
この投稿はOracleSQLチュートリアルの一部であり、Oracleの分析関数(パーティションごと)について、例と詳細な説明を使用して説明します。
avg、sum、countなどのOracleAggregate関数についてはすでに学習しました。例を見てみましょう
まず、サンプルデータを作成しましょう
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
ここで、集計関数の例を以下に示します
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
ここでは、各クエリの行数が減少していることがわかります。ここで、すべての行をcount(*)で返す必要がある場合はどうすればよいかという質問があります
そのために、オラクルは一連の分析関数を提供しています。したがって、最後の問題を解決するために、次のように書くことができます
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
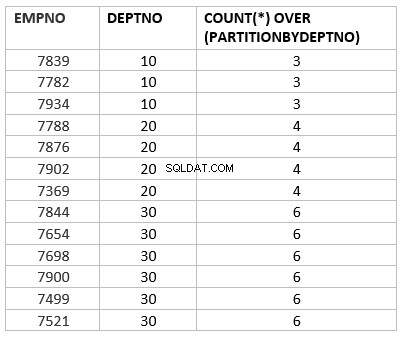
ここで、count(*)over(dept_noによるパーティション)は、カウント集計関数の分析バージョンです。集計関数によって異なる主な重要な作業は、分割による
です。分析関数は、行のグループに基づいて集計値を計算します。これらは、グループごとに複数の行を返すという点で集計関数とは異なります。行のグループはウィンドウと呼ばれ、analytic_clauseによって定義されます。
一般的な構文は次のとおりです
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
例
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
各部分を見ていきましょう
query_partition_clause
行のグループを定義しました。以下のようになります
deptnoによるパーティション:同じdeptnoの行のグループ
または
():すべての行
SQL> select empno ,deptno , count(*) over () from emp;
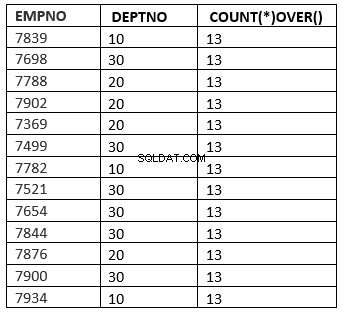
[order_by_clause [windowing_clause]]
この句は、パーティション内の行を並べ替える場合に使用されます。これは、分析関数で行の順序を考慮したい場合に特に便利です。
例はrow_number関数です
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
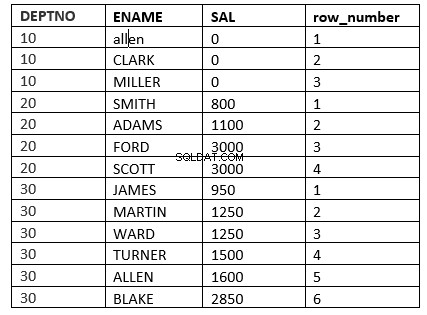
別の例は
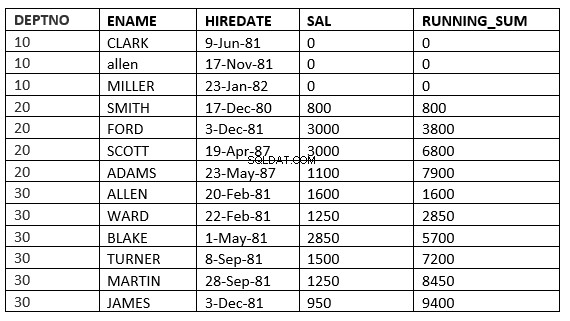
ですSQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
