このブログ投稿では、単一サーバーの問題からマルチデータセンターのフェイルオーバー計画に至るまで、本番データベースシステムの6つの異なる障害シナリオを分析します。それぞれのシナリオのリカバリとフェイルオーバーの手順を説明します。これにより、直面する可能性のあるリスクと、インフラストラクチャを設計する際に考慮すべき事項を十分に理解できるようになることを願っています。
データベーススキーマが破損しています
単一ノードのインストールから始めましょう-最も単純な形式のデータベース設定。実装が簡単で、最低のコストです。このシナリオでは、各データベーススキーマが異なるアプリケーションに属する単一のサーバーで複数のアプリケーションを実行します。単一のスキーマを回復するためのアプローチは、いくつかの要因に依存します。
- バックアップはありますか?
- バックアップはありますか?また、どのくらいの速さで復元できますか?
- どのような種類のストレージエンジンが使用されていますか?
- PITR互換の(ポイントインタイムリカバリ)バックアップはありますか?
データの破損はmysqlcheckで特定できます。
mysqlcheck -uroot -p <DATABASE>DATABASEをデータベースの名前に置き換え、TABLEを確認するテーブルの名前に置き換えます。
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheckは、指定されたデータベースとテーブルをチェックします。テーブルがチェックに合格すると、mysqlcheckはテーブルに対してOKを表示します。以下の例では、テーブルが給与であることがわかります。 回復が必要です。
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OK追加のDRサーバーを使用しない単一ノードのインストールの場合、主なアプローチはバックアップからデータを復元することです。しかし、これだけを考慮する必要はありません。同じインスタンスの下に複数のデータベーススキーマがあると、データを復元するためにサーバーを停止する必要がある場合に問題が発生します。もう1つの質問は、すべてのデータベースを最後のバックアップにロールバックする余裕があるかどうかです。ほとんどの場合、それは不可能です。
