最近、さまざまなクラウドプロバイダーがデータベースフェイルオーバーを処理する方法をカバーするいくつかのブログを作成しました。 Amazon Aurora、Amazon RDS、ClusterControlでフェイルオーバーのパフォーマンスを比較し、AmazonRDSとGoogleCloudPlatformでフェイルオーバーの動作をテストしました。これらのサービスはフェイルオーバーに関して優れたオプションを提供しますが、すべてのアプリケーションに適しているとは限りません。
このブログ投稿では、手動で、またはClusterControlなどのデータベース管理プラットフォームを使用して環境を設計する場合と比較して、DBaaSソリューションを使用することの長所と短所を分析するために少し時間を費やします。
既存のソリューションを使用する主な理由は、使いやすさです。数回クリックするだけで、自動フェイルオーバーを備えた高可用性ソリューションを展開できます。さまざまなツールを組み合わせたり、データベースを手動で管理したり、ツールを導入したり、スクリプトを作成したり、監視を設計したり、その他のデータベース管理操作を行ったりする必要はありません。すべてがすでに整っています。これにより、学習曲線が大幅に短縮され、データベースの高可用性環境をセットアップするために必要な経験が少なくなります。基本的に誰もがそのようなセットアップを展開できるようにします。
これらのソリューションのほとんどの場合、フェイルオーバープロセスは妥当な時間内に実行されます。 Amazon Auroraのように非常に速く、Google CloudPlatformSQLノードのようにやや遅くなる可能性があります。ほとんどの場合、これらのタイプの結果は許容範囲内です。
HAにマネージドソリューションを使用することの欠点
DBaaSソリューションは簡単に使用できますが、いくつかの重大な欠点もあります。手始めに、考慮すべきベンダーロックインコンポーネントが常にあります。アマゾンウェブサービスにクラスターをデプロイすると、そのプロバイダーから移行するのは非常に困難です。物理バックアップを介して完全なデータセットをダウンロードする簡単な方法はありません。ほとんどのプロバイダーでは、手動で実行された論理バックアップのみが使用可能です。もちろん、これを実現するためのオプションは常にありますが、通常は複雑で時間のかかるプロセスであり、結局のところ、ある程度のダウンタイムが必要になる場合があります。
AmazonRDSなどのプロバイダーの使用にも制限があります。一部のアクションは簡単に実行できません。これは、完全にユーザー制御された方法でデプロイされた環境(AWS EC2など)で実行するのは非常に簡単です。これらの制限のいくつかは他のブログですでに取り上げられていますが、要約すると、通常のMySQLGTIDベースのレプリケーションと同じレベルの柔軟性を提供するDBaaSサービスはありません。任意のスレーブを昇格させることができ、すべてのノードを他のノードから再スレーブすることができます...事実上すべてのアクションが可能です。 RDSのようなツールを使用すると、設計に起因する制限に直面し、回避することはできません。
問題は、パフォーマンスの詳細を理解する能力にもあります。独自の高可用性セットアップを設計すると、発生する可能性のある潜在的なパフォーマンスの問題について知識を深めることができます。一方、RDSおよび同様の環境は、ほとんど「ブラックボックス」です。はい、Amazon RDSがDRBDを使用してマスターのシャドウコピーを作成することを学びました。Auroraが共有のレプリケートされたストレージを使用して、非常に高速なフェイルオーバーを実装することを知っています。それは単なる一般的な知識です。何気なく気付くかもしれないもの以外に、これらのソリューションのパフォーマンスへの影響が何であるかを知ることはできません。それらに関連する一般的な問題は何ですか?それらのソリューションはどれくらい安定していますか?ソリューションの背後にいる開発者だけが確実に知っています。
DBaaSソリューションの代替手段は何ですか?
