これらすべてを手動で実行したい場合、人為的エラーが発生する可能性が高く、プロセスが遅くなります。このブログでは、ClusterControlを使用してMySQL、MariaDB、またはPerconaServerデータベースをアップグレードするためのテストを自動化する方法を説明します。
アップグレードには、マイナーアップグレードとメジャーアップグレードの2種類があります。
最初のマイナーアップグレードは最も一般的で安全なアップグレードであり、ほとんどの場合、これは適切に実行されます。 100%安全なものはないため、常にバックアップとレプリケーションのスレーブノードが必要です。アップグレードで問題が発生し、何らかの理由でロールバック/ダウングレードできない場合でも、スレーブノードを昇格させることができます。システムは引き続き使用できます。中断することなく作業できます。
ClusterControlを使用してこの種のアップグレードを実行できます。これを行うには、ClusterControl->クラスターの選択->管理->アップグレードに移動します。
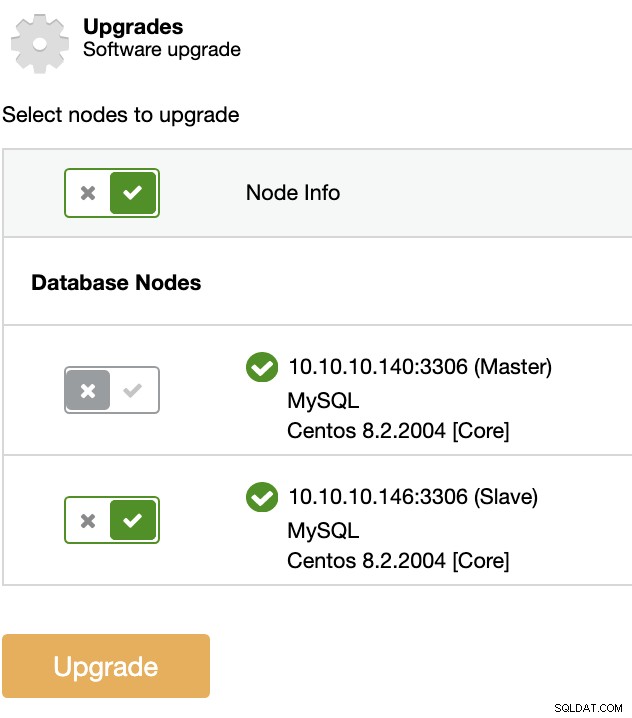
