世界中で、求人ポータルサイトはインターネット環境のよく知られた機能です。 IndeedやMonsterのような大手企業は、就職活動や求人を真のオンライン業界に変えました。ジョブポータルで活用される基本機能を詳しく調べて、それらをサポートできるデータモデルを構築しましょう。
人々は技術革新を利用して時間を節約するのが大好きです。オンライン求人ポータルは、ハードではなく、よりスマートに機能する別のバージョンです。求職者も企業も同様に、オンラインで検索することの価値を認識しています。つまり、より高速で低コストでより良いリーチを得ることができます。
求人ポータル業界は、少なくともトラフィック量に関しては、現在かなり安定しています。ジョブハンターはこれらのポータルを使用して多くの業界でポジションを見つけ、ITを超えてエンジニアリング、セールス、製造、金融サービスなどのセクターに移行しています。しかし、彼らはソーシャルメディアやLinkedInのようなプロのネットワーキングサイトとの激しい競争にさらされています。しかし、農村部や小都市への浸透を拡大するなど、探索する機会はまだあります。
先ほど述べたように、データベース設計の観点からこのトピックを検討します。求人ポータルの基本的な期待を列挙することから始めましょう。
人々はオンライン求人ポータルに何を期待していますか?
雇用主と求職者の両方が、オンライン求人サイトに次の機能を期待しています。
- 人々は求職者として登録し、プロフィールを作成し、スキルセットに一致する仕事を探すことができます。
- ユーザーは既存の履歴書をアップロードできます。持っていない場合は、フォームに記入して履歴書を作成できるはずです。
- 投稿されたジョブに直接応募できます。
- 企業は、求職者のプロフィールを登録、投稿、検索できます。
- 会社の複数の代表者が仕事を登録して投稿できる必要があります。
- 会社の代表者は、求職者のリストを表示して、求職者に連絡したり、面接を主導したり、自分のポストに関連するその他のアクションを実行したりできます。
- 登録ユーザーは、場所、必要なスキル、給与、経験レベルなどに基づいて、仕事を検索し、結果をフィルタリングできる必要があります。
データモデルの構築
上記の要件を検討した後、私は3つの幅広い機能カテゴリを考え出しました。
- ユーザーの管理 –ポータルがユーザー、つまり求職者、人事担当者、および独立したリクルーターまたはコンサルティングリクルーターを管理する方法。 (このモデルの目的上、個々のHR担当者と独立またはコンサルティングの採用担当者は、少なくともポータルの使用方法に関しては企業として扱われます。)
- プロファイルの作成 –ポータルで求職者や組織がプロフィールや履歴書を作成する方法。
- ジョブの投稿と検索 –ポータルがジョブの投稿、検索、および申請のプロセスをどのように促進するか。
これらの各領域を個別に見てみましょう。
1。ユーザーの管理
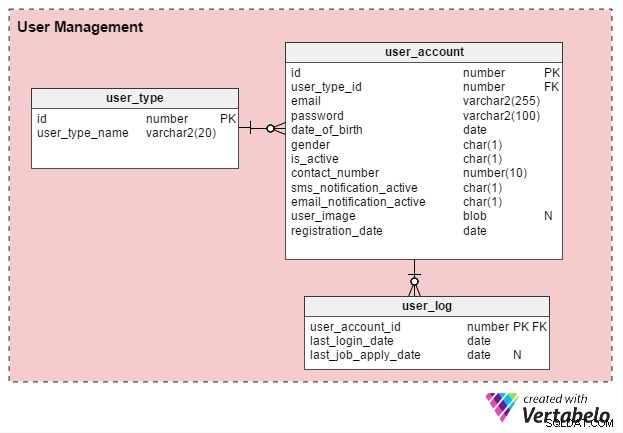
オンライン求人ポータルユーザーには、主に2つのタイプがあります。個々の求職者と人事採用担当者(または独立した採用コンサルタント)です。 user_type これらのレコードを保存します。まず、2つのレコードがあります。1つは求職者用で、もう1つは採用担当者用です。 (必要に応じていつでも追加のレコードタイプを作成できます。)
ユーザーは、ポータルを使用する前に登録する必要があります。 user_account テーブルには、基本的なアカウントの詳細が格納されます。以前、このテーブルに「user」という名前を付けることを検討しましたが、userはほとんどすべてのデータベースでシステム定義のキーワードであるため、「user_account」を使用することを好みます。
user_account テーブルには次の列があります:
- id –これは、テーブルの主キーであり、各ユーザーの一意の識別子でもあります。このIDは、データモデル内の他のテーブルによって参照されます。
