システム管理者および開発者として、私たちはターミナルで多くの時間を過ごします。そこで、s9sと呼ばれるコマンドラインインターフェイスツールを使用して、ClusterControlをターミナルに導入しました。 s9sは、ClusterControl RPCv2APIへの簡単なインターフェイスを提供します。 CLIを使用すると、より複雑な機能やワークフローを設計できるため、大規模な展開で作業する場合に非常に便利です。
このブログ投稿では、s9sを使用してMySQLまたはMariaDB用のGalera Clusterの管理を自動化する方法と、単純なマスタースレーブレプリケーションのセットアップを紹介しています。
セットアップ
特定のOSのインストール手順は、ドキュメントに記載されています。注意すべき重要な点は、GitHubの最新のs9s-toolsを使用した場合、ユーザーの作成方法にわずかな変更があることです。次のコマンドは正常に機能します:
s9s user --create --generate-key --controller="https://localhost:9501" dba一般に、ClusterControlホストでCLIをローカルに構成する場合は、2つの手順が必要です。まず、ユーザーを作成してから、構成ファイルにいくつかの変更を加える必要があります。すべての手順はドキュメントに含まれています。
展開
CLIが正しく構成され、ターゲットデータベースホストへのSSHアクセスが可能になったら、展開プロセスを開始できます。これを書いている時点では、CLIを使用してMySQL、MariaDB、およびPostgreSQLクラスターをデプロイできます。 Percona XtraDBCluster5.7をデプロイする方法の例から始めましょう。これを行うには、1つのコマンドが必要です。
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --wait最後のオプション「--wait」は、コマンドがジョブが完了するまで待機し、進行状況を表示することを意味します。必要に応じてスキップできます。その場合、s9sコマンドは、cmonに新しいジョブを登録した後、すぐにシェルに戻ります。 cmonはジョブ自体を処理するプロセスであるため、これはまったく問題ありません。次を使用して、いつでもジョブの進行状況を個別に確認できます。
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1別の例を見てみましょう。今回は、新しいクラスターであるMySQLレプリケーションを作成します。単純なマスターとスレーブのペアです。繰り返しますが、1つのコマンドで十分です:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdこれで、両方のクラスターが稼働していることを確認できます。
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2もちろん、これらすべてはGUIからも表示できます:
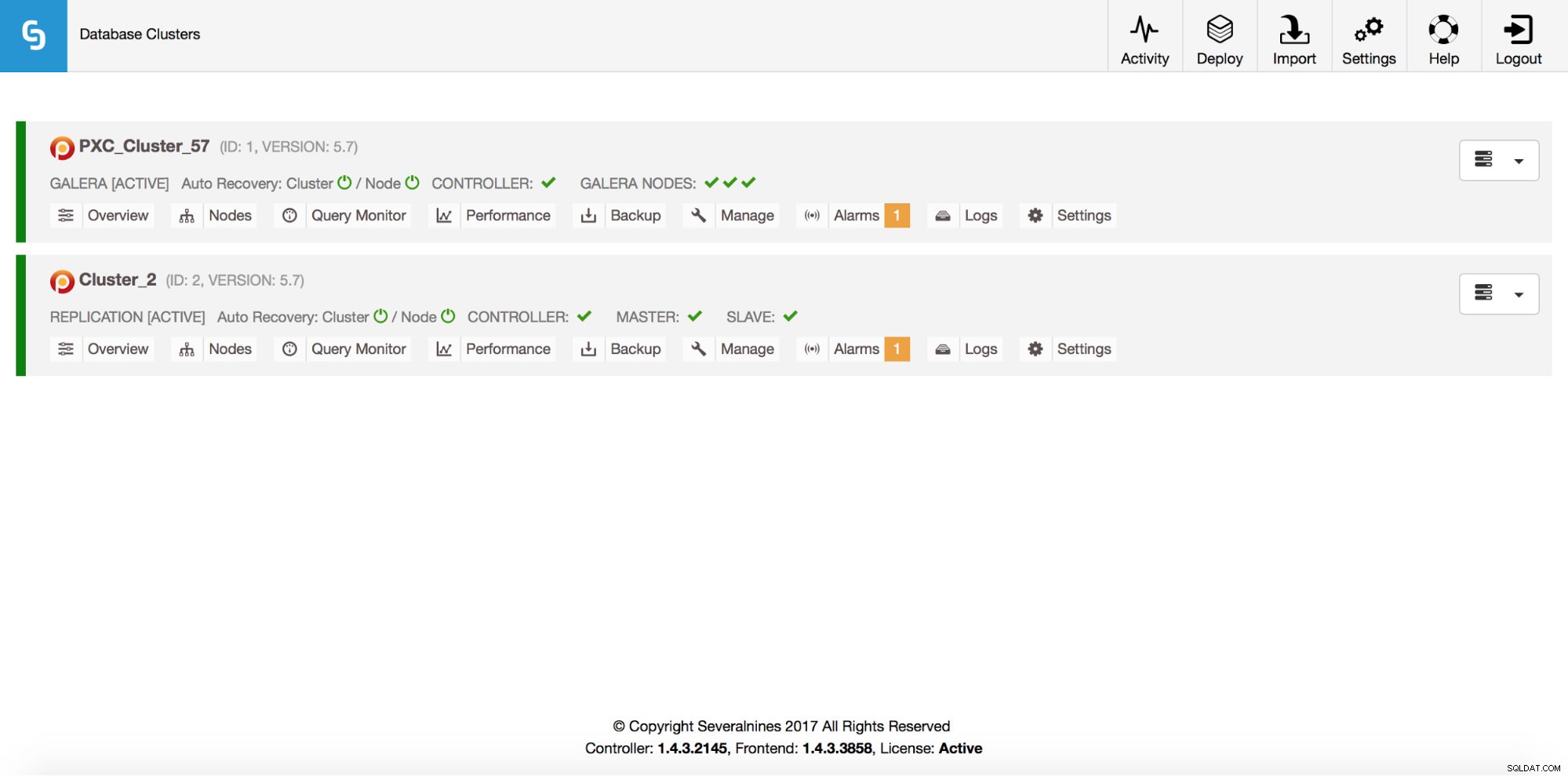
それでは、ProxySQLロードバランサーを追加しましょう:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.今回は「--wait」オプションを使用しなかったため、進捗状況を確認する場合は、自分で行う必要があります。前のコマンドで返されたジョブIDを使用しているため、この特定のジョブに関する情報のみを取得することに注意してください。
