HAトポロジの選択
データベースで高可用性を維持するには、さまざまな方法があります。仮想IP(VRRP)を使用してホストの可用性を管理したり、ZookeeperやEtcdなどのリソースマネージャーを使用してアプリケーションを(再)構成したり、ロードバランサー/プロキシを使用して使用可能なすべてのホストにワークロードを分散したりできます。
仮想IPには、それらを管理するアプリケーション(MHA、Orchestrator)、スクリプト(Keepalived、Pacemaker / Corosync)、または手動でフェイルオーバーするエンジニアのいずれかが必要であり、プロセスの意思決定が複雑になる可能性があります。仮想IPフェイルオーバーは、あるホストからIPアドレスを削除し、それを別のホストに割り当て、arpingを使用して無償のARP応答を送信することにより、単純で単純なプロセスです。理論的には、仮想IPは1秒で移動できますが、フェイルオーバー管理アプリケーションがホストに障害が発生し、それに応じて動作することを確認するまでに数秒かかります。実際には、これは10〜30秒の間にあるはずです。仮想IPのもう1つの制限は、一部のクラウドプロバイダーでは、独自の仮想IPを管理したり、割り当てたりすることをまったく許可していないことです。たとえば、Googleではコンピューティングノードでこれを行うことは許可されていません。
ZookeeperやEtcdなどのリソースマネージャーは、ホストに障害が発生したり、スレーブがマスターに昇格したりすると、データベースを監視し、アプリケーションを(再)構成できます。一般に、これは良い考えですが、ZookeeperとEtcdを使用してチェックを実装するのは複雑な作業です。
