データベースサーバーの実行を開始して使用量が増えるとすぐに、さまざまな種類の技術的な問題、パフォーマンスの低下、データベースの誤動作にさらされます。これらはそれぞれ、壊滅的な障害やデータの損失など、はるかに大きな問題につながる可能性があります。それは連鎖反応のようなもので、あることが別のことにつながり、ますます多くの問題を引き起こす可能性があります。できるだけ長く安定した環境を保つためには、積極的な対策が必要です。
このブログ投稿では、ClusterControlが提供する一連の優れた機能を紹介します。これらの機能は、MySQLデータベースの問題が発生した場合のトラブルシューティングと修正に大いに役立ちます。
すべての不要なイベントについて、ClusterControlは、ClusterControlページのアクティビティ(トップメニュー)からアクセスできる[アラーム]の下にすべてを記録します。これは通常、問題が発生したときにトラブルシューティングを開始するための最初のステップです。このページから、データベースクラスターで実際に何が起こっているかを知ることができます。
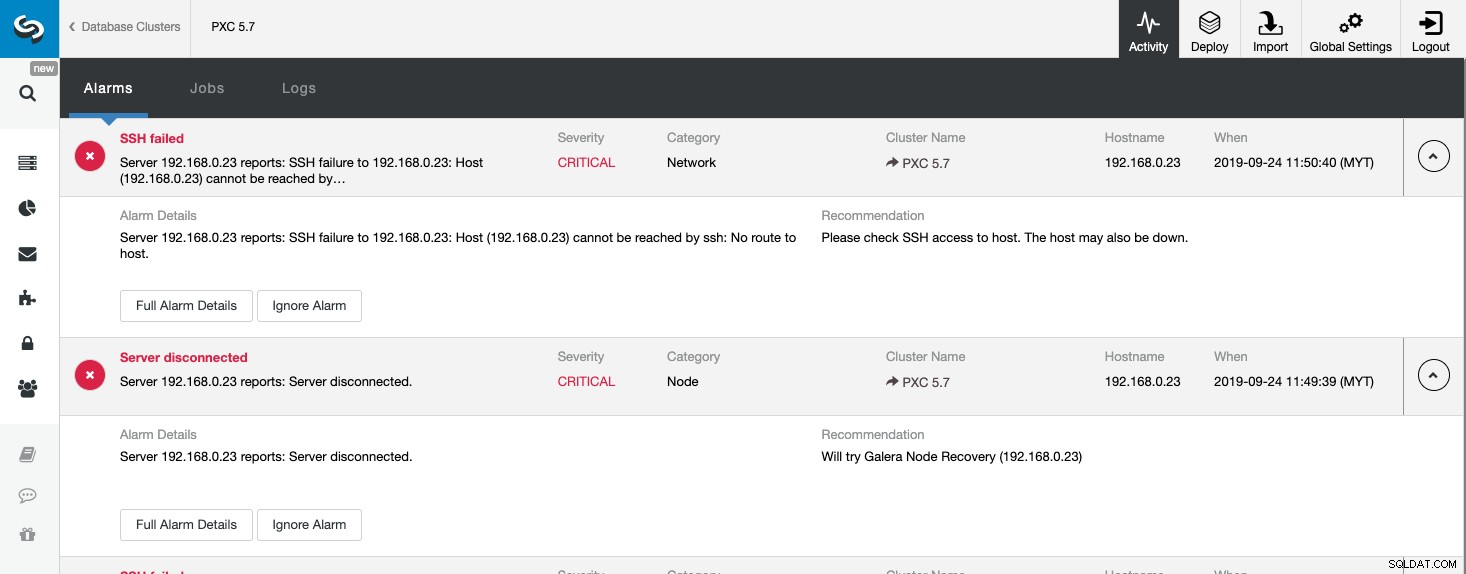
上のスクリーンショットは、重大度が重大なサーバー到達不能イベントの例を示しています。 、ネットワークとノードの2つのコンポーネントによって検出されます。電子メール通知設定を構成している場合は、これらのアラームのコピーをメールボックスに受け取る必要があります。
[完全なアラームの詳細]をクリックすると、ホスト名、タイムスタンプ、クラスター名など、アラームの重要な詳細を取得できます。また、次に推奨される手順についても説明します。このアラームを、電子メール通知設定で構成された他の受信者に電子メールとして送信することもできます。
[アラームを無視]ボタンをクリックしてアラームを消音することもできます。アラームはリストに表示されなくなります。重大度の低いアラームがあり、その処理または回避方法を知っている場合は、アラームを無視すると便利な場合があります。たとえば、ClusterControlがデータベースで重複するインデックスを検出した場合、レガシーアプリケーションで必要になることがあります。
