MySQLマスタースレーブレプリケーションは、セットアップが非常に簡単で簡単です。これが、データベースの可用性を向上させるための最初のステップとしてこのテクノロジーを選択する主な理由です。ただし、管理と保守が複雑になるという代償が伴います。特にフェイルオーバー、フェイルバック、メンテナンス、アップグレードなどの際にデータの整合性を維持するのは管理者の責任です。
レプリケーション設定のフェイルオーバー操作を実行する方法について説明している記事はたくさんあります。このトピックについては、このブログ投稿「MySQLレプリケーションのフェイルオーバーの概要-101ブログ」でも取り上げています。このブログ投稿では、元のトポロジに復元する際の災害後のタスク、つまりフェイルバック操作の実行について説明します。
なぜフェイルバックが必要なのですか?
レプリケーションリーダー(マスター)は、レプリケーションセットアップで最も重要なノードです。書き込みの処理、レプリケーションイベントの生成、重要な読み取りの処理などを安定した方法で実行できるようにするには、優れたハードウェア仕様が必要です。災害復旧またはメンテナンス中にフェイルオーバーが必要な場合、劣ったハードウェアを備えた新しいリーダーを宣伝することは珍しくありません。この状況は一時的には問題ないかもしれませんが、長期的には、正常であると見なされた後、指定されたマスターを元に戻してレプリケーションを主導する必要があります。
フェイルオーバーとは異なり、フェイルバック操作は通常、スイッチオーバーによって制御された環境で発生しますが、パニックモードで発生することはめったにありません。これにより、運用チームは慎重に計画を立て、スムーズに移行できるように演習をリハーサルする時間ができます。主な目的は、古き良きマスターを最新の状態に戻し、レプリケーション設定を元のトポロジに復元することです。ただし、新しく昇格したマスターが期待どおりに機能せず、データベースサービス全体に影響を与える場合など、フェールバックが重要な場合があります。
フェイルバックを安全に実行する方法
フェイルオーバーが発生した後、古いマスターはメンテナンスまたはリカバリのためにレプリケーションチェーンから外れます。スイッチオーバーを実行するには、次のことを行う必要があります。
- 最新のスレーブにすることで、古いマスターを正しい状態にプロビジョニングします。
- アプリケーションを停止します。
- すべてのスレーブが追いついていることを確認します。
- 古いマスターを新しいリーダーとして昇進させます。
- すべてのスレーブを新しいマスターに再ポイントします。
- 新しいマスターに書き込んでアプリケーションを起動します。
次のレプリケーション設定を検討してください。
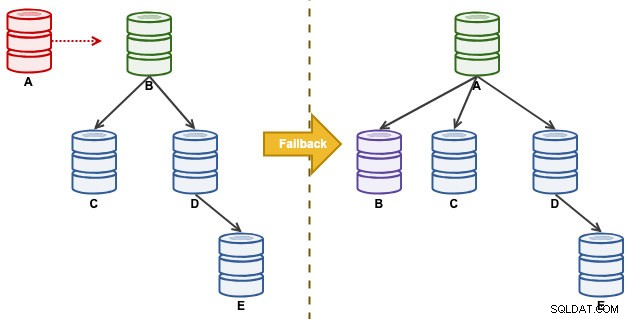
「A」は、ディスクがいっぱいになるまでマスターであり、レプリケーションチェーンに大混乱を引き起こしました。フェイルオーバーイベントの後、レプリケーショントポロジはBによってリードされ、EまでCにレプリケートされます。フェイルバックの演習では、Aがリーダーとして復帰し、災害前の元のトポロジが復元されます。すべてのノードがGTIDを有効にしたMySQL8.0.15で実行されていることに注意してください。メジャーバージョンが異なれば、使用するコマンドや手順も異なる場合があります。