ロードバランサーまたはプロキシは、アプリケーションとデータベースホストの間に配置され、クライアントがデータベースホストに直接接続するかのように透過的に機能します。仮想IPおよびリソースマネージャーの場合と同様に、ロードバランサーとプロキシもホストを監視し、1つのホストがダウンした場合にトラフィックをリダイレクトする必要があります。 ClusterControlは、HAProxyとProxySQLの2つのプロキシをサポートしており、どちらもMySQLマスタースレーブレプリケーションとGaleraクラスターでサポートされています。 HAProxyとProxySQLにはどちらも独自のユースケースがあり、この投稿でも説明します。
なぜロードバランサーが必要なのですか?
理論的にはロードバランサーは必要ありませんが、実際にはロードバランサーを使用することをお勧めします。理由を説明します。
仮想IPを設定している場合は、アプリケーションに正しい(仮想)IPアドレスを指定するだけで、すべてが正常に接続されます。ただし、リードレプリカの数をスケールアウトした場合、メンテナンスまたは可用性の理由から、これらのリードレプリカのそれぞれに仮想IPを提供することもできます。これは、管理する必要のある仮想IPの非常に大きなプールになる可能性があります。これらのリードレプリカの1つに障害が発生した場合は、仮想IPを別のホストに再割り当てする必要があります。そうしないと、アプリケーションは、ダウンしているホスト、または最悪の場合、古いデータを含む遅延サーバーに接続します。したがって、仮想IPを管理するアプリケーションへのレプリケーション状態を維持する必要があります。
