データベースが単一のノードまたはインスタンスとしてデプロイされていた時代は過ぎ去りました。これは、データベースへのすべての要求を処理するように任務を負った強力なスタンドアロンサーバーです。垂直スケーリングがその方法でした。サーバーを別の、さらに強力なサーバーに置き換えてください。この間、ネットワークのパフォーマンスに煩わされる必要はありませんでした。リクエストが届いている限り、すべてが良かったです。
しかし現在、データベースは、ネットワークを介して相互接続されたノードを備えたクラスターとして構築されています。常に高速なローカルネットワークであるとは限りません。ビジネスが世界規模に達するにつれ、データベースインフラストラクチャも世界中に広がり、顧客の近くにとどまり、遅延を減らす必要があります。高可用性データベース環境を設計するときに直面しなければならない追加の課題が伴います。このブログ投稿では、直面する可能性のあるネットワークの問題を調査し、それらに対処する方法についていくつかの提案を提供します。
MySQLまたはMariaDBHAの2つの主なオプション
この特定のトピックについては、ホワイトペーパーの1つで非常に広範囲にわたって取り上げましたが、MySQLとMariaDBの高可用性を構築する2つの主な方法を見てみましょう。
ガレラクラスター
Galera Clusterはシェアードナッシングであり、MySQL用の実質的に同期するクラスターテクノロジーです。これにより、世界中にまたがることができるマルチライター設定を構築できます。 Galeraは低遅延環境で繁栄しますが、長いWAN接続で動作するように構成することもできます。 Galeraには、一部のノードのネットワーク分割の場合にデータが危険にさらされないようにするクォーラムメカニズムが組み込まれています。
MySQLレプリケーション
