Galeraクラスターは、クラスター内のすべてのノードが緊密に結合された強力なデータ整合性を実現します。ネットワークセグメンテーションはサポートされていますが、レプリケーションのパフォーマンスは依然として2つの要因によって制限されます。
-
オリジネーターノードからクラスター内で最も遠いノードへのラウンドトリップ時間(RTT)。
> -
転送され、受信側ノードでの競合が認定される書き込みセットのサイズ。
ガレラのパフォーマンスを向上させる方法はありますが、これら2つの制限要因を回避することはできません。
幸いなことに、Galera ClusterはMySQLの上に構築されており、MySQLにはレプリケーション機能も組み込まれています(ええと!)。 GaleraレプリケーションとMySQLレプリケーションはどちらも同じサーバーソフトウェアに独立して存在します。これらのテクノロジーを利用して連携することができます。データセンター内のすべてのレプリケーションはGaleraで行われ、データセンター間のレプリケーションは標準のMySQLレプリケーションで行われます。スレーブサイトはホットスタンバイサイトとして機能し、アプリケーションがバックアップサイトにリダイレクトされるとデータを提供できるようになります。これについては、ディザスタリカバリのためのMySQLアーキテクチャに関する以前のブログで取り上げました。
クラスター間レプリケーションは、バージョン1.7.4のClusterControlで導入されました。このブログ投稿では、2つのGaleraクラスター(PXC 8.0)間でレプリケーションを設定することがいかに簡単であるかを示します。次に、より難しい部分を見ていきます。ClusterControlを使用して、ノードレベルとクラスターレベルの両方で障害を処理します。フェイルオーバーとフェイルバックの操作は、システム全体でデータの整合性を維持するために重要です。