Galeraにも同様の課題があります。理論的には、アプリケーション構成に必要な数のホストを追加して、ランダムに1つ選択することができます。このホストがダウンしている場合にも同じ問題が発生します。使用できないホストに接続してしまう可能性があります。また、読み取りと書き込みの両方にすべてのホストを使用すると、Galeraの楽観的なロックが原因でロールバックが発生する可能性があります。 2つの接続が同時に同じ行に書き込もうとすると、そのうちの1つがロールバックを受け取ります。ワークロードにそのような同時更新がある場合は、Galeraの1つのノードのみを使用して書き込むことをお勧めします。したがって、データベースクラスターの内部状態を追跡するマネージャーが必要です。
HAProxyとProxySQLはどちらも、MySQL / MariaDBデータベースホストを監視し、クラスターとそのトポロジーの状態を維持する機能を提供します。レプリケーション設定の場合、スレーブレプリカがダウンした場合、HAProxyとProxySQLの両方が接続を別のホストに再配布できます。ただし、レプリケーションマスターがダウンしている場合、HAProxyは接続を拒否し、ProxySQLはクライアントに適切なエラーを返します。 Galeraセットアップの場合、両方のロードバランサーがGaleraクラスターからマスターノードを選択し、その特定のノードにのみ書き込み操作を送信できます。
一見すると、HAProxyとProxySQLは似たようなソリューションのように見えるかもしれませんが、機能や接続とクエリの分散方法が大きく異なります。 HAProxyは、最小接続、ソース、ランダム、ラウンドロビンなどの多数のバランシングアルゴリズムをサポートしますが、ProxySQLは、重みベースのラウンドロビンアルゴリズムを使用して接続を分散します(等しい重みは等しい分散を意味します)。 