選択した各ノードで、アップグレード手順は次のようになります。
-
ノードの停止
-
ノードのアップグレード
-
ノードの開始
メジャーアップグレードの場合、本番環境では問題が発生するリスクが高すぎるため、インプレースアップグレードはお勧めしません。これの代わりに、現在のデータベースクラスターのクローンを作成し、そこでアプリケーションをテストできます。終了したら、データベースクラスターを再作成するか、新しいバージョンで新しいクラスターを作成して、準備ができたらトラフィックを切り替えることができます。これらのアップグレードにはさまざまなアプローチがあります。ノードを1つずつアップグレードしたり、現在のノードからトラフィックを複製する別のクラスターを作成したり、ロードバランサーを使用して高可用性やその他のオプションを改善したりすることもできます。最善のアプローチは、ダウンタイムの許容範囲と目標復旧時間(RTO)によって異なります。
前述のように、アップグレードが安全であることを確認するために最初にすべてをテストする必要があるため、ClusterControlを使用してメジャーアップグレードを直接実行することはできませんが、さまざまなClusterControl機能を使用して作成できます。このタスクは簡単です。では、これらの機能のいくつかを見てみましょう。
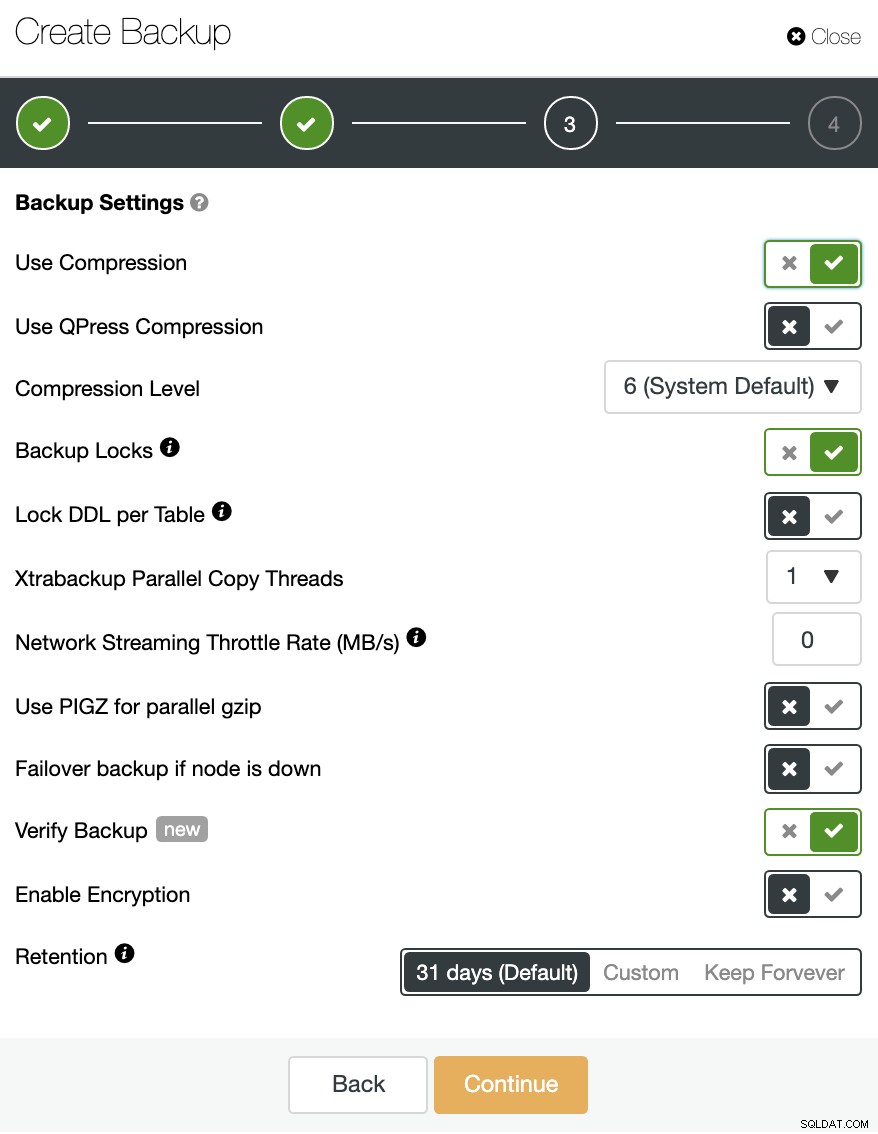
バックアップは、アップグレードする前に必須です。優れたバックアップポリシーは、ビジネスにとって大きな問題を回避できます。それでは、ClusterControlがこれを自動化する方法を見てみましょう。
ClusterControlに移動->クラスターを選択->バックアップ->バックアップの作成
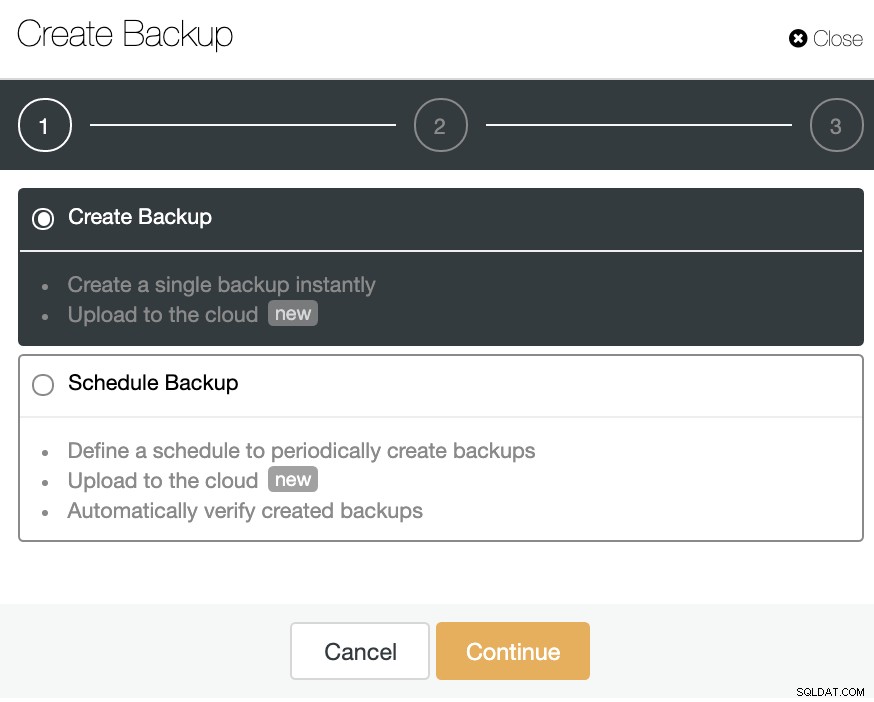
新しいバックアップを作成するか、スケジュールされたバックアップを構成できます。
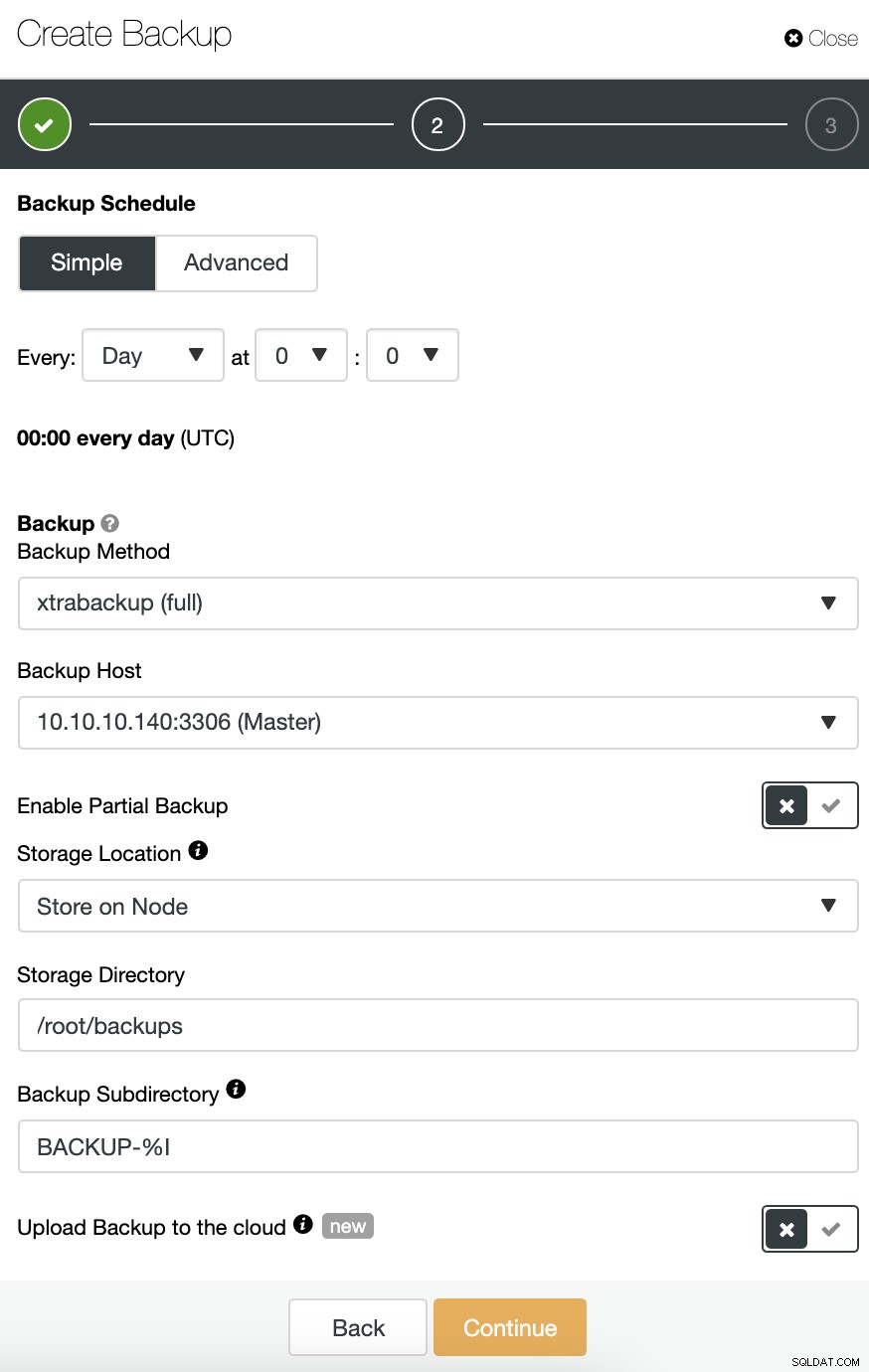
データベーステクノロジーに応じて、さまざまなバックアップ方法を選択できます。同じセクションで、バックアップを取得するサーバー、バックアップを保存する場所、および同じジョブでバックアップをクラウド(AWS、Azure、またはGoogle Cloud)にアップロードしたい。