このページを見ると、データベースクラスターで何が起こっているのか、そして問題を解決するために次のステップで何をするのかをすぐに理解できます。この場合のように、データベースノードの1つがダウンし、ClusterControlホストからSSH経由で到達できなくなりました。初心者のSysAdminでも、このアラームが表示された場合に次に何をすべきかがわかります。
ここで、データベースサーバーの問題点をドリルダウンできます。 ClusterControl-> Logs-> System Logsで、データベースクラスターに関連するすべてのログファイルを確認できます。 MySQLベースのデータベースクラスターの場合、ClusterControlはProxySQLログ、MySQLエラーログ、およびバックアップログを取得します。
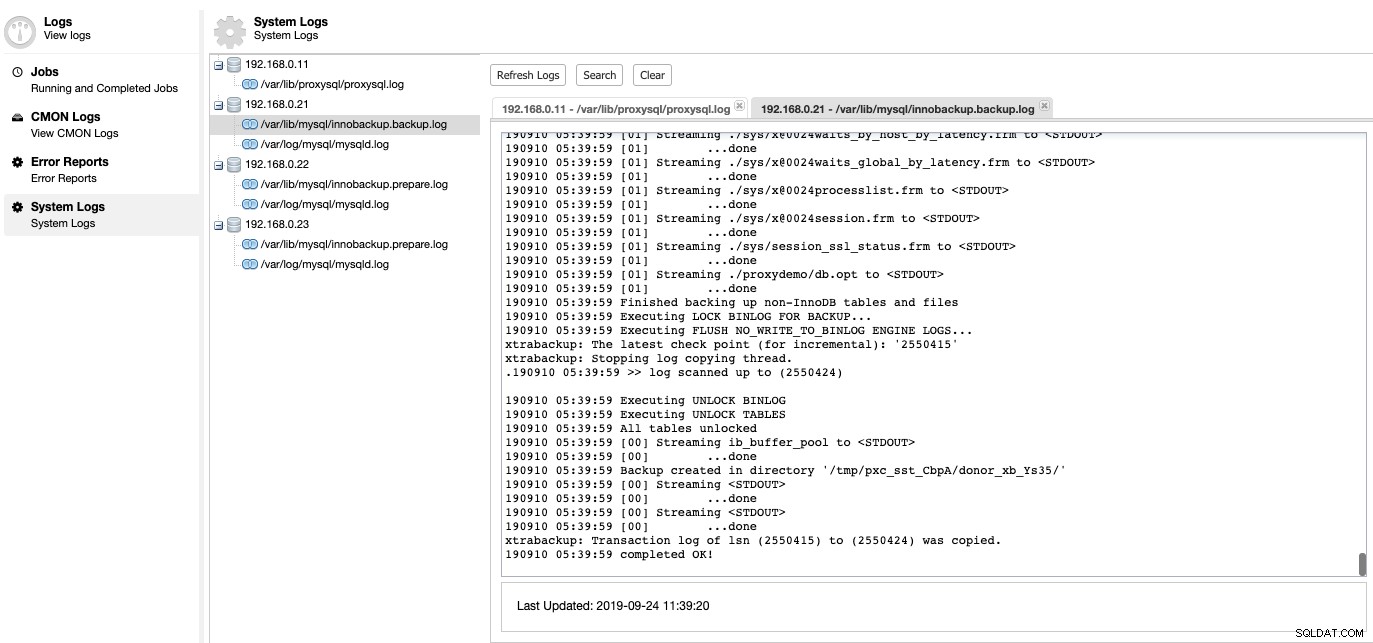
「ログの更新」をクリックして、その特定の時間にアクセス可能なすべてのホストから最新のログを取得します。ノードに到達できない場合でも、この情報はCMONデータベース内に格納されているため、ClusterControlは古いログインを表示します。デフォルトでは、ClusterControlはシステムログを10分ごとに取得し続け、[設定]->[ログ間隔]で構成できます。
ClusterControlは、次の「ログの収集」ジョブに示すように、各サーバーから最新のログをプルするジョブをトリガーします。
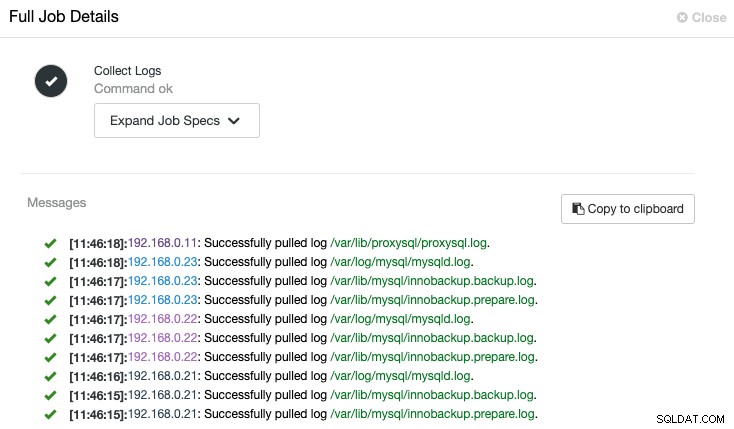
ログファイルを一元的に表示することで、何が起こったのかをより早く理解できます。間違い。一般に複数のノードと層が関係するデータベースクラスターの場合、この機能によりログの読み取りが大幅に改善され、SysAdminがこれらのログを並べて比較し、重要なイベントを特定できるため、トラブルシューティングの合計時間が短縮されます。
WebSSHコンソール