ProxySQLはインテリジェントプロキシであるため、データベースを認識し、クエリを分析することもできます。 ProxySQLは、クエリルールに基づいて読み取り/書き込み分割を実行できます。この場合、クエリをクラスタ内の指定されたスレーブまたはマスターに転送できます。 ProxySQLには、クエリの書き換え、キャッシュ、クエリファイアウォールなどの追加機能が含まれており、ワークロードに関するリアルタイムの詳細な統計が生成されます。
これで、このトピックに関する十分な背景情報が得られるはずです。そこで、MySQLレプリケーションとGaleraトポロジの両方のロードバランサーをデプロイする方法を見てみましょう。
HAProxyのデプロイ
ClusterControlを使用してGaleraクラスターにHAProxyをデプロイするのは簡単です。関連するクラスターに移動し、[ロードバランサーの追加]を選択します。
また、ホストアドレスを追加し、構成に含めるサーバーインスタンスを選択することで、HAProxyインスタンスをデプロイできます。
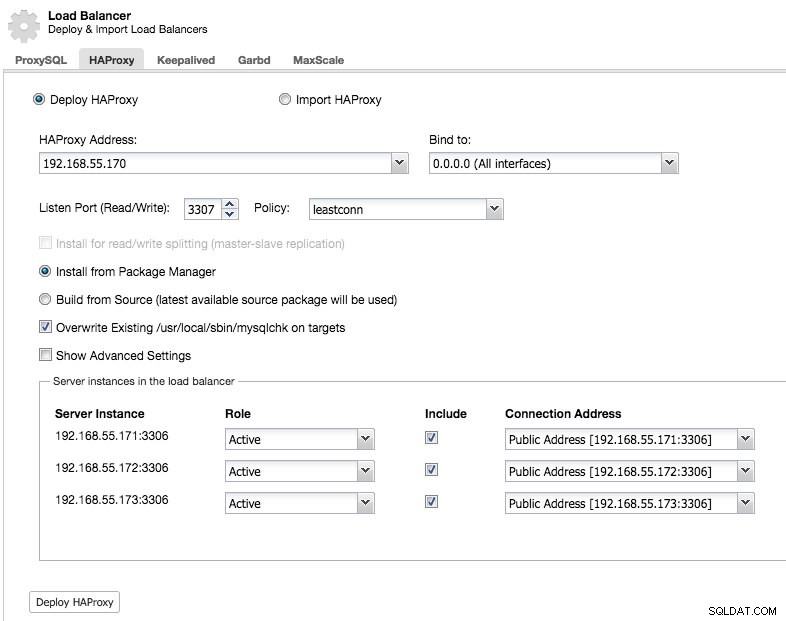
デフォルトでは、HAProxyインスタンスは、接続数が最も少ないサーバーインスタンスに接続を送信するように構成されますが、そのポリシーをラウンドロビンまたはソースのいずれかに変更できます。
詳細設定では、タイムアウト、接続の最大数を設定し、接続のIP範囲をホワイトリストに登録してプロキシを保護することもできます。
そのクラスターの[ノード]タブの下に、HAProxyノードが表示されます。