不思議に思うかもしれませんが、DBaaSに代わるものはありますか?結局のところ、UIを介してほとんどの一般的なアクションにアクセスできるマネージドサービスを実行すると非常に便利です。バックアップを作成および復元できます。フェイルオーバーは自動的に処理されます。環境は使いやすく、データベースを扱うための専任の経験豊富なスタッフがいない企業にとっては魅力的です。
ClusterControlは、クラウドベースのDBaaSサービスに代わる優れたサービスを提供します。オープンソースデータベースの展開、管理、および監視に使用できるグラフィカルユーザーインターフェイスを提供します。
数回クリックするだけで、自動フェイルオーバー(ほとんどのDBaaS製品よりも高速)、バックアップ管理、高度な監視、および外部ツールとの統合などの他の機能を備えた、可用性の高いデータベースクラスターを簡単にデプロイできます。 (例:SlackまたはPagerDuty)またはアップグレード管理。ベンダーロックインを完全に回避しながら、これらすべてを実現します。
ClusterControlは、SSHを使用してデータベースに接続できる限り、データベースがどこにあるかを気にしません。クラウド、オンプレミス、または複数のクラウドプロバイダーの混合環境でセットアップを行うことができます。接続が確立されている限り、ClusterControlは環境を管理できます。必要なソリューション(および、慣れていない、または認識していないソリューション)を利用することで、いつでも環境を完全に制御できます。
ClusterControlを使用して展開したセットアップが何であれ、従来の手動またはスクリプトによる方法で簡単に管理できます。 ClusterControlは、ClusterControlによって実行されるタスクをシェルスクリプトに組み込むことができるコマンドラインインターフェイスも提供します。