MySQLレプリケーションは、非同期または準同期のいずれかになります。どちらも大規模なレプリケーションクラスターを構築するように設計されています。他のマスタースレーブまたはプライマリ-セカンダリレプリケーションのセットアップと同様に、ライターはマスターのみです。他のノードであるスレーブは、メーザーからのデータセットのコピーを含んでいるため、フェイルオーバーの目的で使用されます。スレーブは、データを読み取り、マスターからワークロードの一部をオフロードするためにも使用できます。
どちらのソリューションにも独自の制限と機能があり、どちらも異なる問題に悩まされています。どちらも不安定なネットワーク接続の影響を受ける可能性があります。これらの制限と、不安定なネットワークインフラストラクチャの影響を最小限に抑えるための環境を設計する方法を見てみましょう。
ガレラクラスター-ネットワークの問題
まず、GaleraClusterを見てみましょう。すでに説明したように、これは低遅延環境で最適に機能します。 Galeraのレイテンシに関連する主な問題の1つは、Galeraが書き込みを処理する方法です。このブログではすべての詳細を説明するわけではありませんが、Galera ClusterforMySQLチュートリアルをさらに読んでください。つまり、書き込みの認証プロセスでは、クラスター内のすべてのノードが書き込みを適用できるかどうかについて合意する必要があるため、単一行の書き込みパフォーマンスは、ライター間のネットワークラウンドトリップ時間によって厳密に制限されます。ノードと最も遠いノード。待ち時間が許容範囲内であり、データにホットスポットが多すぎない限り、WANセットアップは問題なく機能する可能性があります。この問題は、ネットワーク遅延が時々急上昇したときに始まります。その場合、書き込みには通常の3〜4倍の時間がかかり、その結果、データベースが長時間実行される書き込みで過負荷になり始める可能性があります。
