前回のブログ投稿では、スケーリングの基本、つまり、スケーリングとは何か、タイプとは何か、スケーリングする場合に必須のものは何かについて説明しました。このブログ投稿では、課題とスケールアウトの方法に焦点を当てます。
データベースのスケーリングは、さまざまな理由から最も簡単な作業ではありません。データベースインフラストラクチャのスケールアウトに関連する課題に少し焦点を当てましょう。
ステートレスとステートフルの2種類のサービスを区別できます。ステートレスサービスは、既存のデータに依存しないサービスです。あなたはただ先に進んで、そのようなサービスを始めることができます、そしてそれはうまくいくでしょう。データの状態やサービスについて心配する必要はありません。稼働している場合は適切に機能し、既存のVM、コンテナなどのクローンまたはコピーを追加するだけで、トラフィックを複数のサービスインスタンスに簡単に分散できます。このようなサービスの例としては、リポジトリからデプロイされ、適切に構成されたWebサーバーを備えたWebアプリケーションがあります。このようなサービスは、正常に起動して機能します。
データベースの問題は、データベースがステートレスではないことです。データはデータベースに挿入する必要があり、処理して永続化する必要があります。データベースのイメージは、OSイメージ上にインストールされたほんの数個のパッケージにすぎず、データと適切な構成がなければ、かなり役に立ちません。これにより、データベースのスケーリングが複雑になります。ステートレスサービスの場合は、それらをデプロイし、ワークロードに新しいインスタンスを含めるようにいくつかのロードバランサーを構成するだけです。データベースをデプロイするデータベースの場合、インスタンスは単なる開始点です。さらに先にはデータ管理があります。既存のデータベースインスタンスから新しいデータベースインスタンスにデータを転送する必要があります。これは、新しいインスタンスがトラフィックの処理を開始するために必要な問題と時間の重要な部分になる可能性があります。データが転送された後でのみ、既存のレプリケーショントポロジの一部になるように新しいノードを設定できます。他のノードに到達するトラフィックに基づいて、データをリアルタイムで更新する必要があります。
データベースがステートフルサービスであるという事実は、データベースインフラストラクチャをスケールアウトするときに直面する2番目の課題の直接的な理由です。ステートレスサービス-開始するだけで、それだけです。それは非常に迅速なプロセスです。データベースの場合、データを転送する必要があります。どれくらいの時間がかかりますか、それは複数の要因に依存します。データセットの大きさはどれくらいですか?ストレージの速度はどれくらいですか?ネットワークの速度はどれくらいですか?新しいノードに新しいデータをプロビジョニングするために必要な他の手順は何ですか?その過程でデータは圧縮/解凍されていますか、それとも暗号化/復号化されていますか?現実の世界では、新しいノードにデータをプロビジョニングするのに数分から数時間かかる場合があります。これにより、データベース環境をスケールアップできるケースが大幅に制限されます。突然の一時的な負荷の急上昇?実際には、追加のデータベースノードを開始できるようになる前にそれらはずっとなくなっている可能性があります。突然の一貫した負荷の増加?はい、ノードを追加することで対処できますが、ノードを起動して既存のデータベースノードからのトラフィックを引き継ぐには数時間かかる場合があります。
スケールアップに必要な時間は、問題の1つの側面にすぎないことを覚えておくことが非常に重要です。反対側は、スケーリングプロセスによって引き起こされる負荷です。前述したように、データセット全体を新しく追加されたノードに転送する必要があります。これは無視できることではありません。結局のところ、ディスクからデータを読み取り、ネットワーク経由で送信し、新しい場所に保存するのに1時間かかる場合があります。データを読み取るノードであるドナーが過負荷になっている場合、追加の重いI / Oアクティビティを実行するように強制された場合に、ドナーがどのように動作するかを考慮する必要がありますか?クラスターがすでに大きなプレッシャーにさらされて薄く広がっている場合、クラスターは追加のワークロードを引き受けることができますか?ノードへの負荷はさまざまな形で発生する可能性があるため、答えを得るのは簡単ではないかもしれません。 I / Oアクティビティは低く、追加のディスク操作を管理できるため、CPUバウンドの負荷が最良のシナリオになります。一方、I / Oバウンドの負荷は、データ転送を大幅に遅くし、クラスターのスケーリング能力に深刻な影響を与える可能性があります。
前述のスケールアウトプロセスは、読み取りのスケーリングにかなり限定されています。書き込みのスケーリングはまったく別の話であることを理解することが最も重要です。ノードを追加し、より多くのバックエンドノードに読み取りを分散するだけで、読み取りをスケーリングできます。書き込みのスケーリングはそれほど簡単ではありません。手始めに、そのように書き込みをスケールアウトすることはできません。データセットにすべての変更を適用するだけで一貫性を維持できるため、データセット全体を含むすべてのノードは、明らかに、クラスター内のどこかで実行されるすべての書き込みを処理する必要があります。したがって、考えてみると、クラスターをどのように設計し、どのテクノロジーを使用するかに関係なく、クラスターのすべてのメンバーがすべての書き込みを実行する必要があります。レプリカであるかどうかにかかわらず、GaleraやInnoDBクラスターなどのマルチマスタークラスター内のマスターまたはノードからのすべての書き込みを複製して、クラスターの他のすべてのノードで実行されるデータセットへのすべての変更を実行します。結果は同じです。書き込みは、クラスターにノードを追加するだけではスケールアウトしません。
データベースをスケールアウトするにはどうすればよいですか?