- user_type_id –これは、ユーザーが求職者であるか採用担当者であるかを示します。
- メール –この列には、ユーザーの電子メールアドレスが保持されます。ポータルの別のユーザーIDとして機能します。
- パスワード –これは、暗号化されたアカウントパスワード(登録時にユーザーが作成したもの)を保存します。
- date_of_birth および性別 –名前が示すように、これらの列にはユーザーの生年月日と性別が表示されます。
- is_active –最初、この列は「Y」になりますが、ユーザーはプロファイルを非アクティブまたは「N」に設定できます。この列には、選択内容が格納されます。
- contact_number –これは、登録時に提供される電話番号(通常は携帯電話)です。ユーザーは、この番号でSMS(テキスト)通知を受信できます。プロフィールまたは履歴書に記載されている1人の求職者と同じ数(または同じ数ではない)にすることができます。
- sms_notification_active およびemail_notification_active –これらの列には、テキストや電子メールによる通知の受信に関するユーザーの設定が格納されます。
- user_image –これは、各ユーザーのプロファイル画像を格納するBLOBタイプの属性です。このポータルでは、ユーザーごとに1つのプロフィール画像しか使用できないため、ここに保存するのが理にかなっています。
- register_date –この列には、ユーザーがいつポータルに登録したかが記録されます。
もう1つのテーブルuser_log 、ユーザーの最終ログイン日と最終求人応募日の記録を保存します。この知識から構築できる機能はたくさんあります。たとえば、この情報を使用して、ユーザーXは積極的に仕事を探していますかという質問に答えることができます。 ?もしそうなら、彼らは効果的な履歴書を作成するための製品を提供することができます。積極的に仕事を探していないユーザーは、そのようなオファーを受け取りません。
2。プロファイルの作成
このセクションはさらに、会社または組織のプロファイルと求職者のプロファイルの2つの領域に分けることができます。
会社概要
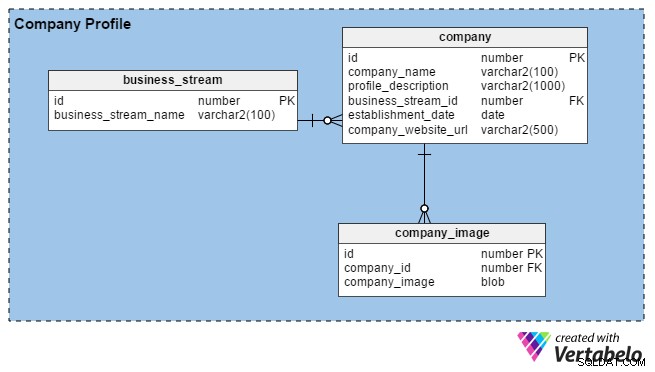
通常、HRチームは、組織の詳細やオフィス、建物などの画像を入力して会社のプロファイルを作成します。主な目的は、優秀な人材を引き付けることです。採用担当者がポータルに登録すると、ビジネスの期間、場所、主なビジネスストリーム(例:製造、ITサービス、財務など)。
ポータルを使用すると、HRおよびコンサルティングリクルーターは好きなだけ画像をアップロードできます(1つしかアップロードできない求職者とは対照的です)。そのため、company_image リクルーターアカウントごとに複数の画像を保存するテーブル。 company_id この表の列は、company テーブル。
company 表には、次の列があります:
- id –このテーブルの主キーは、企業を一意に識別するためにも使用されます。
- company_name –列名が示すように、これは会社の正式な名前を保持します。
- profile_description –これには各企業の簡単な説明が含まれています。
- business_stream_id –この列は、会社が属するビジネスストリームを示しています。たとえば、石油とガスの探査会社はITエンジニアを雇うことができますが、彼らの主なビジネスストリームは「石油とガス」のままです。
- establishment_date –この列は、会社の築年数を示しています。
- company_website_url –これは必須の(NULL不可)列です。求職者がより多くの情報を見つけることができるように、会社の公式ウェブサイトへのポインタを保持しています。
最後に、business_stream テーブルには、このテーブルの主キーであるIDと、会社のメインビジネスストリームの説明( business_stream_name )の2つの属性しかありません。 。
