目標復旧時間(RTO)は、許容できない結果を回避するためにサービスを復元する必要がある期間です。データベース障害からの回復にかかる時間を計算することで、必要な準備のレベルを知ることができます。 RTOが数分である場合、フェイルオーバーへの多額の投資が必要です。 36時間のRTOは、大幅に少ない投資で済みます。これがフェイルオーバーの自動化の出番です。
以前のブログでは、MongoDB、MySQL / MariaDB / Percona、PostgreSQL、またはTimeScaleDBのフェイルオーバーについて説明しました。要約すると、「フェイルオーバー 「は、何らかの障害が発生した場合でもシステムが機能し続ける能力です。これは、プライマリコンポーネントに障害が発生した場合に、システムの機能がセカンダリコンポーネントによって引き継がれることを示しています。フェイルオーバーは、高可用性システムの自然な部分であり、場合によっては、自動化する必要もあります。手動フェイルオーバーには時間がかかりすぎますが、自動化がうまく機能しない場合があります。たとえば、データベースレプリケーションが壊れており、2つの「半分」が効果的に更新を受信し続けるスプリットブレインの場合です。データセットの多様化と不整合につながります。
以前、ClusterControlの自動フェイルオーバー手順の背後にある基本原則について説明しました。可能な場合、自動フェイルオーバーは障害からの迅速な回復を可能にするため、効率を提供します。このブログでは、ClusterControlを使用してマスタースレーブ(またはプライマリスタンバイ)レプリケーションのセットアップで自動フェイルオーバーを実現する方法について説明します。
テクノロジースタックの要件
スタックはオープンソースソフトウェアコンポーネントから組み立てることができ、利用可能なオプションがいくつかあります。フェイルオーバーの特性やソリューションの管理と保守に利用できる専門知識のレベルに応じて、他のオプションよりも適切なものもあります。ハードウェアとネットワーキングも重要な側面です。
ソフトウェア
フェイルオーバーを実装するために使用できるオープンソースエコシステムで利用可能なオプションはたくさんあります。 MySQLの場合、MHA、MMM、Maxscale / MRM、mysqlfailover、またはOrchestratorを利用できます。この以前のブログでは、MaxScaleとMHA、Maxscale/MRMを比較しています。 PostgreSQLには、repmgr、Patroni、PostgreSQL自動フェイルオーバー(PAF)、pglookout、pgPool-II、またはstolonがあります。これらのさまざまな高可用性オプションについては、以前に説明しました。 MongoDBには、自動フェイルオーバーをサポートするレプリカセットがあります。
ClusterControlは、MySQL、MariaDB、PostgreSQL、およびMongoDBの自動フェイルオーバー機能を提供します。これについては、さらに詳しく説明します。壊れたノードまたはクラスターを自動的に回復する機能もあることに注意してください。
ハードウェア
自動フェイルオーバーは通常、データベースノードとは別の独自のハードウェア上にセットアップされた別のデーモンサーバーによって実行されます。データベースのステータスを監視し、その情報を使用して、障害が発生した場合の対応方法を決定します。
サーバーが膨大な数のインスタンスを監視していない限り、コモディティサーバーは正常に機能します。通常、システムチェックとヘルス分析は処理の点で軽量です。ただし、チェックするノードが多数ある場合は、サーバーからpingを実行して情報を収集しようとするため、チェックをキューに入れる必要がある場合は特に、CPUとメモリを大きくする必要があります。監視および監視されているノードは、ネットワークの問題や高負荷が原因で停止する場合があります。さらに悪い場合は、ハードウェア障害やVMホストの破損が原因でノードがダウンする場合があります。したがって、ヘルスチェックとシステムチェックを実行するサーバーは、このようなストールに耐えることができます。監視対象の各ノードへの応答が使用できなくなったか、タイムアウトが発生したことが確認されるまで時間がかかる可能性があるため、キューの処理が上がる可能性があります。到達しました。
クラウドベースの環境には、自動フェイルオーバーを提供するサービスがあります。たとえば、AmazonRDSはDRBDを使用してストレージをスタンバイノードに複製します。または、ボリュームをEBSに保存している場合、これらは複数のゾーンに複製されます。