ここにはいくつかの例外があります。ポイントインタイムリカバリが不要な場合は、最後のバックアップから単一のテーブルまたはデータベースを復元することができます。このようなプロセスはより複雑です。 mysqldumpがある場合は、そこからデータベースを抽出できます。 xtradbackupまたはmariabackupを使用してバイナリバックアップを実行し、ファイルごとにテーブルを有効にしている場合は、それが可能です。
ファイルごとのテーブルオプションが有効になっているかどうかを確認する方法は次のとおりです。
mysql> SET GLOBAL innodb_file_per_table=1; innodb_file_per_tableを有効にすると、InnoDBテーブルをtbl_name.ibdファイルに保存できます。 MyISAMストレージエンジンとは異なり、インデックスとデータ用に別々のtbl_name.MYDファイルとtbl_name.MYIファイルがあり、InnoDBはデータとインデックスを1つの.ibdファイルにまとめて保存します。ストレージエンジンを確認するには、以下を実行する必要があります:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';またはコンソールから直接:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: xtradbackupからテーブルを復元するには、エクスポートプロセスを実行する必要があります。バックアップを復元する前に、バックアップを準備する必要があります。エクスポートは準備段階で行われます。完全バックアップが作成されたら、追加のフラグ--export:
を指定して標準の準備手順を実行します。innobackupex --apply-log --export /u01/backupこれにより、後でインポートフェーズで使用する追加のエクスポートファイルが作成されます。テーブルを別のサーバーにインポートするには、最初に、そのサーバーでインポートされるものと同じ構造の新しいテーブルを作成します。
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;表領域を破棄します:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;次に、mytable.ibdファイルとmytable.expファイルをデータベースのホームにコピーし、そのテーブルスペースをインポートします。