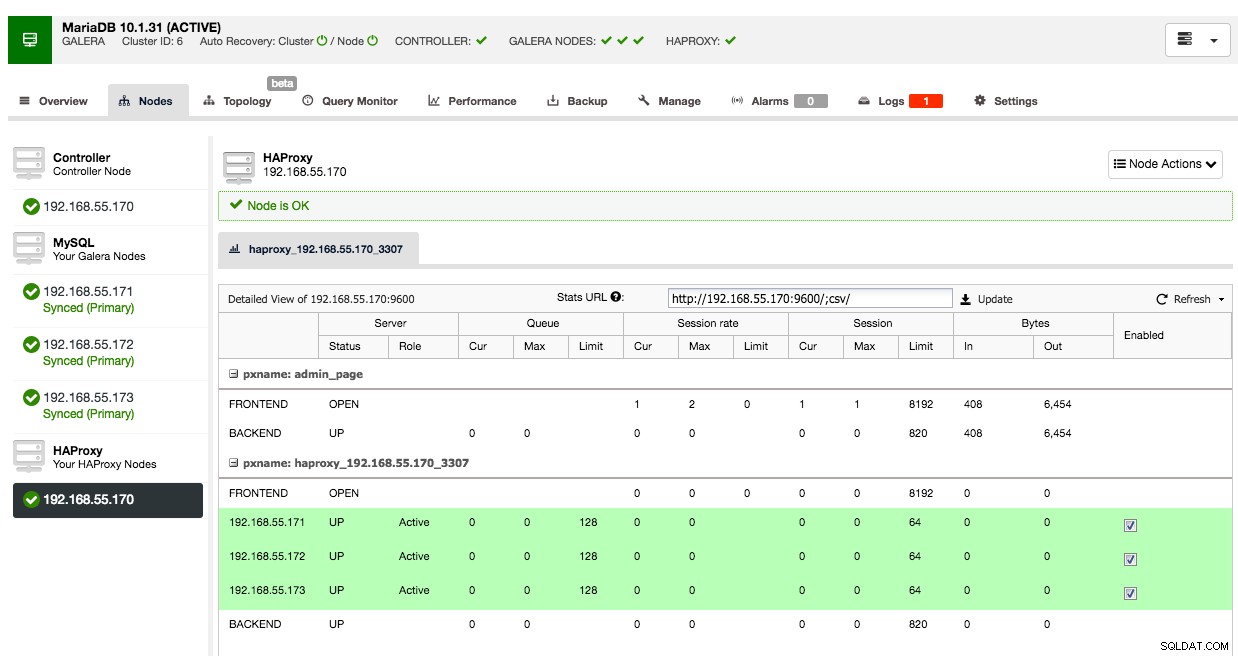
これで、Galeraクラスターはポート3307に新しくデプロイされたHAProxyノードを介して利用できるようになります。トラフィックはアプリケーションホストではなくプロキシから着信するため、HAProxyIPからのアプリケーションアクセスを許可することを忘れないでください。また、アプリケーション接続をHAProxyノードに向けることを忘れないでください。
ここで、1つのサーバーインスタンスがダウンすると、HAProxyは数秒以内にこれに気づき、このインスタンスへのトラフィックの送信を停止します。
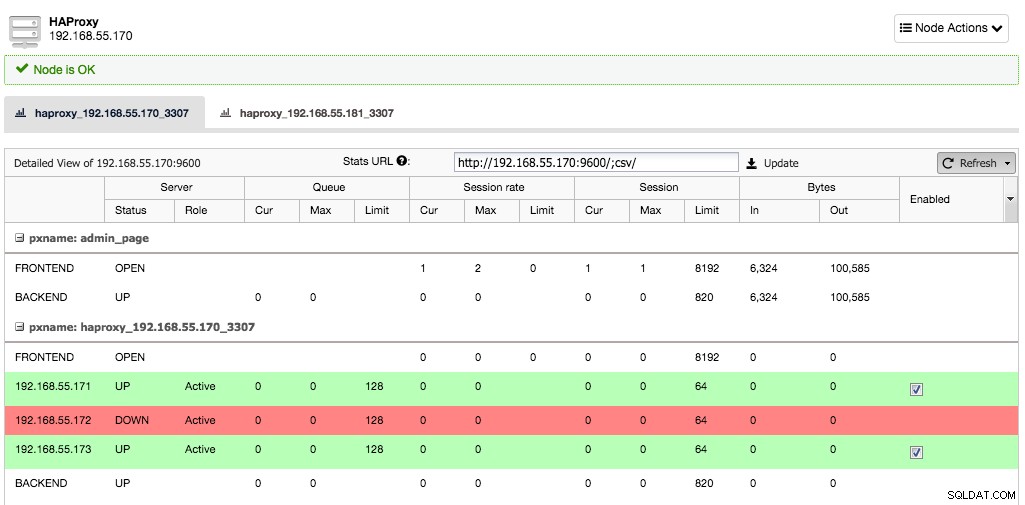
他の2つのノードは引き続き正常であり、トラフィックを受信し続けます。これにより、クライアントが違いに気付くことなく、クラスターの高可用性が維持されます。
セカンダリHAProxyノードのデプロイ
データベース接続で高可用性を維持する責任をクライアントからHAProxyに移したので、プロキシノードが停止した場合はどうなりますか?答えは、次の図に示すように、別のHAProxyインスタンスを作成し、Keepalivedによって制御される仮想IPを使用することです。
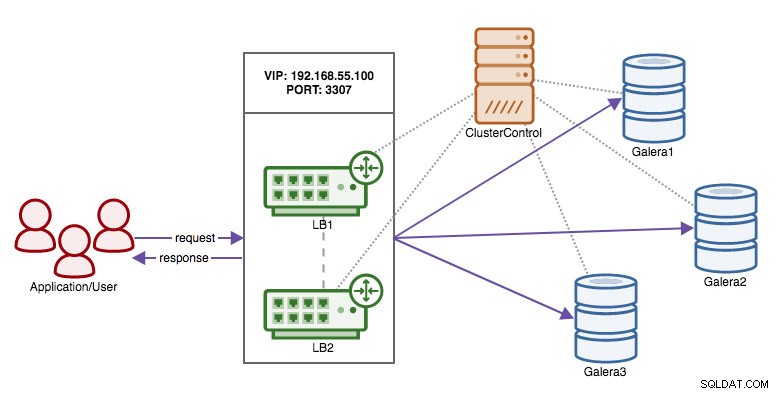
データベースノードで仮想IPを使用する場合と比較した場合の利点は、MySQLのロジックがプロキシレベルであり、プロキシのフェイルオーバーが簡単なことです。
それでは、セカンダリHAProxyノードをデプロイしましょう:
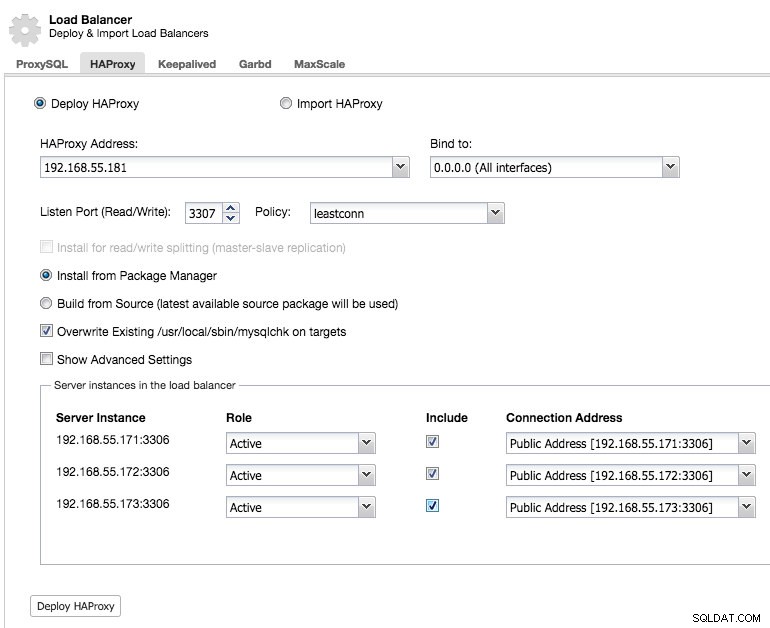
