前回の投稿では、ホワイトリストとブラックリストを利用してClusterControlでフェイルオーバープロセスを制御する方法について説明しました。この投稿では、同様の概念について説明します。ただし、今回は、ClusterControlによって利用可能になった多数のフックを介した外部スクリプトおよびアプリケーションとの統合に焦点を当てます。
インフラストラクチャ環境はさまざまな方法で構築できます。多くの場合、パズルの特定のピースに対して選択できるオプションが多数あります。書き込むデータベースノードをどのように定義しますか?仮想IPを使用していますか?ある種のサービスディスカバリを使用していますか?たぶん、DNSエントリを使用して、必要に応じてAレコードを変更しますか?プロキシレイヤーはどうですか?プロキシの「read_only」値を使用してライターを決定しますか、それともプロキシの構成で必要な変更を直接行いますか?ご使用の環境はスイッチオーバーをどのように処理しますか?先に進んで実行することはできますか、それとも事前にいくつかの予備的なアクションを実行する必要がありますか?たとえば、実際に切り替える前に他のプロセスを停止しますか?
フェイルオーバーソフトウェアを事前構成して、ユーザーが作成できるさまざまなセットアップをすべてカバーすることはできません。これが、フェイルオーバープロセスにフックするさまざまな方法を提供する主な理由です。このようにして、それをカスタマイズし、セットアップのすべての微妙な点を処理できるようにすることができます。このブログ投稿では、さまざまなフェイルオーバー前およびフェイルオーバー後のスクリプトを使用して、ClusterControlのフェイルオーバープロセスをカスタマイズする方法について説明します。また、このようなカスタマイズで実現できることの例についても説明します。
ClusterControlの統合
ClusterControlは、外部スクリプトをプラグインするために使用できるいくつかのフックを提供します。以下に、説明付きのリストを示します。
- Replication_onfail_failover_script-このスクリプトは、フェイルオーバーが必要であることが検出されるとすぐに実行されます。スクリプトがゼロ以外を返す場合、フェイルオーバーは強制的に中止されます。スクリプトが定義されているのに見つからない場合、フェイルオーバーは中止されます。