Galera Clusterの優れた機能の1つは、クラスターの状態を検出し、ネットワークのパーティション分割に反応する機能です。クラスタのノードに到達できない場合、そのノードはクラスタから削除され、書き込みを実行できなくなります。これは、クラスターが分割されている間、データの整合性を維持するために重要です。クラスターの大部分のみが書き込みを受け入れます。少数派は文句を言うでしょう。これを処理するために、Galeraは、非常に一時的なネットワークの問題に関する誤ったアラートを回避するために、膨大な数のチェックと構成可能なタイムアウトを導入しています。残念ながら、ネットワークの信頼性が低い場合、Galera Clusterは正しく機能しません。ノードはクラスターを離れ始め、後でクラスターに参加します。ガレラクラスターがWANにまたがっている場合は特に問題になります。相互接続ネットワークが適切に機能しない場合、クラスターの分離された部分がランダムに消える可能性があります。
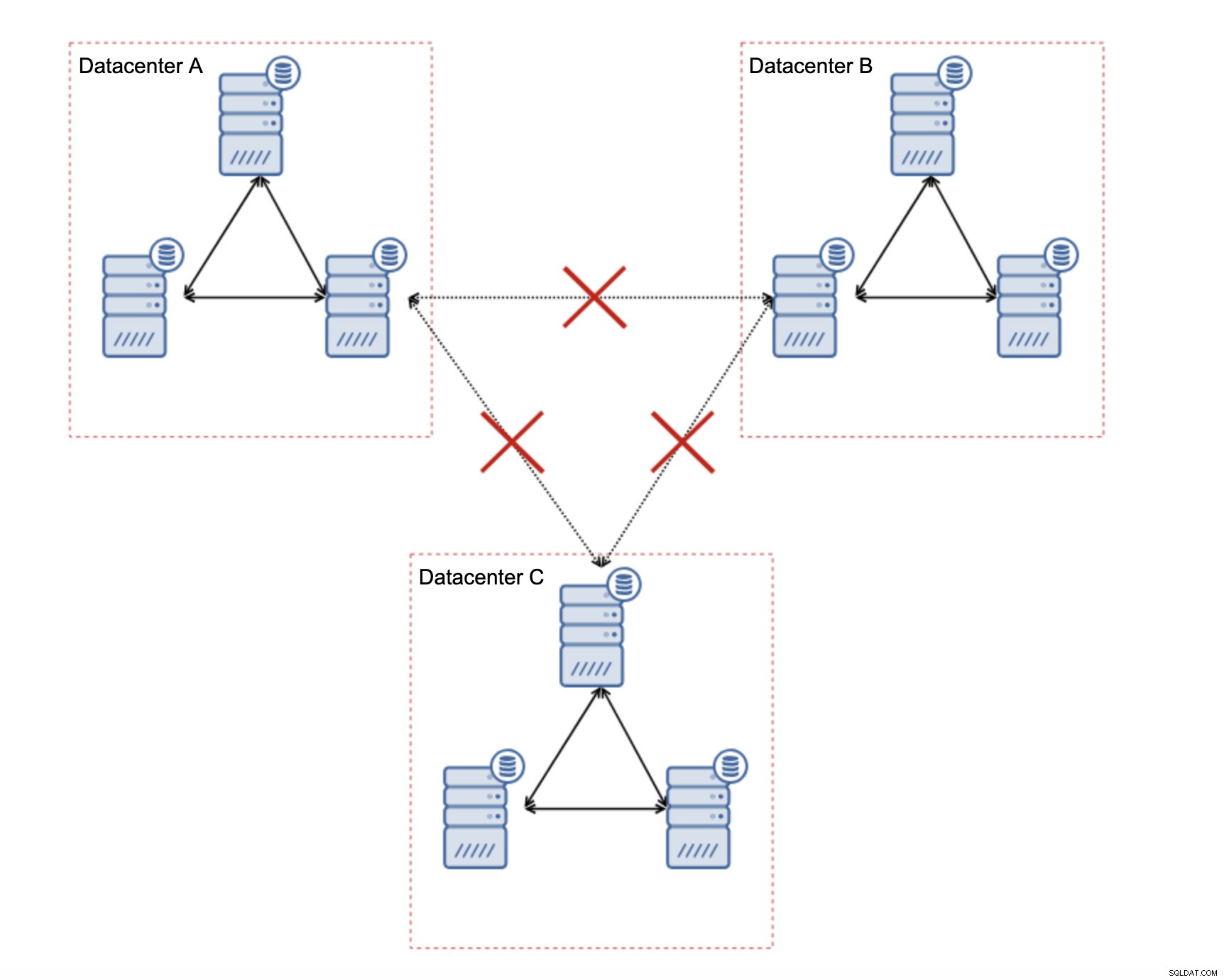
不安定なネットワーク用にGaleraクラスターを設計する方法
まず最初に、単一のデータセンター内でネットワークの問題が発生した場合、それらの問題を何らかの方法で解決できない限り、できることはあまりありません。信頼性の低いローカルネットワークはGaleraClusterには適していません。他のソリューションの使用を再検討する必要があります(ただし、正直なところ、信頼性の低いネットワークは常に問題になります)。一方、問題がWAN接続のみに関連している場合(これは最も一般的なケースの1つです)、WAN Galeraリンクを通常の非同期レプリケーションに置き換えることができる場合があります(Galera WANチューニングが役に立たなかった場合)。