ClusterControlはWebベースのSSHコンソールを提供するため、ClusterControl UIを介してDBサーバーに直接アクセスできます(SSHユーザーはデータベースホストに接続するように構成されているため)。ここから、より多くの情報を収集できるため、問題をさらに迅速に修正できます。データベースの問題が本番システムに発生すると、ダウンタイムが1秒ごとにカウントされることは誰もが知っています。
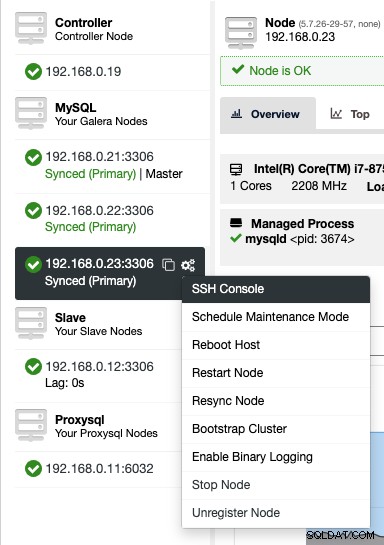
Web経由でSSHコンソールにアクセスするには、[ノード]->[ノードアクション]->[SSHコンソール]でノードを選択するか、歯車のアイコンをクリックしてショートカットを表示します。
この機能に課せられる可能性のあるセキュリティ上の懸念により、特にマルチの場合-ユーザーまたはマルチテナント環境。ClusterControlサーバーの/var/www/html/clustercontrol/bootstrap.phpにアクセスし、次の定数をfalseに設定することで無効にできます。
define('SSH_ENABLED', false);ClusterControl UIページを更新して、新しい変更をロードします。
監視機能とトレンド機能の他に、ClusterControlは、データベースのパフォーマンスに関連するさまざまなアラームとアドバイザをプロアクティブに送信します。例:
- 過剰な使用量-CPU、メモリ、スワップ使用量、ディスク容量などの特定のしきい値を超えるリソース。
- クラスターの劣化-クラスターとネットワークのパーティション分割。
- システム時間ドリフト-クラスター内のすべてのノード(ClusterControlノードを含む)間の時間差。
- その他のさまざまなMySQL関連のアドバイザー:
- レプリケーション-レプリケーションの遅延、binlogの有効期限、場所、および成長
- Galera-SSTメソッド、GRAログファイルのスキャン、クラスターアドレスチェッカー
- スキーマチェック-GaleraClusterに非トランザクションテーブルが存在します。
- 接続-スレッド接続率
- InnoDB-ダーティページの比率、InnoDBログファイルの増加
- 遅いクエリ-デフォルトでは、ClusterControlは、クエリが30秒を超えて実行されていることを検出すると、アラームを発生させます。もちろん、これは[設定]->[ランタイム構成]->[長いクエリ]で構成できます。
