このブログ投稿は、MySQLのインデックスに関する一連のブログの第3部です。 。 MySQLインデックスに関するブログ投稿シリーズの第2部では、インデックスとストレージエンジンについて説明し、主キーに関するいくつかの考慮事項に触れました。ディスカッションには、列プレフィックスを一致させる方法、FULLTEXTインデックスに関するいくつかの考慮事項、ワイルドカードでBツリーインデックスを使用する方法、およびClusterControlを使用してクエリのパフォーマンスを監視する方法(その後のインデックス)が含まれていました。
このブログ投稿では、MySQLのインデックスについて詳しく説明します。 :ハッシュインデックス、インデックスカーディナリティ、インデックス選択性について説明し、インデックスについての興味深い詳細を説明します。また、いくつかのインデックス作成戦略についても説明します。そしてもちろん、ClusterControlについても触れます。始めましょうか?
MySQLのハッシュインデックス
MySQL DBAとMySQLを扱う開発者も、MySQLに関する限り、別のトリックを持っています。ハッシュインデックスもオプションです。ハッシュインデックスは、MySQLのMEMORYエンジンで頻繁に使用されます。MySQLのほとんどすべての場合と同様に、これらの種類のインデックスには独自の長所と短所があります。これらの種類のインデックスの主な欠点は、=または<=>演算子を使用する等式比較にのみ使用されることです。つまり、値の範囲を検索する場合はあまり役に立ちませんが、主な利点は次のとおりです。そのルックアップは非常に高速です。さらにいくつかの欠点には、開発者がキーの左端のプレフィックスを使用して行を検索できないという事実(必要な場合は、代わりにBツリーインデックスを使用する)、MySQLが行の数を概算できないという事実があります。 2つの値の間-ハッシュインデックスが使用されている場合、オプティマイザはハッシュインデックスを使用してORDERBY操作を高速化することもできません。 MEMORYエンジンがサポートするのはハッシュインデックスだけではないことに注意してください。MEMORYエンジンはBツリーインデックスも持つことができます。
MySQLのインデックスカーディナリティ
MySQLインデックスに関する限り、別の用語が使われていることもあるかもしれません。この用語はインデックスカーディナリティと呼ばれます。非常に簡単に言えば、インデックスのカーディナリティとは、インデックスを使用する列に格納されている値の一意性を指します。特定のインデックスのインデックスカーディナリティを表示するには、phpMyAdminの[Structure]タブに移動してその情報を確認するか、SHOWINDEXESクエリを実行することもできます。
mysql> SHOW INDEXES FROM demo_table;
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| demo_table | 1 | demo | 1 | demo | A | 494573 | NULL | NULL | | BTREE | | |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)ご覧のとおり、上記のSHOW INDEXESクエリ出力には多くのフィールドがあり、そのうちの1つはインデックスのカーディナリティを示しています。このフィールドは、インデックス内の一意の値の推定数を返します。カーディナリティが高いほど、クエリオプティマイザがルックアップにインデックスを使用する可能性が高くなります。そうは言っても、インデックスカーディナリティには兄弟もいます。彼の名前はインデックス選択性です。
インデックスの選択性は、テーブル内のレコードの数に対する個別の値の数です。簡単に言うと、インデックスの選択性は、データベースインデックスがMySQLが値の検索を絞り込むのにどれだけ厳密に役立つかを定義します。理想的なインデックス選択性は1の値です。インデックス選択性は、テーブル内の個別の値をレコードの総数で割ることによって計算されます。たとえば、テーブルに1,000,000レコードがあるが、そのうちの100,000のみが個別値である場合です。 、インデックスの選択性は0.1になります。テーブルに10,000のレコードがあり、そのうちの8,500が個別の値である場合、インデックスの選択性は0.85になります。それははるかに良いです。あなたはポイントを取得します。インデックスの選択性が高いほど、優れています。
MySQLのインデックスのカバー
カバーするインデックスは、InnoDBの特別な種類のインデックスです。カバーするインデックスが使用されている場合、クエリに必要なすべてのフィールドがインデックスに含まれるか、「カバーされる」ため、データの代わりにインデックスのみを読み取ることのメリットを享受できます。他に何も役に立たない場合は、カバーするインデックスがパフォーマンスを向上させるためのチケットになる可能性があります。カバーインデックスを使用する利点には、次のようなものがあります。
-