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;ただし、これをより制御された方法で行うには、他のインスタンス/サーバーでデータベースのバックアップを復元し、必要なものをメインシステムにコピーして戻すことをお勧めします。これを行うには、mysqlインスタンスのインストールを実行する必要があります。これは同じマシンで実行できますが、両方のインスタンスを同じマシンで実行できるように構成するには、より多くの労力が必要です。たとえば、異なる通信設定が必要になります。
ClusterControlを使用して、タスクの復元とインストールの両方を組み合わせることができます。
ClusterControlは、オンプレミスまたはクラウドで利用可能なバックアップを案内し、復元の正確な時間または正確なログ位置を選択し、必要に応じて新しいデータベースインスタンスをインストールできるようにします。
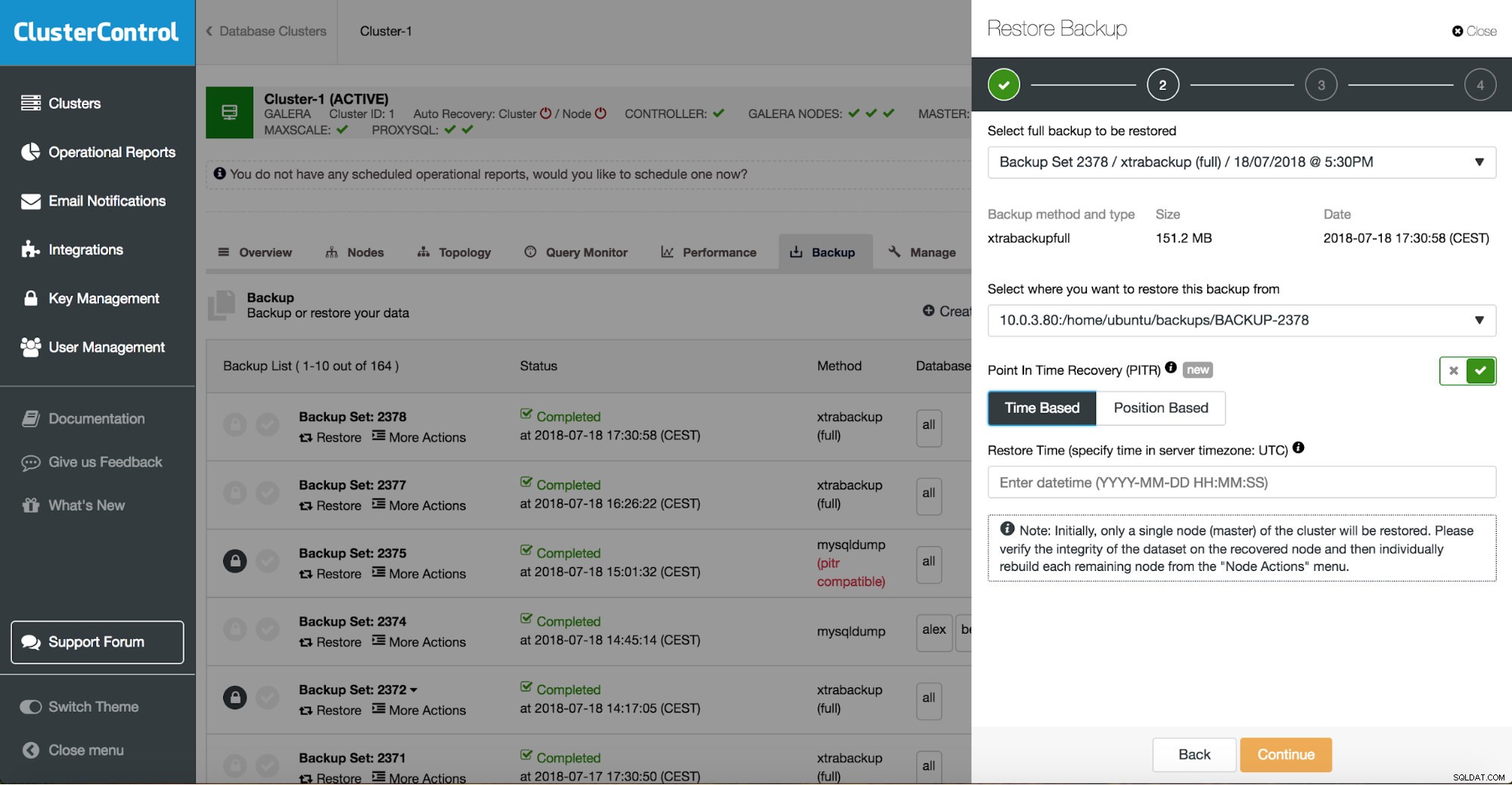 ClusterControlポイントインタイムリカバリ
ClusterControlポイントインタイムリカバリ 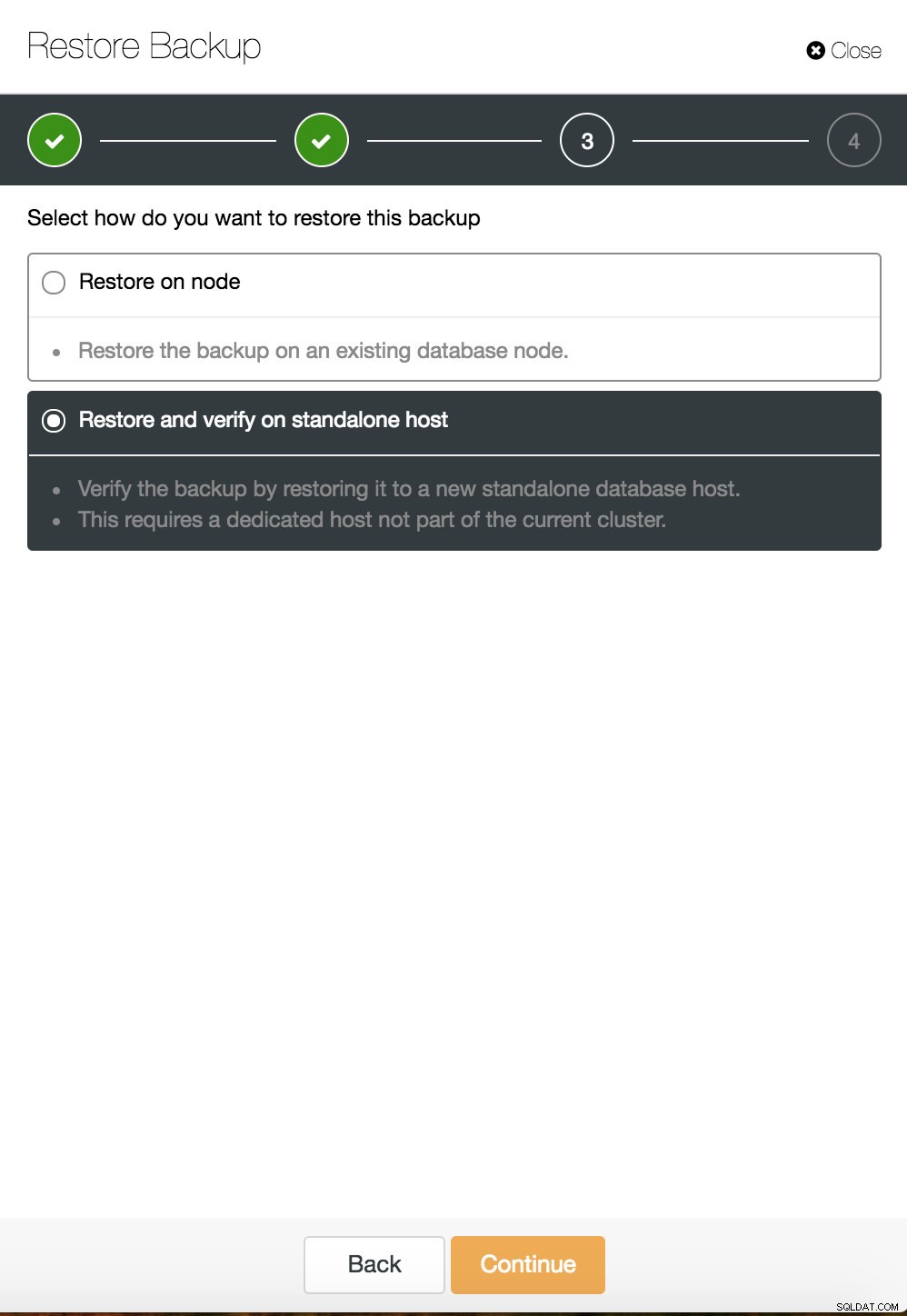 ClusterControlはスタンドアロンホストで復元および検証します
ClusterControlはスタンドアロンホストで復元および検証します 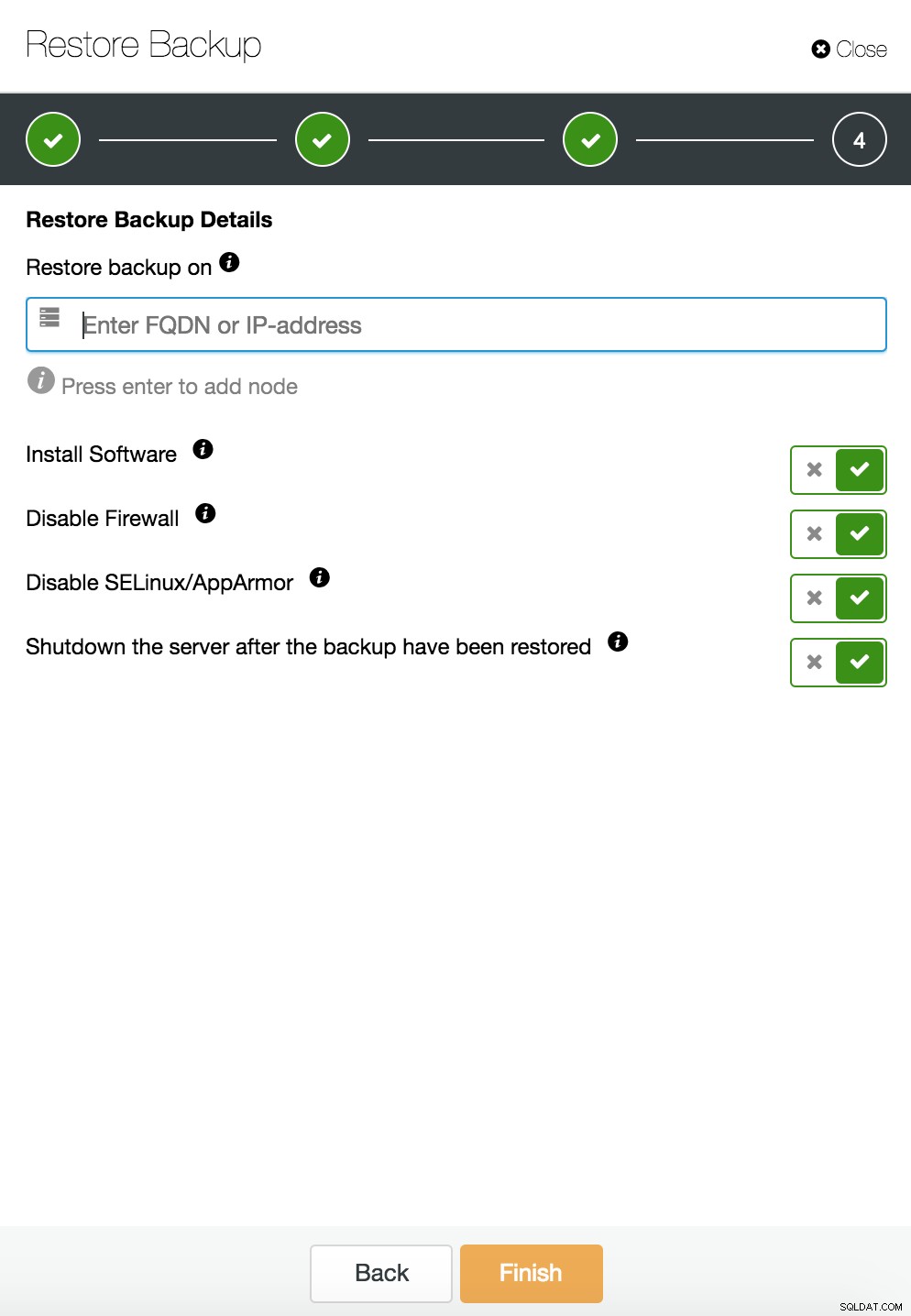 CusterControlは、スタンドアロンホストで復元および検証します。インストールオプション。
CusterControlは、スタンドアロンホストで復元および検証します。インストールオプション。 データ回復の詳細については、ブログMy MySQL Database is Corrupted ...を参照してください。今何をしますか?
専用サーバーでデータベースインスタンスが破損しました
基盤となるプラットフォームの欠陥は、データベースの破損の原因となることがよくあります。 MySQLインスタンスは、データを保存および取得するために、ディスクサブシステム、コントローラー、通信チャネル、ドライバー、ファームウェアなど、さまざまなものに依存しています。クラッシュは、データの一部、mysqlバイナリ、またはシステムに保存しているバックアップファイルにさえ影響を与える可能性があります。異なるアプリケーションを分離するために、それらを専用サーバーに配置できます。