この例では、少なくとも2つのクラスターと2つのサイトが必要です。1つはプライマリ用、もう1つはセカンダリ用です。これは、従来のMySQLマスタースレーブレプリケーションと同様に機能しますが、各サイトに3つのデータベースノードがある大規模です。 ClusterControlを使用すると、プライマリクラスターを展開した後、ディザスタリカバリサイトにレプリカクラスターとしてセカンダリクラスターを展開し、双方向の非同期レプリケーションによって複製することでこれを実現できます。
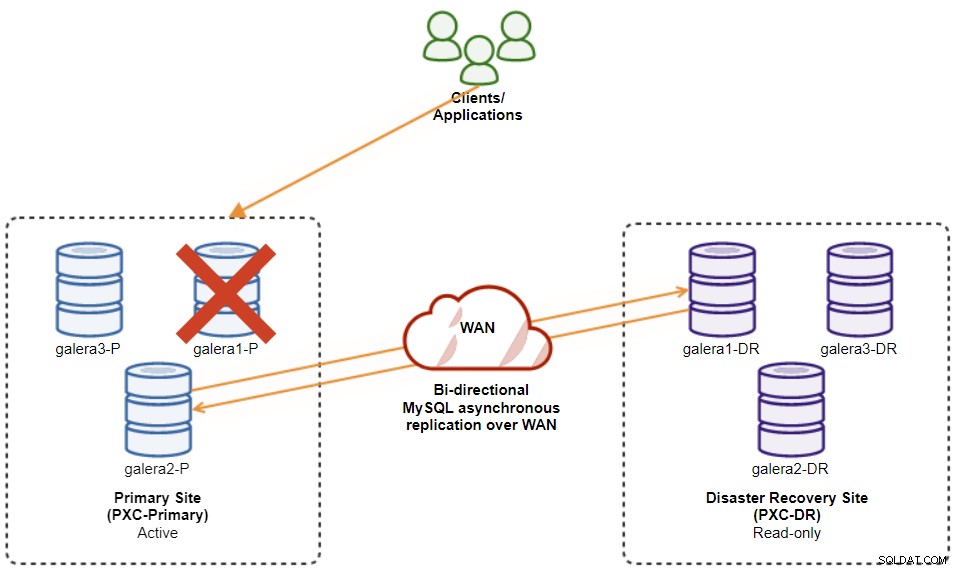
次の図は、最終的なアーキテクチャを示しています。

データベースノードは全部で6つあり、プライマリサイトに3つ、もう1つにもう1つあります。災害復旧サイトに3つ。ノード表現を単純化するために、次の表記法を使用します。
-
プライマリサイト:
-
galera1-P-192.168.11.171(マスター)
-
galera2-P --192.168.11.172
-
galera3-P --192.168.11.173
-
-
災害復旧サイト:
-
galera1-DR-192.168.11.181(スレーブ)
-
galera2-DR --192.168.11.182
-
galera3-DR --192.168.11.183
-
まず、最初のクラスターをデプロイするだけで、これをPXC-Primaryと呼びます。 ClusterControlUI→Deploy→MySQLGaleraを開き、必要なすべての詳細を入力します:
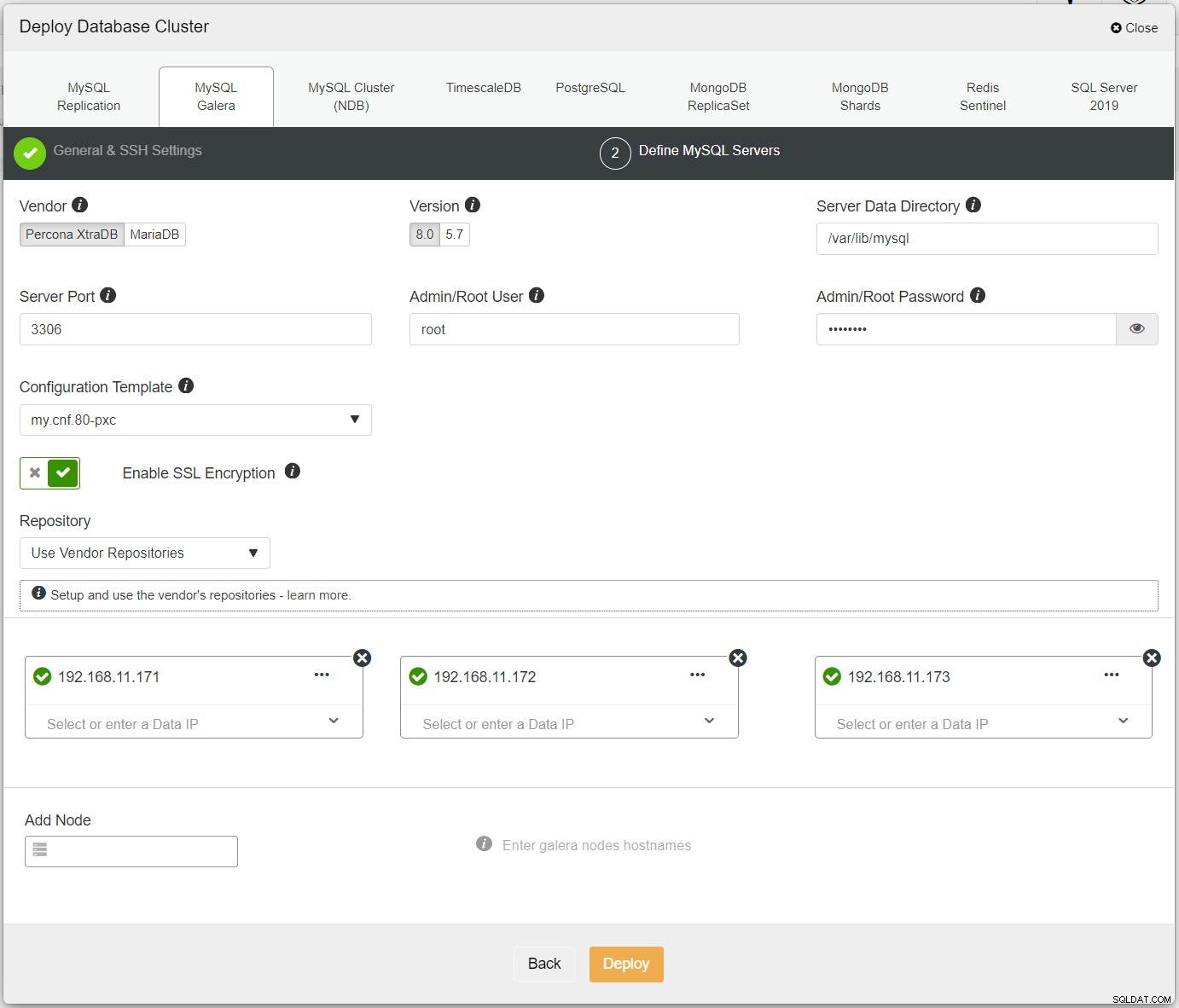
指定されたすべてのノードの横に緑色のチェックマークが付いていることを確認します。これは、ClusterControlを示します。パスワードなしのSSHを介してホストに接続できます。 [デプロイ]をクリックして、デプロイが完了するのを待ちます。完了すると、クラスターダッシュボードページに次のクラスターが表示されます。
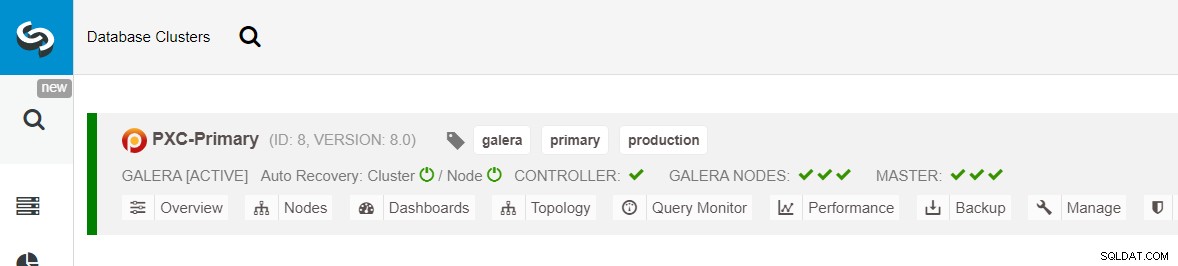
次に、CreateReplicaClusterと呼ばれるClusterControl機能を使用します。クラスタアクションドロップダウン:
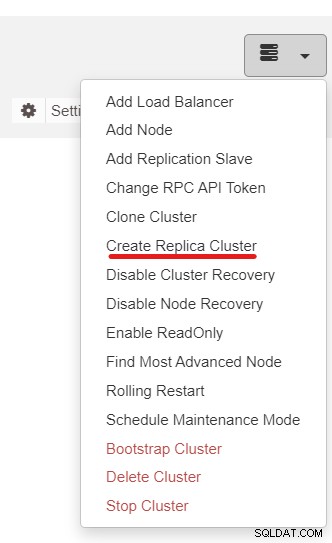