セカンダリHAProxyノードをデプロイした後、Keepalivedを追加する必要があります:
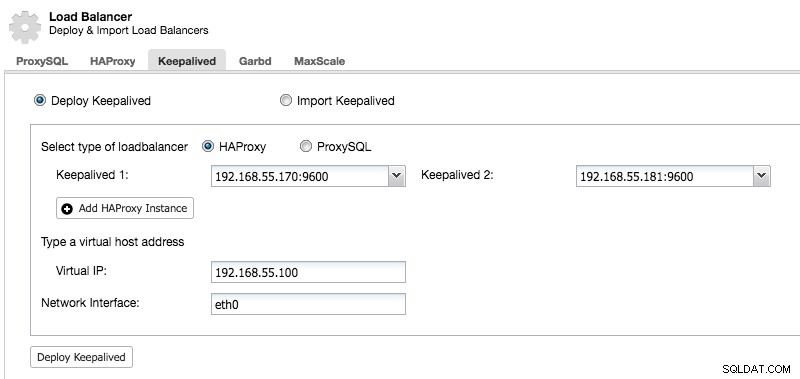
キープアライブが追加されると、ノードの概要は次のようになります。
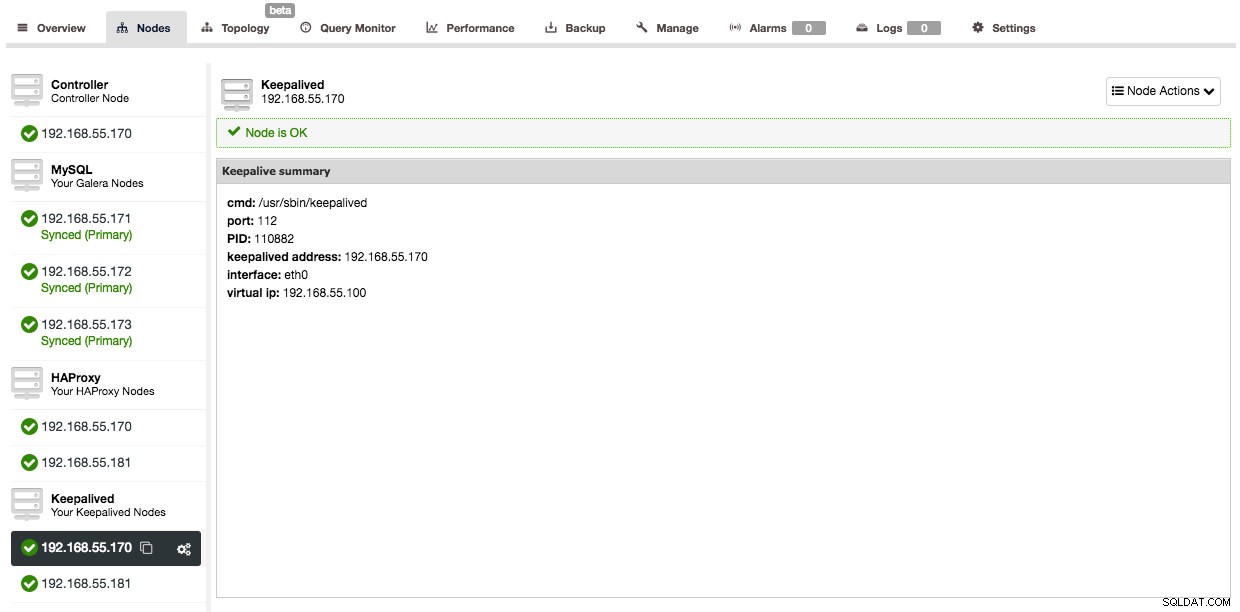
したがって、アプリケーション接続をHAProxyノードに直接ポイントする代わりに、仮想IPをポイントする必要があります。
この例では、別々のホストを使用してHAProxyを実行しましたが、既存のサーバーインスタンスにそれらを簡単に追加することもできます。 HAProxyはそれほどオーバーヘッドをもたらしませんが、サーバーに障害が発生した場合、データベースノードとプロキシの両方が失われることに注意する必要があります。
ProxySQLの導入
ProxySQLのクラスターへのデプロイは、HAProxyと同様の方法で行われます:ProxySQLタブの下のクラスターリストの「ロードバランサーの追加」。
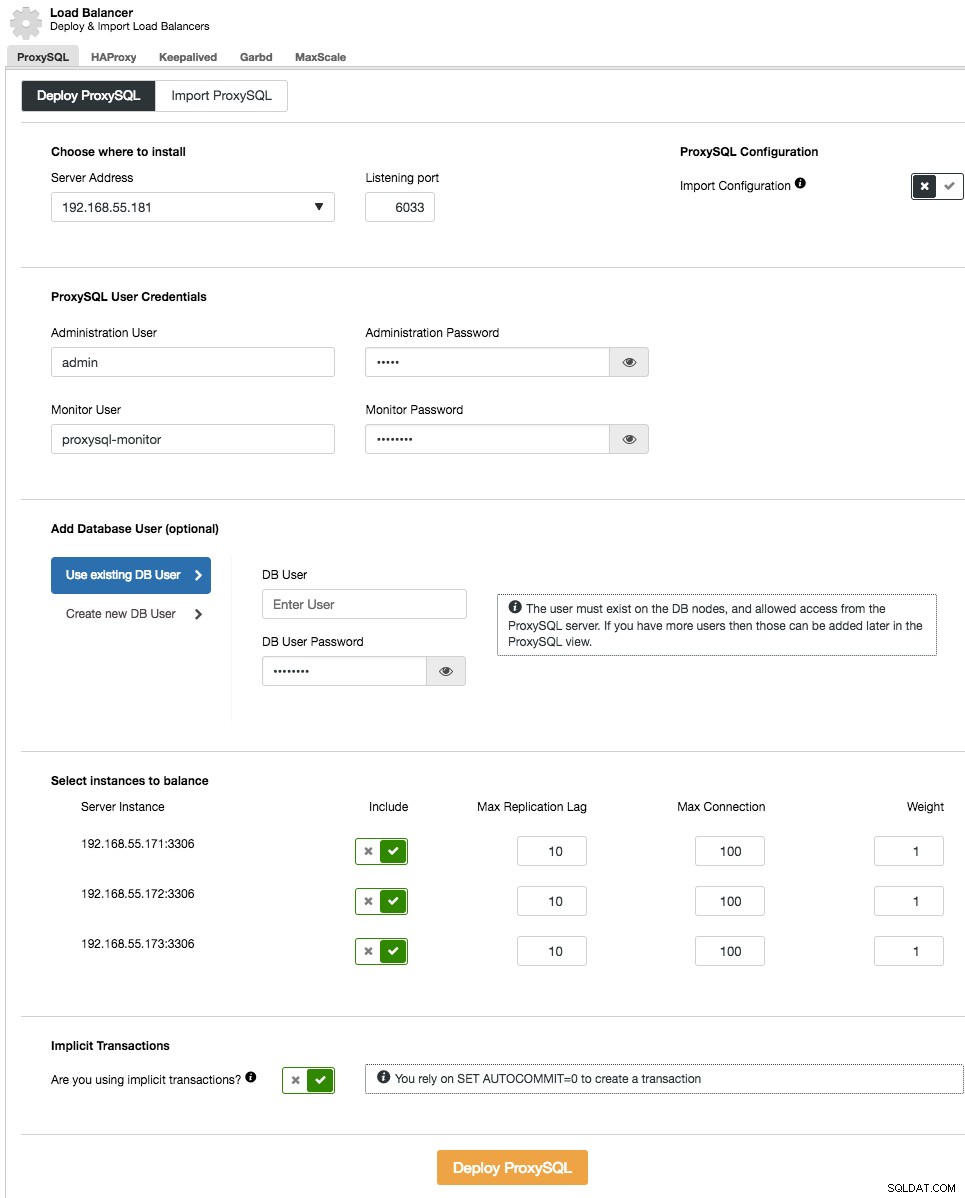
デプロイメントウィザードで、ProxySQLをインストールする場所、管理ユーザー/パスワード、MySQLバックエンドに接続するための監視ユーザー/パスワードを指定します。 ClusterControlから、アプリケーションで使用する新しいユーザーを作成するか(ユーザーはMySQLとProxySQLの両方で作成されます)、既存のデータベースユーザーを使用できます(ユーザーはProxySQLでのみ作成されます)。暗黙のトランザクションを使用しているかどうかを設定します。基本的に、SET autocommit =0を使用して新しいトランザクションを作成しない場合、ClusterControlは読み取り/書き込み分割を構成します。