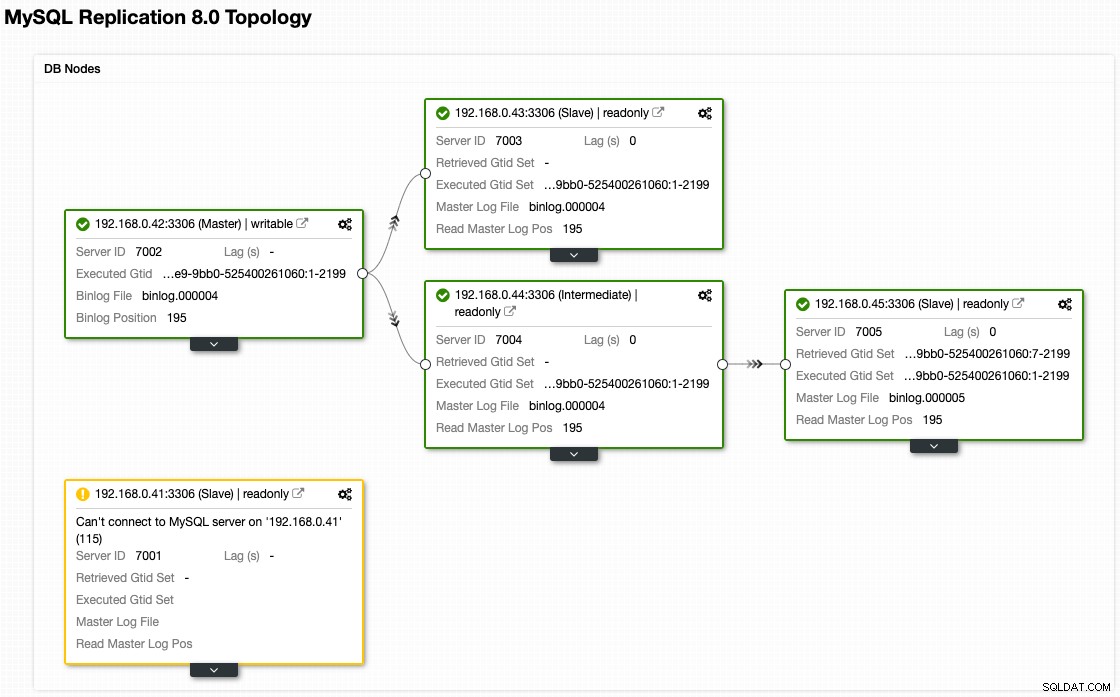
これは、フェイルオーバー後のアーキテクチャの外観です(ClusterControlのトポロジビューから取得):
ノードプロビジョニング
Aをマスターにする前に、Aを現在のデータベースの状態で最新の状態にする必要があります。これを行う最良の方法は、AをアクティブマスターBのスレーブにすることです。すべてのノードがlog_slave_updates =ONで構成されているため(スレーブもバイナリログを生成することを意味します)、実際にはCやDなどの他のスレーブを次のように選択できます。初期同期の信頼できる情報源。ただし、アクティブなマスターに近いほど良いです。バックアップを取るときに発生する可能性のある追加の負荷に注意してください。この部分は、フェイルバック時間のほとんどを要します。ノードの状態とデータセットのサイズによっては、古いマスターの同期に時間がかかる場合があります(数時間から数日かかる場合があります)。
「A」の問題が解決され、レプリケーションチェーンに参加する準備ができたら、最初の最善のステップは、CHANGE MASTERステートメントを使用して「B」(192.168.0.42)からのレプリケーションを試行することです。
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */レプリケーションが機能する場合は、レプリケーションステータスに次のように表示されます。
Slave_IO_Running: Yes
Slave_SQL_Running: Yesレプリケーションが失敗した場合は、スレーブステータス出力からLast_IO_ErrorまたはLast_SQL_Errorを確認してください。たとえば、次のエラーが表示された場合:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2次に、現在アクティブなマスターBにレプリケーションユーザーを作成する必要があります:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;次に、Aでスレーブを再起動して、複製を再開します。
mysql> STOP SLAVE;
mysql> START SLAVE;表示されるその他の一般的なエラーは次の行です:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...これはおそらく、スレーブが現在のマスターからのバイナリログファイルの読み取りに問題があることを意味します。場合によっては、スレーブが大幅に遅れて、レプリケーションを開始するために必要なバイナリイベントが現在のマスターから欠落しているか、フェイルオーバー中にマスター上のバイナリがパージされている可能性があります。この場合、最良の方法は、Bで完全バックアップを取り、Aでそれを復元することによって完全同期を実行することです。Bでは、mysqldumpまたはPerconaXtrabackupのいずれかを使用して完全バックアップをとることができます。