次のサイドバーポップアップが表示されます:
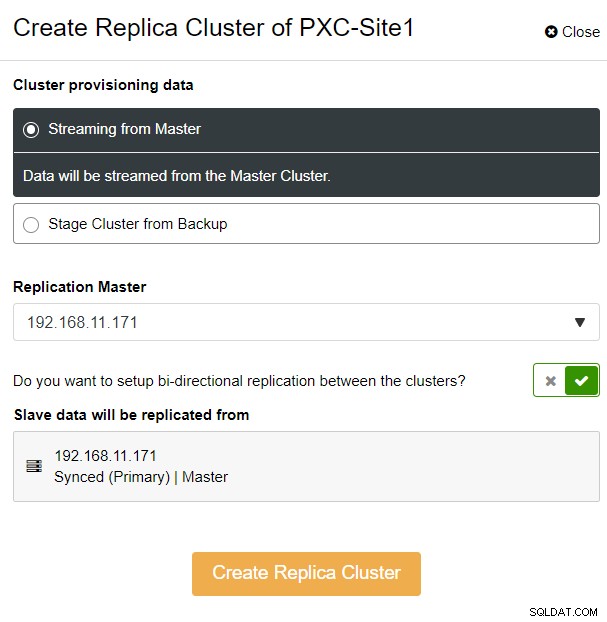
「マスターからのストリーミング」オプションを選択しました。ここで、ClusterControlはレプリカクラスターを同期し、レプリケーションを構成するマスターを選択しました。双方向レプリケーションオプションに注意してください。有効にすると、ClusterControlは両方のサイト間で双方向レプリケーション(循環レプリケーション)をセットアップします。選択されたマスターは、レプリカクラスター用に定義された最初のマスターから複製されます。その逆も同様です。この設定により、フェイルオーバーまたはフェイルバック後にリカバリするときに必要なステージング時間が最小限に抑えられます。 [レプリカクラスターの作成]をクリックすると、以下に示すように、ClusterControlがレプリカクラスターの新しい展開ウィザードを開きます。
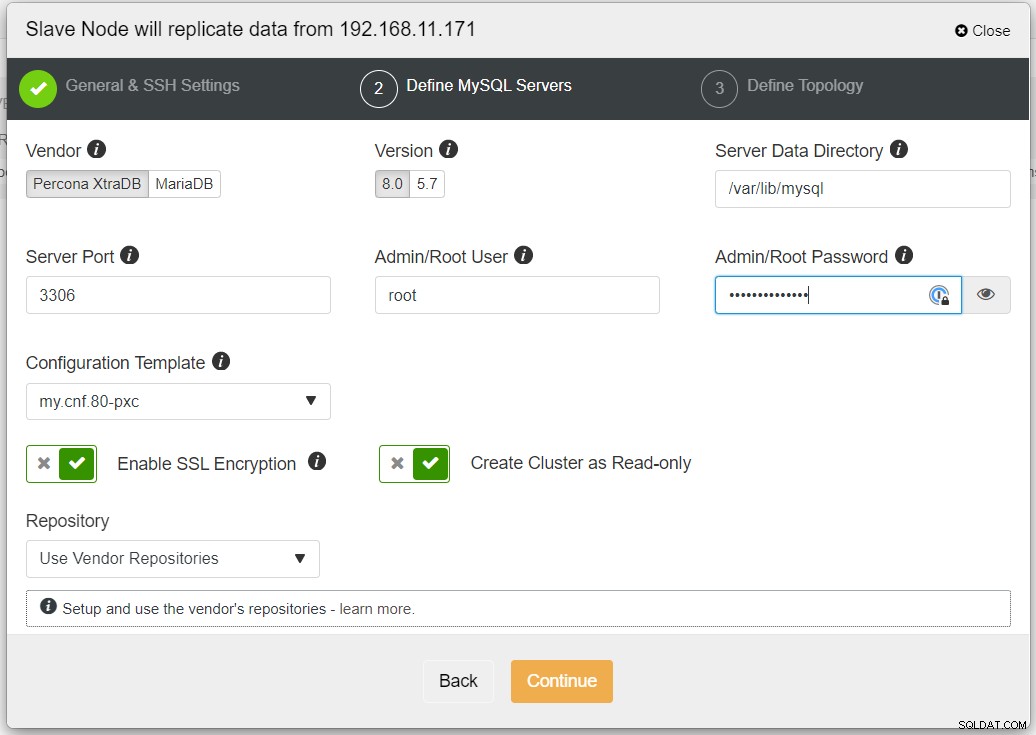
レプリケーションにWANなどの信頼できないネットワークが含まれる場合は、SSL暗号化を有効にすることをお勧めします。非トンネリングネットワーク、またはインターネット。また、「クラスターを読み取り専用として作成」が切り替えられていることを確認してください。これは、偶発的な書き込みに対する保護であり、アクティブクラスター(読み取り/書き込み)とパッシブクラスター(読み取り専用)を簡単に区別するための優れたインジケーターです。
必要な情報をすべて入力したら、次の段階に進んでレプリカクラスタートポロジを定義する必要があります。
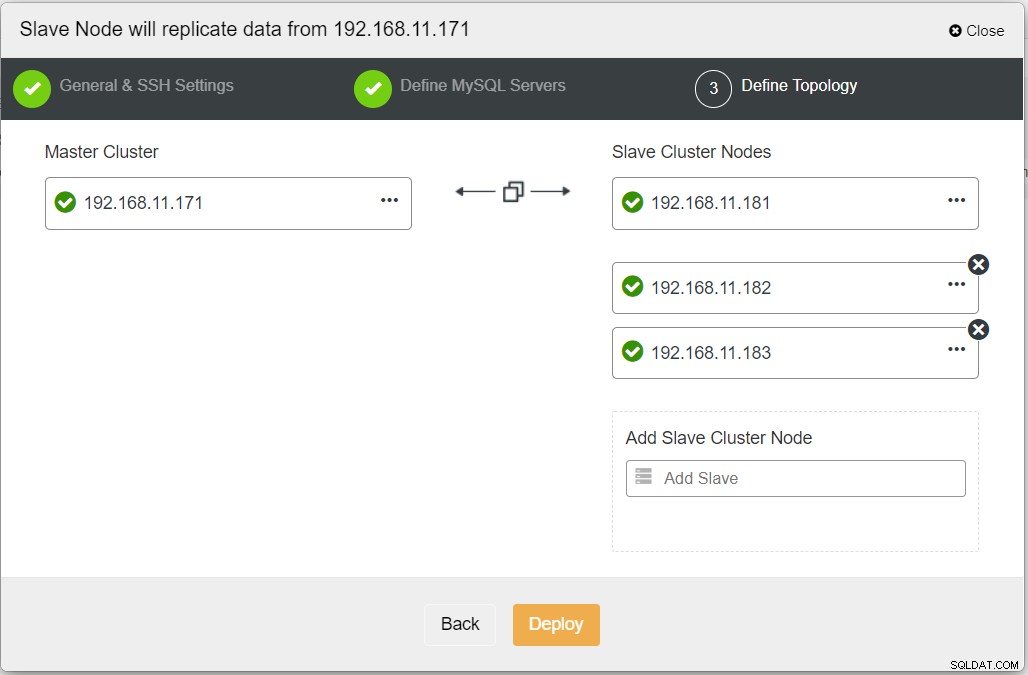
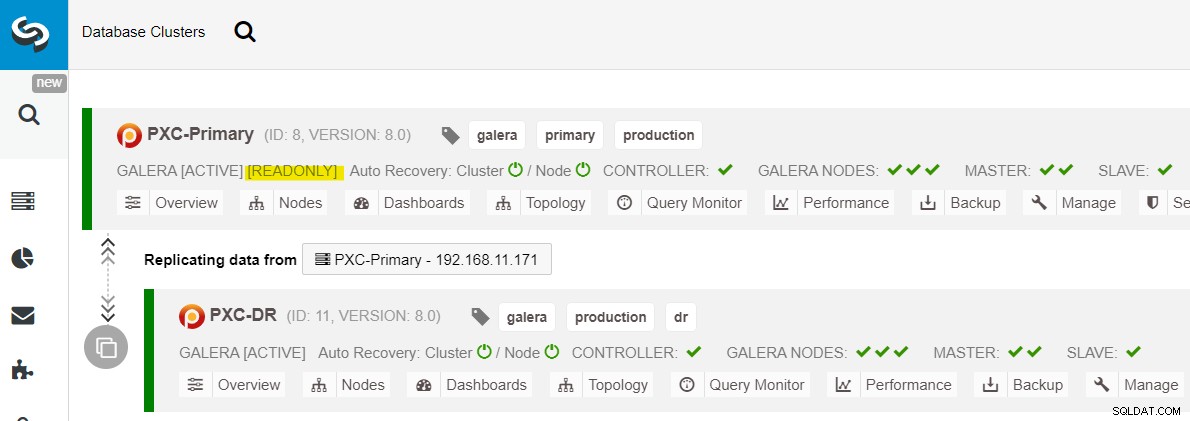
ClusterControlダッシュボードから、展開が完了すると、 DRサイトには、プライマリサイトに接続された双方向の矢印があります:
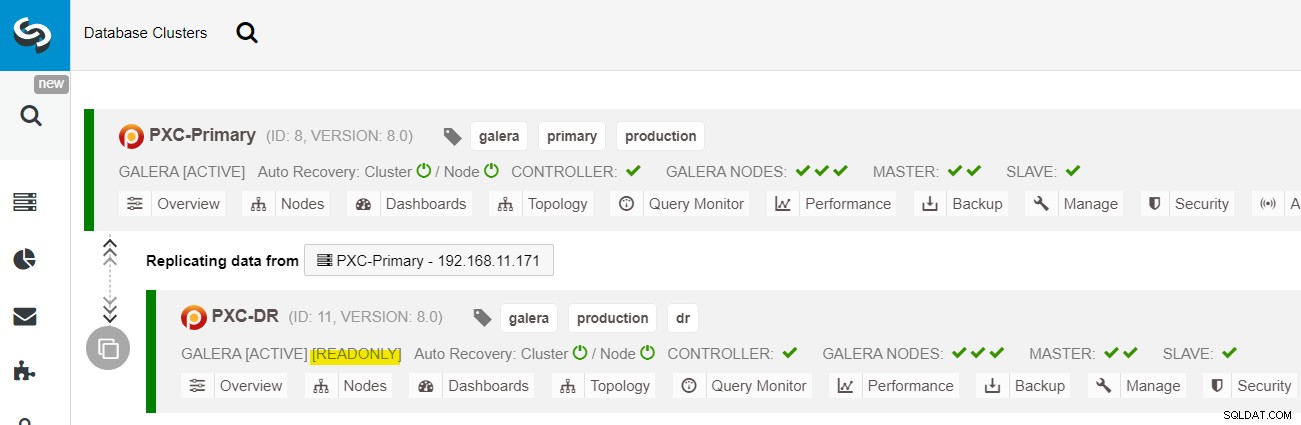
