データベースロードバランサーまたはデータベースリバースプロキシは、受信データベースのワークロードを、その背後で実行されている複数のデータベースサーバーに分散します。データベースロードバランサーを使用する目的は、接続するアプリケーションに単一のデータベースエンドポイントを提供し、クエリスループットを向上させ、遅延を最小限に抑え、データベースサーバーのリソース使用率を最大化することです。
データベースロードバランサートポロジには、次の2つの方法があります。
このブログ投稿では、両方のトポロジをカバーし、各セットアップの長所と短所を理解します。また、両方のトポロジを一緒に混合することは可能でしょうか?
一元化されたセットアップでは、次の図に示すように、データ層とプレゼンテーション層の間にリバースプロキシが配置されます。
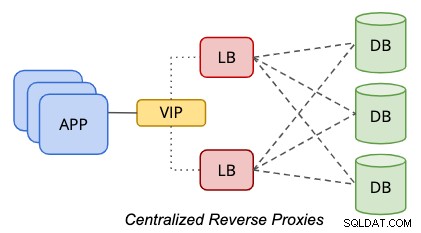
単一障害点を排除するには、次のように設定する必要があります。冗長性を確保するために、2つ以上のロードバランサノードをアップします。アプリケーションが複数のデータベースエンドポイントを処理できる場合、たとえば、ロードバランサーがクエリ処理に対して正常である場合、アプリケーションまたはデータベースドライバーが正常性チェックを実行できる場合は、仮想IPアドレスの部分をスキップできます。それ以外の場合は、両方のロードバランサーノードを共通のホスト名または仮想IPアドレスで結び付けて、単一のデータベースエンドポイントを使用してデータ層にアクセスする必要があるデータベースクライアントに透過性を提供する必要があります。仮想IPアドレスの使用をスキップする場合は、DNSまたはホストマッピングを使用することもできます。
この層ベースのアプローチは、独立した静的ホスト配置のため、管理がはるかに簡単です。アプリケーション層に対する復元力、冗長性、および透過性の強固な基盤のため、ロードバランサー層がスケールアウト(ノードの追加)される可能性はほとんどありません。おそらく、ホストをスケールアップする必要があります(ホストにリソースを追加する)。これは、ビジネスの成長に伴ってロードバランサーのワークロードがより厳しくなった後、将来的には一般的に発生します。
このトポロジでは、追加の層とホストが必要です。これは、物理サーバーを備えたベアメタルインフラストラクチャではコストがかかる可能性があります。このセットアップは、クラウドまたは仮想環境での管理が容易です。クラウドまたは仮想環境では、電力、ラックスペース、ネットワークコストなどの物理インフラストラクチャのコストをあまりかけずに、アプリケーション層とデータベース層の間に層を追加する柔軟性があります。
分散トポロジのセットアップでは、次の図で簡略化されているように、ロードバランサーはプレゼンテーション層(アプリケーションまたはWebサーバー)内に同じ場所に配置されます。
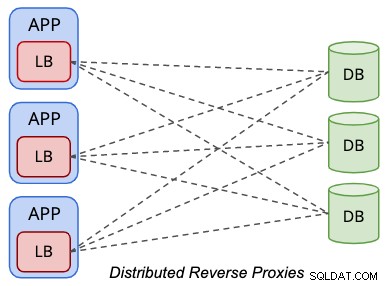
アプリケーションは、データベースロードバランサーをローカルデータベースサーバーと同様に扱います。ロードバランサーは、アプリケーションの観点からリモートデータベースの表現になります。通常、ロードバランサーは、127.0.0.1や「localhost」などのローカルネットワークインターフェイスをリッスンします。これにより、アプリケーションのデータベースエンドポイントデータベースホストが合理化されます。
このトポロジで実行する利点の1つは、負荷分散の目的で追加のホストを必要としないことです。プレゼンテーション層内でロードバランサー層を組み合わせることで、少なくとも2つのホストを節約できます。ベアメタル環境では、このトポロジにより、何年にもわたって多くの費用を節約できる可能性があります。一般に、ロードバランサーのワークロードは、データベースやアプリケーションのワークロードと比較した場合、要求がはるかに少ないため、同じハードウェアリソースをアプリケーションと共有することが正当化されます。
アプリケーションサーバーと同じ場所に配置する場合は、リバースプロキシをアプリケーションに近づけて、単一障害点を排除します。これにより、特にProxySQLやMaxScaleなどの結果セットのキャッシュをサポートするデータベースロードバランサーの場合、アプリケーションとデータ層が地理的に離れている場合に、アプリケーションのパフォーマンスを大幅に向上させることができます。一方、データベースロードバランサーの数は通常、アプリケーションノードの数と同じです。つまり、アプリケーション層をスケールアップすると、データベースロードバランサーの数が増え、データベースの正常性のパフォーマンスが低下する可能性があります。サービスを確認してください。ロードバランサーのヘルスチェックは、データベースノードの正しい状態に追いつく責任があるため、少しおしゃべりであることに注意してください。
Chef、Puppet、AnsibleなどのITインフラストラクチャ自動化ツールとコンテナーオーケストレーションツールの助けを借りて、このトポロジの複数のロードバランサーインスタンスの展開と管理を自動化することはもはや不可能な作業ではありません。ただし、多くのロードバランサーノードを処理する際の過剰な作業を削減するために、運用チームが実稼働環境でテスト済みの展開および管理ポリシーを考案するための別の学習曲線があります。バックアップ/復元、アップグレード/ダウングレード、構成管理、サービス制御、障害管理など、データベースロードバランサーのすべての重要な管理面をお見逃しなく。
次の図に示すように、分散トポロジは、ProxySQLなどのサポートされているデータベースロードバランサーの集中トポロジと組み合わせることができます。
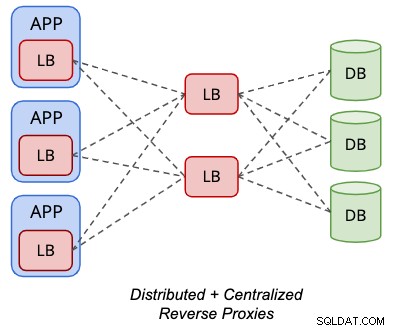
ProxySQLインスタンスのバックエンド「サーバー」は、ProxySQLの別のセットにすることができます代わりにノード。この構成では、データベースノードへの単一エンドポイントアクセスに仮想IPアドレスは必要ありません。これは、アプリケーションサーバーでローカルにホストされるローカルProxySQLインスタンスが、アプリケーションの観点から単一エンドポイントアクセスになるためです。
ただし、これには2つのバージョンのロードバランサー構成が必要です。1つはアプリケーション層に存在し、もう1つはロードバランサー層に存在します。また、仮想IPアドレス技術、IPフェイルオーバーなどについて学ぶ必要がない限り、より多くのホストが必要になります。分散セットアップと集中セットアップの両方の長所と短所は、このトポロジで融合されています。
各トポロジには独自の長所と短所があり、最初から十分に計画する必要があります。この早期の決定は重要であり、長期的にはアプリケーションのパフォーマンス、スケーラビリティ、信頼性、可用性に大きな影響を与える可能性があります。