スクリプトには4つの引数が提供されます:arg1='すべてのサーバー'arg2='oldmaster' arg3 ='candidate'、arg4 ='oldmasterのスレーブ'そして次のように渡されます:' scripname arg1 arg2arg3arg4'。スクリプトは、コントローラーでアクセス可能であり、実行可能である必要があります。
- Replication_pre_failover_script-このスクリプトは、フェイルオーバーが発生する前に実行されますが、候補が選出された後、フェイルオーバープロセスを続行できます。スクリプトがゼロ以外を返す場合、フェイルオーバーは強制的に中止されます。スクリプトが定義されているのに見つからない場合、フェイルオーバーは中止されます。スクリプトは、コントローラーでアクセス可能であり、実行可能である必要があります。
- Replication_post_failover_script-このスクリプトは、フェイルオーバーが発生した後に実行されます。スクリプトがゼロ以外を返す場合、警告がジョブログに書き込まれます。スクリプトは、コントローラーでアクセス可能であり、実行可能である必要があります。
- Replication_post_unsuccessful_failover_script-このスクリプトは、フェイルオーバーの試行が失敗した後に実行されます。スクリプトがゼロ以外を返す場合、警告がジョブログに書き込まれます。スクリプトは、コントローラーでアクセス可能であり、実行可能である必要があります。
- Replication_failed_reslave_failover_script-このスクリプトは、新しいマスターが昇格された後、新しいマスターへのスレーブの再スレーブが失敗した場合に実行されます。スクリプトがゼロ以外を返す場合、警告がジョブログに書き込まれます。スクリプトは、コントローラーでアクセス可能であり、実行可能である必要があります。
- Replication_pre_switchover_script-このスクリプトは、切り替えが発生する前に実行されます。スクリプトがゼロ以外を返す場合、スイッチオーバーは強制的に失敗します。スクリプトが定義されているのに見つからない場合、スイッチオーバーは中止されます。スクリプトは、コントローラーでアクセス可能であり、実行可能である必要があります。