これは常にorderby句で使用され、グループ内の行のセットをより細かく制御できます
Windowing句を使用すると、行ごとに、行のスライディングウィンドウが定義されます。ウィンドウは、現在の行の計算を実行するために使用される行の範囲を決定します。ウィンドウサイズは、物理的な行数または時間などの論理的な間隔に基づくことができます。
order by句を使用し、windowing_clauseに何も指定されていない場合、windowing_clauseのデフォルト値を下回る値が使用されます
UNBOUNDEDPRECEDINGとCURRENTROWの間のRANGEまたはRANGEUNBOUNDEDPRECEDING
これは「パーティションは、計算で使用する必要がある行です」
以下の例はこれを明確に示しています。これは部門の移動平均になります
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
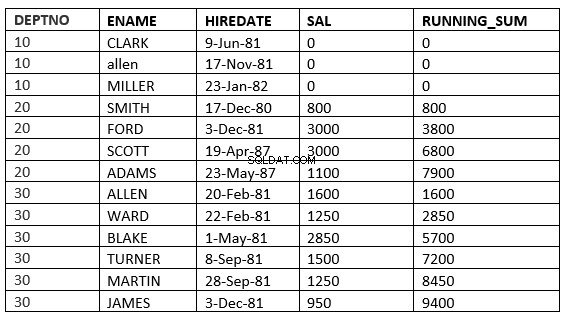
これで、windowing_clauseをさまざまな方法で定義できるようになりました
最初に用語を理解しましょう
行 ウィンドウを物理単位(行)で指定します。
範囲 ウィンドウを論理オフセットとして指定します。 RANGEウィンドウ句は、数値または日付のデータ型の列または式を含むORDERBY句でのみ使用できます
PRECEDING –現在の行より前の行を取得します。
フォロー中 –現在の行の後に行を取得します。
無制限 – PRECEDINGまたはFOLLOWINGと一緒に使用すると、すべての前後に戻ります。現在の行
したがって、一般的には
と定義されます。前に無制限の行 :現在のパーティションの現在の行と前の行は、計算で使用する必要がある行です
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
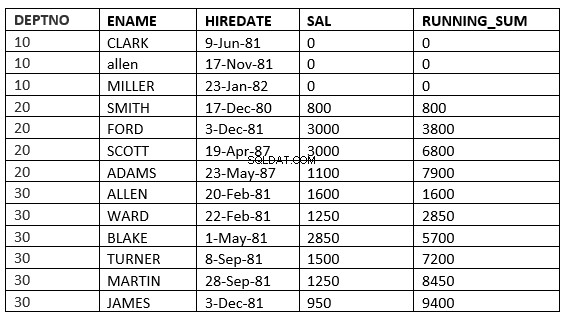
範囲の制限のない前へ :現在のパーティションの現在の行と前の行は、計算で使用する必要のある行です。また、範囲が指定されているため、すべてが現在の行と等しい値を取ります。
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
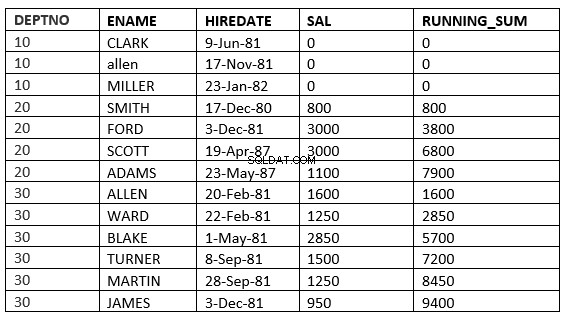
範囲と行の違いは、hire_dateがすべての場合で異なるため、表示されない場合があります。salを句ごとの順序として使用すると、違いがより明確になります。
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
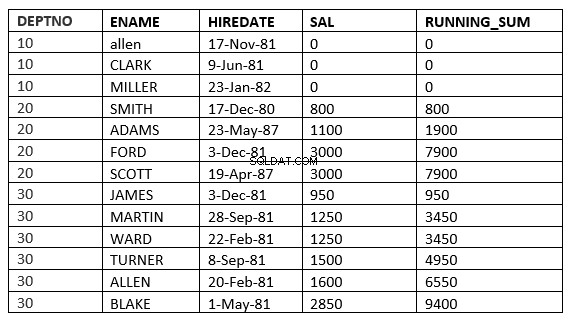
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
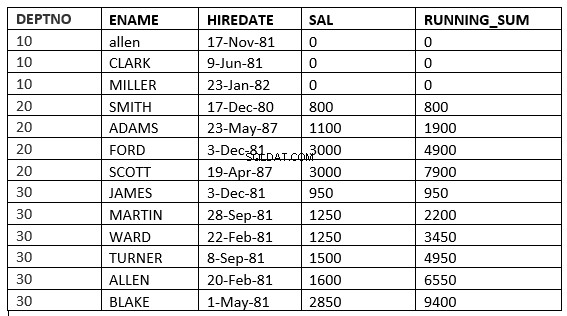
