クラウドインフラストラクチャでデータベースを実行することは、最近ますます人気が高まっています。クラウドVMはエンタープライズグレードのサーバーほど信頼性が高くない場合がありますが、主要なクラウドプロバイダーは、サービスの可用性を高めるためのさまざまなツールを提供しています。このブログ投稿では、クラウドで高可用性を実現するためにMySQLまたはMariaDBデータベースを設計する方法を紹介します。特にアマゾンウェブサービスとGoogleCloudPlatformについて見ていきますが、ほとんどのヒントは他のクラウドプロバイダーでも使用できます。
AWSとGoogleはどちらもクラウド上でデータベースサービスを提供しており、これらのサービスは高可用性を実現するように設定できます。リージョン内のサービスの部分的な障害を乗り切るチャンスを増やすために、さまざまなアベイラビリティーゾーン(またはGCPのゾーン)にコピーを配置することができます。ホスト型サービスはデータベースを実行するための非常に便利な方法ですが、サービスは特定の方法で動作するように設計されており、要件に適合する場合と適合しない場合があることに注意してください。したがって、たとえば、AWS RDS for MySQLには、フェイルオーバー処理に関してはかなり限られたオプションのリストがあります。ドキュメントによると、マルチAZ展開には、60〜120秒のフェイルオーバー時間があります。実際、「シャドウ」MySQLインスタンスは「破損した」データセットから開始する必要があるため、InnoDB REDOログからのトランザクションの適用またはロールバックにさらに多くの作業が必要になる可能性があるため、これにはさらに時間がかかる可能性があります。スレーブをマスターに昇格させるオプションがありますが、既存のスレーブを新しいマスターから再スレーブすることはできないため、実行できません。マネージドサービスの場合、本質的に複雑で、パフォーマンスの問題を追跡するのが困難です。このブログ投稿で、RDSforMySQLとその制限に関する詳細情報をご覧ください。
一方、データベースを管理することにした場合は、別の可能性の世界にいます。ベアメタルで実行できる多くのことは、EC2またはComputeEngineインスタンスでも可能です。基盤となるハードウェアを管理するオーバーヘッドはありませんが、システムの設計方法を制御できます。 MySQLの可用性を設計する場合、MySQLレプリケーションとGaleraClusterの2つの主要なオプションがあります。それらについて話し合いましょう。
MySQLレプリケーション
MySQLレプリケーションは、データの複数のコピーを使用してMySQLをスケーリングする一般的な方法です。非同期または準同期では、単一のライターであるマスターで実行された変更をレプリカ/スレーブに伝播できます。各レプリカ/スレーブには完全なデータセットが含まれ、新しいマスターになるように昇格できます。レプリケーションは、リードトラフィックをレプリカに転送し、この方法でマスターをオフロードすることにより、リードのスケーリングにも使用できます。レプリケーションの主な利点は使いやすさです。レプリケーションは非常に広く知られ、人気があり(構成も簡単です)、管理と構成に役立つ多数のリソースとツールがあります。独自のClusterControlはその1つです。これを使用して、統合されたロードバランサーを使用してMySQLレプリケーションセットアップを簡単にデプロイし、トポロジの変更、フェイルオーバー/リカバリなどを管理できます。