ネットワーク
自動フェイルオーバーソフトウェアは、多くの場合、データベースノードにセットアップされているエージェントに依存しています。エージェントはデータベースインスタンスからローカルに情報を収集し、要求があればいつでもサーバーに送信します。
ネットワーク要件に関しては、十分な帯域幅と安定したネットワーク接続があることを確認してください。チェックは頻繁に行う必要があり、ネットワークが不安定なためにハートビートが失われると、フェイルオーバーソフトウェアがノードがダウンしていると(誤って)推測する可能性があります。
ClusterControlは、定期的に各データベースノードにSSHで接続し、いくつかのチェックを実行するため、データベースノードにエージェントをインストールする必要はありません。
ClusterControlによる自動フェイルオーバー
ClusterControlは、手動フェイルオーバーと自動フェイルオーバーを実行する機能を提供します。これがどのように行われるか見てみましょう。
ClusterControlのフェイルオーバーは、自動にするかどうかを構成できます。フェイルオーバーを手動で処理する場合は、クラスターの自動回復を無効にすることができます。手動フェイルオーバーを実行する場合は、クラスター→トポロジに移動できます。 ClusterControlで。以下のスクリーンショットを参照してください:
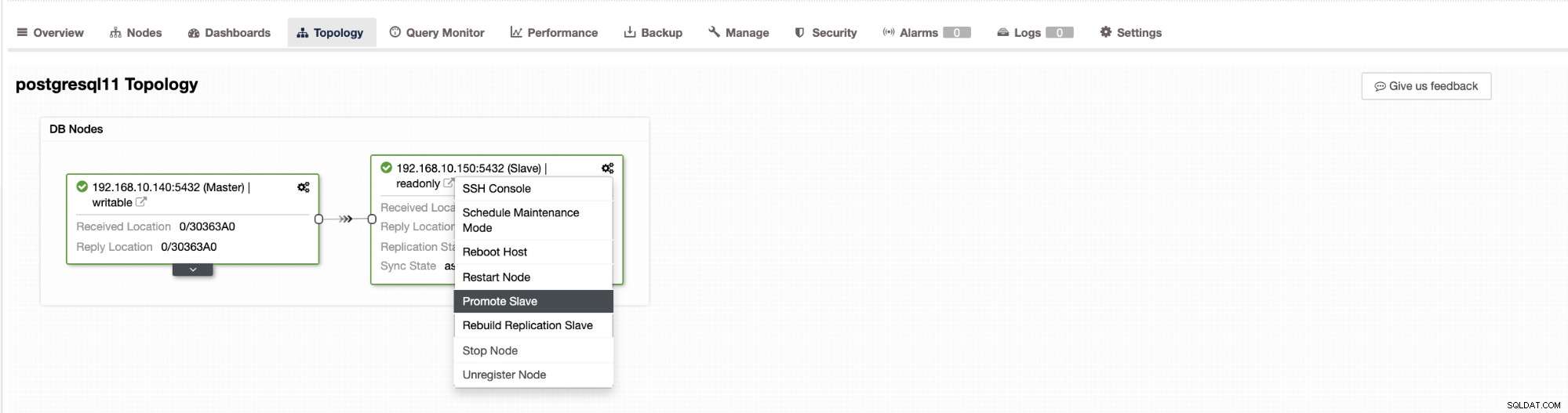
デフォルトでは、クラスターリカバリが有効になっており、自動フェールオーバーが使用されます。 UIを変更すると、ランタイム構成が変更されます。コントローラの再起動後も設定を維持したい場合は、cmon構成も変更してください。つまり、 /etc/cmon.d/cmon_

MySQL / MariaDB / Perconaサーバーでは、 read_only のホストがないことを検出すると、ClusterControlによって自動フェイルオーバーが開始されます。 フラグが無効です。マスター( read_only 0に設定)は使用できないか、マスターでこのフラグを変更したユーザーまたは外部ソフトウェアによってトリガーされる可能性があります。データベースノードを手動で変更する場合、またはread_only設定をいじる可能性のあるソフトウェアがある場合は、自動フェイルオーバーを無効にする必要があります。 ClusterControlの自動フェイルオーバーは1回だけ試行されるため、失敗したフェイルオーバーの後に後続のフェイルオーバーが続くことはありません。cmonが再起動されるまでです。
PostgreSQLの場合、ClusterControlは、データベースのバージョンに応じてpg_current_xlog_location(PostgreSQL 9以降)またはpg_current_wal_lsn(PostgreSQL 10以降)を使用して、最も高度なスレーブを選択します。 ClusterControlは、いくつかの一般的な間違いを回避するために、フェイルオーバープロセスに対していくつかのチェックも実行します。 1つの例は、失敗した古いマスターを回復できた場合、「しない」というものです。 「マスターとしてもスレーブとしても、クラスターに自動的に再導入されます。手動で行う必要があります。これにより、その時点で(昇格した)スレーブが遅延した場合に、データの損失や不整合が発生する可能性を回避できます。また、問題をレプリケーションセットアップに再導入する前に詳細に分析したい場合があるため、診断情報を保持する必要があります。
また、フェイルオーバーが失敗した場合、それ以上の試行は行われません(これはPostgreSQLベースとMySQLベースのクラスターの両方に適用されます)。問題を分析して対応するアクションを実行するには、手動による介入が必要です。これは、自動フェイルオーバーを処理するClusterControlが次のスレーブと次のスレーブをプロモートしようとする状況を回避するためです。問題がある可能性があり、複数のフェイルオーバーを試行して事態を悪化させたくはありません。
ClusterControlは、フェイルオーバーに参加する、または候補として除外する一連のサーバーのホワイトリストとブラックリストを提供します。
MySQLタイプのクラスターの場合、ClusterControlは、マスターに昇格できるスレーブのリストを作成します。ほとんどの場合、トポロジ内のすべてのスレーブが含まれますが、ユーザーはそれをさらに制御できます。 cmon構成で設定できる変数は2つあります。