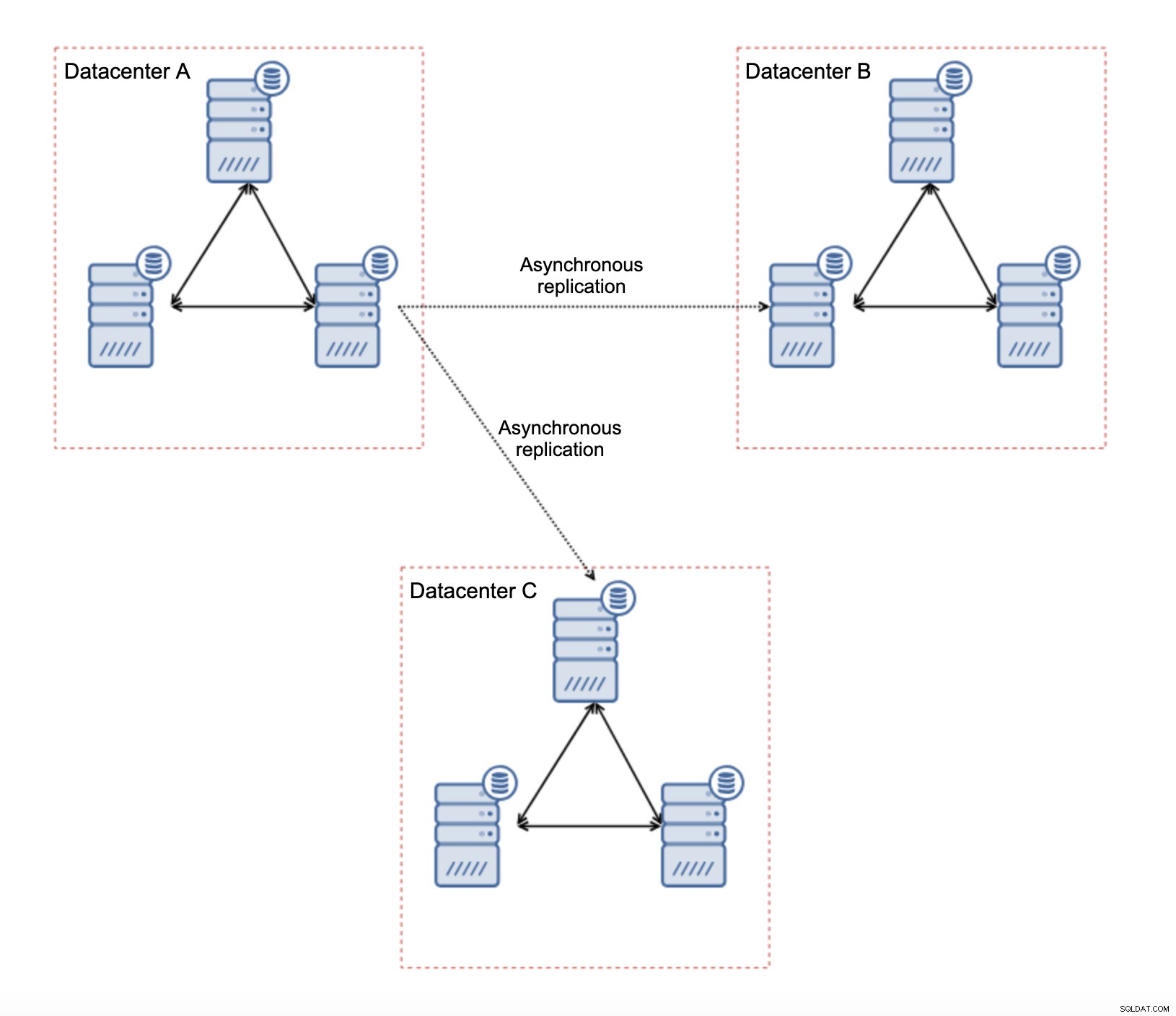
この設定にはいくつかの固有の制限があります。主な問題は、書き込みがローカルで行われていたことです。これで、すべての書き込みは「マスター」データセンター(この場合はDC A)に向かう必要があります。これは思ったほど悪くはありません。オールガレラ環境では、異なるデータセンターにあるノード間のレイテンシーによって書き込みが遅くなることに注意してください。ローカル書き込みでも影響を受けます。これは、WANを介して「マスター」データセンターに書き込みを送信する非同期セットアップの場合とほぼ同じ速度低下になります。
非同期レプリケーションの使用には、非同期レプリケーションに典型的なすべての問題が伴います。レプリケーションの遅延が問題になる可能性があります。Galeraのパフォーマンスが向上するのではなく、Galeraがフロー制御を介してトラフィックを遅くし、レプリケーションにはマスターのトラフィックを抑制するメカニズムがないだけです。
もう1つの問題はフェイルオーバーです。「マスター」Galeraノード(他のデータセンターのスレーブのマスターとして機能するノード)に障害が発生した場合、スレーブを別の動作中のマスターノードに再ポイントするメカニズムを作成する必要があります。ある種のスクリプトである可能性があります。「スレーブ」Galeraクラスターが「マスター」クラスター内の稼働中のGaleraノードに常に割り当てられている仮想IPからスレーブ化するVIPで何かを試すこともできます。
このようなセットアップの主な利点は、WAN Galeraリンクを削除することです。これは、一部のノードが地理的に分離されているために「マスター」クラスターの速度が低下しないことを意味します。