余裕があれば、別々のシステムに異なるアプリケーションスキーマを配置することをお勧めします。これはリソースの無駄だと言う人もいるかもしれませんが、そのうちの1つだけがダウンした場合、ビジネスへの影響は少なくなる可能性があります。ただし、それでも、データベースをデータ損失から保護する必要があります。別の場所にコピーがある限り、同じサーバーにバックアップを保存することは悪い考えではありません。最近では、クラウドストレージはテープバックアップの優れた代替手段です。
ClusterControlを使用すると、バックアップのコピーをクラウドに保持できます。上位3つのクラウドプロバイダー(Amazon AWS、Google Cloud、Microsoft Azure)へのアップロードをサポートしています。
完全バックアップを復元したら、特定の時点に復元することをお勧めします。ポイントインタイムリカバリにより、サーバーは完全バックアップが作成されたときよりも新しい時刻に更新されます。そのためには、バイナリログを有効にする必要があります。次のコマンドで利用可能なバイナリログを確認できます:
mysql> SHOW BINARY LOGS;そして現在のログファイル:
SHOW MASTER STATUS;次に、バイナリログをSQLファイルに渡すことで増分データをキャプチャできます。その後、欠落している操作を再実行できます。
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outClusterControlでも同じことができます。
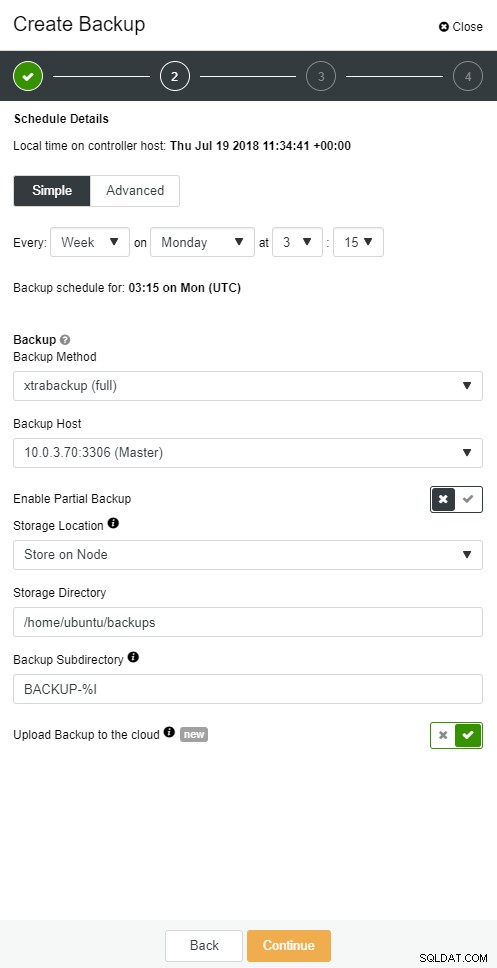 ClusterControlクラウドバックアップ
ClusterControlクラウドバックアップ 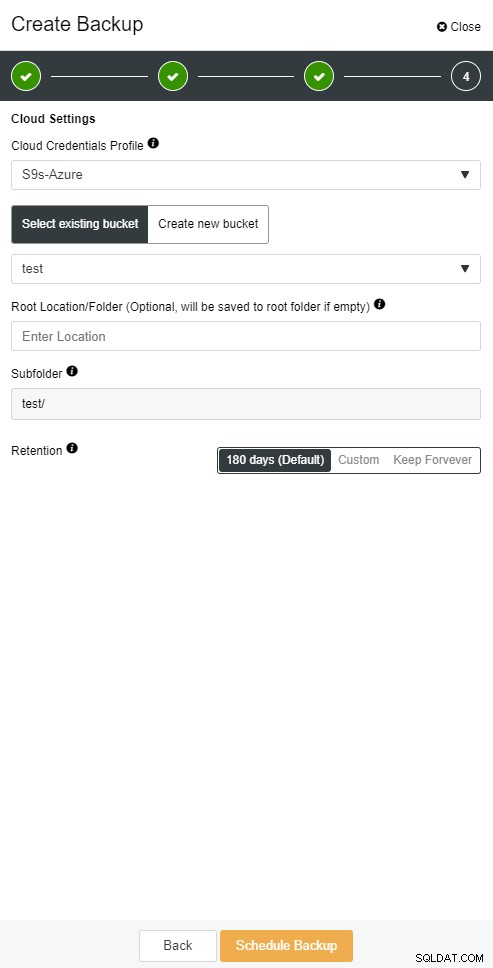 ClusterControlクラウドバックアップ
ClusterControlクラウドバックアップ データベーススレーブがダウンする
