ITインフラストラクチャがAWSで実行されている場合、クラウドでリレーショナルデータベースをセットアップ、運用、スケーリングする簡単な方法であるAmazon Relational Database Service(RDS)について聞いたことがあるでしょう。ハードウェアプロビジョニング、データベースセットアップ、パッチ適用、バックアップなどの時間のかかる管理タスクを自動化しながら、費用対効果が高くサイズ変更可能な容量を提供します。 MySQL、MariaDB、PostgreSQL、Microsoft SQL Server、OracleServerなどのRDS用のデータベースエンジン製品は多数あります。
ClusterControl 1.7.3は、AWSプラットフォームでのデータベースクラスターのデプロイ、管理、モニタリング、スケーリングをサポートするため、RDSと同様に機能します。また、GoogleCloudPlatformやMicrosoftAzureなどの他の多くのクラウドプラットフォームもサポートしています。 ClusterControlはデータベーストポロジを理解し、自動リカバリ、トポロジ管理、およびデータベースを制御するためのより高度な機能を実行できます。
このブログ投稿では、Amazon Auroraの自動フェイルオーバー時間、MySQLのAmazon RDS、およびClusterControlによってデプロイおよび管理されるMySQLレプリケーションのセットアップを比較します。これから行うフェイルオーバーのタイプは、マスターがダウンした場合のスレーブプロモーションです。これは、最新のスレーブがクラスター内のマスターの役割を引き継いでデータベースサービスを再開する場所です。
フェイルオーバー時間を測定するために、単一のデータベースエンドポイントに接続するSQLステートメントのステータスをカウントするループを使用して、単純なMySQL接続更新テストを実行します。スクリプトは次のようになります:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
上記のBashスクリプトは、MySQLホストに接続し、Bashクライアントコマンドとmysqlクライアントコマンドの両方で1秒のタイムアウトで単一行の更新を実行します。 mysqlクライアントはデフォルトでMySQLwait_timeoutに到達するまで常に再接続するため、タイムアウト関連のパラメーターが必要です。これにより、ダウンタイムを秒単位で正しく測定できます。事前に次のコマンドをテストデータセットに入力しました:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareスクリプトは、上記のクエリが成功したか(OK)、失敗したか(Fail)を報告します。サンプル出力はさらに下に表示されます。
このテストでは、次の仕様で最も低いRDSオファリングを使用します。
- MySQLバージョン:5.7.22
- vCPU:4
- RAM:16 GB
- ストレージタイプ:プロビジョニングされたIOPS(SSD)
- IOPS:1000
- ストレージ:100ギブ
- マルチAZレプリケーション:はい
Amazon RDSがDBインスタンスをプロビジョニングした後、標準のMySQLクライアントアプリケーションまたはユーティリティを使用してインスタンスに接続できます。接続文字列では、ホストパラメータとしてDBインスタンスエンドポイントからのDNSアドレスを指定し、ポートパラメータとしてDBインスタンスエンドポイントからのポート番号を指定します。
Amazon RDSのドキュメントページによると、DBインスタンスの計画的または計画外の停止が発生した場合、マルチAZを有効にしていると、AmazonRDSは別のアベイラビリティーゾーンのスタンバイレプリカに自動的に切り替わります。フェイルオーバーが完了するまでにかかる時間は、プライマリDBインスタンスが使用できなくなったときのデータベースアクティビティおよびその他の条件によって異なります。フェイルオーバー時間は通常60〜120秒です。
RDSでマルチAZフェイルオーバーを開始するために、次のスクリーンショットに示すように、[フェイルオーバーを使用して再起動]をオンにして再起動操作を実行しました。
以下は、私たちのアプリケーションによって観察されているものです:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...アプリケーション側から見たMySQLのダウンタイムは、03:41:09から03:41:36までで、合計で約27秒でした。 RDSイベントから、マルチAZフェイルオーバーが実際のダウンタイムの15秒後にのみ発生したことがわかります。
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.新しいデータベースインスタンスが03:41:33頃に再起動すると、約3秒後にMySQLサービスにアクセスできるようになりました。
MySQL用AmazonAuroraのフェイルオーバー
Amazon Auroraは、共有ストレージを使用した高速レプリケーション、フェイルオーバー中のデータ損失なし、最大64 TBのストレージ制限など、多くの注目すべき機能を備えたRDSの優れたバージョンと見なすことができます。 Amazon Aurora for MySQLは、オープンソースのMySQL Editionに基づいていますが、それ自体はオープンソースではありません。これは、独自のクローズドソースデータベースです。 MySQLレプリケーション(複数のスレーブを持つ1つだけのマスター)でも同様に機能し、フェイルオーバーはAmazonAuroraによって自動的に処理されます。
Amazon Aurora FAQSによると、同じまたは異なるアベイラビリティーゾーンにAmazon Auroraレプリカがある場合、フェイルオーバー時に、AuroraはDBインスタンスの正規名レコード(CNAME)を反転して、正常なレプリカを指します。ターンは新しいプライマリになるように昇格します。開始から終了まで、フェイルオーバーは通常30秒以内に完了します。
