MySQL / MariaDBでデータベーススキーマの変更を監視すると、データベースの拡張、テーブル定義の変更、データサイズ、インデックスサイズ、または行サイズの分析にかかる時間を節約できるため、非常に役立ちます。 MySQL / MariaDBの場合、information_schemaをperformance_schemaと一緒に参照するクエリを実行すると、さらに分析するための集合的な結果が得られます。 sysスキーマは、データベースの変更またはアクティビティの追跡に非常に役立つ集合的なメトリックとして機能するビューを提供します。
データベースサーバーが多数ある場合、常にクエリを実行するのは面倒です。また、その結果をより読みやすく、理解しやすいものに消化する必要があります。
このブログでは、既存のデータベースを監視し、データベースの変更またはスキーマの変更操作に関するメトリックを収集するためのユーティリティツールとして役立つ自動化を作成します。
データベーススキーマオブジェクトチェックの自動化の作成
この演習では、次の指標を監視します。
-
主キーテーブルなし
-
重複するインデックス
-
データベーススキーマの行の総数のグラフを生成します
-
データベーススキーマの合計サイズのグラフを生成します
この演習では、注意が必要であり、MySQL/MariaDBデータベースからより高度なメトリックを収集するように変更できます。
IaCと自動化にPuppetを使用する
この演習では、Puppetを使用して自動化を提供し、監視するメトリックに基づいて期待される結果を生成します。サーバーとクライアントを含むPuppetのインストールとセットアップについては説明しませんので、Puppetの使用方法を知っていることを期待します。 Puppetのセットアップとインストールについて説明している古いブログ「MySQLGaleraClusterのAmazonAWSへのPuppetによる自動デプロイ」にアクセスすることをお勧めします。
この演習では最新バージョンのPuppetを使用しますが、コードは基本的な構文で構成されているため、古いバージョンのPuppetで実行されます。
この演習では、Percona Server 8.0.22-13を使用します。これは、主にテストと、ビジネスまたは個人使用のマイナーな展開にPerconaServerを使用するためです。
ここで私が行った仮定は、自動展開を受信するためにマスターサーバーと通信する準備ができている登録済みクライアントでマスターサーバーをセットアップしたことです。
先に進む前に、サーバー情報は次のとおりです。
マスターサーバー:192.168.40.200
クライアント/エージェントサーバー:192.168.40.160
このブログでは、クライアント/エージェントサーバーがデータベースサーバーを実行している場所です。実際のシナリオでは、特に監視用である必要はありません。ターゲットノードと安全に通信できる限り、それも完璧なセットアップです。
-
マスターサーバーに移動し、パス/ etc / puppetlabs / code / environment / product/moduleに移動します。この演習に必要なディレクトリを作成しましょう:
mkdir schema_change_mon/{files,manifests}
-
必要なファイルを作成する
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
init.ppスクリプトに次の内容を入力します。
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
graphing_gen.shファイルに入力します。このスクリプトはターゲットノードで実行され、データベース内の行の総数とデータベースの合計サイズのグラフを生成します。このスクリプトでは、スクリプトを単純化して、MyISAMまたはInnoDBタイプのデータベースのみを許可しましょう。
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
最後に、モジュールパスディレクトリまたは/ etc / puppetlabs / code/environmentsに移動します/私のセットアップでのプロダクション。マニフェスト/schema_change_mon.ppファイルを作成しましょう。
touch manifests/schema_change_mon.pp-
次に、ファイルmanifests/schema_change_mon.ppに次の内容を入力します。
>
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
完了したら、私のようなツリー構造が必要です。
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppモジュールは何をしますか?
schema_change_monと呼ばれるモジュールは、以下を収集します
exec { "mysql-without-primary-key" :...