これで展開が完了しました。プライマリサイトはアクティブサイトであり、DRサイトは読み取り専用に構成されているため(黄色で強調表示されているため)、アプリケーションはプライマリサイトにのみ書き込みを送信する必要があります。読み取りは両方のサイトに送信できますが、DRサイトは、非同期レプリケーションの性質のために遅れるリスクがあります。この設定により、プライマリサイトとディザスタリカバリサイトが互いに独立し、非同期レプリケーションとの接続が緩くなります。 DRサイトのGaleraノードの1つは、プライマリサイトのGaleraノード(マスター)の1つから複製するスレーブになります。
これで、プライマリサイトでのクラスター障害がバックアップサイトに影響を与えないシステムができました。パフォーマンス面では、WAN遅延はアクティブクラスターの更新に影響を与えません。これらは、バックアップサイトに非同期で出荷されます。
補足として、Galeraノードの1つをスレーブとして使用する代わりに、専用のスレーブインスタンスをレプリケーションリレーとして使用することもできます。
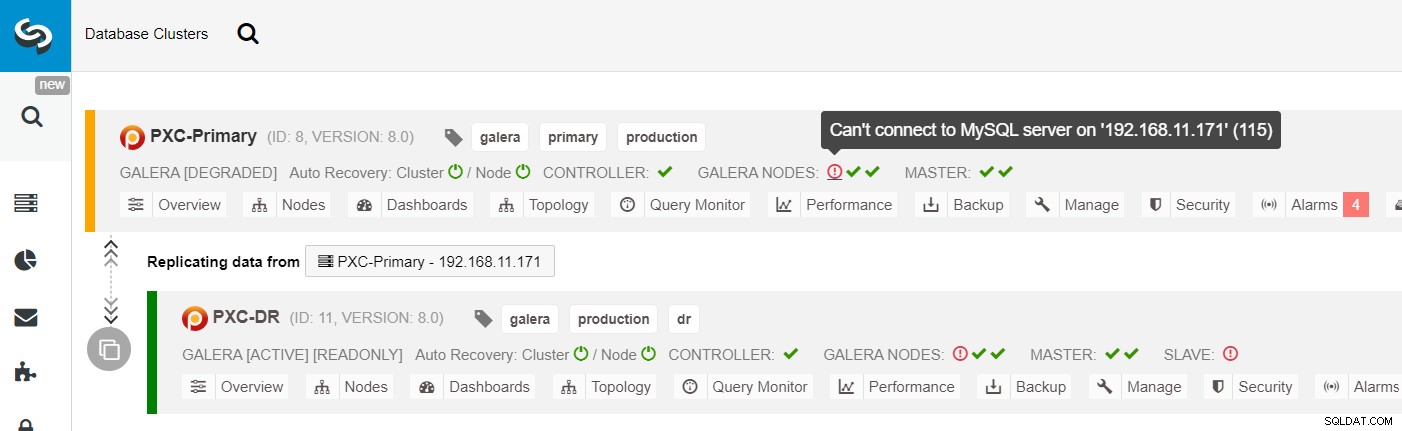
現在のマスター(galera1-P)に障害が発生し、プライマリサイトの残りのノードがまだ稼働している場合は、ディザスタリカバリサイト(galera1-DR)のスレーブを使用可能なマスターに転送する必要があります。次の図に示すように、プライマリサイトで:
ClusterControlクラスターリストから、クラスターのステータスが低下していることがわかります。 、感嘆符アイコンをロールオーバーすると、その特定のノード(galera1-P)のエラーが表示されます。
ClusterControlを使用すると、PXC-DRクラスター→ノード→galera1-DRの選択→ノードアクション→レプリケーションスレーブの再構築に移動するだけで、次の構成ダイアログが表示されます。
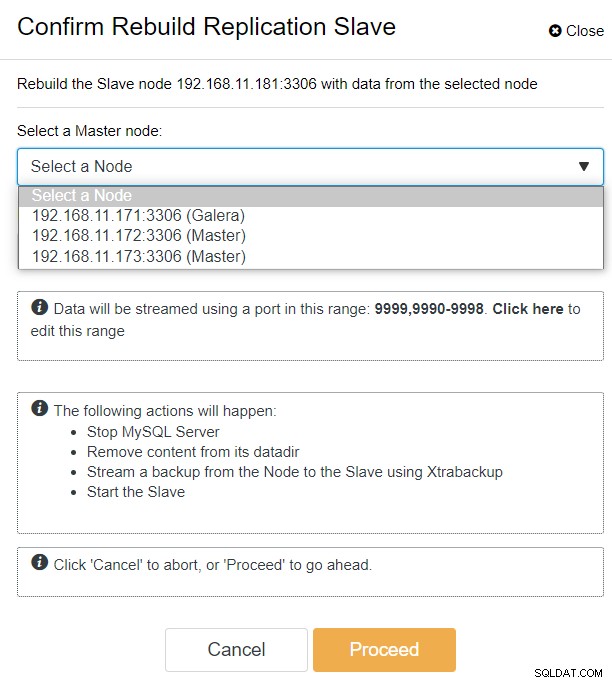