つまり、私たちは直面している課題の種類を知っています。私たちが持っているオプションは何ですか?データベースをスケールアウトするにはどうすればよいですか?
何よりもまず、ノードを追加するだけでスケールアウトします。確かに、それは時間と確かに時間がかかります、それはあなたがすぐに起こると期待できるプロセスではありません。もちろん、そのような書き込みをスケールアウトすることはできません。一方、直面する最も一般的な問題は、SELECTクエリによって引き起こされるCPU負荷であり、前述したように、クラスターにノードを追加するだけで読み取りを簡単にスケーリングできます。読み取るノードが増えると、各ノードの負荷が軽減されます。アプリケーションのライフサイクルへの旅の始めにいるときは、これがあなたが扱っているものであると仮定してください。 CPU負荷、効率的なクエリではありません。アプリケーションがすでに成熟していて、顧客の数に対処する必要があるライフサイクルのさらに先まで、書き込みをスケールアウトする必要がある可能性はほとんどありません。
ノードを追加しても、書き込みの問題は解決されません。これが私たちが確立したことです。代わりに行う必要があるのは、シャーディングです。つまり、データセットをクラスター全体に分割します。この場合、各ノードにはデータのすべてではなく、一部のみが含まれます。これにより、最終的に書き込みのスケーリングを開始できます。 4つのノードがあり、それぞれにデータセットの半分が含まれているとします。
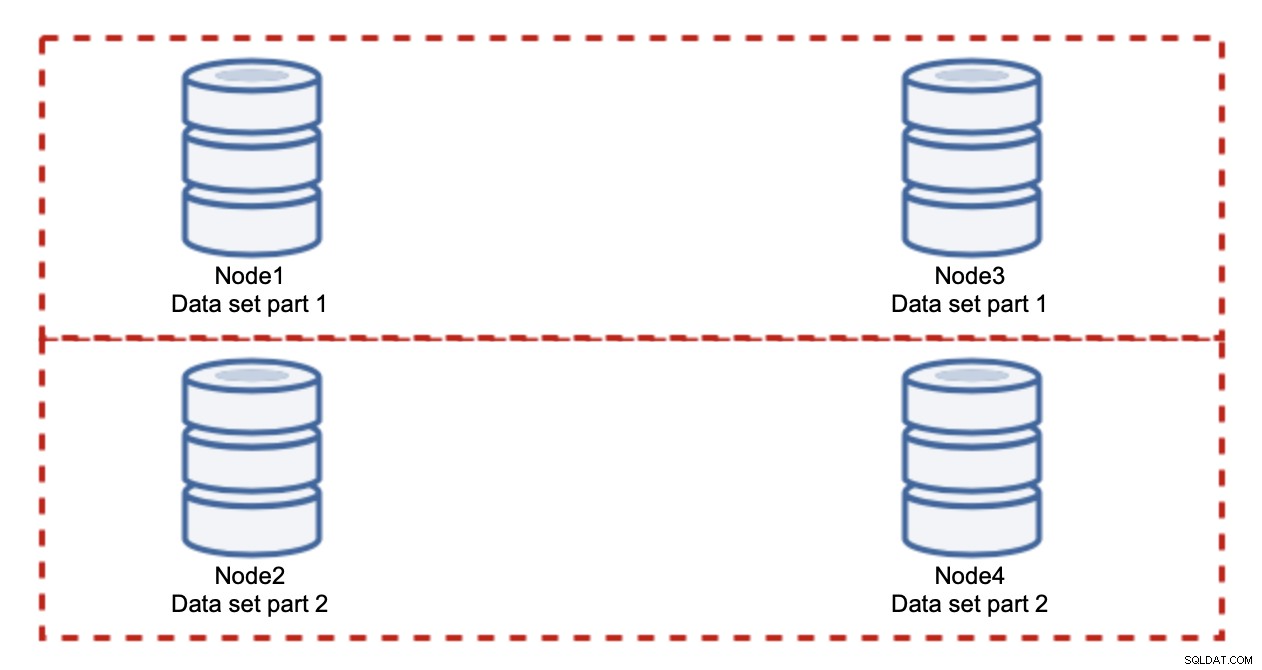