必要なすべてのコントロールがあります。ブラックボックスはありません。環境のすべての部分は、ClusterControlによって組み合わされて展開されたオープンソースソリューションを使用して構築されます。
ClusterControlを使用してMySQLレプリケーションクラスターを簡単にデプロイできることを見てみましょう。 ClusterControlが1つのインスタンスにインストールされ、他のすべてのノードがClusterControlホストからSSH経由でアクセスできる環境が準備されていると仮定します。
「展開」ウィザードの選択から始めます。
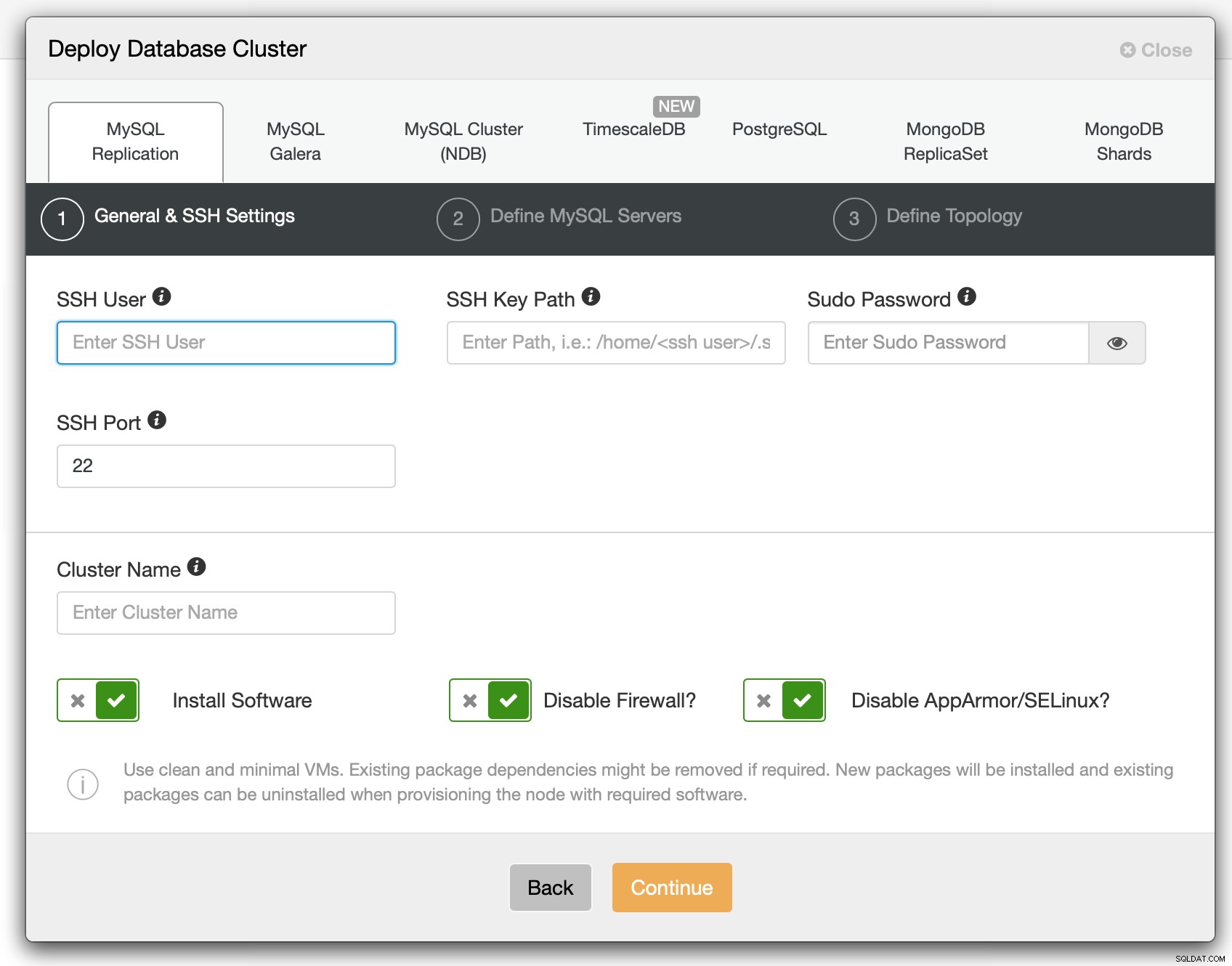
最初のステップでは、ClusterControlがノードに接続する方法を定義する必要があります。どのデータベースをデプロイするか。ルートアクセスまたはsudo(パスワードの有無にかかわらず)の両方がサポートされています。