カバーインデックスが役立つ可能性のある主なシナリオの1つには、追加のI/O読み取りなしでクエリを提供することが含まれます。大きなテーブルで。
-
MySQLは、インデックスエントリが行のサイズよりも小さいため、アクセスできるデータも少なくなります。
-
ほとんどのストレージエンジンは、データよりもインデックスをキャッシュします。
テーブルにカバーするインデックスを作成するのは非常に簡単です。SELECT、WHERE、およびGROUPBY句でアクセスされるフィールドをカバーするだけです。
ALTER TABLE demo_table ADD INDEX index_name(column_1, column_2, column_3);インデックスをカバーする場合は、インデックス内の列の正しい順序を選択することが非常に重要であることに注意してください。カバーするインデックスを有効にするには、WHERE句で使用する列を最初に配置し、次にORDERBYとGROUPBYを配置し、次にSELECT句で使用する列を配置します。
MySQLのインデックス作成戦略
MySQLのインデックスに関するブログ投稿のこれらの3つの部分でカバーされているアドバイスに従うと、非常に優れた基盤が得られますが、必要に応じて使用できるインデックス戦略もいくつかあります。 MySQLアーキテクチャのインデックスの力を実際に活用します。 MySQLのベストプラクティスに準拠するインデックスについては、次のことを考慮してください。
-
インデックスを使用する列を分離する-一般に、MySQLは、列が使用されているものは分離されていません。たとえば、このようなクエリは分離されていないため、インデックスを使用しません。
SELECT demo_column FROM demo_table WHERE demo_id + 1 = 10;
ただし、このようなクエリは次のようになります。
SELECT demo_column FROM demo_table WHERE demo_id = 10; -
インデックスを作成する列にインデックスを使用しないでください。たとえば、このようなクエリを使用してもあまり効果がないため、可能であれば、このようなクエリは避けたほうがよいでしょう。
SELECT demo_column FROM demo_table WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(column_date) <= 10; -
インデックス付き列と一緒にLIKEクエリを使用する場合は、検索クエリの先頭にワイルドカードを配置しないでください。そうすれば、MySQLもインデックスを使用しません。これは、次のようなクエリを作成する代わりです:
SELECT * FROM demo_table WHERE demo_column LIKE ‘%search query%’;
次のように書くことを検討してください:SELECT * FROM demo_table WHERE demo_column LIKE ‘search_query%’;
MySQLは列の先頭を認識しており、インデックスをより効果的に使用できるため、2番目のクエリの方が優れています。ただし、すべての場合と同様に、インデックスが実際にMySQLで使用されていることを確認したい場合は、EXPLAINステートメントが非常に役立ちます。
ClusterControlを使用してクエリのパフォーマンスを維持する
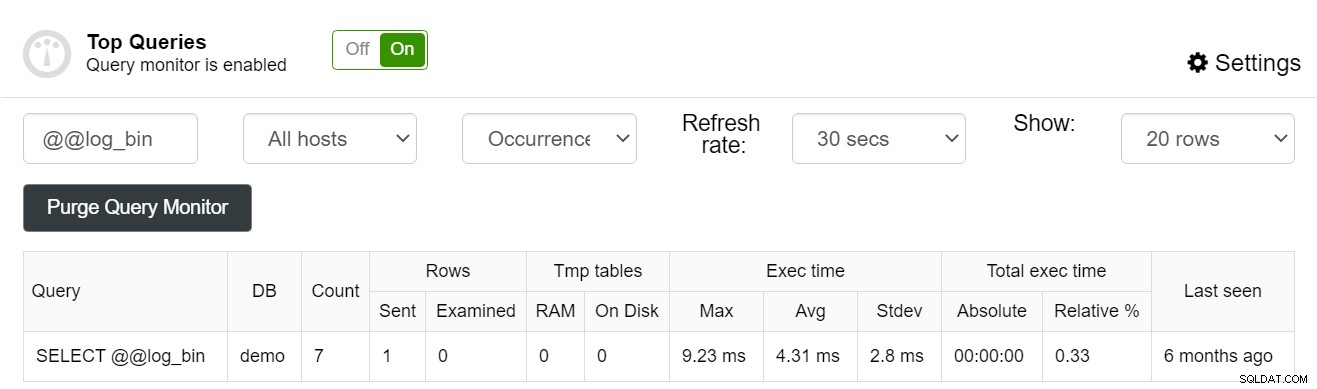
MySQLのパフォーマンスを向上させたい場合は、上記のアドバイスで正しい方向に進むことができます。ただし、さらに何かが必要だと思われる場合は、ClusterControlforMySQLを検討してください。 ClusterControlが役立つパフォーマンス管理を含めることができることの1つは、以前のブログ投稿ですでに述べたように、ClusterControlにはクエリも含まれているため、クエリのパフォーマンスを常に最高の状態に保つのに役立ちます。クエリのパフォーマンスを監視し、実行速度の遅いクエリを確認し、データベースのパフォーマンスのボトルネックの可能性を自分で気付く前に警告するクエリの外れ値を確認できるモニター:
クエリをフィルタリングして、インデックスの場合に仮定を立てることもできます個々のクエリで使用されたかどうか:
ClusterControlは、メンテナンスの手間を省きながら、データベースのパフォーマンスを向上させるための優れたツールです。 ClusterControlがMySQLインスタンスのパフォーマンスを向上させるために何ができるかについて詳しくは、ClusterControlforMySQLページをご覧になることを検討してください。
おそらく今ではお分かりのように、MySQLのインデックスは非常に複雑な獣です。 MySQLインスタンスに最適なインデックスを選択するには、インデックスとは何か、インデックスの機能、MySQLインデックスの種類、利点と欠点を理解し、MySQLインデックスがストレージエンジンとどのように相互作用するかを理解し、ClusterControlを参照してください。 MySQLのインデックスに関連する特定のタスクを自動化すると、1日が楽になると思われる場合はMySQL。