これは、インメモリOLTPに関する一連の記事の最初の記事です。これは、新しいHekatonエンジンが内部でどのように機能するかを理解するのに役立ちます。メモリ内で最適化されたテーブルとインデックスの詳細に焦点を当てます。これはエントリレベルの記事です。つまり、SQL Serverの専門家である必要はありませんが、従来のSQLServerエンジンに関する基本的な知識が必要です。
はじめに
SQL Server 2014インメモリOLTPエンジン(Hekatonプロジェクト)は、テラバイトの使用可能なメモリと膨大な数の処理コアを利用するためにゼロから作成されました。インメモリOLTPを使用すると、ユーザーはメモリに最適化されたテーブルとインデックス、およびネイティブにコンパイルされたストアドプロシージャを操作できます。 SQL Serverが常に提供しているディスクベースのテーブルとインデックス、およびT-SQLストアドプロシージャと一緒に使用できます。
インメモリOLTPエンジンの内部と機能は、標準のリレーショナルエンジンとは大幅に異なります。複数の並行プロセスがどのように処理されるかについて知っているほとんどすべてを修正する必要があります。
SQL Serverエンジンは、ディスクベースのストレージ用に最適化されています。処理のために8KBのデータページをメモリに読み込み、変更後に8KBのデータページをディスクに書き込みます。もちろん、SQL Serverは、トランザクションログのディスクへの変更を何よりも修正します。ディスクから8KBのデータページを読み取って書き戻すと、大量のI / Oが生成され、レイテンシコストが高くなる可能性があります。バッファキャッシュ内のデータがある場合でも、SQLサーバーはそうではないと想定するように設計されているため、CPUの使用効率が低下します。
従来のディスクベースのストレージ構造の制限を考慮して、SQL Serverチームは、大容量のメインメモリとマルチコアCPU用に最適化されたデータベースエンジンの構築を開始しました。チームは次の目標を設定しました:
- 完全にメモリに保存されていたが、SQLServerの再起動でも耐久性のあるデータ用に最適化されました
- 既存のSQLServerエンジンに完全に統合されています
- OLTP操作のパフォーマンスが非常に高い
- 最新のCPU用に設計されています
SQLServerインメモリOLTPはこれらすべての目標を満たしています。
インメモリOLTPについて
SQL Server 2014インメモリOLTPは、ディスクベースのテーブルに加えて、メモリ最適化テーブルを操作するための多数のテクノロジを提供します。たとえば、T-SQLやSSMSなどの標準インターフェイスを利用してメモリ内データにアクセスできます。次の図は、8KBのデータページの読み取りと書き込みを必要とするインメモリOLTP(左側)とディスクベースのテーブル(左側)の一部として、メモリに最適化されたテーブルとインデックスを示しています。インメモリOLTPは、ネイティブにコンパイルされたストアドプロシージャもサポートし、新しいインメモリOLTPコンパイラを提供します。
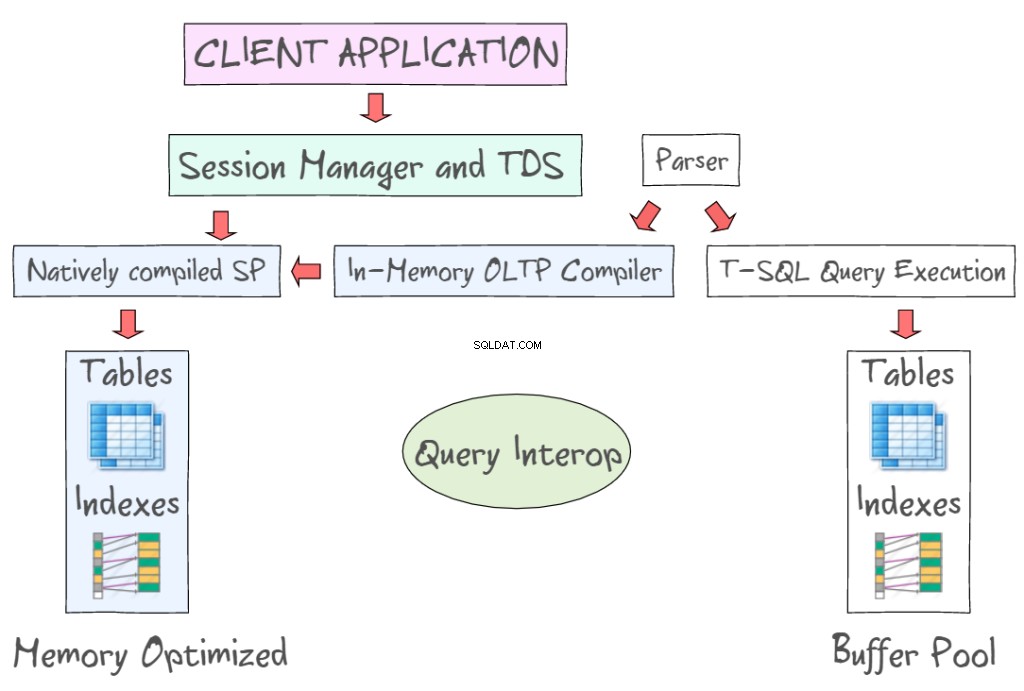
クエリ相互運用機能を使用すると、T-SQLを解釈してメモリ最適化テーブルを参照できます。トランザクションがメモリ最適化テーブルとディスクベーステーブルの両方を参照する場合、それはクロスコンテナトランザクションと呼ばれる可能性があります。クライアントアプリは、データベースサーバーとクライアント間でデータを転送するために使用されるアプリケーション層プロトコルである表形式のデータストリームを利用します。当初は、1984年にSybase SQLServerリレーショナルデータベースエンジン用にSybaseInc.によって設計および開発され、その後MicrosoftSQLServerでMicrosoftによって設計および開発されました。
メモリ最適化テーブル
ディスクベースのテーブルにアクセスしているときに、必要なデータがすでにメモリにある場合がありますが、そうではない場合があります。データがメモリにない場合、SQLServerはデータをディスクから読み取る必要があります。メモリ最適化テーブルを使用する場合の最も基本的な違いは、テーブル全体とそのインデックスが常にメモリに保存されることです。 。同時データ操作には、ロックやラッチは必要ありません。