前述したように、すべてのデータセンターに書き込む機能は失われますが、WANを介した遅延に関する書き込みは、WANにまたがるGaleraクラスターにローカルに書き込むことと同じです。その結果、全体的なレイテンシーが改善されるはずです。非同期レプリケーションは、不安定なネットワークに対する脆弱性も低くなります。最悪のシナリオでは、レプリケーションリンクが壊れ、ネットワークが収束したときに再作成されます。
不安定なネットワーク用にMySQLレプリケーションを設計する方法
前のセクションでは、Galeraクラスターについて説明しましたが、1つの解決策は非同期レプリケーションを使用することでした。プレーンな非同期レプリケーションのセットアップではどのように見えますか?不安定なネットワークがどのようにレプリケーション設定で最大の混乱を引き起こす可能性があるかを見てみましょう。
まず第一に、レイテンシー-ガレラクラスターの主な問題点の1つです。複製の場合、それはほとんど問題ではありません。準同期レプリケーションを使用しない限り、このような場合、レイテンシーが増加すると書き込みが遅くなります。非同期レプリケーションでは、レイテンシは書き込みパフォーマンスに影響を与えません。ただし、レプリケーションの遅延に影響を与える可能性があります。 Galeraの場合ほど重要ではありませんが、ノード間のネットワークの遅延が大きい場合は、ラグスパイクが多くなり、レプリケーションパフォーマンスが全体的に不安定になることが予想されます。これは主に、高遅延ネットワークでスレーブへのデータ転送を開始する前に、マスターが複数の書き込みを提供する可能性があるという事実によるものです。
ネットワークの不安定性は間違いなくレプリケーションリンクに影響を与える可能性がありますが、これもそれほど重要ではありません。 MySQLスレーブはマスターへの再接続を試み、レプリケーションが開始されます。