- Replication_post_switchover_script-このスクリプトは、切り替えが発生した後に実行されます。スクリプトがゼロ以外を返す場合、警告がジョブログに書き込まれます。スクリプトは、コントローラーでアクセス可能であり、実行可能である必要があります。
ご覧のとおり、フックは、スイッチオーバーの前後、フェイルオーバーの前後、再スレーブが失敗したとき、またはフェイルオーバーが失敗したときに、いくつかのアクションを実行する必要があるほとんどの場合をカバーします。すべてのスクリプトは、4つの引数で呼び出されます(スクリプトで処理される場合とされない場合があります。スクリプトがそれらすべてを利用する必要はありません):すべてのサーバー、ホスト名(または、ClusterControlで定義されているIP)古いマスターの、マスター候補のホスト名(または、ClusterControlで定義されているIP)と4番目のホスト名(古いマスターのすべてのレプリカ)。これらのオプションにより、ほとんどのケースを処理できるようになります。
これらのフックはすべて、特定のクラスターの構成ファイル(/etc/cmon.d/cmon_X.cnf、XはクラスターのID)で定義する必要があります。例は次のようになります:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shもちろん、呼び出されたスクリプトは実行可能である必要があります。そうしないと、cmonはそれらを実行できません。ここで少し時間を取って、ClusterControlのフェイルオーバープロセスを実行し、外部スクリプトがいつ実行されるかを確認しましょう。
ClusterControlのフェイルオーバープロセス
使用可能なすべてのフックを定義しました:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shこの後、cmonプロセスを再開する必要があります。完了したら、フェイルオーバーをテストする準備が整います。元のトポロジは次のようになります:
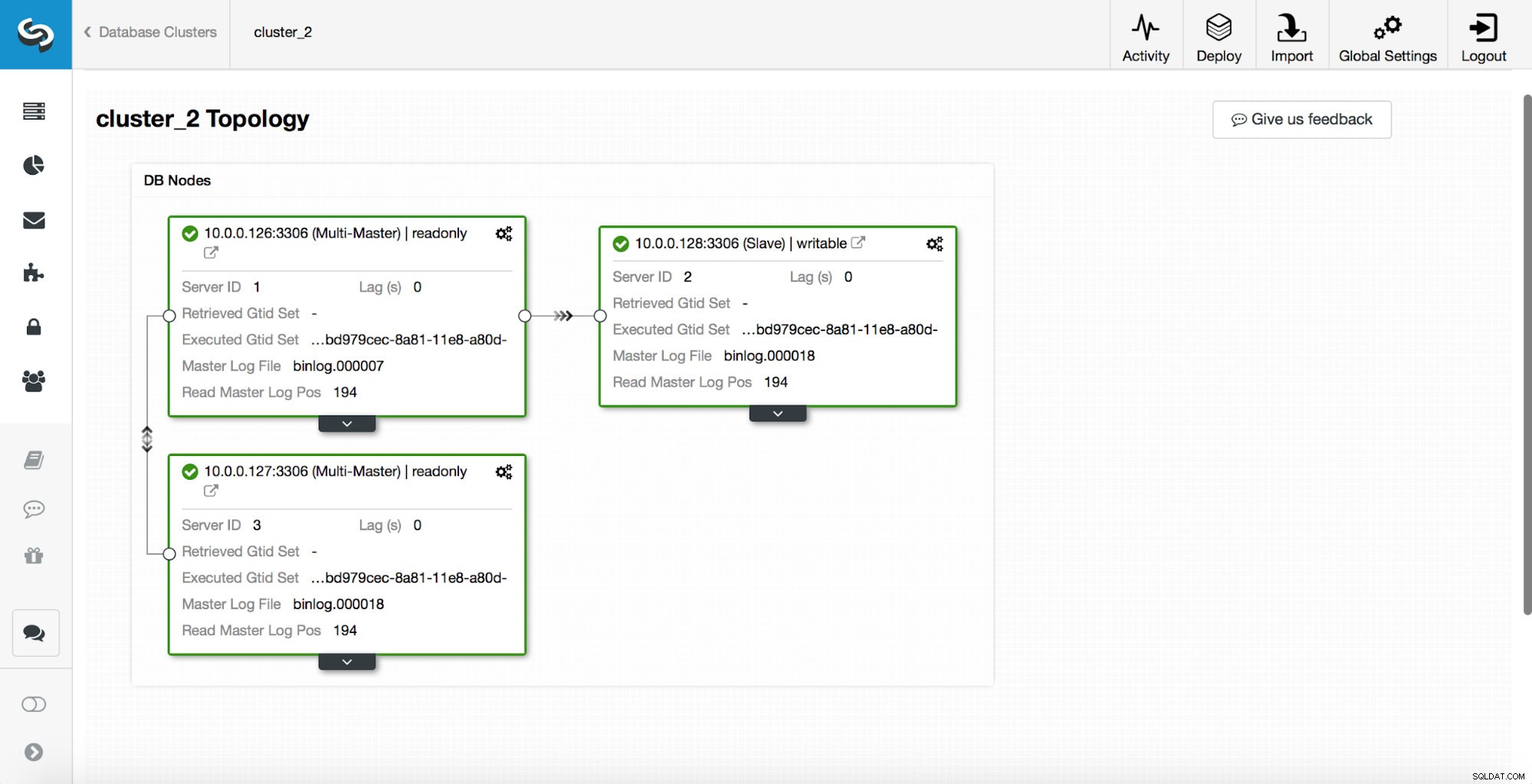
マスターが強制終了され、フェイルオーバープロセスが開始されました。最新のログエントリが上部にあるため、フェイルオーバーを下から上に追跡する必要があることに注意してください。
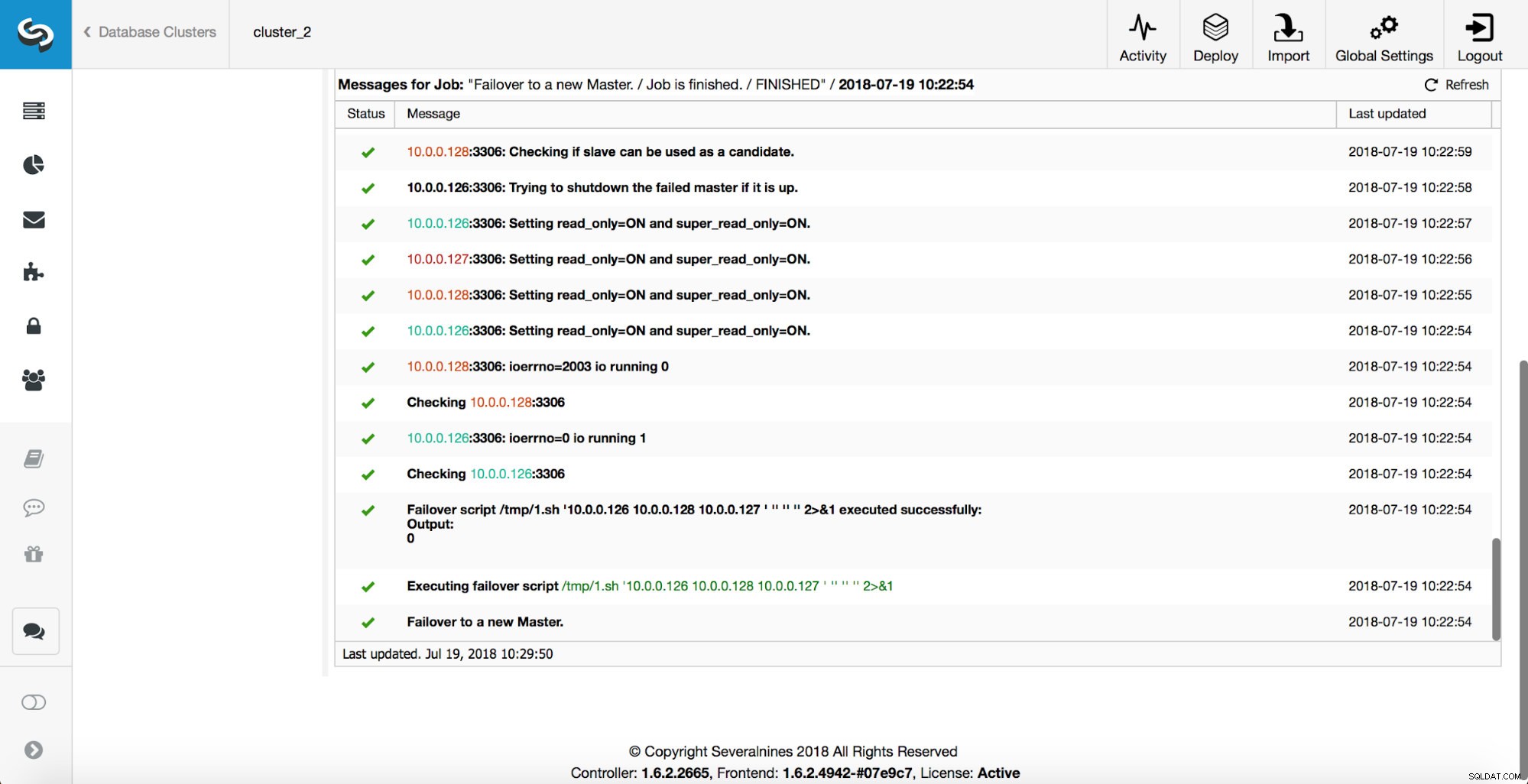