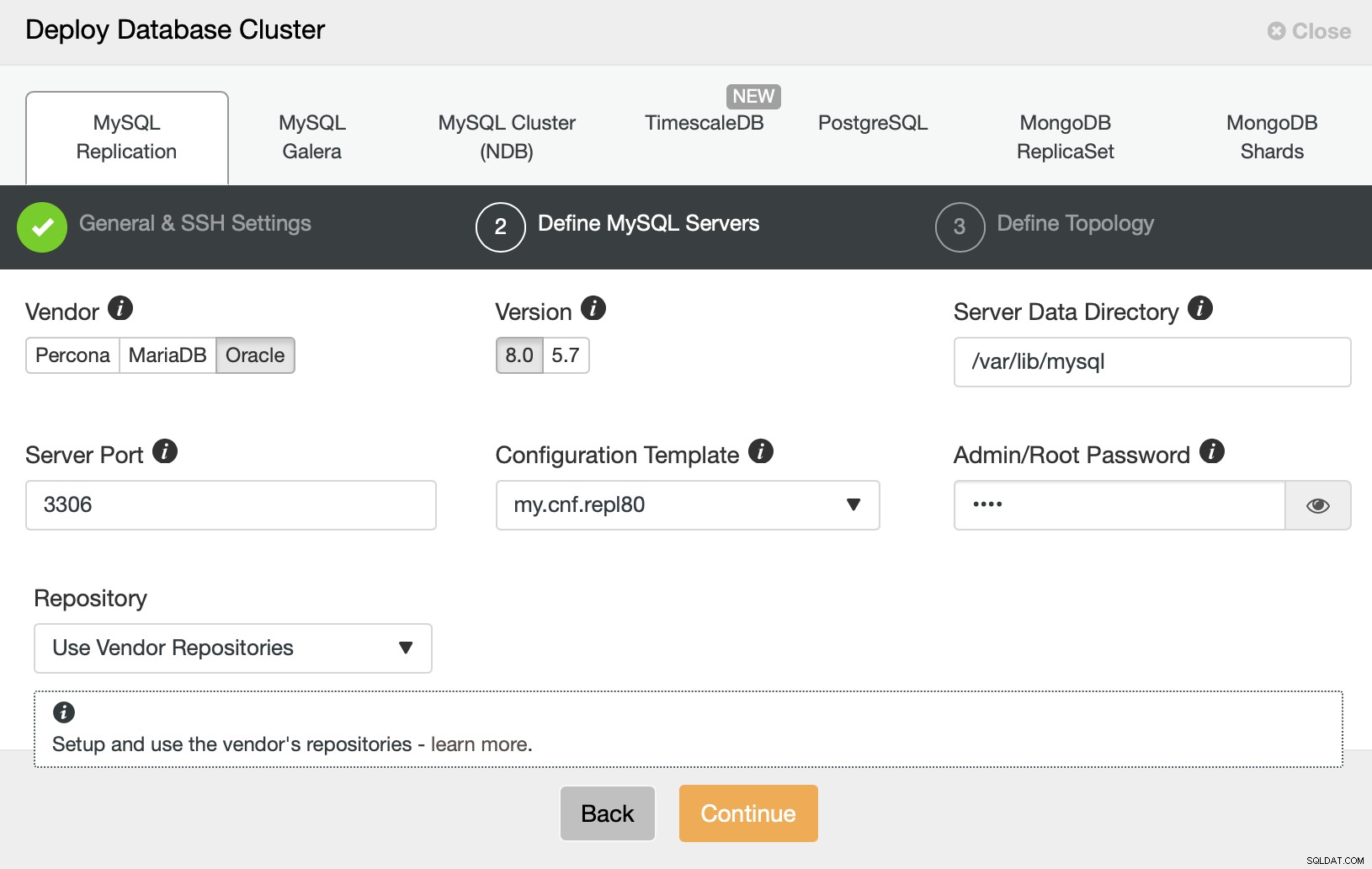
次に、ベンダー、バージョンを選択し、次のパスワードを渡します。 MySQLデータベースの管理ユーザー。
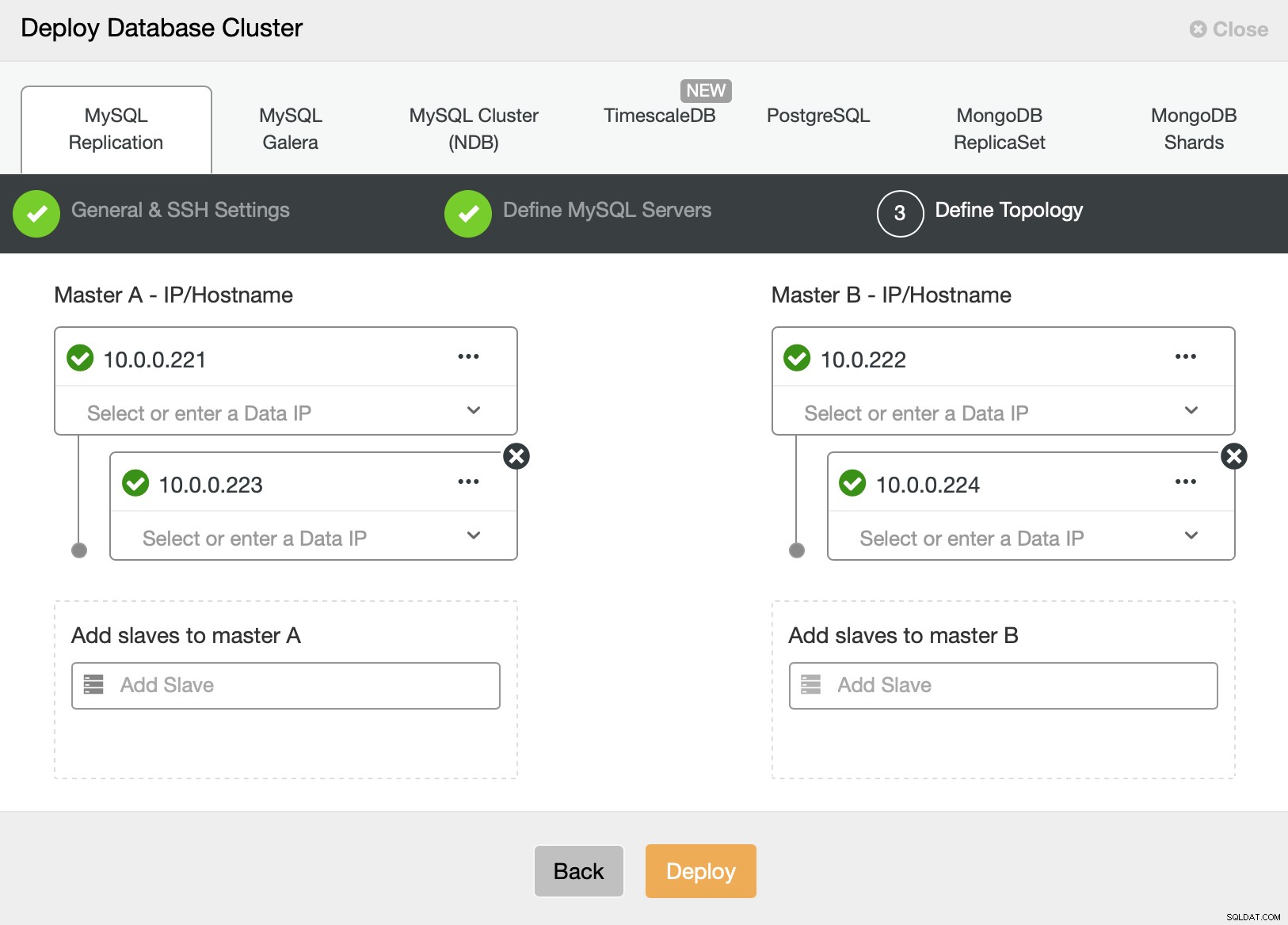
最後に、新しいクラスターのトポロジーを定義します。ご覧のとおり、AWSRDSまたはGCPSQLノードを使用してデプロイできるものとは異なり、これはすでに非常に複雑なセットアップです。
ここで行う必要があるのは、プロセスが完了するのを待つことだけです。 ClusterControlは、デプロイ先の環境を理解し、データベース自体を含む必要なパッケージのセットをインストールするために最善を尽くします。

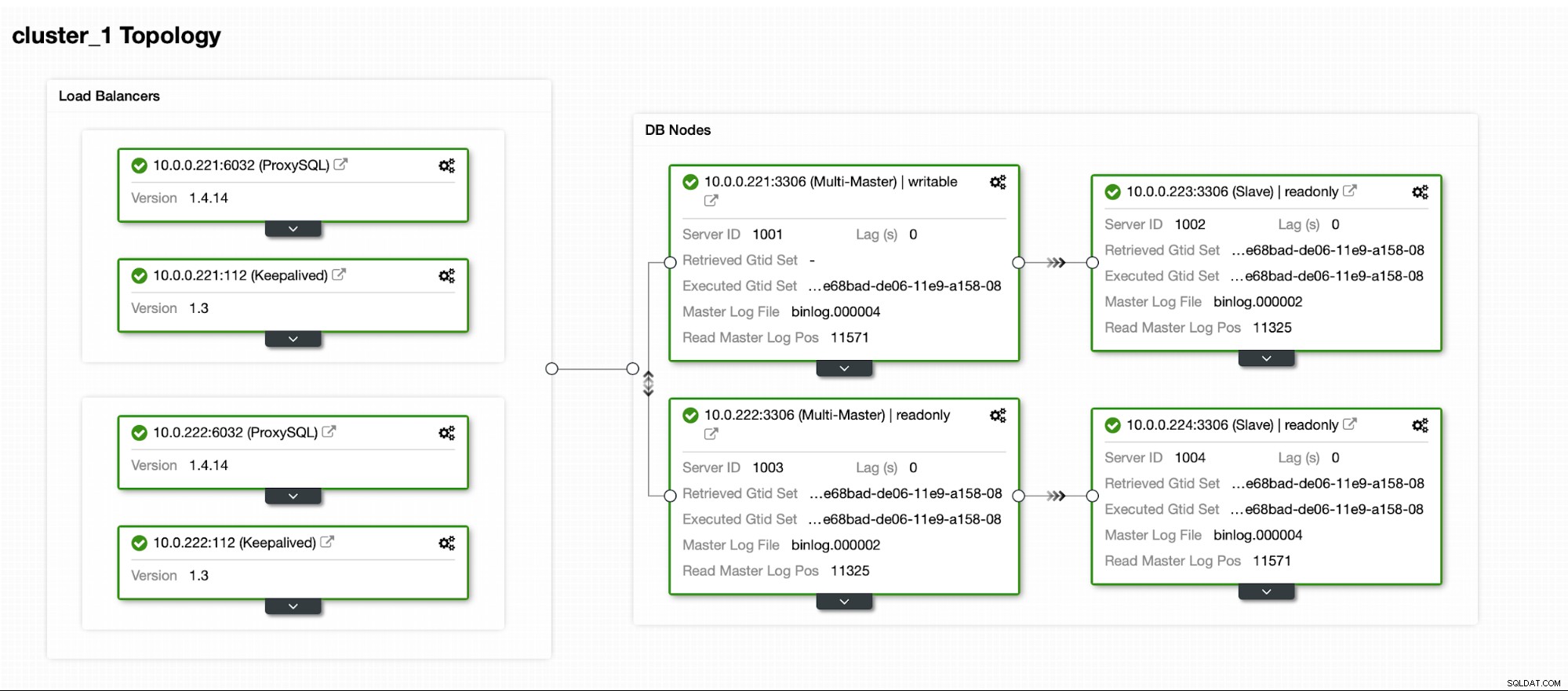