MySQLレプリケーションの主な問題は、実際にはGaleraClusterが内部で解決するものです-ネットワークパーティショニング。ネットワークのセグメントが互いに分離されている状態として、ネットワークの分割について話します。 MySQLレプリケーションは、単一のライターノード(マスター)を利用します。環境をどのように設計する場合でも、書き込みをマスターに送信する必要があります。マスターが(何らかの理由で)利用できない場合、アプリケーションは、ある種の読み取り専用モードで実行されない限り、そのジョブを実行できません。したがって、できるだけ早く新しいマスターを選ぶ必要があります。ここに問題が発生します。
まず、どのホストがマスターで、どのホストがマスターでないかを判断する方法。通常の方法の1つは、「read_only」変数を使用してスレーブとマスターを区別することです。ノードでread_onlyが有効になっている場合(read_only =1に設定)、それはスレーブです(スレーブは直接書き込みを処理してはならないため)。ノードでread_onlyが無効になっている場合(read_only =0に設定)、ノードはマスターです。より安全にするための一般的なアプローチは、MySQL構成でread_only =1を設定することです。再起動の場合、ノードがスレーブとして表示される方が安全です。このような「言語」は、ProxySQLやMaxScaleなどのプロキシで理解できます。
例を見てみましょう。
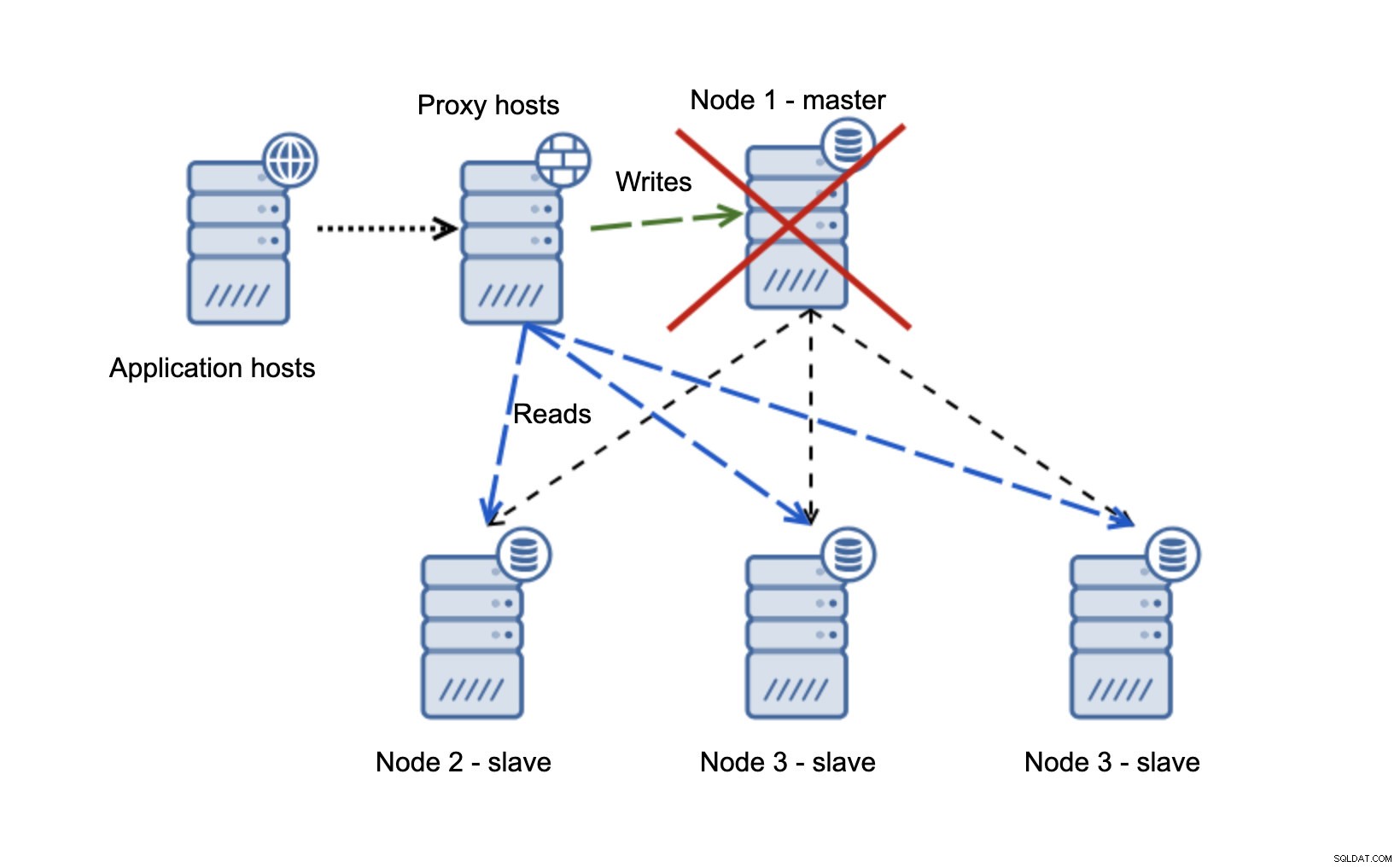
プロキシ層に接続するアプリケーションホストがあります。プロキシは、SELECTをスレーブに送信し、マスターに書き込みを送信する読み取り/書き込み分割を実行します。マスターがダウンしている場合、フェイルオーバーが実行され、新しいマスターがプロモートされ、プロキシレイヤーがそれを検出して、別のノードへの書き込みの送信を開始します。