ご覧のとおり、フェイルオーバージョブが開始された直後に、「replication_onfail_failover_script」フックがトリガーされます。次に、到達可能なすべてのホストがread_onlyとしてマークされ、ClusterControlは古いマスターの実行を阻止しようとします。
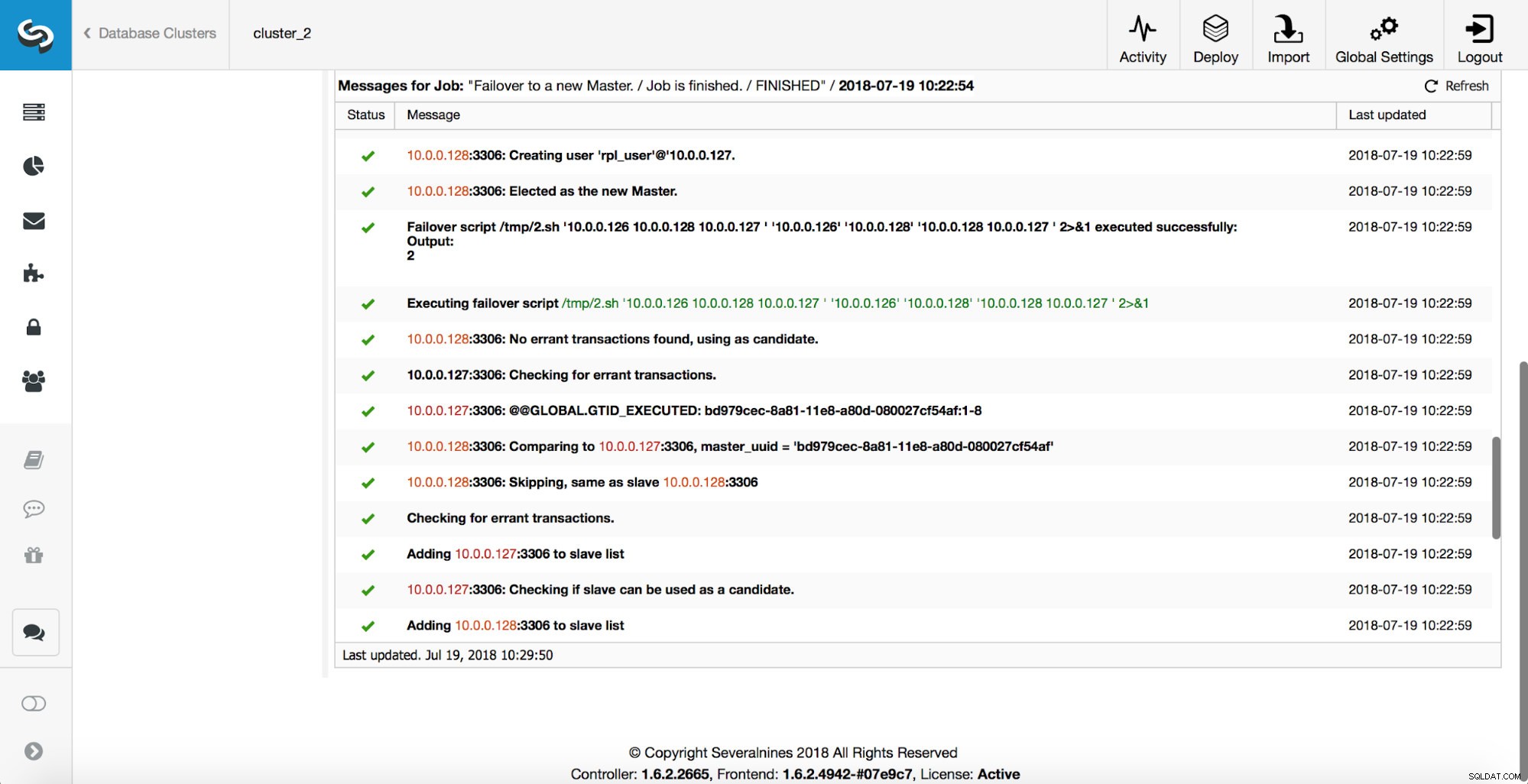
次に、マスター候補が選択され、健全性チェックが実行されます。マスター候補を新しいマスターとして使用できることが確認されると、「replication_pre_failover_script」が実行されます。
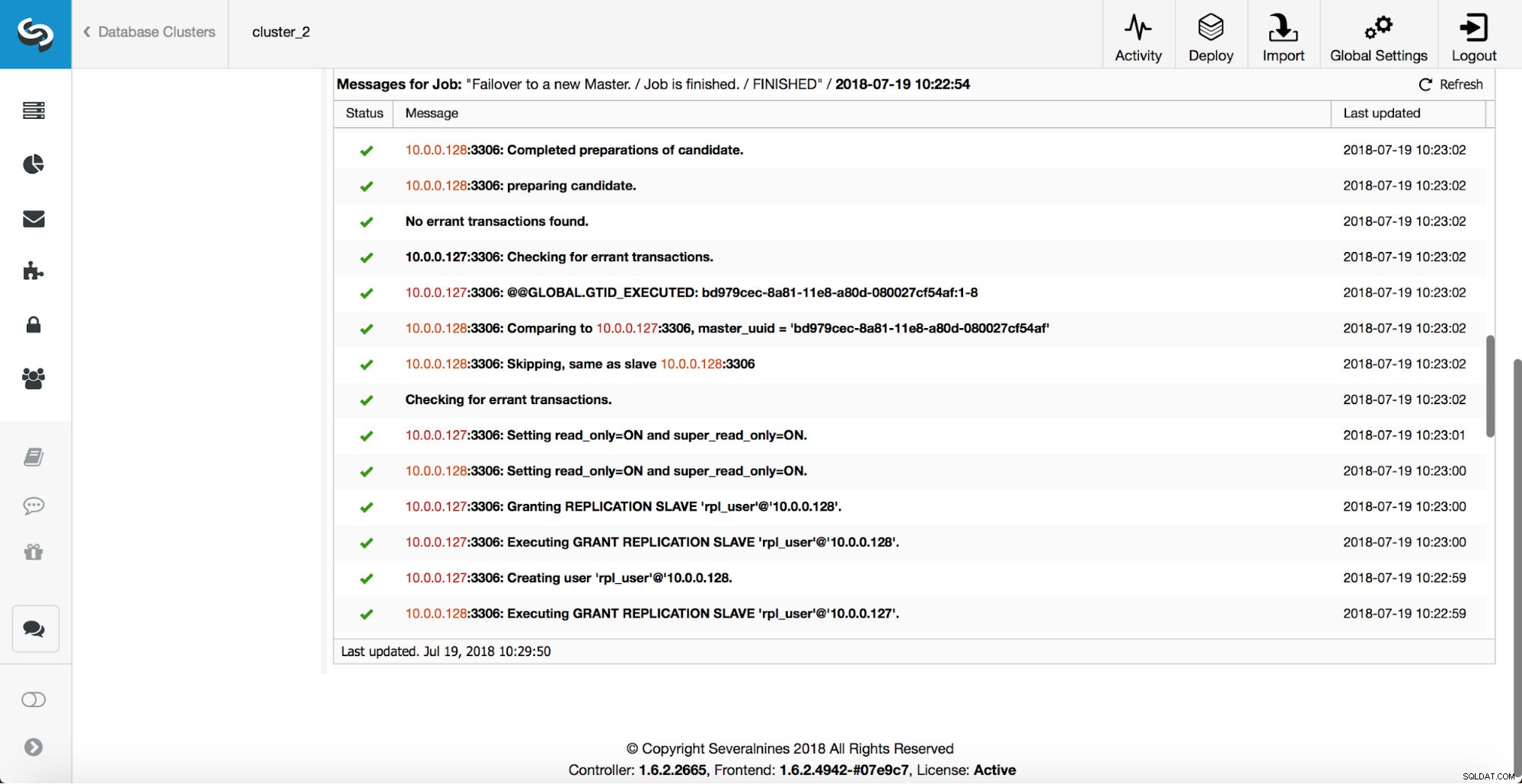
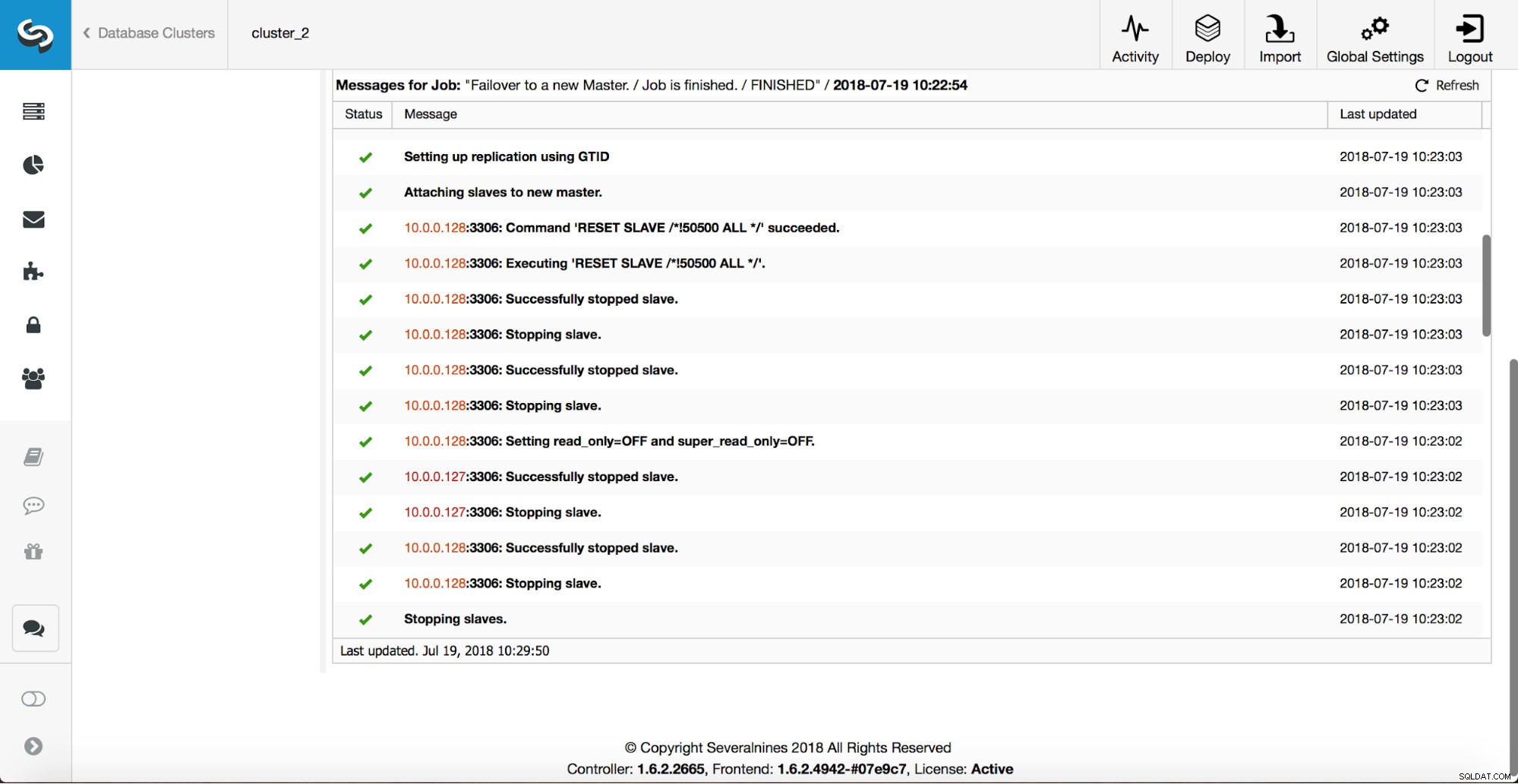
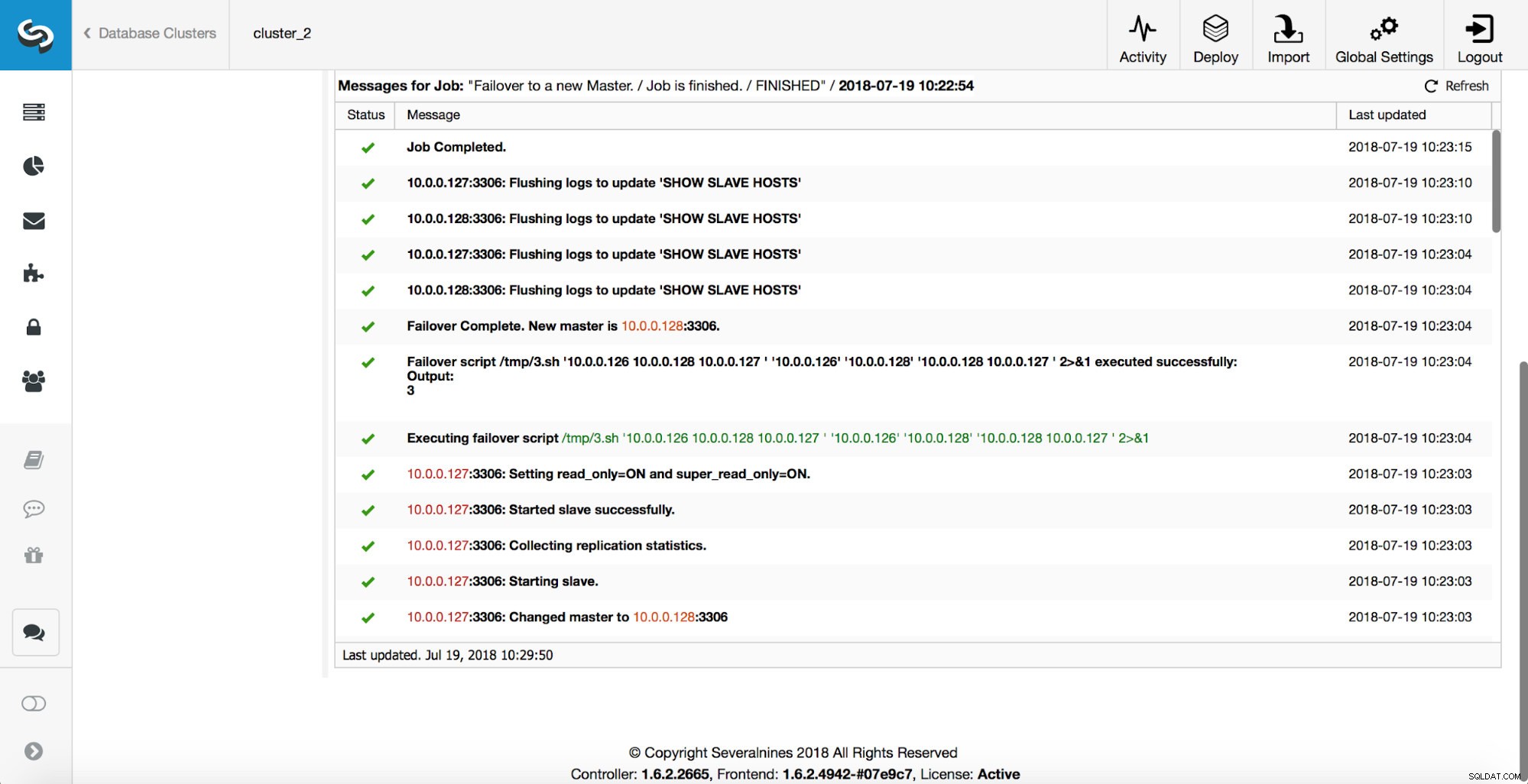
さらにチェックが実行され、レプリカが停止され、新しいマスターからスレーブ化されます。最後に、フェイルオーバーが完了した後、最後のフック「replication_post_failover_script」がトリガーされます。
フックが役立つのはいつですか?