ProxySQLがデプロイされると、[ノード]タブで使用できるようになります:
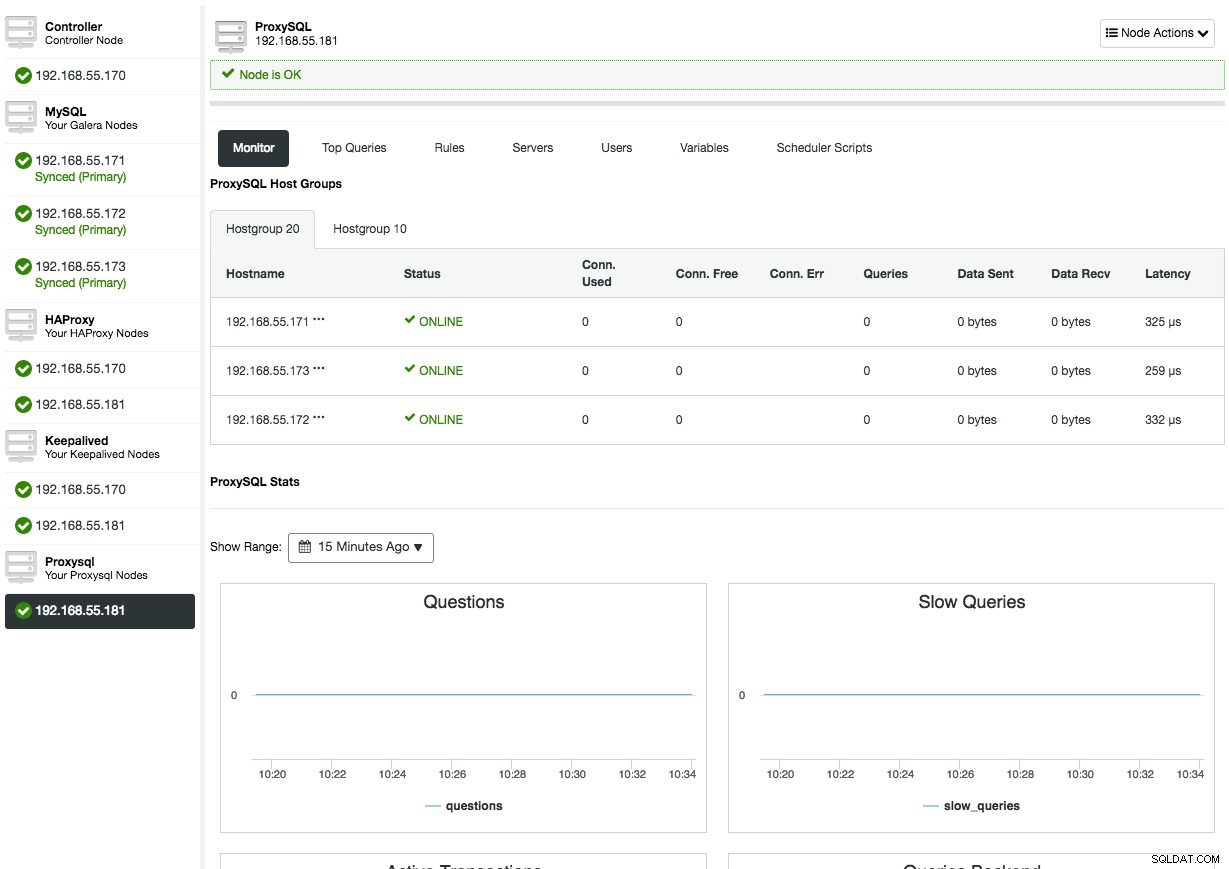
ProxySQLノードの概要を開くと、ProxySQLの監視および管理インターフェイスが表示されるため、ノードでProxySQLにログインする必要はありません。 ClusterControlは、メモリ使用率、クエリキャッシュ、クエリプロセッサなどのほとんどのProxySQLの重要な統計情報に加えて、ホストグループ、バックエンドサーバー、クエリルールのヒット、上位のクエリ、ProxySQL変数などの他の指標をカバーします。 ProxySQL管理の側面では、UIから直接、クエリルール、バックエンドサーバー、ユーザー、構成、およびスケジューラを管理できます。
ProxySQLを使用してMySQLおよびMariaDBのデータベース負荷分散を実行する方法について詳しく説明しているProxySQLチュートリアルページを確認してください。
Garbdの導入
Galeraは、クォーラムベースのアルゴリズムを実装して、一貫性を強制する主要コンポーネントを選択します。主要コンポーネントは過半数の投票(50%+ 1ノード)を持つ必要があるため、2ノードシステムでは、過半数がないためにスプリットブレインが発生します。幸い、garbd(Galera Arbitrator Daemon)を追加することができます。これは、奇数ノードとして機能できる軽量のステートレスデーモンです。 Galera Arbitratorを追加することによる追加の利点は、クラスター内の2つのノードのみで実行できることです。