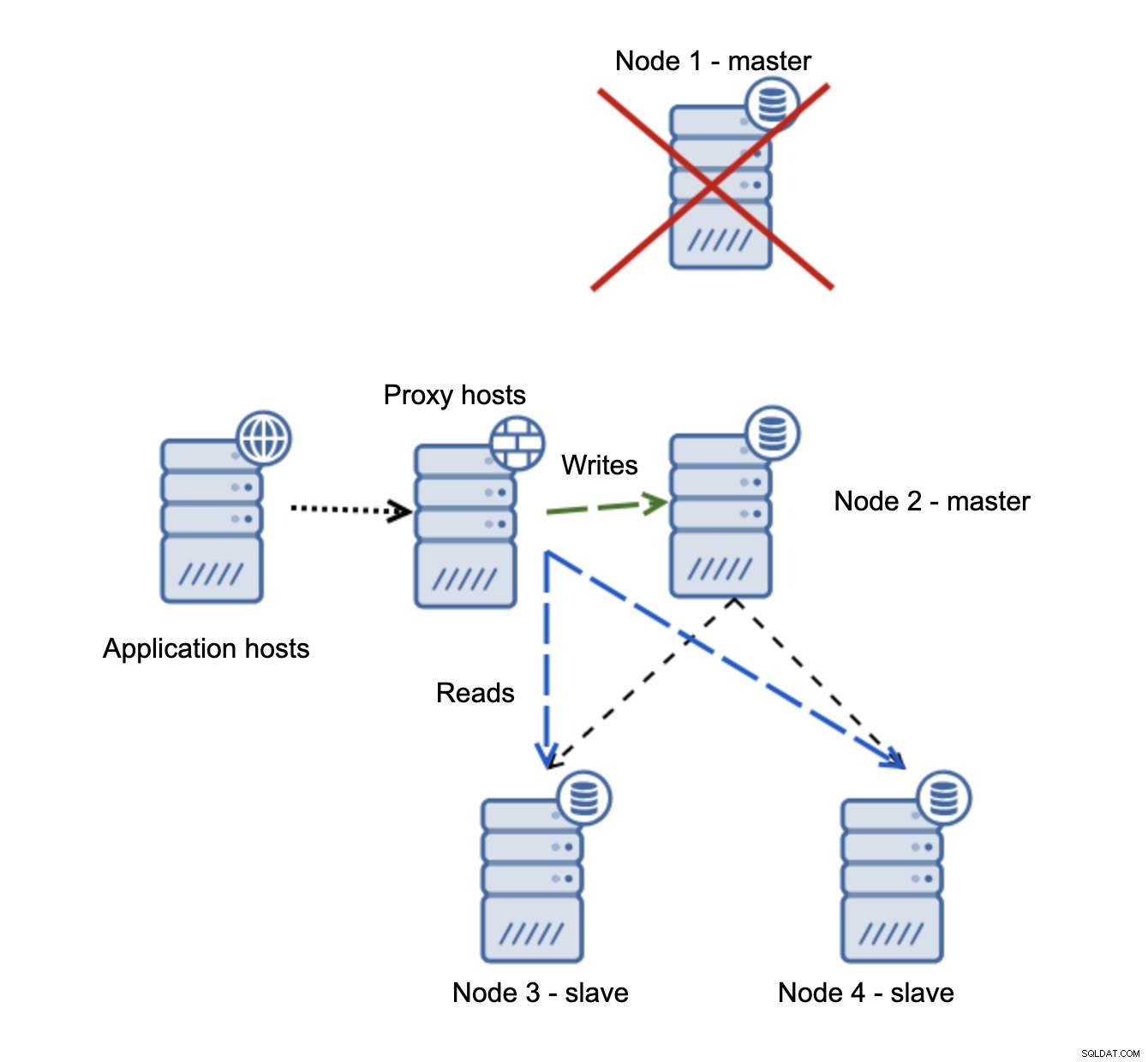
node1が再起動すると、read_only =1が起動し、スレーブとして検出されます。複製されていないため理想的ではありませんが、許容範囲内です。理想的には、古いマスターは、再構築されて新しいマスターからスレーブ化されるまで、まったく表示されないはずです。
さらに問題のある状況は、ネットワークのパーティショニングに対処する必要がある場合です。同じ設定、つまりアプリケーション層、プロキシ層、データベースについて考えてみましょう。
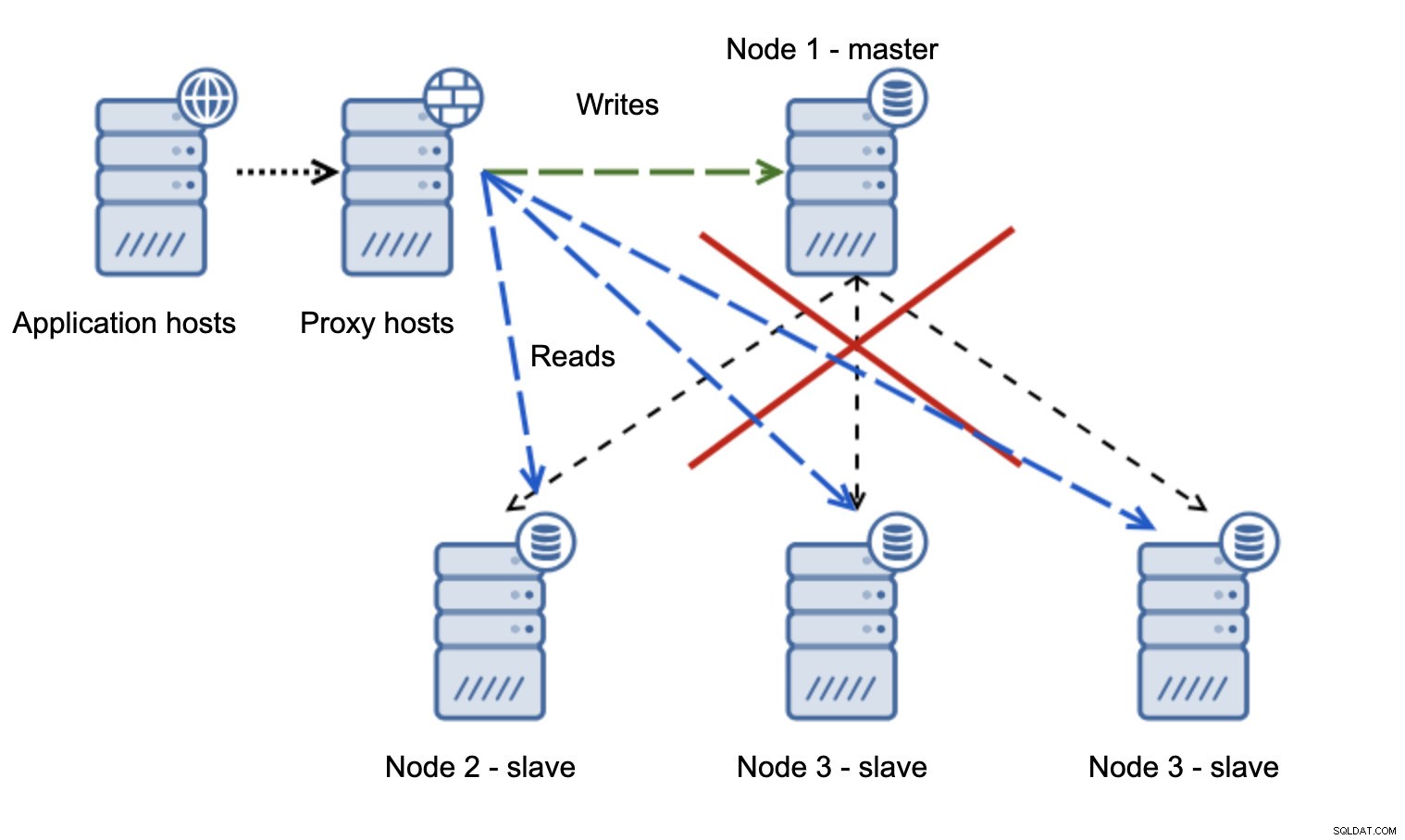
ネットワークによってマスターが到達不能になると、宛先への書き込みが行われないため、アプリケーションは使用できなくなります。新しいマスターがプロモートされ、書き込みがリダイレクトされます。ネットワークの問題が停止し、古いマスターが到達可能になった場合はどうなりますか?停止されていないため、引き続きread_only =0を使用しています:
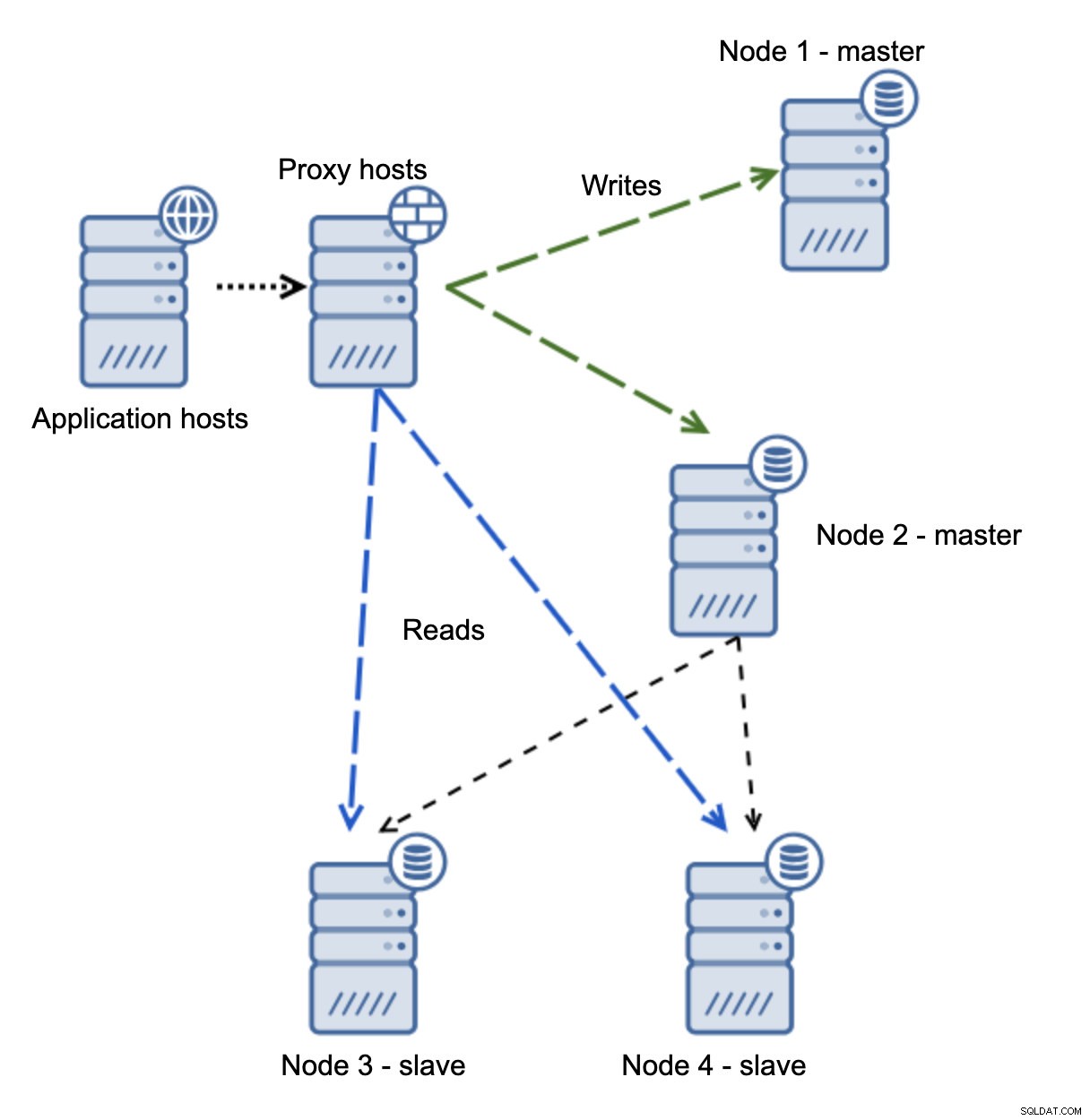
書き込みが2つのノードに向けられたとき、あなたはスプリットブレインになってしまいました。分岐したデータセットをマージするには時間がかかる場合があり、非常に複雑なプロセスであるため、この状況はかなり悪いです。
この問題を回避するために何ができるでしょうか?特効薬はありませんが、スプリットブレインが発生する可能性を最小限に抑えるためにいくつかのアクションを実行できます。