- デッドロック-InnoDBトランザクションのデッドロックとGaleraのデッドロック。
- インデックス-重複キー、主キーのないテーブル。
ClusterControlによって提案されたように改善できることの詳細を取得するには、[パフォーマンス]->[アドバイザ]の下の[アドバイザ]ページを確認してください。すべてのアドバイザについて、「ディスクスペース使用量の確認」アドバイザの次の例に示すように、正当化とアドバイスを提供します。
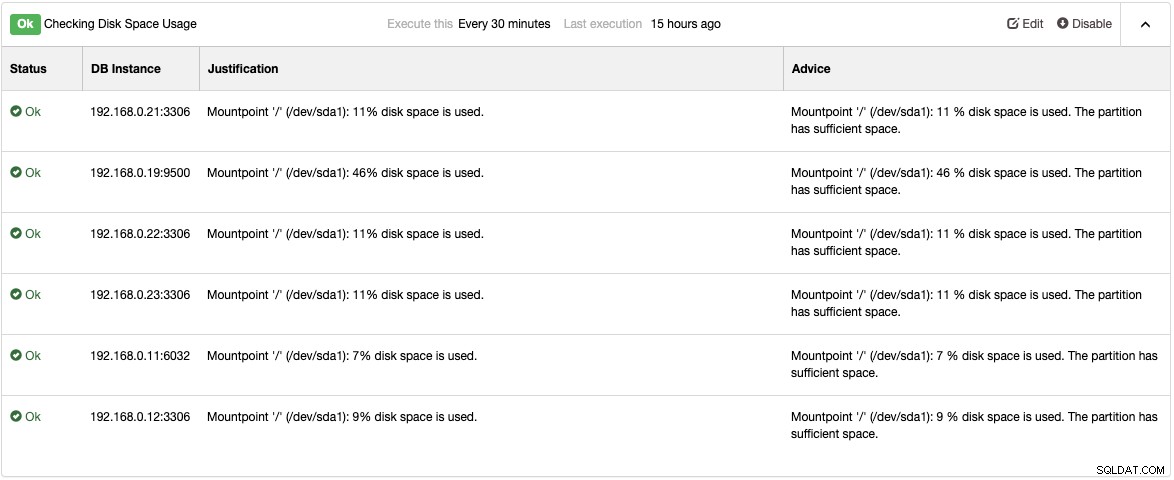
パフォーマンスの問題が発生すると、「警告」(黄色)またはこれらのアドバイザーの「クリティカル」(赤)ステータス。この問題を克服するには、通常、さらに調整が必要です。アドバイザはアラームを発生させます。つまり、電子メール通知が適切に構成されている場合、ユーザーはメールボックス内にこれらのアラームのコピーを取得します。 ClusterControlまたはそのアドバイザーによって発生したすべてのアラームについて、アラームがクリアされた場合、ユーザーにも電子メールが送信されます。これらはClusterControl内で事前構成されており、初期構成は必要ありません。 [管理]->[DeveloperStudio]で、さらにカスタマイズすることができます。独自のアドバイザーを作成する方法については、このブログ投稿を確認してください。
ClusterControlは、ClusterControl->Performanceの下にデータベースパフォーマンスに関する専用ページも提供します。 DBステータス、変数、InnoDBステータス、スキーマアナライザー、トランザクションログの集中ビューなどのベストプラクティスに従って、あらゆる種類のデータベースインサイトを提供します。これらはかなり自明であり、理解するのは簡単です。
クエリのパフォーマンスについては、上位のクエリとクエリの外れ値を調べることができます。ClusterControlは、平均的なクエリとは大幅に異なるパフォーマンスのクエリを強調表示します。このトピックについては、このブログ投稿「MySQLクエリパフォーマンスチューニング」で詳しく説明しています。