クラスターが稼働状態になったら、デプロイを続行できますプロキシレイヤー(データベースレイヤーへの単一のエントリポイントをアプリケーションに提供します)。これは多かれ少なかれ、データベースクラスターに接続するエンドポイントもあるDBaaSの舞台裏で行われていることです。書き込みに単一のエンドポイントを使用し、特定のレプリカに到達するために複数のエンドポイントを使用することは非常に一般的です。
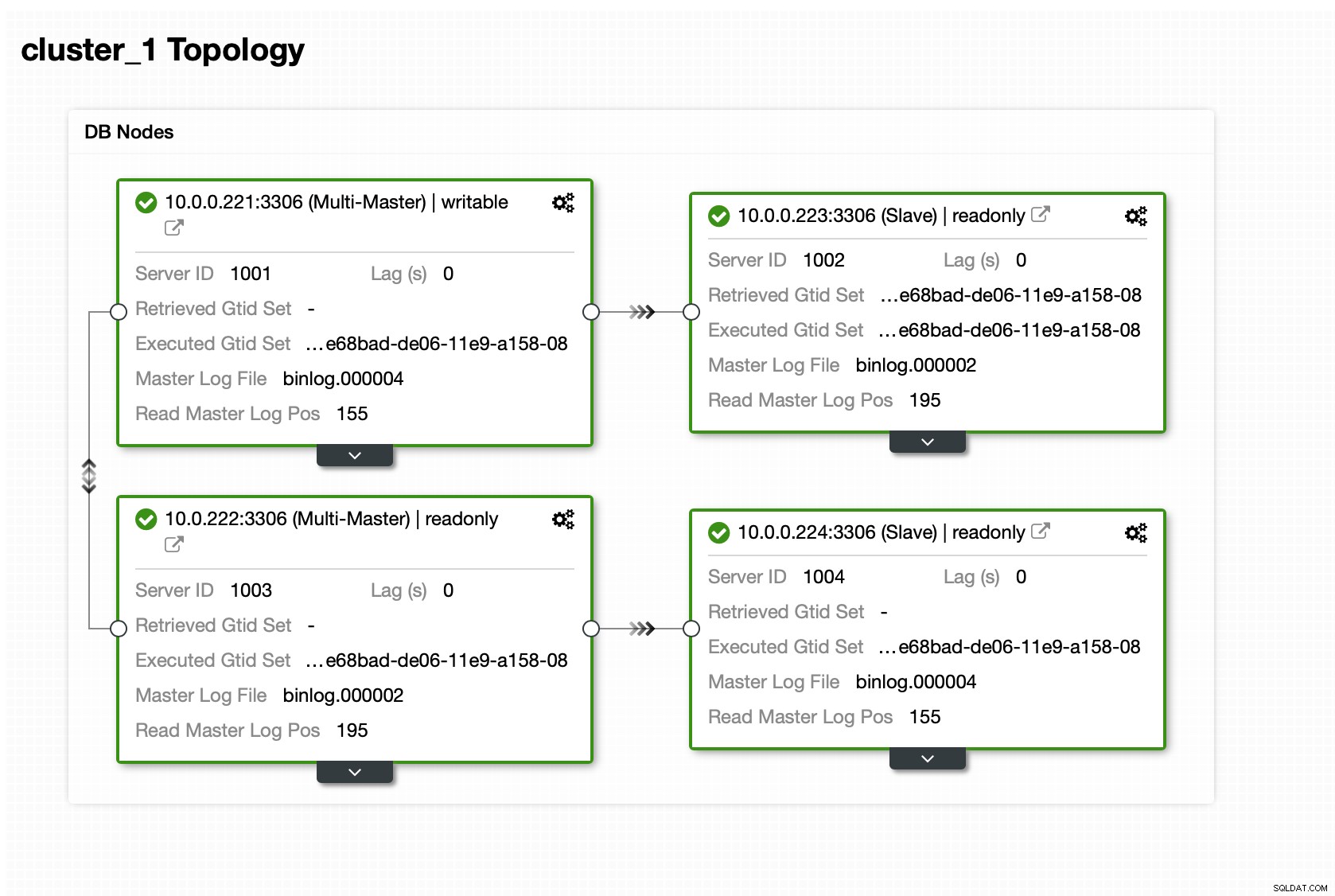
ここでは、ProxySQLを使用します。これにより、ダーティな作業が実行されます-トポロジを理解し、マスターにのみ書き込みを送信し、存在するすべてのレプリカ間で読み取り専用クエリの負荷を分散します。
ProxySQLをデプロイするには、[管理]->[ロードバランサー]に移動します。
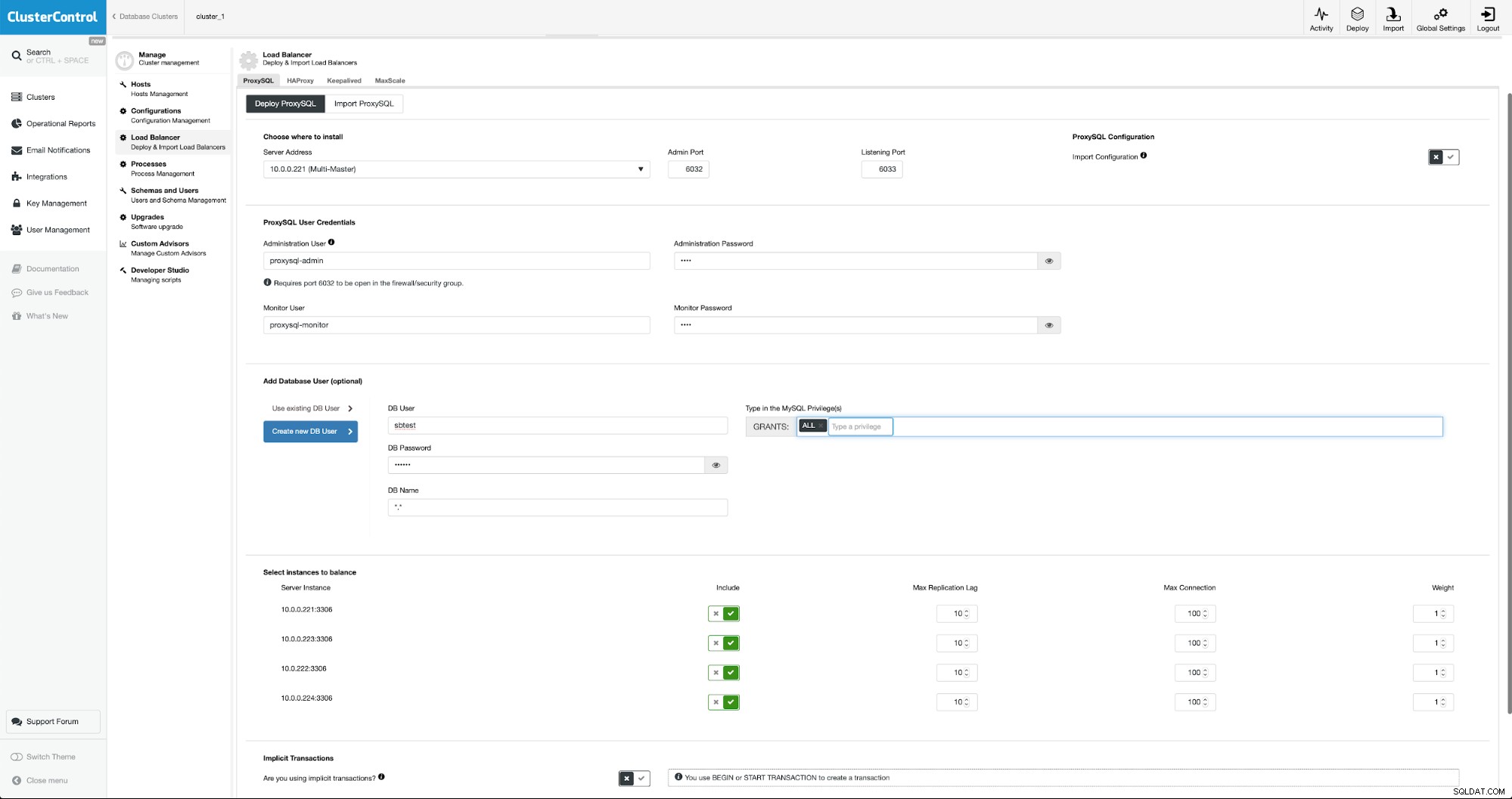