6行目で違いを確認できます
RANGE value_expr PRECEDING :ウィンドウは、ORDER BY値が現在の行よりも小さい、または前の数値式行である行で始まり、処理中の現在の行で終わります。
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
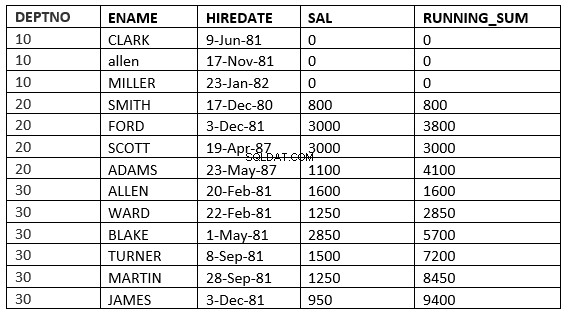
ここでは、現在の行の採用日値より365日以内に採用日値が含まれるすべての行を取得します
ROWS value_expr PRECEDING :ウィンドウは指定された行で始まり、処理中の現在の行で終わります
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
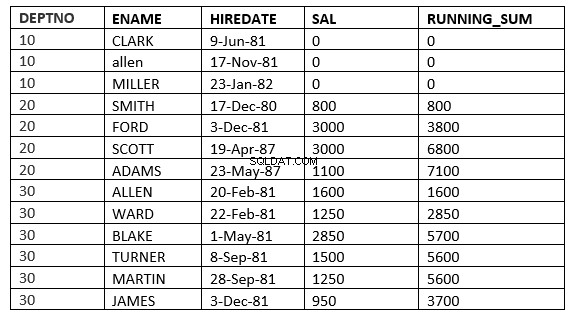
ここで、ウィンドウは現在の行の前の2行から始まります
現在の行と次のvalue_exprの間の範囲 :ウィンドウは現在の行で始まり、ORDERBY値が数値式の行よりも小さいか次の行で終わります
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
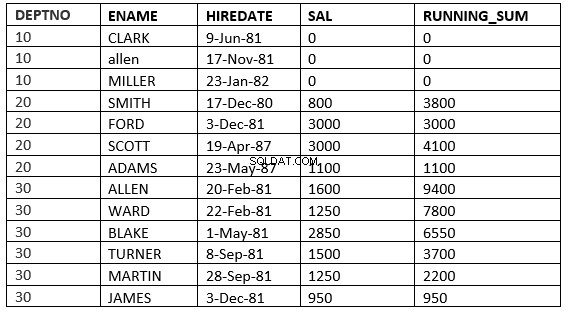
現在の行と次のvalue_exprの間の行 :ウィンドウは現在の行で始まり、現在の行の後の行で終わります
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
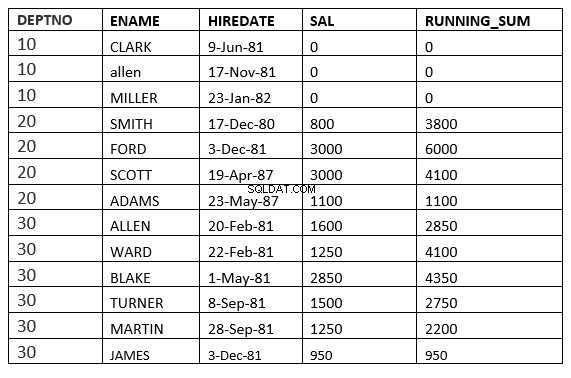
無制限の先行と無制限の後続の間の範囲
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
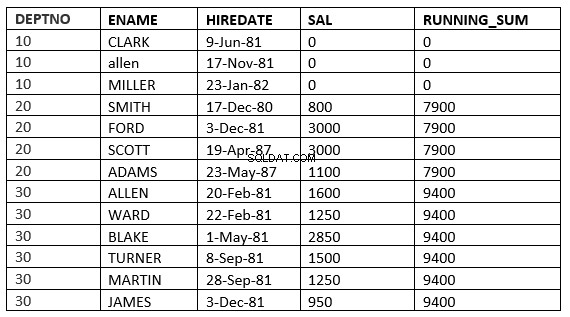
value_exprPRECEDINGとvalue_exprFOLLOWINGの間の範囲
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
いくつかの重要な注意事項
(1)分析関数は、最後のORDER BY句を除いて、クエリで実行される最後の一連の操作です。分析関数が処理される前に、すべての結合とすべてのWHERE、GROUP BY、およびHAVING句が完了します。したがって、分析関数は選択リストまたはORDER BY句にのみ表示できます。
(2)分析関数は通常、累積、移動、中央揃え、およびレポートの集計を計算するために使用されます。
オラクルの分析関数のこの詳細な説明が気に入っていただければ幸いです(パーティション句による)
関連記事
OracleのLEAD関数
OracleのDENSE関数
OracleLISTAGG関数
グループ関数を使用したデータの集約
https://docs.oracle.com/cd/E11882_01/ server.112 / e41084 / features004.htm