さて、データベースは専用サーバーで実行されています。完全バックアップと増分バックアップを組み合わせて高度なバックアップスケジュールを作成し、それらをクラウドにアップロードして、最新のバックアップをローカルディスクに保存し、迅速に復旧できるようにしました。さまざまなバックアップ保持ポリシーがあります。ローカルディスクドライバーに保存されているバックアップの場合は短く、クラウドバックアップの場合は拡張されます。
災害シナリオに十分に備えているようです。ただし、復元時間に関しては、ビジネスニーズを満たさない場合があります。
クイックフェイルオーバー機能が必要です。書き込みが行われるマスターからのバイナリログを適用して稼働するサーバー。マスター/スレーブレプリケーションは、フェイルオーバーシナリオの新しい章を開始します。マスターがダウンした場合にアプリケーションを復活させるための迅速な方法です。
ただし、フェイルオーバーのシナリオで考慮すべきことがいくつかあります。 1つは、遅延レプリケーションスレーブをセットアップすることです。これにより、マスターサーバーでトリガーされたファットフィンガーコマンドに対応できます。スレーブサーバーは、少なくとも指定された時間だけマスターより遅れることがあります。デフォルトの遅延は0秒です。 CHANGE MASTER TOのMASTER_DELAYオプションを使用して、遅延をN秒に設定します。
CHANGE MASTER TO MASTER_DELAY = N;2つ目は、自動フェイルオーバーを有効にすることです。市場には多くの自動フェイルオーバーソリューションがあります。自動フェイルオーバーは、MHA、MRM、mysqlfailover、GUIOrchestratorおよびClusterControlなどのコマンドラインツールを使用して設定できます。正しく設定すると、停止を大幅に減らすことができます。
ClusterControlは、MySQL、PostgreSQL、MongoDBレプリケーションの自動フェイルオーバー、およびマルチマスタークラスターソリューションのGaleraとNDBをサポートしています。
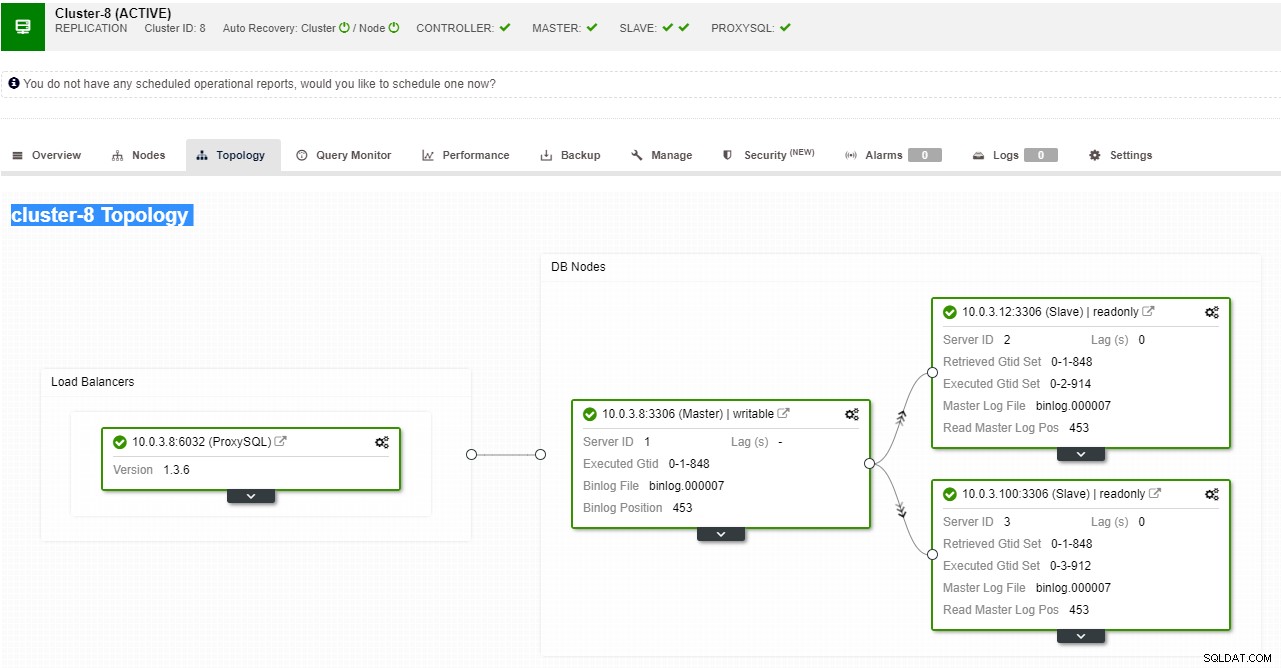 ClusterControlレプリケーショントポロジビュー
ClusterControlレプリケーショントポロジビュー スレーブノードがクラッシュし、サーバーが大幅に遅れている場合は、スレーブサーバーを再構築することをお勧めします。スレーブの再構築プロセスは、バックアップからの復元に似ています。