プライマリサイト(192.168.11.17x)ですべてのGaleraノードを確認できます)ドロップダウンリストから。セカンダリノード192.168.11.172(galera2-P)を選択し、[続行]をクリックします。次に、ClusterControlは、レプリケーショントポロジを適切に構成し、galera2-Pからgalera1-DRへの双方向レプリケーションを設定します。これは、クラスターダッシュボードページ(黄色で強調表示)から確認できます:
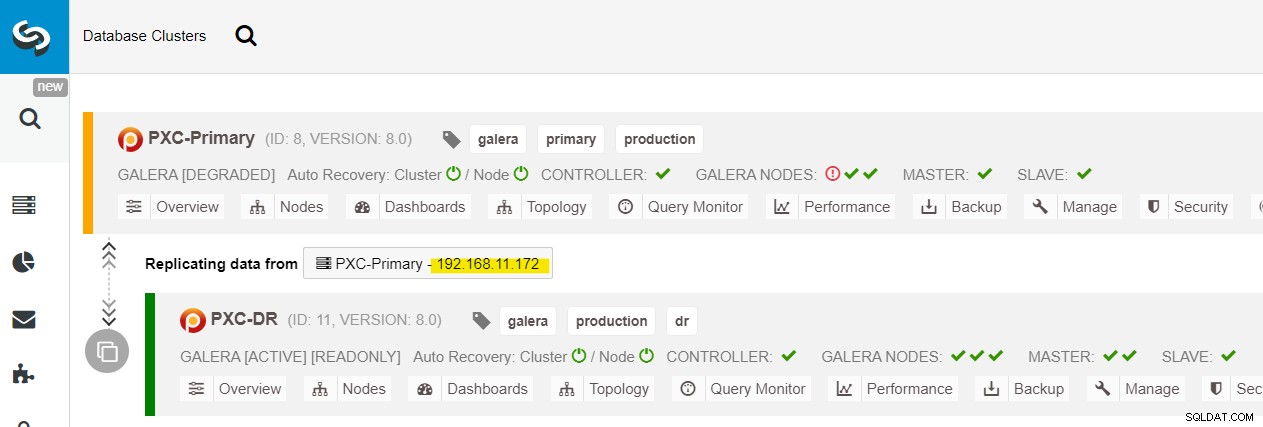
この時点で、プライマリクラスター(PXC-Primary)は引き続き機能しています。このトポロジのアクティブクラスタとして。プライマリクラスタのデータベースサービスの稼働時間に影響を与えることはありません。
アプリケーションの観点から、プライマリクラスターがダウンしたり、クラッシュしたり、単に接続が失われたりした場合、アプリケーションはほぼ瞬時にDRサイトに転送されます。 SysAdminは、次のステートメントを使用して、ディザスタリカバリサイトのすべてのGaleraノードで読み取り専用を無効にする必要があります。
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRClusterControlユーザーの場合、ClusterControlUI→ノード→DBノードの選択→ノードアクション→読み取り専用の無効化を使用できます。 ClusterControlノードで次のコマンドを実行することにより、ClusterControlCLIも使用できます。
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeこれでDRサイトへのフェイルオーバーが完了し、アプリケーションはPXC-DRクラスターへの書き込みの送信を開始できます。 ClusterControl UIから、次のように表示されます。
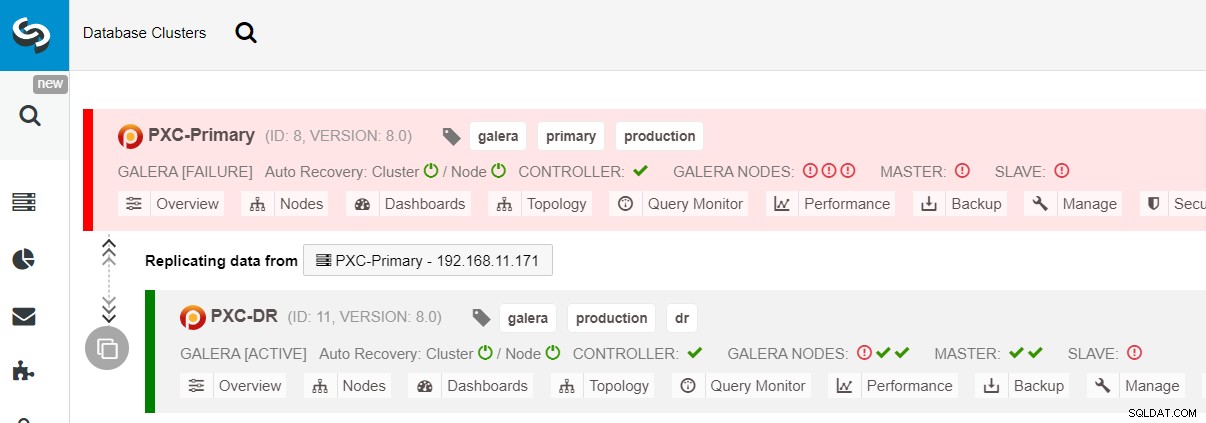
次の図は、アプリケーションがDRサイトにフェイルオーバーした後のアーキテクチャを示しています。 :
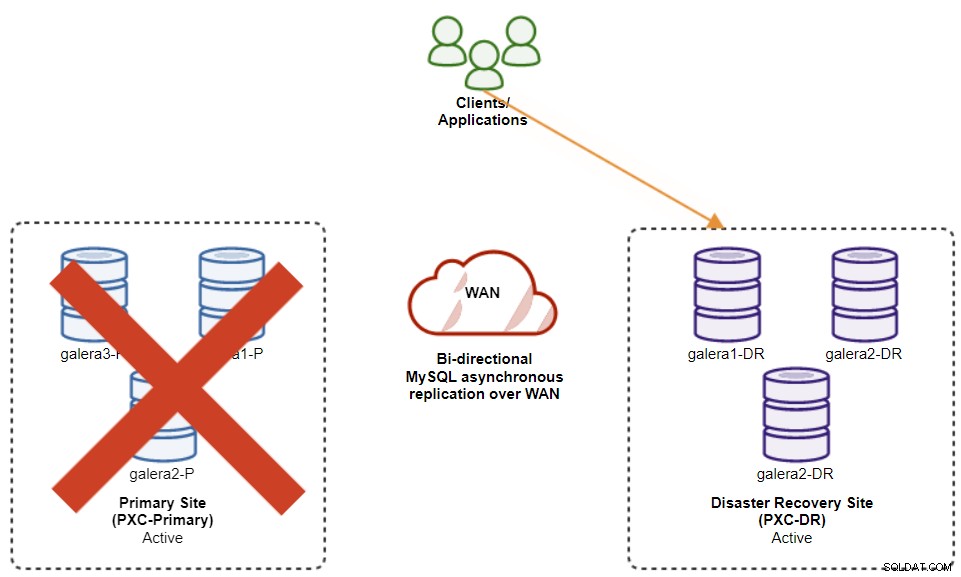
