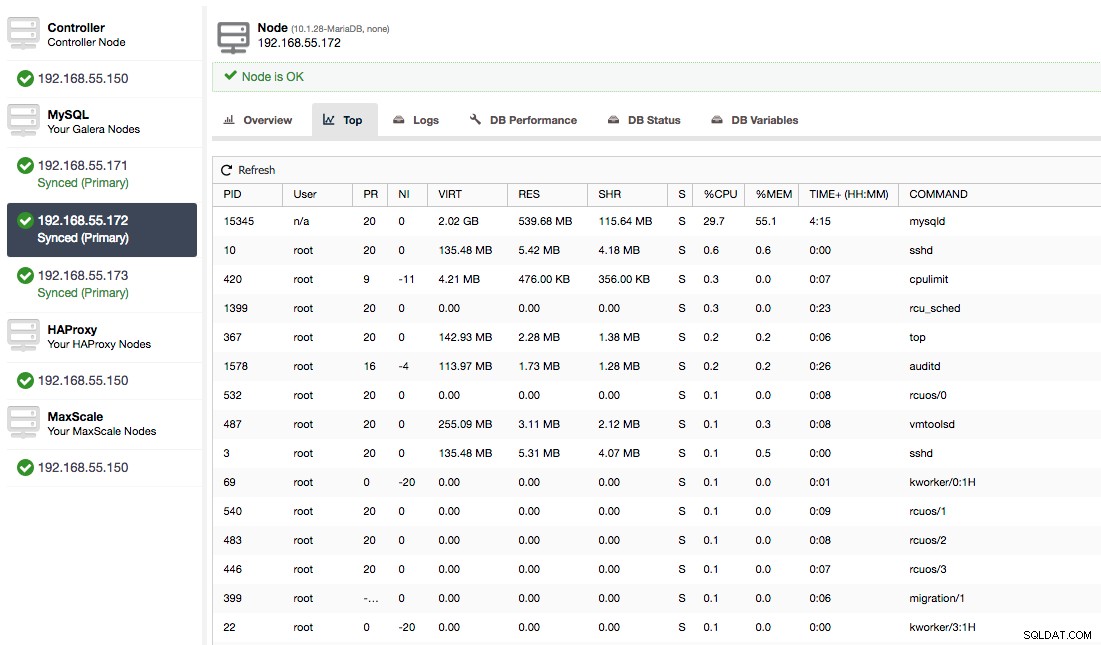
この場合、cpulimitを介してmysqldコマンドを実行し、使用可能なCPUの400%のうち30%に制限することで特にmysqldプロセスの低速CPU使用率をシミュレートしました(サーバーには4つのコアがあります)。
「CertDepsDistance」列には、平均して並列に適用できるライトセットの数に関する情報が表示されます。書き込みセットを同時に実行できる場合もあります。Galeraは、複数の wsrep_slave_threads を使用して、これを利用します。 書き込みセットを適用します。この列は、ワークロードで使用できるスレーブスレッドの数を示しています。 wsrep_slave_threadsを設定しても意味がないことに注意してください。 この列またはwsrep_cert_deps_distanceに表示される値よりも高い値に可変 「CertDepsDistance」列の基になるステータス変数。もう1つの重要な注意事項-wsrep_slave_threadsを設定しても意味がありません CPUが持つコアの数よりも多く変動します。
「セグメントID」-この列には、もう少し説明が必要です。セグメントは、Galera3.0で追加された新機能です。このバージョンより前は、書き込みセットはすべてのノード間で交換されていました。 2つのデータセンターがあるとしましょう:
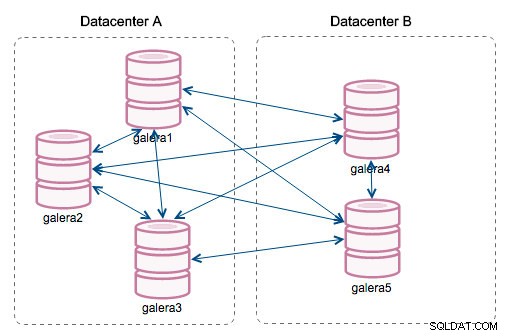
この種のおしゃべりはローカルネットワークでは問題なく機能しますが、WANは別の話です。遅延が増えるために認証が遅くなり、クラスターのすべてのメンバー間でライトセットを転送するために使用されるネットワーク帯域幅のために追加のコストが発生します。
「セグメント」の導入により、状況は変化しました。 wsrep_provider_options を変更して、ノードをセグメントに割り当てることができます。 変数に「gmcast.segment=x」(0、1、2)を追加します。同じセグメント番号のノードは、ローカルネットワークで接続された同じデータセンター内にあるものとして扱われます。その後、グラフは異なります:
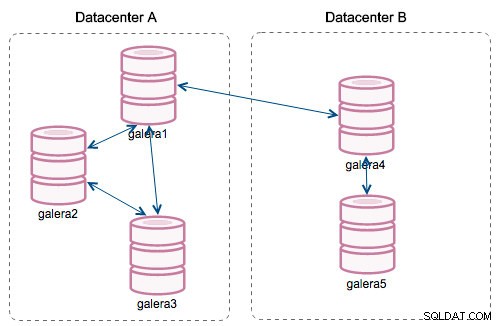
主な違いは、それはもはやすべての人からすべての人へのコミュニケーションではないということです。各セグメント内では、はい。それでも同じメカニズムですが、両方のセグメントは、選択した2つのノード間の単一の接続を介してのみ通信します。ダウンタイムが発生した場合、この接続は自動的にフェイルオーバーします。その結果、リモートデータセンター間のネットワークチャタリングと帯域幅の使用量が減少します。したがって、基本的に、「セグメントID」列は、ノードが割り当てられているセグメントを示します。
「LastCommitted」列には、特定のノードで最後に実行されたライトセットのシーケンス番号に関する情報が表示されます。クラスタをブートストラップする必要がある場合は、どのノードが最新のノードであるかを判断するのに役立ちます。
残りの列は一目瞭然です。サーバーのバージョン、ノードの稼働時間、ステータスがいつ更新されたかなどです。
ご覧のとおり、[概要]タブの[ノード/ホスト統計]の[ガレラノード]セクションでは、クラスターの状態(「プライマリ」コンポーネントを形成するかどうか、正常なノードの数)をかなりよく理解できます。 、一部のノードにパフォーマンスの問題がありますか。ある場合は、どのノードがクラスターの速度を低下させていますか。
このデータセットは、Galeraクラスターを操作するときに非常に便利なので、うまくいけば、ブラインドで飛ぶことはもうありません:-)