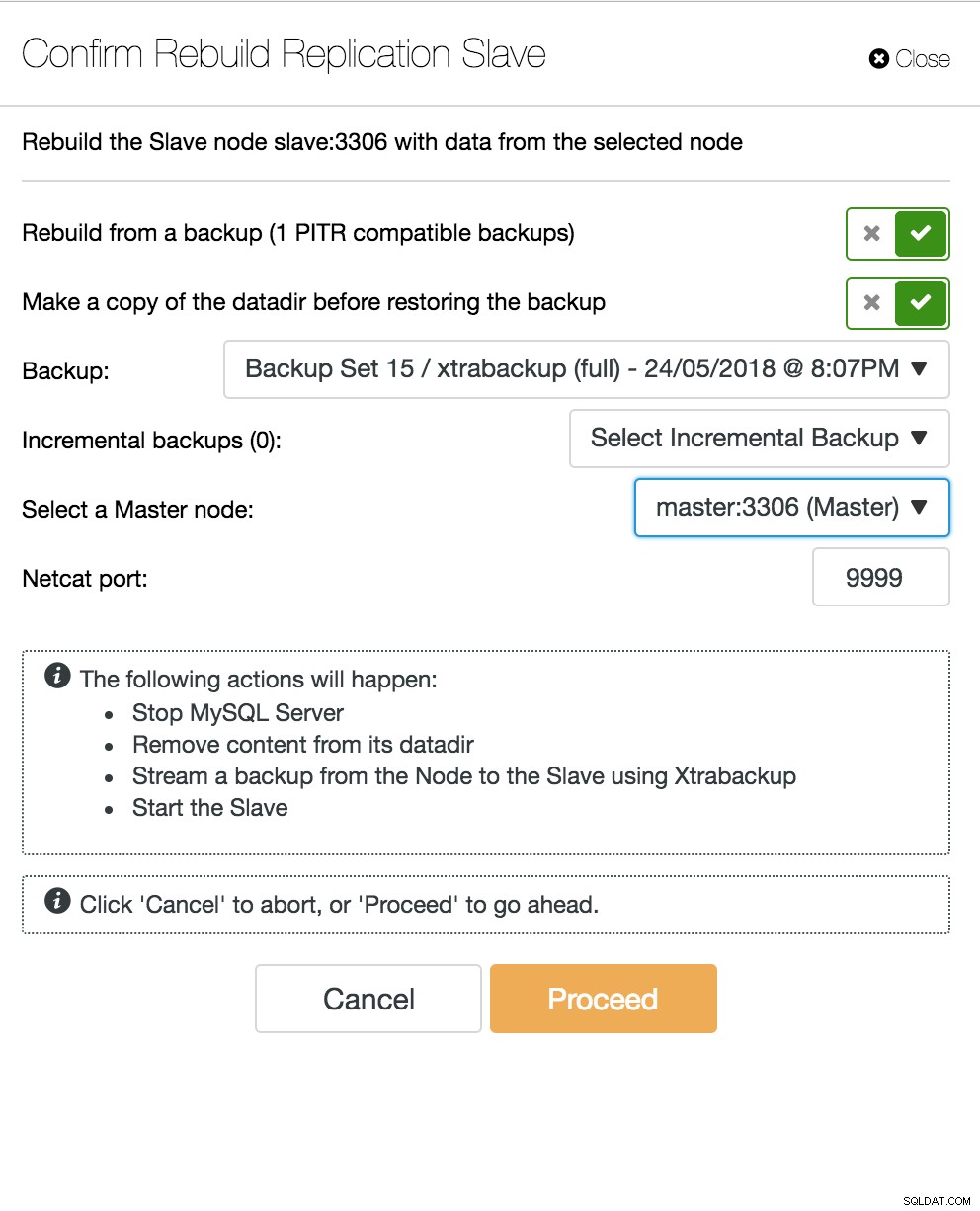 ClusterControl再構築スレーブ
ClusterControl再構築スレーブ データベースマルチマスターサーバーがダウンしました
スレーブサーバーがDRノードとして機能し、フェイルオーバープロセスが十分に自動化されてテストされている場合、DBAの生活はより快適になります。それは本当ですが、解決すべきパズルがさらにいくつかあります。コンピューティング能力は無料ではありません。ビジネスチームからハードウェアの活用を求められる場合があります。スレーブサーバーをパッシブサーバーとしてだけでなく、書き込み操作にも使用することをお勧めします。
次に、マルチマスターレプリケーションソリューションを調査することをお勧めします。 Galera Clusterは、高可用性MySQLおよびMariaDBの主流オプションになりました。現在では、従来のMySQLマスタースレーブアーキテクチャの信頼できる代替品として知られていますが、ドロップインの代替品ではありません。
Galeraクラスターにはシェアードナッシングアーキテクチャがあります。共有ディスクの代わりに、Galeraは、同期レプリケーションを実現するために、グループ通信とトランザクション順序付けを使用した認証ベースのレプリケーションを使用します。データベースクラスターは、さまざまな方法で実現されますが、ノードの損失に耐えられる必要があります。ガレラの場合、重要な側面はノードの数です。ガレラは、運用を維持するために定足数を必要とします。 3ノードのクラスターは、1つのノードのクラッシュに耐えることができます。クラスタ内のノードが増えると、より多くの障害に耐えることができます。
リカバリプロセスは自動化されているため、フェイルオーバー操作を実行する必要はありません。ただし、ノードを強制終了して、ノードをどれだけ早く戻すことができるかを確認することをお勧めします。この操作をより効率的にするために、ガレラキャッシュサイズを変更できます。ガレラキャッシュサイズが適切に計画されていない場合、次の起動ノードは、キャッシュに書き込みセットがないだけでなく、完全バックアップを取る必要があります。