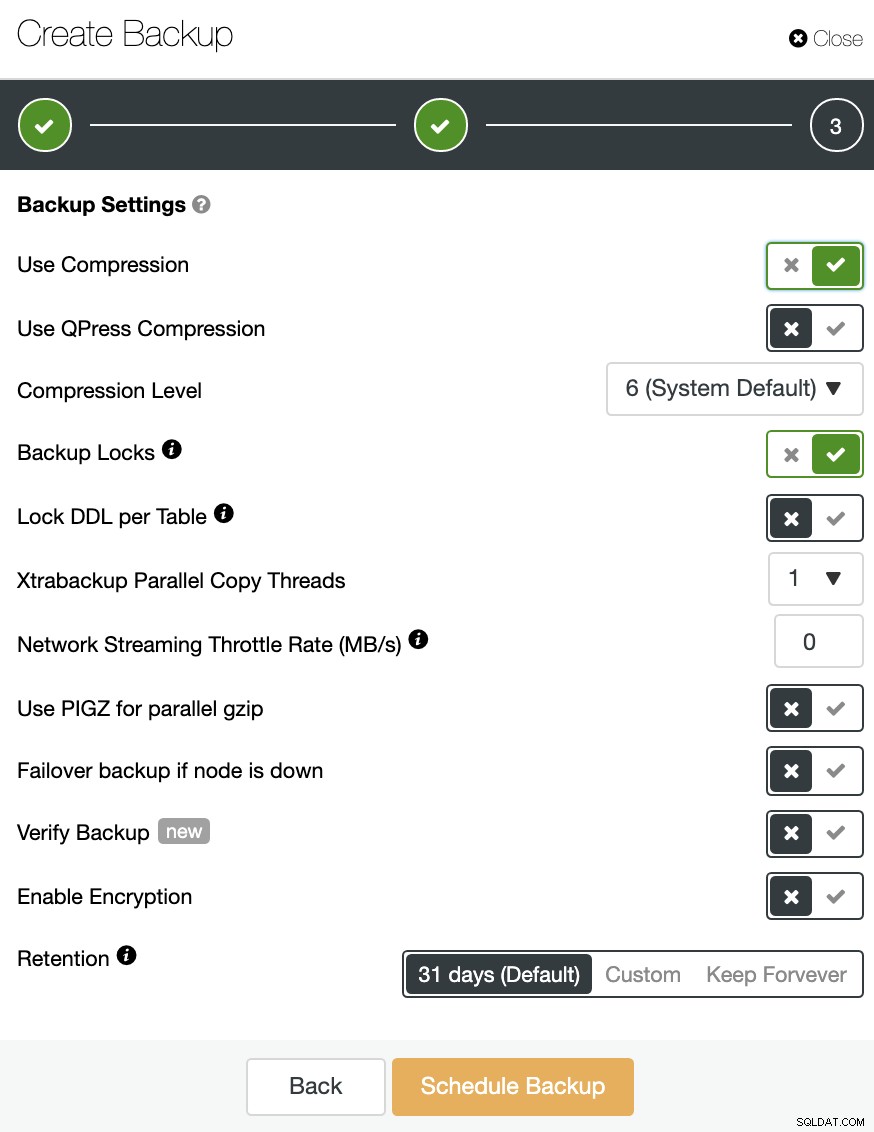
バックアップを圧縮および暗号化し、保存期間を指定することもできます。
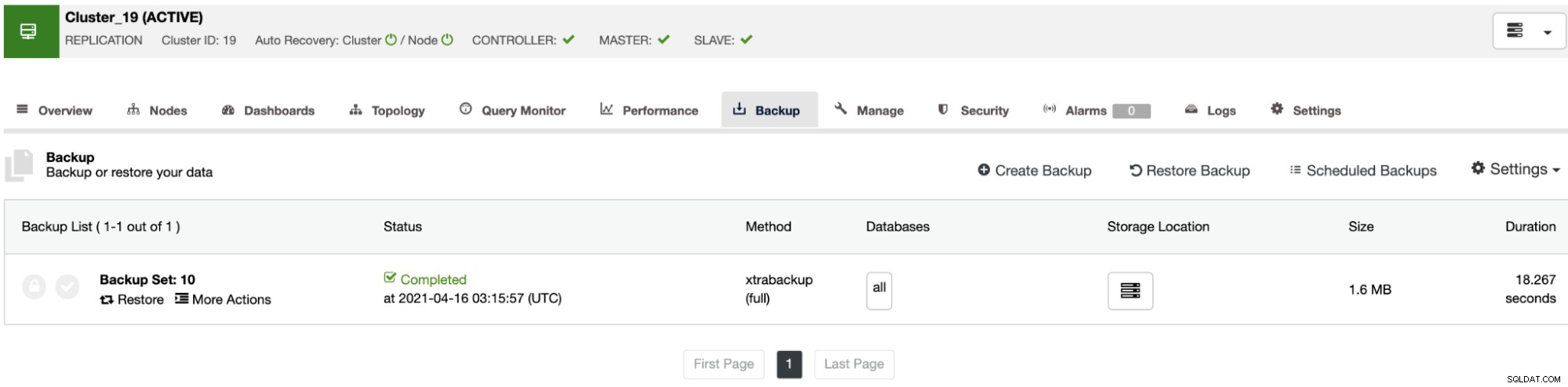
バックアップセクションでは、バックアップの進行状況と、方法、サイズ、場所などの情報を確認できます。
このため、すべてを最初から作成する必要はありません。これの代わりに、ClusterControlを使用して、手動または自動でこれを行うことができます。
[バックアップ]セクションで、[スタンドアロンホストで復元して確認する]オプションを選択して、別のノードにバックアップを復元できます。
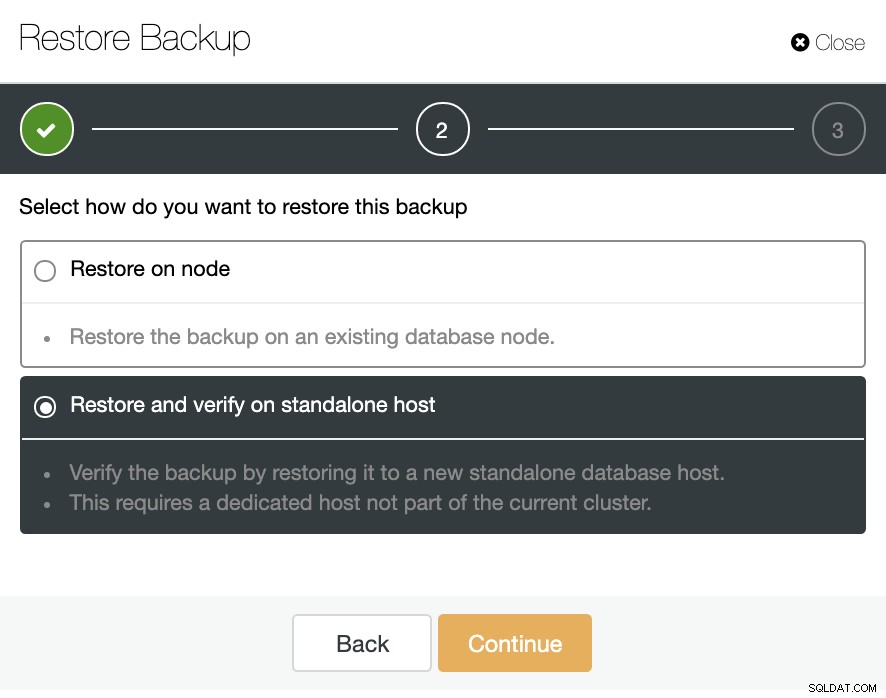
ここで、ClusterControlでソフトウェアを新しいノードにインストールするかどうかを指定し、ファイアウォールまたはAppArmor / SELinux(OSによって異なります)を無効にすることができます。このためには、クラスターの一部ではない専用のホスト(またはVM)が必要です。
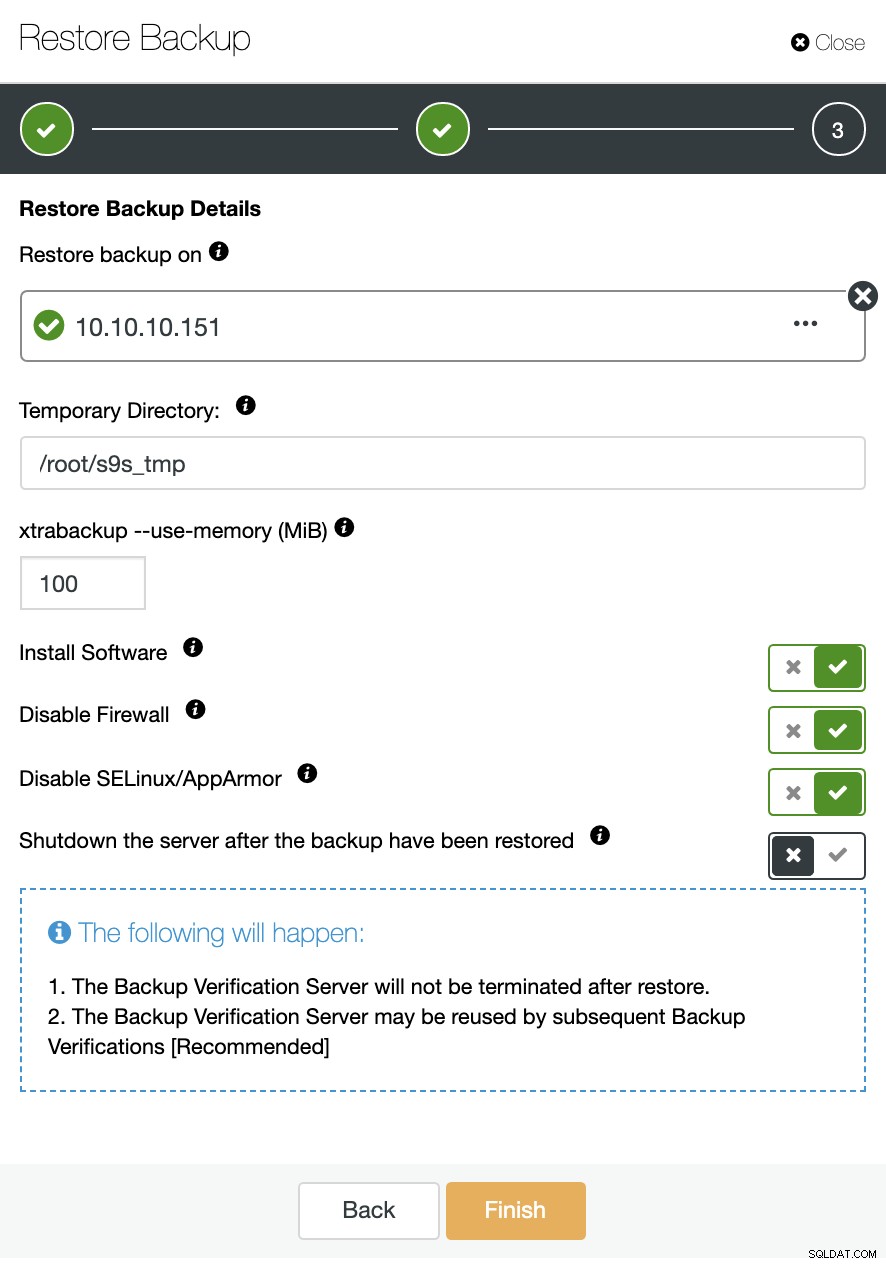