mysqlコマンドを実行し、クエリを実行して主キーのないテーブルを取得します。次に、
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :次に、線は収集されたメトリックに基づいてグラフを生成します。これらは次の行です
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…クエリが正常に実行されると、https://quickchart.io/によって提供されるAPIに依存するグラフが生成されます。
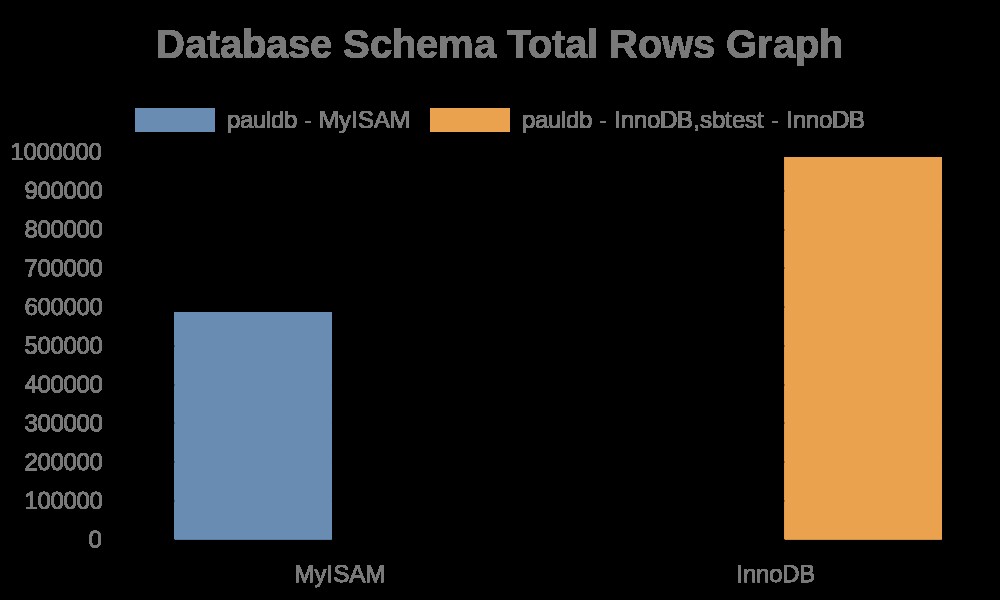
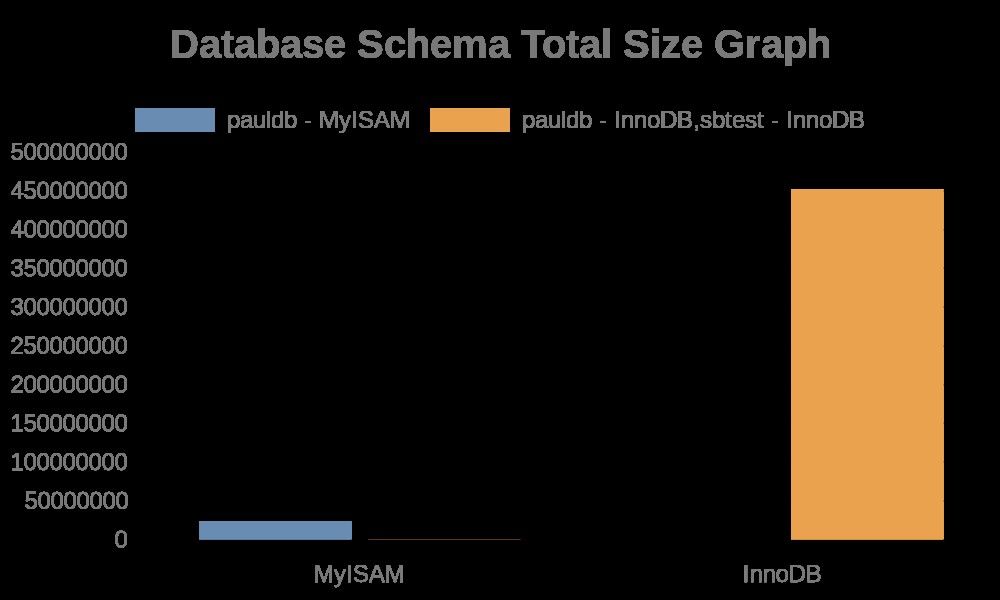
ファイルログには、テーブル名とインデックス名を含む文字列が含まれているだけです。以下の結果をご覧ください
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBClusterControlを使用しないのはなぜですか?