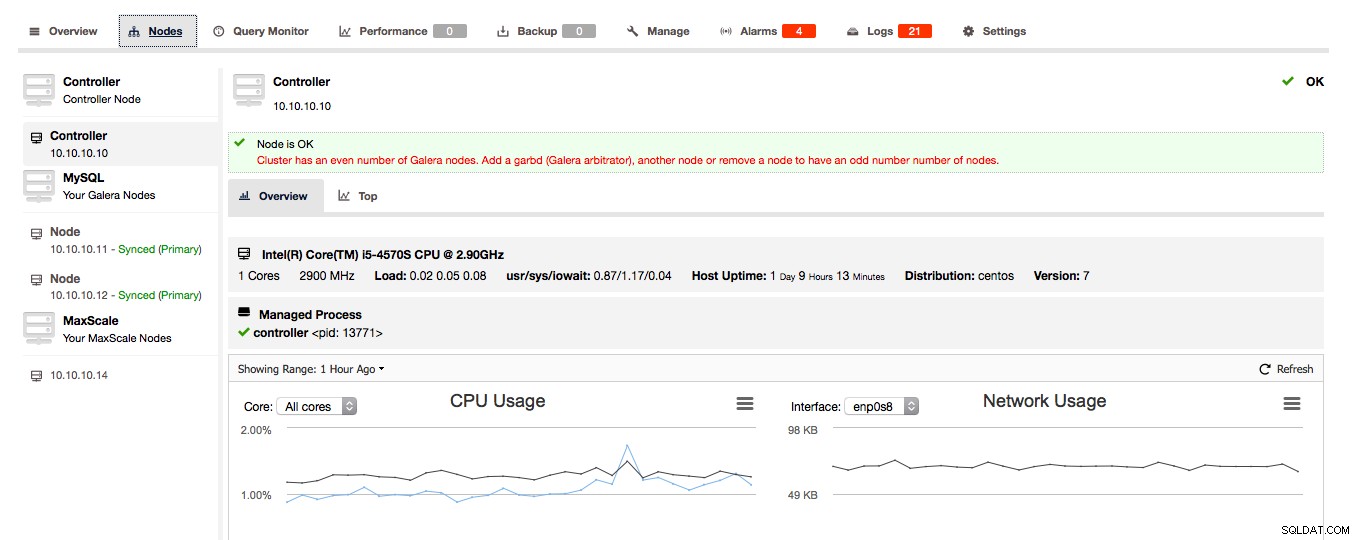
ClusterControlがGaleraクラスターが偶数のノードで構成されていることを検出した場合、クラスターを奇数のノードに拡張するようにClusterControlから警告/アドバイスが表示されます。
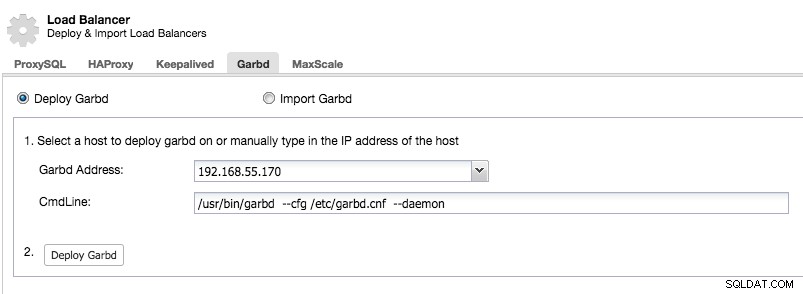
garbdをデプロイするホストを賢明に選択してください。これは、複製されたすべてのデータを受信するためです。ネットワークがトラフィックを処理でき、十分に安全であることを確認してください。以下の例のように、garbdをデプロイするHAProxyまたはProxySQLホストのいずれかを選択できます。
ClusterControl 1.5.1以降では、パッケージの競合のリスクがあるため、garbdをClusterControlと同じホストにインストールできないことに注意してください。
garbdをインストールすると、2つのGaleraノードの横に表示されます。

最終的な考え
HAProxyとProxySQLを使用して、MySQLマスタースレーブとGaleraクラスターのセットアップをより堅牢にし、高可用性を維持する方法を示しました。また、garbdは、Galeraクラスターに余分な3番目のノードを保存できる優れたデーモンです。
これにより、ClusterControlの展開側が完成します。次のブログでは、グループを使用して特定の役割をユーザーに割り当てることにより、ClusterControlを組織内に統合する方法を紹介します。