プライマリサイトがまだダウンしていると仮定すると、この時点では、プライマリサイトが復旧するまでのサイト間のレプリケーション。
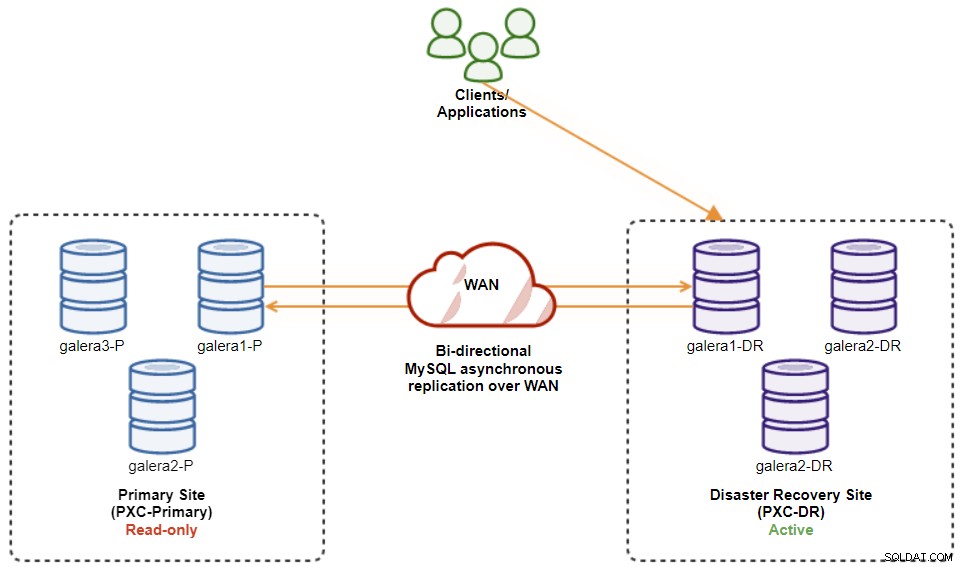
プライマリサイトが起動したら、プライマリクラスタを読み取り専用に設定する必要があることに注意してください。これにより、アクティブクラスタがディザスタリカバリサイトにあることがわかります。 ClusterControlから、クラスターのドロップダウンメニューに移動し、[読み取り専用を有効にする]を選択します。これにより、プライマリクラスター内のすべてのノードで読み取り専用が有効になり、現在のトポロジが次のように要約されます。
クラスターのフェイルバック手順を開始する前に、すべてが緑色であることを確認してください(緑色すべてのノードが稼働していて、相互に同期していることを意味します)。劣化状態のノードがある場合、たとえば、複製ノードがまだ遅れている場合、またはプライマリクラスター内の一部のノードのみに到達可能であった場合は、ClusterControl自動回復手順を待つことにより、クラスターが完全に回復するまで待機します。完了するか、手動で介入します。
この時点では、アクティブなクラスターは引き続きDRのクラスターであり、プライマリクラスターはセカンダリクラスターとして機能しています。次の図は、現在のアーキテクチャを示しています。
プライマリサイトにフェールバックする最も安全な方法は、読み取り専用に設定することです。 DRのクラスターで、プライマリサイトで読み取り専用を無効にします。 ClusterControl UI→PXC-DR(ドロップダウンメニュー)→[読み取り専用を有効にする]に移動します。これにより、DRのクラスター上のすべてのノードで読み取り専用を設定するジョブがトリガーされます。次に、ClusterControl UI→PXC-Primary→Nodesに移動し、プライマリクラスター内のすべてのデータベースノードで読み取り専用を無効にします。
ClusterControlCLIを使用して上記の手順を簡略化することもできます。または、ClusterControlホストで次のコマンドを実行します。