MySQLレプリケーションの大きな問題の1つは、ネットワークの分割やマスターの障害を処理するように設計されていないことです。マスターがダウンした場合は、レプリカの1つをプロモートする必要があります。これは手動プロセスですが、外部ツール(ClusterControlなど)を使用して自動化することもできます。また、クォーラムメカニズムはなく、MySQLレプリケーションで失敗したマスターインスタンスのフェンシングはサポートされていません。残念ながら、これは分散環境で深刻な問題を引き起こす可能性があります。古いマスターがオンラインに戻ったときに新しいマスターをプロモートすると、2つのノードに書き込み、データドリフトが発生し、深刻なデータ整合性の問題が発生する可能性があります。
この投稿の後半で、ネットワーク分割を検出し、MySQLレプリケーションセットアップにSTONITHまたはその他のフェンシングメカニズムを実装する方法を示すいくつかの例を検討します。
ガレラクラスター
前のセクションで、MySQLレプリケーションにはフェンシングとクォーラムのサポートがないことを確認しました。これがGaleraClusterの優れた点です。クォーラムサポートが組み込まれており、パーティション化されたノードが書き込みを受け入れないようにするフェンシングメカニズムも備えています。これにより、Galera Clusterは、マルチデータセンターのセットアップでのレプリケーションよりも適しています。 Galera Clusterは複数のライターもサポートしており、書き込みの競合を解決できます。したがって、マルチデータセンターのセットアップでは単一のライターに限定されず、すべてのデータセンターにライターを配置して、アプリケーションとデータベース層の間の遅延を減らすことができます。認証のためにすべての書き込みをすべてのGaleraノードに送信する必要があるため、書き込みが高速化されるわけではありませんが、WANを介してすべてのアプリケーションサーバーから単一のリモートマスターに書き込みを送信するよりも簡単です。
Galeraは優れていますが、すべてのワークロードに常に最適であるとは限りません。 Galeraは、MySQL/InnoDBのドロップイン代替品ではありません。 「通常の」MySQLと共通の機能を共有します。ストレージエンジンとしてInnoDBを使用し、すべてのノードにデータセット全体が含まれているため、JOINが実現可能です。それでも、Galeraのパフォーマンス特性の一部(ネットワーク遅延の影響を受ける書き込みのパフォーマンスなど)は、レプリケーションのセットアップから期待されるものとは異なります。メンテナンスも異なって見えます。スキーマ変更の処理は少し異なります。一部のスキーマ設計は最適ではありません。頻繁に更新されるカウンターなど、テーブルにホットスポットがある場合、パフォーマンスの問題が発生する可能性があります。バッチ処理に関連するベストプラクティスにも違いがあります。大きなトランザクションでクエリを実行する代わりに、トランザクションを小さくする必要があります。
プロキシ層
プロキシなしで可用性の高いセットアップを構築することは非常に困難で面倒です。もちろん、アプリケーションにコードを記述して、データベースインスタンスを追跡したり、異常なインスタンスをブラックリストに登録したり、書き込み可能なマスターを追跡したりすることができます。ただし、これは、トラフィックを単一のエンドポイントに送信するよりもはるかに複雑です。これは、プロキシが入る場所です。ClusterControlを使用すると、ProxySQL、HAProxy、およびMaxScaleをデプロイできます。 ProxySQLを使用した例をいくつか示します。これにより、データベーストラフィックを柔軟に制御できるようになります。