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupバックアップファイルをAに転送し、既存のMySQLインストールを再初期化して適切なクリーンアップを行い、データベースの復元を実行します。
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root password復元したら、アクティブマスターB(192.168.0.42)へのレプリケーションリンクを設定し、読み取り専用を有効にします。 Aで、次のステートメントを実行します。
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Percona Xtrabackupについては、Aに復元する方法についてのドキュメントページを参照してください。これには、MySQLデータディレクトリを置き換える前に、最初にバックアップを準備するための前提条件の手順が含まれます。
Aが正しく複製を開始したら、スレーブ状態のSeconds_Behind_Masterを監視します。これにより、スレーブがどれだけ置き去りにされたか、追いつくまでにどれくらい待つ必要があるかがわかります。この時点で、アーキテクチャは次のようになります。
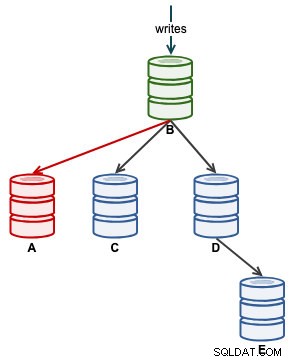
Seconds_Behind_Masterが0にフォールバックすると、それはAが最新のスレーブとして追いついた瞬間です。
ClusterControlを使用している場合は、既存のバックアップから復元してノードを再同期するか、アクティブなマスターノードから直接バックアップを作成してストリーミングするかを選択できます。
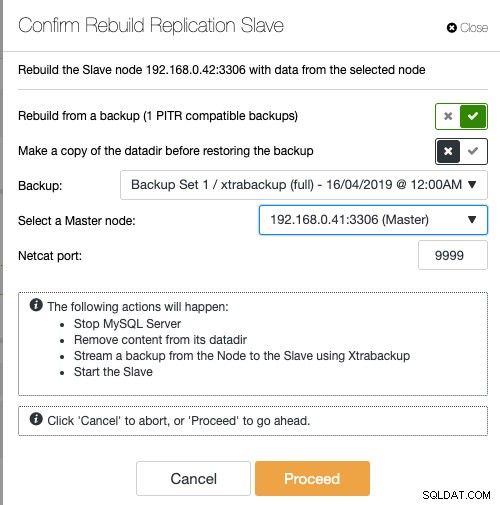
スレーブを構築するには、既存のバックアップを使用してスレーブをステージングすることをお勧めします。これは、ノードの準備時にアクティブなマスターサーバーに影響を与えないためです。
オールドマスターを宣伝する
Aを新しいマスターとして昇格させる前に、最も安全な方法は、Bでのすべての書き込み操作を停止することです。これが不可能な場合は、Bを強制的に読み取り専用モードで操作します。
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';次に、Aで、SHOW SLAVE STATUSを実行し、次のレプリケーションステータスを確認します。