replication_failover_whitelistおよび
replication_failover_blacklist構成変数replication_failover_whitelistには、潜在的なマスター候補として使用する必要があるスレーブのIPまたはホスト名のリストが含まれています。この変数が設定されている場合、それらのホストのみが考慮されます。変数replication_failover_blacklistの場合、マスター候補とは見なされないホストのリストが含まれます。これを使用して、バックアップまたは分析クエリに使用されるスレーブを一覧表示できます。ハードウェアがスレーブ間で異なる場合は、低速のハードウェアを使用するスレーブをここに配置することをお勧めします。
Replication_failover_whitelistが優先されます。つまり、replication_failover_whitelistが設定されている場合、replication_failover_blacklistは無視されます。
マスターに昇格できるスレーブのリストの準備が整うと、ClusterControlは状態の比較を開始し、最新のスレーブを探します。ここでは、MariaDBとMySQLベースのセットアップの処理が異なります。 MariaDBセットアップの場合、ClusterControlは、使用可能なすべてのスレーブの中でレプリケーションラグが最も小さいスレーブを選択します。 MySQLセットアップの場合、ClusterControlはそのようなスレーブも選択しますが、残りのスレーブの一部で実行された可能性のある追加の欠落トランザクションをチェックします。そのようなトランザクションが見つかった場合、ClusterControlは、欠落しているすべてのトランザクションを取得するために、そのホストからマスター候補をスレーブ化します。このプロセスをスキップして、CMON構成で変数replication_skip_apply_missing_txsを設定することにより、最も高度なスレーブを使用できます。
例:
replication_skip_apply_missing_txs=1変数の詳細については、こちらのドキュメントを確認してください。
警告は、誤ったトランザクションが発生する可能性があるため、自分が何をしているかを知っている場合にのみこれを設定する必要があるということです。これらにより、レプリケーションが中断したり、クラスター全体でデータの不整合が発生したりする可能性があります。誤ったトランザクションが過去に発生した場合は、バイナリログで使用できなくなる可能性があります。その場合、スレーブは欠落しているデータを取得できないため、レプリケーションが中断されます。したがって、ClusterControlは、デフォルトで、マスター候補をマスターに昇格させる前に、誤ったトランザクションをチェックします。このような問題が検出された場合、マスタースイッチは中止され、ClusterControlによってユーザーは問題を手動で修正できます。
いくつかの問題が検出された場合でもClusterControlが新しいマスターをプロモートすることを100%確実にしたい場合は、replication_stop_on_error変数を使用してそれを行うことができます。以下を参照してください:
例:
replication_stop_on_error=0この変数をcmon構成ファイルに設定します。前述のように、スレーブが使用できなくなったバイナリログイベントを要求し始める可能性があるため、レプリケーションで問題が発生する可能性があります。このようなケースを処理するために、スレーブの再構築の実験的なサポートを追加しました。変数を設定した場合
replication_auto_rebuild_slave=1cmon構成で、MySQLでスレーブがダウンとしてマークされている場合:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControlは、マスターからのデータを使用してスレーブを再構築しようとします。再構築プロセスによってマスターの負荷が増加するため、このような設定は必ずしも適切ではない場合があります。データセットが非常に大きく、定期的な再構築がオプションではない可能性もあります。そのため、この動作はデフォルトで無効になっています。