フェイルオーバーのシナリオは、インスタンスを開始するのと同じくらい簡単です。ガレラキャッシュ内のデータに基づいて、起動ノードはSST(完全バックアップからの復元)またはIST(欠落している書き込みセットの適用)を実行します。ただし、これは多くの場合、人間の介入に関連しています。フェイルオーバープロセス全体を自動化する場合は、ClusterControlの自動回復機能(ノードおよびクラスターレベル)を使用できます。
 ClusterControlクラスターの自動回復
ClusterControlクラスターの自動回復 ガレラキャッシュサイズの見積もり:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;フェイルオーバーの一貫性を高めるには、mycnfでgcache.recover=yesを有効にする必要があります。このオプションは、再起動時にガレラキャッシュを復活させます。これは、ノードがDONORとして機能し、欠落している書き込みセットを処理できることを意味します(SSTを使用する代わりにISTを容易にします)。
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3プロキシSQLノードがダウンします
仮想IPを設定している場合は、アプリケーションに仮想IPアドレスを指定するだけで、接続に関してすべてが正しく行われる必要があります。データベースインスタンスを複数のデータセンターにまたがるだけでは不十分です。それらにアクセスするには、アプリケーションが必要です。リードレプリカの数をスケールアウトしたと仮定すると、メンテナンスまたは可用性の理由から、これらのリードレプリカごとに仮想IPを実装することもできます。管理しなければならない仮想IPの面倒なプールになる可能性があります。これらのリードレプリカの1つがクラッシュに直面した場合は、仮想IPを別のホストに再割り当てする必要があります。そうしないと、アプリケーションは、ダウンしているホスト、または最悪の場合、古いデータのある遅れているサーバーに接続します。
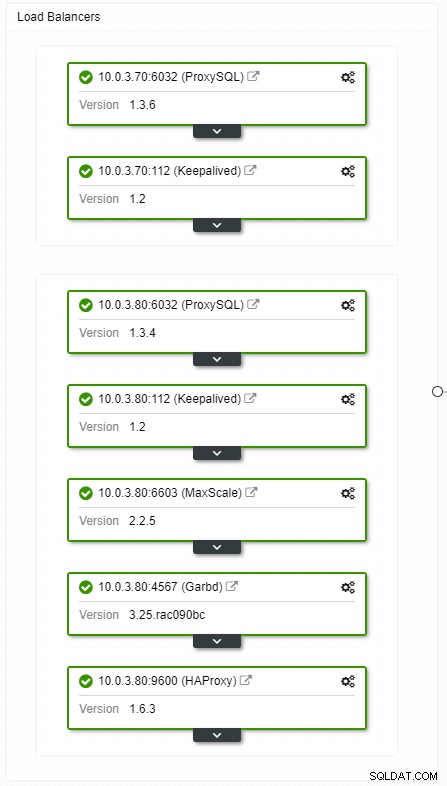 ClusterControlHAロードバランサートポロジビュー