ProxySQLは、いくつかの方法で展開できます。手始めに、それは別々のホストに展開することができ、Keepalivedを使用して仮想IPを提供することができます。 ProxySQLインスタンスの1つに障害が発生した場合、仮想IPは移動されます。クラウドでは、通常、インターフェイスにIPを追加するだけでは不十分であるため、この設定は問題になる可能性があります。エラスティックIP(または静的-ただし、クラウドプロバイダーによって呼び出される場合があります)で動作するように、Keepalived構成とスクリプトを変更する必要があります。次に、クラウドAPIまたはCLIを使用して、このIPアドレスを別のホストに再配置します。このため、ProxySQLをアプリケーションと併置することをお勧めします。各アプリケーションサーバーは、Unixソケットを使用してローカルProxySQLに接続するように構成されます。 ProxySQLはエンジェルプロセスを使用するため、ProxySQLのクラッシュを1秒以内に検出/再起動できます。ハードウェアがクラッシュした場合、その特定のアプリケーションサーバーはProxySQLとともにダウンします。残りのアプリケーションサーバーは、引き続きそれぞれのローカルProxySQLインスタンスにアクセスできます。この特定のセットアップには追加機能があります。セキュリティ-ProxySQLは、バージョン1.4.8の時点で、クライアント側のSSLをサポートしていません。 ProxySQLとバックエンド間のSSL接続のみをセットアップできます。アプリケーションホストでProxySQLを連結し、Unixソケットを使用することは良い回避策です。 ProxySQLにはクエリをキャッシュする機能もあり、この機能を使用する場合は、レイテンシを減らすために、アプリケーションのできるだけ近くに保持するのが理にかなっています。このパターンを使用してProxySQLをデプロイすることをお勧めします。
一般的な設定
高可用性セットアップの例を見てみましょう。
単一のデータセンター、MySQLレプリケーション
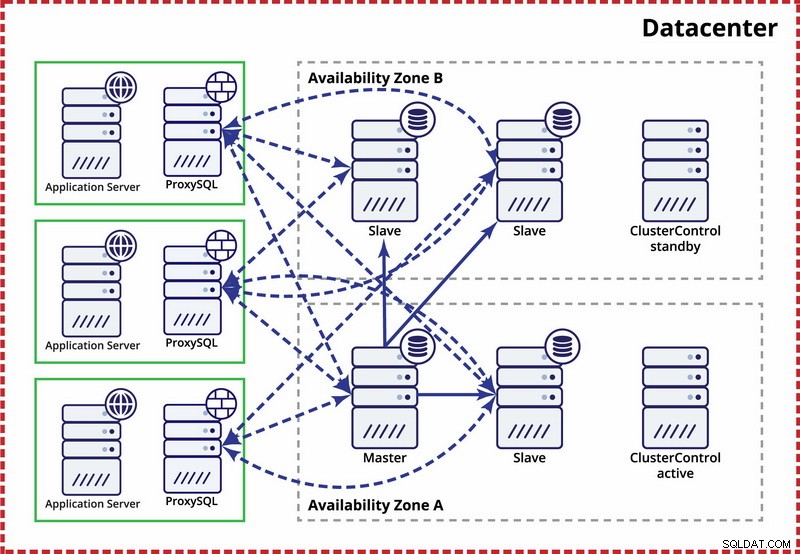
ここでの前提は、データセンター内に2つの別個のゾーンがあることです。各ゾーンには、2つのゾーンが同時に故障する可能性を減らすために、冗長で個別の電源、ネットワーキング、および接続があります。両方のゾーンにまたがるレプリケーショントポロジを設定することができます。
ここでは、ClusterControlを使用してフェイルオーバーを管理します。アベイラビリティーゾーン間のスプリットブレインシナリオを解決するために、アクティブなClusterControlをマスターと併置します。また、他のアベイラビリティーゾーンのスレーブをブラックリストに登録して、自動フェイルオーバーによって2つのマスターが使用可能にならないようにします。
複数のデータセンター、MySQLレプリケーション
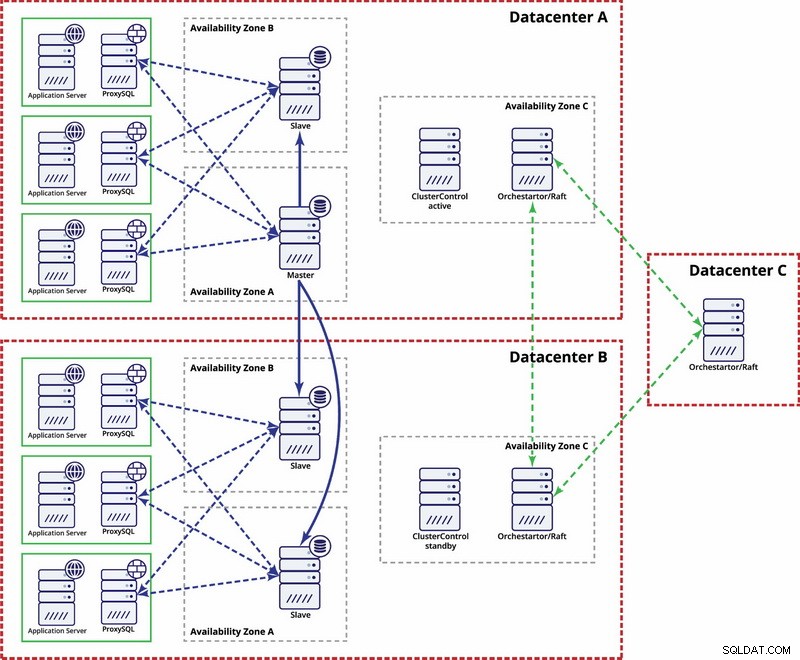
この例では、クォーラムの計算に3つのデータセンターとOrchestrator/Raftを使用します。マスターがインフラストラクチャのパーティション化されたセグメントにある場合は、STONITHを実装するために独自のスクリプトを作成する必要がある場合があります。 ClusterControlは、ノードの回復および管理機能に使用されます。
複数のデータセンター、Galera Cluster
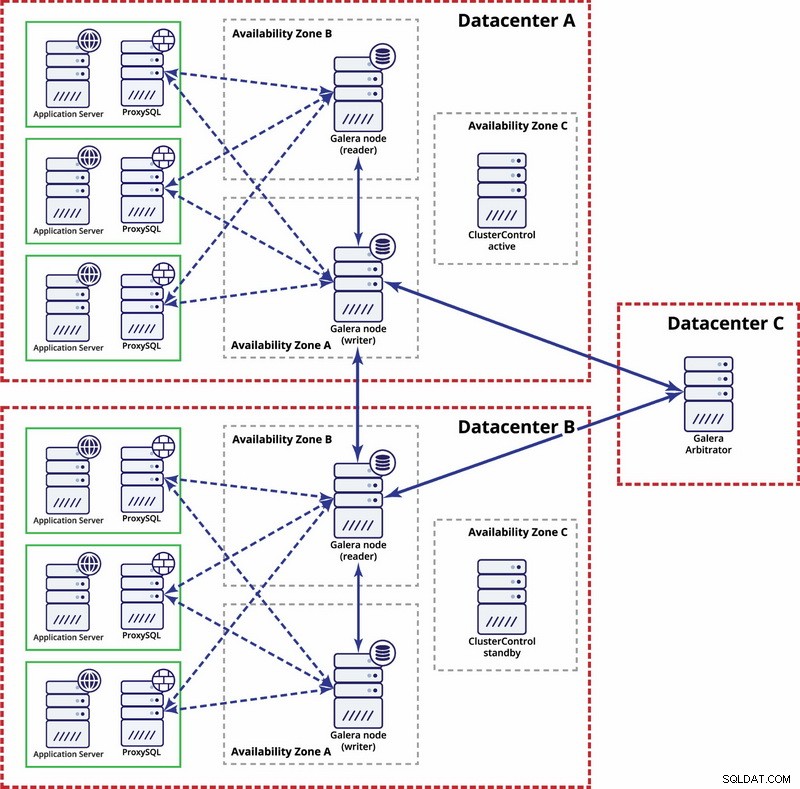
この場合、3つ目のデータセンターにGaleraアービトレーターを備えた3つのデータセンターを使用します。これにより、データセンター全体の障害を処理でき、3つ目のデータセンターをリレーとして使用できるため、ネットワークのパーティション分割のリスクが軽減されます。
詳細については、「高可用性オープンソースデータベース環境を設計する方法」ホワイトペーパーを参照し、ウェビナーのリプレイ「高可用性のためのオープンソースデータベースの設計」をご覧ください。