ご覧のとおり、アイデアは単純です。書き込みがデータセットのパート1に関連している場合、書き込みはノード1とノード3で実行されます。データセットのパート2に関連している場合は、ノード2とノード4で実行されます。データベースノードは、RAID内のディスクと考えることができます。ここに、冗長性のための2対のミラーであるRAID10の例があります。実際の実装では、より複雑な場合があり、高可用性を向上させるためにデータのレプリカが複数ある場合があります。要点は、データが完全に公平に分割されていると仮定すると、書き込みの半分がノード1とノード3に、残りの半分がノード2と4にヒットすることです。負荷をさらに分割する場合は、ノードの3番目のペアを導入できます。
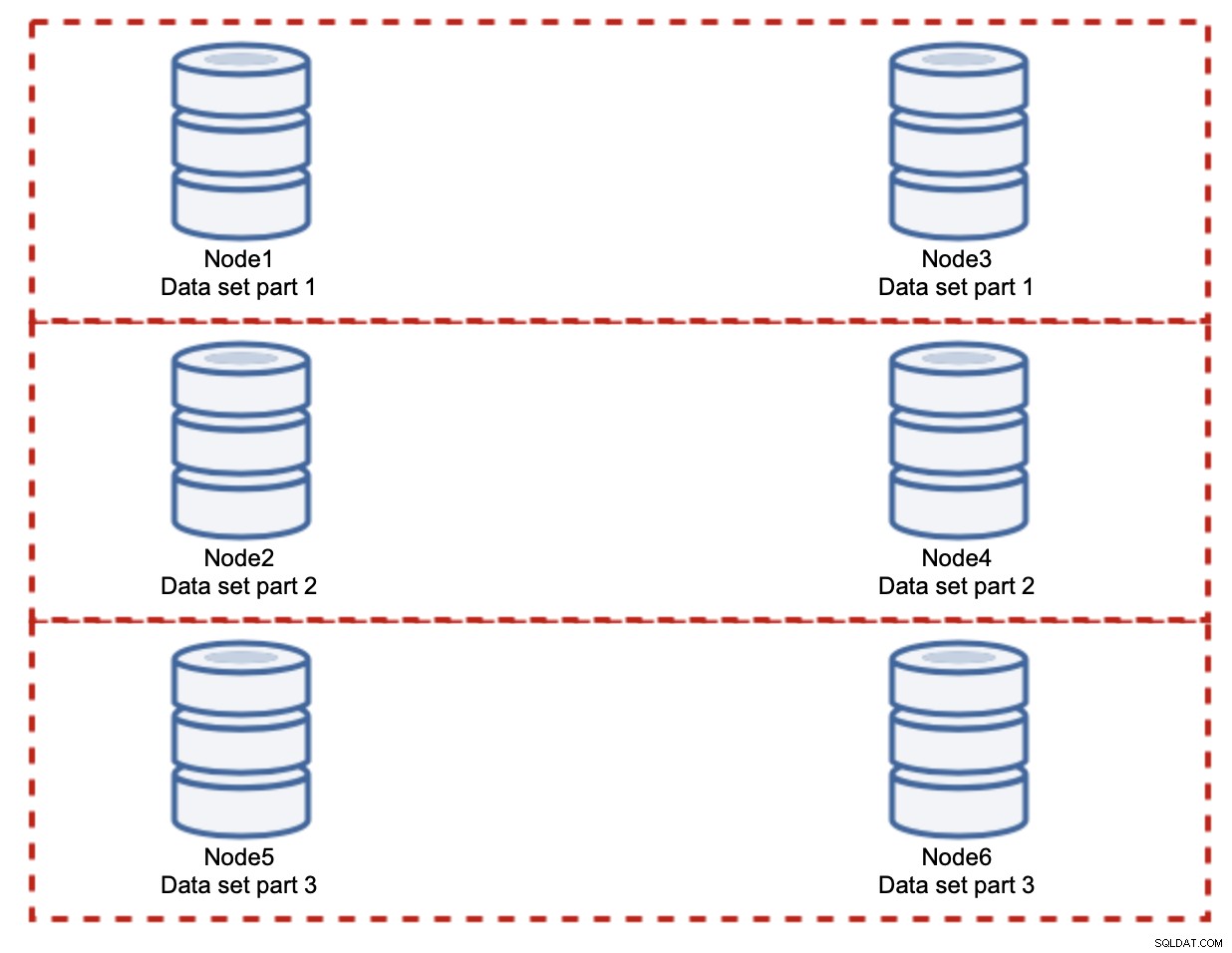
この場合も、完全に公平な分割を想定すると、各ペアはクラスタへのすべての書き込みの33%を担当します。
これは、シャーディングの概念をほぼ要約しています。この例では、シャードを追加することで、データベースノードでの書き込みアクティビティを元のI / O負荷の33%に減らすことができます。ご想像のとおり、これには欠点があります。
データが配置されているシャードを見つけるにはどうすればよいですか?詳細はこの呼び出しの範囲外ですが、要するに、特定の列にある種の関数('id'列のモジュロまたはハッシュ)を実装するか、詳細を格納する別のメタデータベースを構築することができますデータがどのように配布されるかについて。
この短いブログシリーズが参考になり、データベース環境をスケールアウトするときに直面するさまざまな課題について理解を深めていただければ幸いです。このトピックに関するコメントや提案がある場合は、この投稿の下にコメントして、経験を共有してください