ノードを稼働させ続けるか、ClusterControlで次の復元ジョブまでデータベースサービスをシャットダウンできます。完了すると、バックアップリストに復元/検証済みのバックアップがチェックマークで示されます。
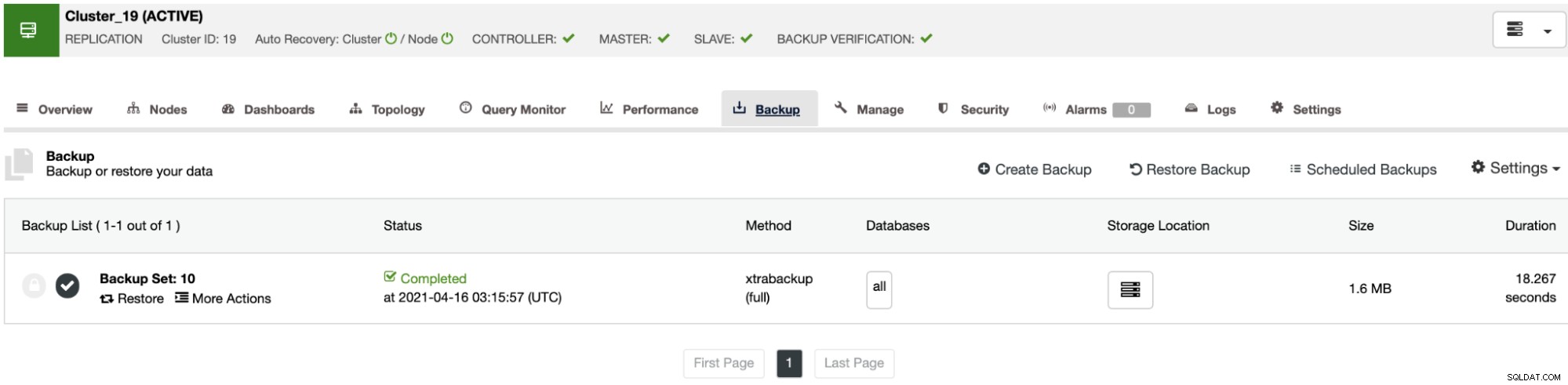
このタスクを手動で実行したくない場合は、バックアップの確認機能を使用してこのプロセスをスケジュールし、バックアップジョブでこのジョブを定期的に繰り返すことができます。これを行う方法については、次のセクションで説明します。
このタスクを自動化するには、[ClusterControl]->[クラスターの選択]->[バックアップ]->[バックアップの作成]に移動し、[スケジュールされたバックアップ]オプションを選択します。
自動検証バックアップ機能は、スケジュールされたバックアップでのみ使用でき、プロセスは前のセクションで説明したものと同じです。 2番目のステップでは、[バックアップの確認]オプションが有効になっていることを確認し、必要な情報を入力します。