すべての必須フィールドに入力する必要があります:デプロイするホスト、管理および監視ユーザーの場合、既存のユーザーをMySQLからProxySQLにインポートするか、新しいユーザーを作成する場合があります。 ProxySQLに関するすべての詳細は、ブログセクションの複数のブログで簡単に見つけることができます。
高可用性を確保するには、少なくとも2つのProxySQLノードをデプロイする必要があります。次に、それらがデプロイされたら、ProxySQLの上にKeepalivedをデプロイします。これにより、少なくとも1つの正常なノードが存在する限り、仮想IPが構成され、ProxySQLインスタンスの1つを指すようになります。
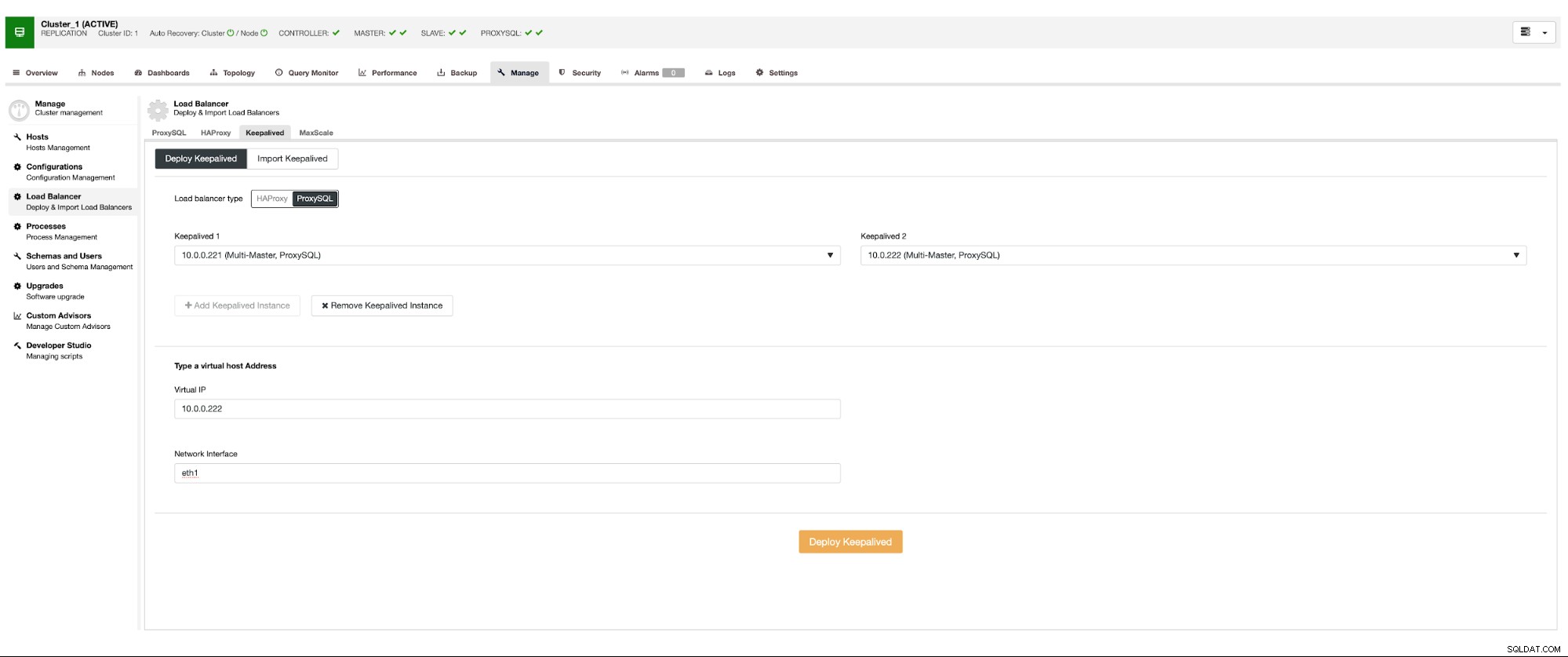
ルーティングが機能するクラウド環境を使用する場合、これが唯一の潜在的な問題です。ネットワークインターフェイスを簡単に立ち上げることができない方法で。このような場合、Keepalivedの設定を変更し、「notify_master」スクリプトを導入して、必要なIP変更を行うスクリプトを使用する必要があります。EC2の場合、Elastic IPを1つのホストからデタッチして、他のホスト。
ClusterControlによってデプロイされたセットアップで、広くテストされたオープンソースソフトウェアを使用してこれを行う方法については、たくさんの説明があります。特定の環境に関連する追加情報、ヒント、およびハウツーを簡単に見つけることができます。
結論
このブログ投稿が洞察に満ちていることを願っています。 ClusterControlをテストする場合は、すべての機能を利用できる30日間のエンタープライズトライアルが付属しています。無料でダウンロードして、ご使用の環境に適合するかどうかをテストできます。