ClusterControlHAロードバランサートポロジビュー クラッシュは頻繁ではありませんが、サーバーがダウンするよりも発生する可能性が高くなります。何らかの理由でスレーブがダウンした場合、ProxySQLのようなものがすべてのトラフィックをマスターにリダイレクトし、過負荷になるリスクがあります。スレーブが回復すると、トラフィックはスレーブにリダイレクトされます。通常、このようなダウンタイムは数分以上かかることはないため、確率も中程度ですが、全体的な重大度は中程度です。
ロードバランサーコンポーネントを冗長化するには、keepalivedを使用できます。
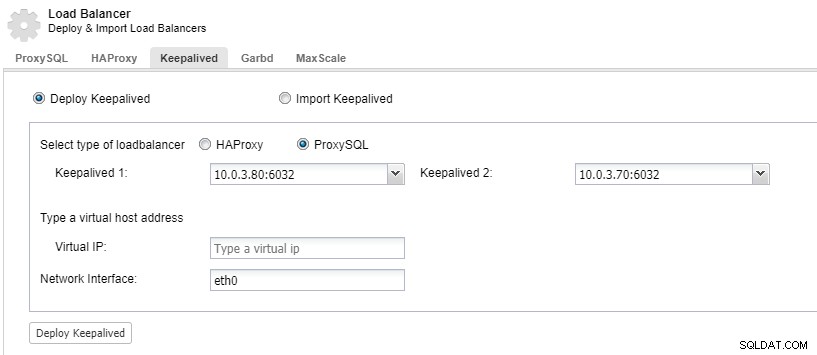 ClusterControl:ProxySQLロードバランサーのキープアライブをデプロイします
ClusterControl:ProxySQLロードバランサーのキープアライブをデプロイします データセンターがダウンする
レプリケーションの主な問題は、データセンターの障害を検出して新しいマスターにサービスを提供するための多数派のメカニズムがないことです。解決策の1つは、Orchestrator/Raftを使用することです。 Orchestratorは、フェイルオーバーを制御できるトポロジスーパーバイザーです。 Raftと一緒に使用すると、Orchestratorはクォーラム対応になります。 Orchestratorインスタンスの1つがリーダーとして選出され、リカバリタスクを実行します。オーケストレーターノード間の接続は、トランザクションデータベースのコミットとは相関関係がなく、まばらです。
Orchestrator / Raftは、トポロジの監視を実行する追加のインスタンスを使用できます。ネットワークパーティショニングの場合、パーティショニングされたOrchestratorインスタンスは何のアクションも実行しません。クォーラムを持つOrchestratorクラスターの一部は、新しいマスターを選出し、必要なトポロジ変更を行います。
ClusterControlは、管理、スケーリング、そして最も重要なノードのリカバリに使用されます。Orchestratorはフェイルオーバーを処理しますが、スレーブがクラッシュした場合、ClusterControlは確実にリカバリされます。 OrchestratorとClusterControlは、MySQLノードから分離された同じアベイラビリティーゾーンに配置され、データセンター内のアベイラビリティーゾーン間のネットワーク分割によってアクティビティが影響を受けないようにします。