誤ったトランザクションが存在せず、問題がないことを確認した後も、何らかの方法で処理する必要のある問題がもう1つあります。すべてのスレーブがマスターに遅れをとっている可能性があります。
ご存知かもしれませんが、MySQLでのレプリケーションはかなり単純な方法で機能します。マスターは書き込みをバイナリログに保存します。スレーブのI/Oスレッドはマスターに接続し、欠落しているバイナリログイベントをプルします。次に、それらをリレーログの形式で保存します。 SQLスレッドはそれらを解析し、イベントを適用します。スレーブラグは、SQLスレッド(または複数のスレッド)がイベントの数に対応できず、I/Oスレッドによってマスターからプルされるとすぐにイベントを適用できない状態です。このような状況は、使用しているレプリケーションのタイプに関係なく発生する可能性があります。半同期レプリケーションを使用する場合でも、マスターからのすべてのイベントがリレーログのスレーブの1つに保存されることを保証することしかできません。それらのイベントをスレーブに適用することについては何も述べていません。
ここでの問題は、スレーブがマスターに昇格すると、リレーログが消去されることです。スレーブが遅れていて、すべてのトランザクションを適用していない場合、データは失われます。リレーログからまだ適用されていないイベントは永久に失われます。
この状況を解決するための万能の方法はありません。 ClusterControlを使用すると、ユーザーは安全なデフォルトを維持しながら、実行方法を制御できます。これは、次の設定を使用してcmon構成で実行されます。
replication_failover_wait_to_apply_timeout=-1デフォルトでは「-1」の値を取ります。これは、マスター候補が遅れている場合にフェイルオーバーがすぐに発生しないことを意味するため、候補が追いつかない限り、永久に待機するように設定されています。 ClusterControlは、リレーログから欠落しているすべてのトランザクションを適用するのを無期限に待機します。これは安全ですが、何らかの理由で最新のスレーブがひどく遅れている場合、フェイルオーバーが完了するまでに数時間かかる場合があります。スペクトルの反対側では、「0」に設定しています。これは、マスター候補が遅れているかどうかに関係なく、フェイルオーバーがすぐに発生することを意味します。途中で値を設定することもできます。これにより、時間が秒単位で設定されます。たとえば、30秒なので、変数を
に設定します。replication_failover_wait_to_apply_timeout=30> 0に設定すると、ClusterControlは、マスター候補がリレーログから欠落しているトランザクションを適用するのを、値が満たされるまで待機します(この例では30秒)。フェイルオーバーは、定義された時間の後、またはマスター候補がレプリケーションに追いつくときのいずれか早い方で発生します。これは、アプリケーションにダウンタイムに関する特定の要件があり、短い時間枠内に新しいマスターを選択する必要がある場合に適しています。
ClusterControlがPostgreSQLおよびMySQLの自動フェイルオーバーでどのように機能するかについての詳細は、「PostgreSQLレプリケーション101のフェイルオーバー」および「MySQLレプリケーションの自動フェイルオーバー-ClusterControl1.4の新機能」というタイトルの以前のブログを確認してください。
結論
自動フェイルオーバーは、特に最小限のダウンタイムで24時間年中無休の運用を必要とする企業にとって価値のある機能です。ビジネスでは、計画外の停止時に自動化プロセスにどの程度の制御を与えるかを定義する必要があります。 ClusterControlのような高可用性ソリューションは、フェイルオーバー処理でカスタマイズ可能なレベルの対話を提供します。一部の組織では、フェイルオーバー中のユーザーの操作が時間を浪費し、RTOに影響を与える可能性がある場合でも、自動フェイルオーバーはオプションではない場合があります。自動フェイルオーバーが正しく機能しない場合、またはさらに悪いことに、データが混乱して部分的に失われる場合はリスクが高すぎると想定されます(ただし、人間も同様の結果につながる悲惨なミスを犯す可能性があると主張する場合があります)。データベースを厳密に制御したい場合は、自動フェイルオーバーをスキップして、代わりに手動プロセスを使用することを選択できます。このようなプロセスには時間がかかりますが、経験豊富な管理者がシステムの状態を評価し、何が起こったかに基づいて修正措置を講じることができます。