まず第一に、あなたはマスターの状態をより賢く検出することができます。奴隷はそれをどのように見ていますか?彼らはそれから複製できますか?おそらく、一部のスレーブはまだマスターに接続できます。つまり、マスターは稼働中であるか、少なくとも、必要に応じてマスターを停止できるようになっています。プロキシレイヤーはどうですか?すべてのプロキシノードはマスターを使用不可と見なしますか?それでも接続できるものがある場合は、それらのノードを利用してマスターにSSHで接続し、フェイルオーバーの前に停止することができますか?
フェイルオーバー管理ソフトウェアは、ネットワークの状態をよりスマートに検出することもできます。たぶん、RAFTまたは他のクラスタリングプロトコルを利用して、クォーラム対応クラスターを構築します。フェイルオーバー管理ソフトウェアがスプリットブレインを検出できる場合は、これに基づいていくつかのアクションを実行することもできます。たとえば、パーティションセグメント内のすべてのノードをread_onlyに設定して、ネットワークが収束したときに古いマスターが書き込み可能として表示されないようにします。
クラスターの状態を保存するために、ConsulやEtcdなどのツールを含めることもできます。プロキシ層は、read_only変数の状態ではなく、Consulからのデータを使用するように構成できます。その後、すべてのプロキシがトラフィックを正しい新しいマスターに送信するように、Consulで必要な変更を加えるのはフェイルオーバー管理ソフトウェア次第です。
これらのヒントのいくつかを組み合わせて、障害検出の信頼性をさらに高めることもできます。全体として、レプリケーションクラスターが信頼性の低いネットワークに悩まされる可能性を最小限に抑えることができます。
ご覧のとおり、GaleraまたはMySQLレプリケーションのどちらについて話していても、不安定なネットワークが深刻な問題になる可能性があります。一方、環境を正しく設計すれば、それでも機能させることができます。このブログ投稿が、ネットワークが安定していない場合でも安定して動作する環境の作成に役立つことを願っています。