この演習では、自動化と、変更や操作などのデータベーススキーマ統計の取得を紹介しているため、ClusterControlもこれを提供します。これ以外にも他の機能があり、車輪の再発明をする必要はありません。 ClusterControlは、上記のようなデッドロックや、以下に示すような長時間実行されるクエリなどのトランザクションログを提供できます。
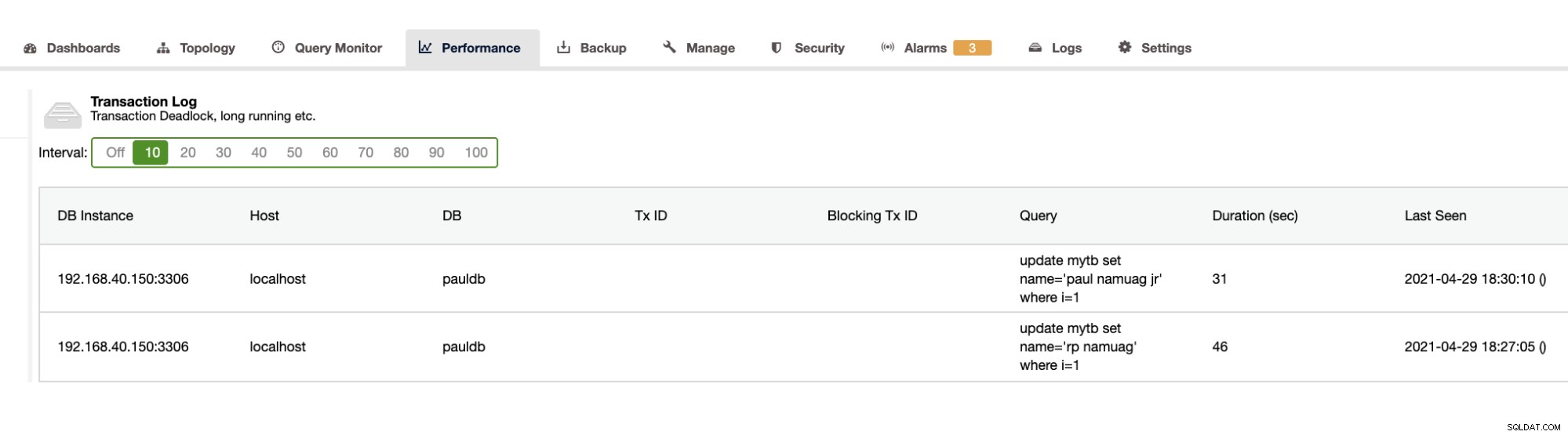
ClusterControlは、以下に示すようにDBの増加も示します。
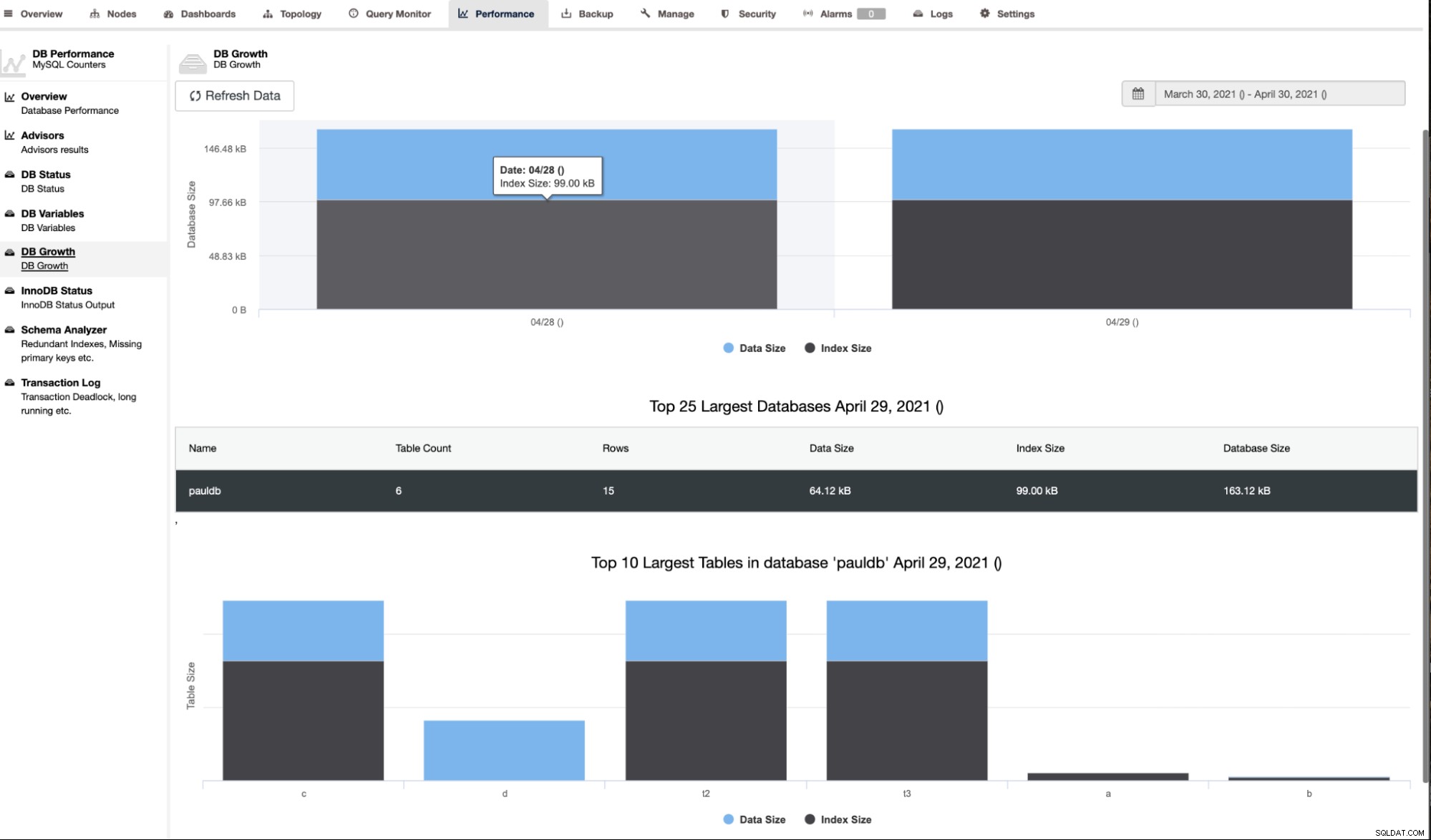
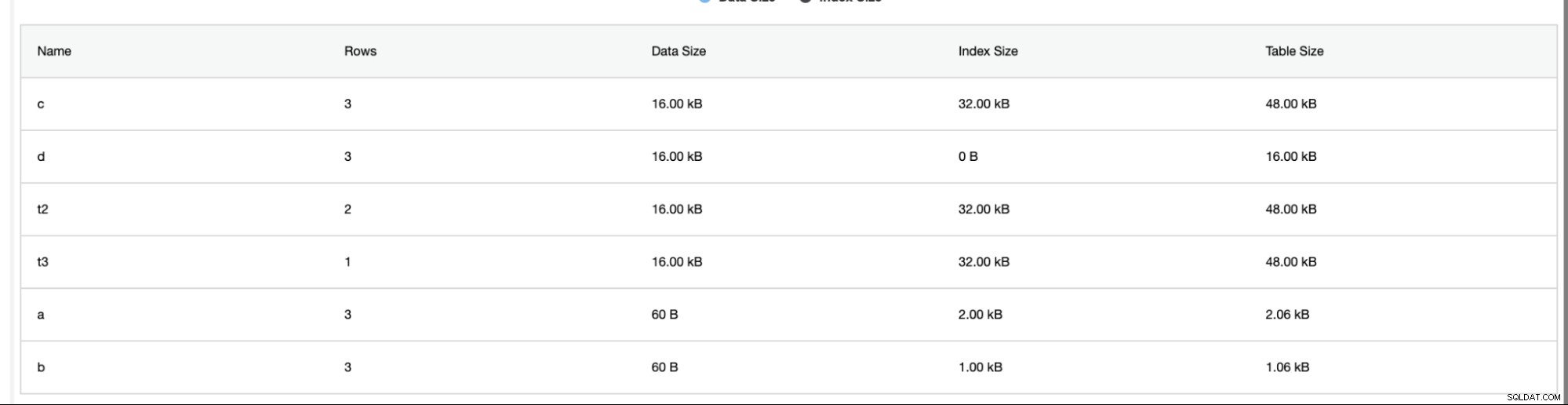
ClusterControlは、行数、ディスクサイズ、インデックスサイズ、合計サイズなどの追加情報も提供します。

また、プライマリのない重複したインデックスまたはテーブルが検出された場合のアラームも提供します以下のようなキー

ClusterControlとその他の機能の詳細については、製品のページをご覧ください。
データベースの変更や、書き込み、重複インデックス、DDL変更などの操作の更新、多くのデータベースアクティビティなどのスキーマ統計を監視するための自動化を提供することは、DBAにとって非常に有益です。これは、データベースをロックしたり、データベースを失効させたりする可能性のある不正なクエリの考えられる原因の概要を示す、弱いリンクや問題のあるクエリをすばやく特定するのに役立ちます。