ジョブが終了すると、ClusterControlバックアップセクションに確認アイコンが表示されます。これは、手動で確認を行う場合と同じですが、不要な違いがあります。復元タスクについて心配する。 ClusterControlは毎回自動的にバックアップを復元し、最新のデータを使用してアプリケーションをテストできます。
自動回復機能を有効にすると、障害が発生した場合、ClusterControlは最も高度なスレーブノードをマスターに昇格させ、問題を通知します。また、残りのスレーブノードをフェイルオーバーして、新しいマスターサーバーから複製します。
トポロジにロードバランサーがある場合、ClusterControlはそれらを再構成してトポロジの変更を適用します。
必要に応じて、手動でフェイルオーバーを実行することもできます。 ClusterControl->クラスターの選択->ノード->プロモートするノードの選択->ノードアクション->スレーブのプロモートに移動します。
このようにして、アップグレード中に問題が発生した場合は、ClusterControlを使用してできるだけ早く修正できます。
ClusterControlCLIを使用した自動化
ClusterControl CLIは、s9sとも呼ばれ、ClusterControlバージョン1.4.1で導入されたコマンドラインツールであり、ClusterControlシステムを使用してデータベースクラスターを操作、制御、および管理します。 ClusterControl CLIは、クラスター自動化への扉を開き、Ansible、Puppet、Chefなどの既存のデプロイメント自動化ツールと簡単に統合できます。このツールの例をいくつか見てみましょう。
$ s9s cluster --cluster-id=19 \
--check-pkg-upgrades \
--log
$ s9s cluster --cluster-id=19 \
--available-upgrades \
--nodes='10.10.10.146' \
--log \
--print-json
$ s9s cluster --cluster-id=19 \
--upgrade-cluster \
--nodes='10.10.10.146' \
--log$ s9s backup --create \
--backup-method=mysqldump \
--cluster-id=2 \
--nodes=10.10.10.146:3306 \
--on-controller \
--backup-directory=/storage/backups
--log$ s9s backup --restore \
--cluster-id=19 \
--backup-id=3 \
--wait$ s9s backup --verify \
--backup-id=3 \
--test-server=10.10.10.151 \
--cluster-id=19 \
--log$ s9s cluster --promote-slave \
--cluster-id=19 \
--nodes='10.10.10.146' \
--logアップグレードは必要ですが、時間のかかる作業です。アップグレードが必要になるたびにテスト環境を展開することは悪夢である可能性があり、自動化ツールなしでこれを最新の状態に維持することは困難です。
ClusterControlを使用すると、マイナーアップグレードを実行したり、テスト環境を展開してアップグレードタスクをより簡単かつ安全にすることができます。 Ansible、Puppetなどのさまざまな自動化ツールと統合することもできます。