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-write完了すると、レプリケーションの方向は元の構成に戻ります。ここで、PXC-Primaryはアクティブクラスターであり、PXC-DRはスタンバイクラスターです。次の図は、クラスターのフェイルバック操作後の最終的なアーキテクチャーを示しています。
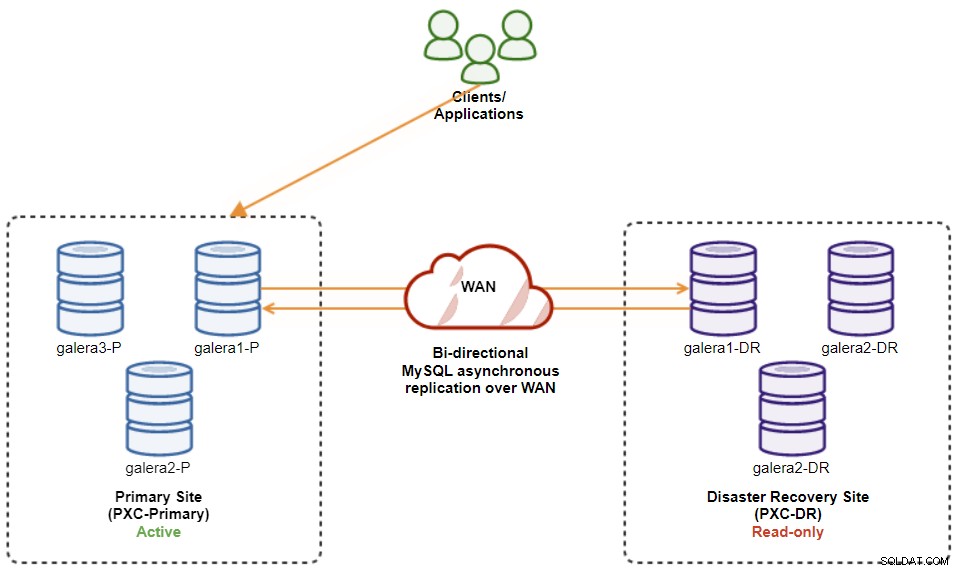
この時点で、書き込み用にアプリケーションをリダイレクトしても安全です。プライマリサイト。
非同期レプリケーションを使用したクラスター間には、いくつかの利点があります。
-
データベースフェイルオーバー操作中の最小限のダウンタイム。基本的に、マスターサイトに到達しないように書き込みを保護できる場合にのみ、書き込みをほぼ瞬時にスレーブサイトにリダイレクトできます(これらの書き込みは複製されず、DRサイトから再同期するときに上書きされる可能性があります)。
-
プライマリサイトはバックアップ(DR)サイトから独立しているため、パフォーマンスへの影響はありません。マスターからスレーブへのレプリケーションは非同期で実行されます。マスターサイトはバイナリログを生成し、スレーブサイトはイベントを複製し、後でイベントを適用します。
-
災害復旧サイトは、データベースのバックアップ、バイナリログのバックアップ、レポートなど、他の目的に使用できます。または重い分析クエリ(OLAP)。スレーブ側でのレプリケーションラグと読み取り専用操作を除いて、両方のサイトを同時に使用できます。
-
DRクラスターは、追いつくことができる限り、パブリッククラウド環境の小さなインスタンスで実行される可能性がありますプライマリクラスターで。必要に応じてインスタンスをアップグレードできます。特定のシナリオでは、コストを節約できます。
-
アクティブ-アクティブGaleraマルチサイトレプリケーションセットアップと比較して、ディザスタリカバリに必要な追加サイトは1つだけです。正しく動作するには、少なくとも3つのアクティブなサイトが必要です。