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7スケールアウト
単一のコマンドでノードをGaleraクラスターに追加できます:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8何かがうまくいかなかった。正確に何が起こったかを確認できます:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.そうです、そのIPはすでにレプリケーションサーバーに使用されています。別の無料のIPを使用する必要がありました。それを試してみましょう:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9管理
レプリケーションマスターのバックアップを取りたいとしましょう。 GUIからそれを行うことができますが、外部スクリプトと統合する必要がある場合があります。 ClusterControl CLIは、このような場合に最適です。クラスターが何であるかを確認しましょう:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2次に、クラスターID2のレプリケーションクラスター内のホストを確認しましょう。
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningご覧のとおり、ClusterControlが認識しているホストは3つあります。そのうちの2つはMySQLホスト(10.0.0.229と10.0.0.230)で、3つ目はClusterControlインスタンス自体です。関連するMySQLホストのみを印刷しましょう:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3「STAT」列には、いくつかの文字が表示されます。詳細については、s9s-nodes(man s9s-nodes)のマニュアルページを参照することをお勧めします。ここでは、最も重要な部分を要約します。最初の文字は、ノードのタイプを示しています。「s」は、通常のMySQLノードを意味します。「c」-ClusterControlコントローラー。 2番目の文字は、ノードの状態を示します。「o」は、ノードがオンラインであることを示します。 3番目の文字-ノードの役割。ここで、「M」はマスターを表し、「S」はスレーブを表し、「C」はコントローラーを表します。最後の4番目の文字は、ノードがメンテナンスモードにあるかどうかを示します。 「-」は、メンテナンスが予定されていないことを意味します。それ以外の場合は、ここに「M」が表示されます。したがって、このデータから、マスターがIP:10.0.0.229のホストであることがわかります。バックアップを取り、コントローラーに保存しましょう。
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command ok次に、それが実際に正常に完了したかどうかを確認できます。印刷する情報を定義できる「--backup-format」オプションに注意してください。