求職者のプロフィール
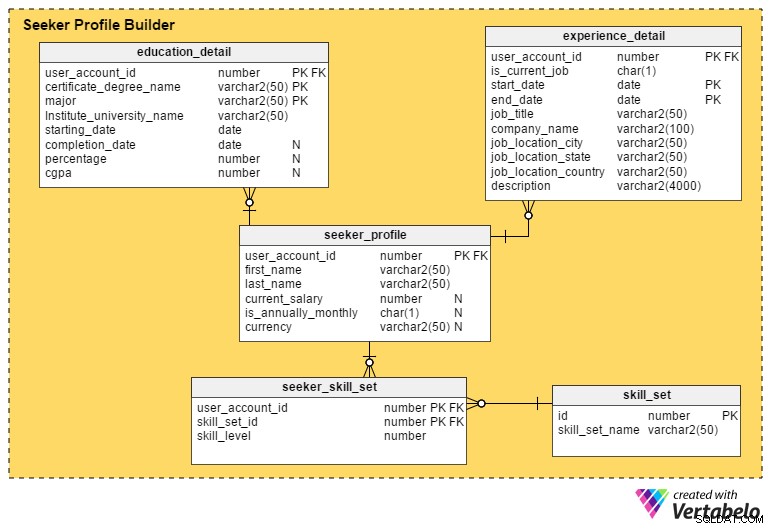
これは、求人ポータルの最も重要なセクションです。ポータルが求職者から可能な限り多くの詳細を取得しない限り、採用担当者がプロファイルまたは候補者を候補リストに載せることは困難です。
seeker_profile 表には、登録プロセス中に取得されなかった追加の詳細が含まれています。次のフィールドが含まれています:
- user_account_id –この列は
user_accountテーブルであり、このテーブルの主キーとして機能します。これにより、求職者ごとに最大1つのプロファイルが存在するようになります。 - first_name およびlast_name –名前が示すように、これらの列には求職者の名前と名前が表示されます。
- current_salary –この属性には、求職者の現在の給与が含まれます。人々がそれを開示したくないかもしれないので、それはnull可能です。
- is_annually_monthly –これは、給与額が1年あたりか1か月あたりかを定義します。
- 通貨 –これは給与の通貨を保存します。
education_detail テーブルには、求職者から提供された各求職者の学歴が保存されます。 user_account_idで構成される複合主キーがあります 、certificate_degree_name およびメジャー 列。これにより、ユーザーは1つのみを入力できます 各学位または証明書の記録。テーブルには次の属性が含まれています:
- user_account_id –この列は
user_accountテーブルであり、このテーブルの主キーとして機能します。 - certificate_degree_name –これは証明書または学位タイプです。例えば高校、高等学校、大学院、大学院、または専門資格。
- メジャー –この列には、証明書または学位の主な学習コースがあります–例:コンピュータサイエンスを専攻し、学士号を取得しています。
- institute_university_name –これは、学位または証明書を授与した機関、学校、または大学です。
- start_date –この属性は、ユーザーが教育プログラムに受け入れられた日付を格納します。
- complete_date –これは学位または証明書が授与された日付です。ただし、この属性はnull許容です。人々は仕事を探している間もプログラムを完了している可能性があります。または、プログラムから完全に脱落した可能性があります。
- パーセンテージ およびcgpa –これらの列には、学位または証明書コースでユーザーが達成した成績のパーセンテージまたはCGPA(累積成績平均点)が格納されます。
experience_detail テーブルには、ユーザーの過去および現在の専門的な経験の記録が保持されます。次の重要な列が含まれています。
- user_account_id –この列は
user_accountテーブルであり、このテーブルの主キーです。 - is_current_job –これは、ユーザーの現在のジョブを示すインジケーター列です。この列は、ユーザーの現在の場所と、ユーザーが現在の位置を保持している期間を取得する上でも重要な役割を果たします。
- start_date –これはユーザーがジョブを開始したときに保存されます。
- end_date –これはユーザーがジョブを終了したときに保存されます。
- job_title –これはユーザーの職務に関する情報を保持します。
- company_name –この属性は、ジョブに関連付けられた関連する会社名を保持します。
- job_location_city –これは、仕事があった都市を意味します。
- job_location_state –これは、ジョブが配置された状態を示します。
- job_location_country –これは、仕事があった国を意味します。
- 説明 –この列には、職務と責任、課題、および成果に関する詳細が格納されます。