Amazon Auroraレプリカ(つまり、単一インスタンス)がない場合、Auroraは最初に元のインスタンスと同じアベイラビリティーゾーンに新しいDBインスタンスを作成しようとします。それができない場合、Auroraは別のアベイラビリティーゾーンに新しいDBインスタンスを作成しようとします。開始から終了まで、フェイルオーバーは通常15分以内に完了します。
接続が失われた場合、アプリケーションはデータベース接続を再試行する必要があります。
Amazon AuroraがDBインスタンスをプロビジョニングした後、ライター用とリーダー用の2つのエンドポイントを取得します。リーダーエンドポイントは、DBクラスターへの読み取り専用接続の負荷分散サポートを提供します。次のエンドポイントは、テストセットアップから取得されます。
- ライター-aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- リーダー-aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
テストでは、次のAurora仕様を使用しました。
- インスタンスタイプ:db.r5.large
- MySQLバージョン:5.7.12
- vCPU:2
- RAM:16 GB
- マルチAZレプリケーション:はい
フェイルオーバーをトリガーするには、次のスクリーンショットに示すように、ライターインスタンス->アクション->フェイルオーバーを選択するだけです。
次の出力は、Auroraライターエンドポイントに接続しているときにアプリケーションによって報告されます:
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...データベースのダウンタイムは、12:35:49から12:35:56まで、合計7秒で開始されました。それはかなり印象的です。
Aurora管理コンソールからデータベースイベントを見ると、次の2つのイベントのみが発生しました。
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedAuroraがスレーブをマスターに昇格させ、マスターを降格させてスレーブになるのにそれほど時間はかかりません。すべてのAuroraレプリカは、プライマリインスタンスと同じ基になるボリュームを共有します。これは、プライマリインスタンスによって行われた更新がすべてのAuroraレプリカで即座に利用できるため、ミリ秒単位でレプリケーションを実行できることを意味します。したがって、レプリケーションの遅延は最小限に抑えられます(Amazonは100ミリ秒以下であると主張しています)。これにより、ヘルスチェック時間が大幅に短縮され、回復時間が大幅に改善されます。
ClusterControlのフェイルオーバー
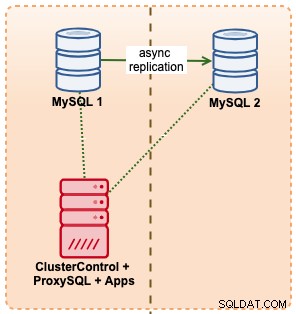
この例では、m5.xlargeインスタンスを使用してAmazon RDSで同様のセットアップを模倣し、その間にProxySQLを配置して、RDSと同様に単一のエンドポイントアクセスを使用してアプリケーションからのフェイルオーバーを自動化します。次の図は、アーキテクチャを示しています。
データベースインスタンスに直接アクセスできるため、アクティブマスター上のMySQLプロセスを強制終了するだけで自動フェイルオーバーをトリガーします。
$ kill -9 $(pidof mysqld)上記のコマンドは、ClusterControl内で自動回復をトリガーしました:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.テストアプリケーションの観点からすると、ProxySQLホストポート6033に接続しているときに、次の時間にダウンタイムが発生しました。
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...リカバリジョブイベントとアプリケーションからの出力の両方を確認すると、MySQLデータベースノードは、クラスタリカバリジョブが開始する4秒前の11:08:28から11:08:39までダウンしており、MySQLの合計ダウンタイムは11秒でした。 。 ClusterControlの最も印象的な点の1つは、フェイルオーバー中にClusterControlによって実行および実行されたアクションの回復の進行状況を追跡できることです。クラウドプロバイダーが提供するデータベースでは得られないレベルの透明性を提供します。
MySQL / MariaDB / PostgreSQLレプリケーションの場合、ClusterControlを使用すると、次の高度な構成とパラメーターをサポートして、データベースに対してよりきめ細かく対応できます。
- マスター-マスターレプリケーショントポロジ管理
- チェーンレプリケーショントポロジ管理
- トポロジビューア
- マスターとして昇格するホワイトリスト/ブラックリストスレーブ
- 誤ったトランザクションチェッカー
- 事前/事後、成功/失敗フェイルオーバー/スイッチオーバーイベントは外部スクリプトにフックします
- エラー時の自動再構築スレーブ
- 既存のバックアップからスレーブをスケールアウトする
フェイルオーバー時間に関しては、Amazon RDS AuroraforMySQLが7秒で明らかに勝者です。 、続いてClusterControl11秒 およびAmazonRDSfor MySQL(27秒) 。
これは単純なテストであり、1秒あたり1つのクライアントと1つのトランザクションを使用して、最速のリカバリ時間を測定することに注意してください。大規模なトランザクションや長いリカバリプロセスにより、フェイルオーバー時間が長くなる可能性があります。たとえば、実行時間の長いトランザクションは、MySQLをシャットダウンするときにロールバックに時間がかかる場合があります。