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1監視
すべてのデータベースを監視する必要があります。 ClusterControlは、アドバイザーを使用して、MySQLとオペレーティングシステムの両方でいくつかのメトリックを監視します。条件が満たされると、通知が送信されます。 ClusterControlは、事後計画または容量計画のために、リアルタイムと履歴の両方のグラフの広範なセットも提供します。 GUIを経由せずに、これらのメトリックの一部にアクセスできると便利な場合があります。 ClusterControl CLIを使用すると、s9s-nodeコマンドを使用できます。これを行う方法については、s9s-nodeのマニュアルページを参照してください。 CLIでできることの例をいくつか示します。
まず、「s9snode」コマンドの「--node-format」オプションを見てみましょう。ご覧のとおり、興味深いコンテンツを印刷するためのオプションはたくさんあります。
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningここに示したもので、おそらく自動化のいくつかのケースを想像することができます。たとえば、ノードのCPU使用率を監視し、しきい値に達した場合は、別のs9sジョブを実行して、Galeraクラスター内の新しいノードを起動できます。たとえば、メモリ使用率を監視し、しきい値を超えた場合にアラートを送信することもできます。
CLIはそれ以上のことを実行できます。まず、コマンドラインからグラフを確認することができます。もちろん、これらはGUIのグラフほど機能が豊富ではありませんが、グラフを見て予期しないパターンを見つけ、さらに調査する価値があるかどうかを判断するだけで十分な場合もあります。
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231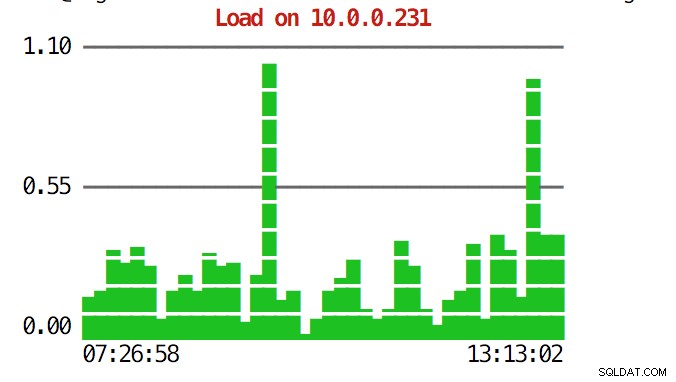
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231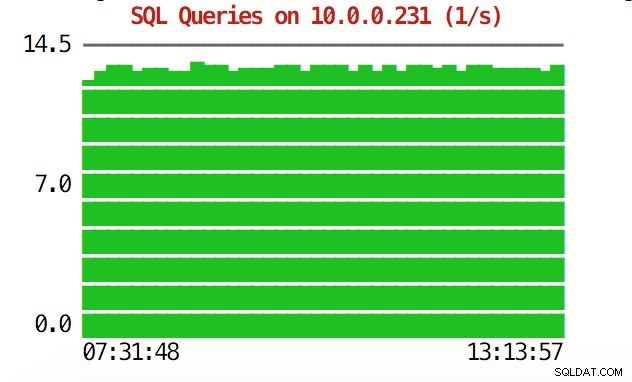
緊急事態では、クラスター全体のリソース使用率を確認することをお勧めします。すべてのクラスターノードからのデータを組み合わせたトップのような出力を作成できます。
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1H上部を見ると、クラスター全体で集計されたCPUとメモリの統計が表示されます。
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,以下に、クラスター内のすべてのノードからのプロセスのリストを示します。
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldこれは、負荷の原因と最も影響を受けるノードを特定する必要がある場合に非常に役立ちます。
うまくいけば、CLIツールを使用すると、ClusterControlを外部スクリプトおよびインフラストラクチャオーケストレーションツールと簡単に統合できます。このツールをお楽しみいただければ幸いです。改善方法についてフィードバックがありましたら、お気軽にお知らせください。