求職者は複数のスキルを持つことができます。これらすべてのスキルセットの記録を保持するために、テーブルseeker_skill_set 。列は次のとおりです。
- user_account_id –この列は
user_accountテーブルであり、このテーブルの主キーです。 - kill_set_id –このIDは、ユーザーが所有するスキルセットを示します。
- kill_level –この数値属性は、特定のスキルにおける求職者の専門知識を定量化します。 1(初心者)から10(エキスパート)までの数字は、彼らの経験レベルを示しています。
最後に、skill_set 表には、上記の表の skir_set_idで参照されているすべてのスキルの説明が含まれています 属性。 kill_set_nameの2つの列のみが含まれます およびそれに関連するid 。
3。仕事の投稿と検索
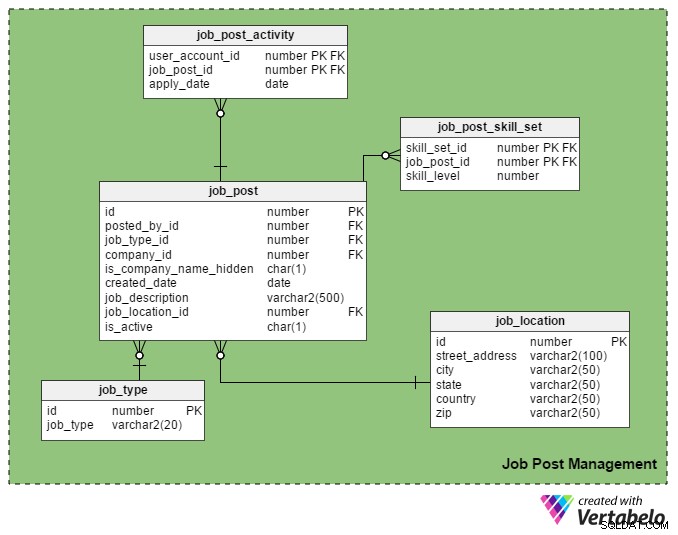
これは、求人ポータルの主要なUSP(Unique Selling Point)です。登録された採用担当者のみがポータルに求人を投稿でき、登録された求職者のみが応募できます。
job_post テーブルは、このサブジェクトエリアのメインテーブルです。ご想像のとおり、求人情報の詳細が含まれています。このセクションの他のすべてのテーブルは、その周りに作成され、リンクされています。
- id –これはこのテーブルの主キーです。各役職には一意の番号が割り当てられており、この番号は他の表で参照されています。
- posted_by_id –この列は register_user_idを保持します 仕事を投稿した採用担当者の
- job_type_id –この列は、ジョブの期間が永続的であるか一時的(契約)であるかを示します。
- company_id –この列には、役職に関連する会社のIDが格納されます。
companyテーブル。 - is_company_name_hidden –これは、求職者に会社の名前を表示する必要があるかどうかを示すフラグ列です。採用担当者は、自分の投稿に会社名を表示したくない場合があります。代わりに、「Global Automobile Company」、「California-BasedITCompany」などの用語を使用します。
- created_date –これはジョブが投稿された日付を保存します。
- job_description –これは仕事の簡単な説明を保持します。
- job_location_id –これは
job_locationジョブの実際の場所を格納するテーブル:住所、市、州、国、および郵便番号。 - is_active –これは、ジョブがまだ開いているかどうかを示します。採用担当者は、ポジションが埋まるとすぐに投稿を非アクティブとしてマークできます。
job_post_skill_set テーブルには、ジョブに必要なスキルセットに関する詳細が格納されます。テーブルの構造は、seeker_skill_set テーブル。
そして、このセクションの最後の表であるjob_post_activity 表には、求職者がいつ仕事に応募するかについての詳細が記載されています。
このオンライン求人ポータルデータモデルに何を追加しますか?
今日のオンラインジョブポータルは、ジョブを投稿して応募するためのプラットフォームを提供するだけではありません。多くの場合、次のような他の専門サービスが含まれます:
- 求人応募を追跡するための個人用ダッシュボード
- アプリケーションのリアルタイム更新
- ビデオ履歴書ビルダー
- 専門家の履歴書作成サービス
- LinkedInまたはその他のソーシャルメディアプロファイルビルダー
- 職務、企業、業界、または地理的な場所にわたる給与レポート
これらの機能をシステムに組み込みたい場合、どのような追加の変更を加える必要がありますか?あなたは求人ポータルで他の必需品を考えることができますか?
コメントセクションでご意見をお聞かせください。