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesRead_Master_Log_PosとExec_Master_Log_Posの値は同一である必要がありますが、Seconds_Behind_Masterは0であり、状態は「スレーブはすべてのリレーログを読み取りました」である必要があります。すべてのスレーブがリレーログ内のステートメントを処理したことを確認してください。そうしないと、新しいクエリがリレーログからのトランザクションに影響を与え、あらゆる種類の問題を引き起こすリスクがあります(たとえば、アプリケーションがトランザクションによってアクセスされる一部の行を削除する場合があります)リレーログから)。
Aで、レプリケーションを停止し、RESET SLAVE ALLステートメントを使用して、レプリケーション関連のすべての構成を削除し、読み取り専用を無効にします。
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';この時点で、Aは書き込みを受け入れる準備ができています(read_only =OFF)が、以下に示すように、スレーブはそれに接続されていません。
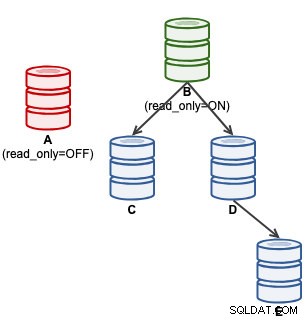
ClusterControlユーザーの場合、Aの昇格は、ノードアクションの「スレーブの昇格」機能を使用して実行できます。 ClusterControlは、アクティブなマスターBを自動的に降格し、スレーブAをマスターとして昇格させ、CとDを再ポイントしてAから複製します。Bは脇に置かれ、ユーザーは「複製マスターの変更」を明示的に選択して、後の段階でAから複製するBに再参加する必要があります。 。
スレーブのリポイント
これで、関連するスレーブのマスターをA(192.168.0.41)から複製するように変更しても安全です。 Eを除くすべてのスレーブで、以下を構成します。
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;ClusterControlユーザーの場合、以前にAをプロモートすることを決定したときにリポイントが自動的に実行されるため、このステップをスキップできます。
次に、アプリケーションを開始してAに書き込むことができます。この時点で、アーキテクチャは次のようになっています。
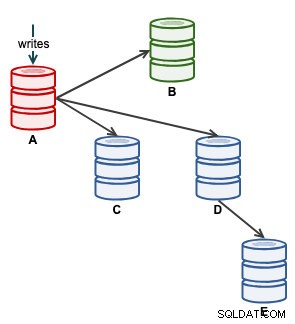
ClusterControlトポロジビューから、レプリケーションクラスターを次のような元のアーキテクチャに復元しました。
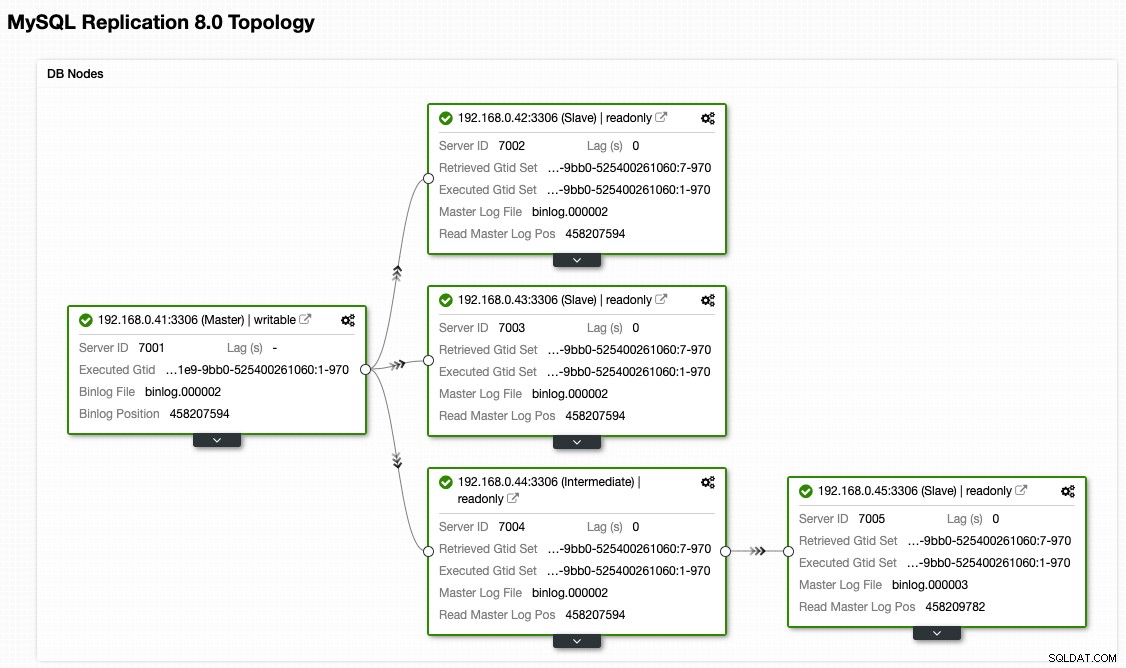
フェイルオーバーと比較した場合、フェイルバックの実行のリスクははるかに低いことに注意してください。ビジネスへの影響を最小限に抑えるために、この演習をオフピーク時にスケジュールすることが重要です。
最終的な考え
フェイルオーバーおよびフェイルバック操作は慎重に実行する必要があります。ノードの数が少ない場合、操作はかなり簡単ですが、複雑なレプリケーションチェーンを持つ複数のノードの場合、リスクが高く、エラーが発生しやすい演習になる可能性があります。また、ClusterControlを使用してUIを介して複雑な操作を実行する方法を示しました。さらに、トポロジビューがリアルタイムで視覚化されるため、構築するレプリケーショントポロジを理解できます。