ClusterControlには、データベースクラスタに関するデバッグ情報を収集して現在の状況とステータスを理解するのに役立つ、エラーレポートジェネレータツールが付属しています。エラーレポートを生成するには、[ClusterControl]->[ログ]->[エラーレポート]->[エラーレポートの作成]に移動します:
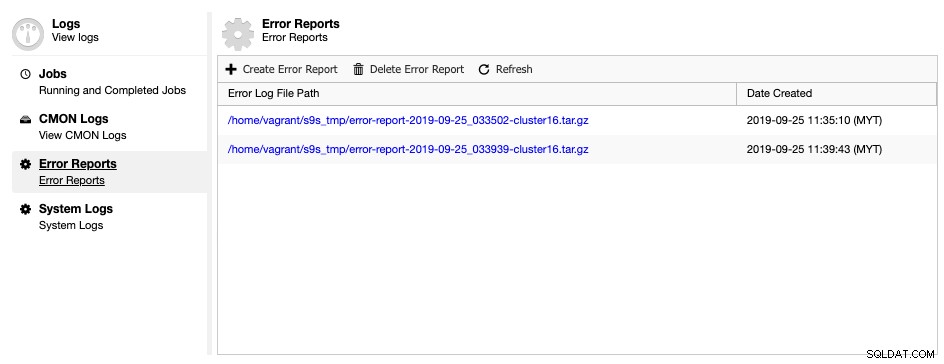
生成されたエラーレポートは、準備ができたらこのページからダウンロードできます。この生成されたレポートはTARボール形式(tar.gz)であり、サポートリクエストに添付できます。サポートチケットのファイルサイズは10MBに制限されているため、tarballのサイズがそれよりも大きい場合は、クラウドドライブにアップロードして、適切な許可を得た場合にのみダウンロードリンクを共有できます。ファイルを取得したら、後で削除できます。エラーレポートのドキュメントページで説明されているように、コマンドラインからエラーレポートを生成することもできます。
停止が発生した場合は、停止中および停止直後に複数のエラーレポートを生成することを強くお勧めします。これらのレポートは、何が悪かったのか、停止の結果を理解し、壊滅的なイベントの後にクラスターが実際に運用状態に戻っていることを確認するのに非常に役立ちます。
ClusterControlのプロアクティブな監視は、一連のトラブルシューティング機能とともに、ユーザーがあらゆる種類のMySQLデータベースの問題をトラブルシューティングするための効率的なプラットフォームを提供します。根本的な原因を特定するために、複数のSSHセッションを開いて複数のホストにアクセスし、複数のコマンドを繰り返し実行する必要があるという従来のトラブルシューティング方法は、古くからあります。
上記の機能が問題の解決やデータベースの問題のトラブルシューティングに役立たない場合は、常にSevereninesサポートチームに連絡してバックアップしてください。 24時間年中無休の専任の技術専門家がいつでもご要望にお応えします。通常、最初の返信の平均時間は30分未満です。