双方向レプリケーションと単方向レプリケーションのどちらを使用しているかによって、この設定には欠点もあります。
-
レプリケーションは非同期であるため、スレーブが遅れている場合、フェイルオーバー中に一部のデータが失われる可能性があります。これは、準同期およびマルチスレッドのスレーブレプリケーションで改善される可能性がありますが、待機中の別の一連の課題(ネットワークオーバーヘッド、レプリケーションギャップなど)があります。
-
単方向レプリケーションでは、フェイルオーバー手順はかなり単純ですが、フェイルバック手順は扱いにくく、人的エラーが発生しやすい場合があります。エラー。マスター/スレーブの役割をプライマリサイトに戻すための専門知識が必要です。手順を文書化して、フェイルオーバー/フェイルバック操作を定期的にリハーサルし、正確なレポートおよび監視ツールを使用することをお勧めします。
-
ディザスタリカバリサイトに同じ数のノードを設定する必要があるため、かなりのコストがかかる可能性があります。コストの正当化は通常、ビジネスの要件に基づいているため、これは白黒ではありません。いくつかの計画を立てれば、データベースの役割に関係なく、両方のサイトでデータベースリソースを最大限に活用することができます。
MySQL Galeraクラスターの非同期レプリケーションのセットアップは、ノードレベルとクラスターレベルの両方で障害を適切に処理する方法を理解している限り、比較的簡単なプロセスです。最終的に、フェイルオーバーとフェイルバックの操作は、データの整合性を確保するために重要です。
フェイルオーバーおよびフェイルバック戦略を念頭に置いてGaleraクラスターを設計するためのその他のヒントについては、ディザスタリカバリのためのMySQLアーキテクチャに関するこの投稿を確認してください。これらの操作を自動化するためのヘルプが必要な場合は、ClusterControlを30日間無料で評価し、この投稿の手順に従ってください。
TwitterまたはLinkedInでフォローし、ニュースレターを購読して、オープンソースデータベースインフラストラクチャを管理するための最新ニュースとベストプラクティスを最新の状態に保つことを忘れないでください。