このセクションでは、外部スクリプトを実装することをお勧めするいくつかの例を紹介します。特定の環境との関連性が高すぎるため、詳細については説明しません。実装に役立つ可能性のある提案のリストになります。
STONITHスクリプト
頭の中の他のノードを撃つ(STONITH)は、死んでいる古いマスターが死んでいることを確認するプロセスです(そして、そうです。私たちは、ゾンビがインフラストラクチャ内を歩き回るのは好きではありません)。おそらく最後に必要なのは、応答しない古いマスターがオンラインに戻り、その結果、書き込み可能なマスターが2つになることです。古いマスターが再び表示されても使用されないようにするための予防措置があり、オフラインのままにしておく方が安全です。それを確実にする方法は、環境ごとに異なります。したがって、ほとんどの場合、フェイルオーバーツールにSTONITHの組み込みサポートはありません。環境によっては、CLIコマンドを実行して、古いマスターが実行されているVMを停止(さらには削除)することもできます。オンプレミス設定を使用している場合は、ハードウェアをより細かく制御できる場合があります。ある種のリモート管理(統合されたLights-outまたはサーバーへの他のリモートアクセス)を利用できる場合があります。また、管理可能な電源ソケットにアクセスし、そのうちの1つで電源をオフにして、人間の介入なしにサーバーが再起動しないようにすることもできます。
サービスディスカバリ
サービスディスカバリについてはすでに少し触れました。レプリケーショントポロジに関する情報を保存し、どのホストがマスターであるかを検出する方法は多数あります。間違いなく、最も一般的なオプションの1つは、etc.dまたはConsulを使用して現在のトポロジに関するデータを保存することです。これにより、アプリケーションまたはプロキシはこのデータに依存して、トラフィックを正しいノードに送信できます。 ClusterControl(フェイルオーバー処理をサポートするほとんどのツールと同様)には、etc.dまたはConsulとの直接統合はありません。トポロジーデータを更新するタスクはユーザーにあります。彼女は、replication_post_failover_scriptやreplication_post_switchover_scriptなどのフックを使用して、一部のスクリプトを呼び出し、必要な変更を行うことができます。もう1つの非常に一般的な解決策は、DNSを使用してトラフィックを正しいインスタンスに誘導することです。 DNSレコードの存続可能時間を低く保つ場合は、マスター(つまり、writes.cluster1.example.com)を指すドメインを定義できるはずです。これにはDNSレコードの変更が必要です。また、replication_post_failover_scriptやreplication_post_switchover_scriptのようなフックは、フェイルオーバーが発生した後に必要な変更を加えるのに非常に役立ちます。
プロキシの再構成
使用される各プロキシサーバーは、正しいインスタンスにトラフィックを送信する必要があります。プロキシ自体に応じて、マスター検出の実行方法は(部分的に)ハードコーディングすることも、ユーザーが好きなものを定義することもできます。 ClusterControlフェイルオーバーメカニズムは、デプロイおよび構成されたプロキシと適切に統合されるように設計されています。 ClusterControlによってインストールされなかったプロキシが配置されている可能性があり、フェイルオーバーの実行中に手動でアクションを実行する必要があります。このようなプロキシは、replication_post_failover_scriptやreplication_post_switchover_scriptなどの外部スクリプトやフックを介してClusterControlフェイルオーバープロセスと統合することもできます。
追加のログ
デバッグの目的でフェイルオーバープロセスのデータを収集したい場合があります。 ClusterControlには、プロセスを追跡し、何が起こったのか、そしてその理由を理解できるようにするための広範なプリントアウトがあります。それでも、追加のカスタム情報を収集したい場合があります。基本的に、ここではすべてのフックを利用できます。フェイルオーバーの前に初期状態を収集でき、フェイルオーバーのすべての段階で環境の状態を追跡できます。