ユーザーがメモリ内データを変更している間、SQL Serverは、サーバーのクラッシュまたは再起動時にメモリ内データを保持するためのテーブルが必要な場合に、耐久性が必要なテーブルに対してディスクI/Oを実行します。
行ベースのストレージ構造
もう1つの重要な違いは、基盤となるストレージ構造です。ディスクベースのテーブルは、ブロックアドレス可能用に最適化されています ディスクストレージ、メモリ内で最適化されたテーブルはバイトアドレス可能用に最適化されています メモリストレージ。
SQL Serverは、ディスクベースのテーブルのエクステントからのスペース割り当てを使用して、データ行を8Kデータページに保持します。データページは、ディスクおよびメモリストレージの基本単位です。ディスクからデータを読み書きしている間、SQLServerは関連するデータページのみを読み書きします。データページには、1つのテーブルまたはインデックスからのデータのみが含まれます。アプリケーションプロセスは、必要に応じて異なるデータページの行を変更します。その後、CHECKPOINT操作中に、SQL Serverは最初にログレコードをディスクに修正し、次にすべてのダーティページをディスクに書き込みます。この操作により、多くのランダムな物理I/Oが発生することがよくあります。
メモリ最適化テーブルの場合、データページもエクステントもありません。トランザクションが発生した順序で、メモリに順番に書き込まれるデータ行のみがあります。各行には、次の行へのインデックスポインタが含まれています。すべてのI/Oは、これらの構造のメモリ内スキャンです。指定されたオブジェクトに属する特定の場所にデータ行が書き込まれるという概念はありません。ただし、メモリ最適化テーブルが組織化されていないデータ行のセットとして格納されていると考える必要はありません(ディスクベースのヒープと同様)。メモリ最適化テーブルの各CREATETABLEステートメントは、SQLServerがそのテーブル内のすべてのデータ行をリンクするために使用する少なくとも1つのインデックスを作成します。
すべての単一データ行は、行ヘッダーと実際の列データであるペイロードで構成されます。ヘッダーには、行を作成したステートメント、ターゲットテーブルの各インデックスへのポインター、およびタイムスタンプ値に関する情報が格納されます。タイムスタンプは、トランザクションが行を挿入および削除した時刻を示します。 SQL Serverレコードは、新しい行バージョンを挿入し、古いバージョンを削除済みとしてマークすることによって更新されました。同じ行の複数のバージョンがいつでも存在する可能性があります。これにより、データの変更中に同じ行に同時にアクセスできます。 SQL Serverは、行バージョンのタイムスタンプを基準にしてトランザクションが開始された時間に従って、各トランザクションに関連する行バージョンを表示します。これは、新しいマルチバージョン同時実行制御の中核です。 インメモリテーブルのメカニズム。
ちなみに、オラクルには優れたマルチバージョン管理システムがあります。基本的に、次のように機能します。
- ユーザーAはトランザクションを開始し、時間T1で1000行をある値で更新します。
- ユーザーBは時間T2で同じ1000行を読み取ります。
- ユーザーAは行565を値Yで更新します(元の値はXでした)。
- ユーザーBは行565に到達し、時間T1以降にトランザクションが実行中であることを検出します。
- データベースは、変更されていないレコードをログから返します。戻り値は、T2以下の時点でコミットされた値です。
- REDOログからレコードを取得できなかった場合は、データベースが適切に設定されていないことを意味します。より多くのスペースをログに割り当てる必要があります。
- 返される結果は、トランザクションの開始時刻に関して常に同じです。したがって、トランザクション内で、読み取りの一貫性が実現されます。
ネイティブにコンパイルされたテーブル
最後の大きな違いは、メモリ内で最適化されたテーブルがネイティブにコンパイルされることです。 。ユーザーがメモリ最適化テーブルまたはインデックスを作成すると、SQL Serverはすべてのテーブルの構造(およびすべてのインデックス)をメタデータに格納します。その後、SQL Serverはそのメタデータを利用して、テーブルにアクセスするための一連のネイティブ言語ルーチンをDDLにコンパイルします。このようなDDLはデータベースに関連付けられていますが、実際にはデータベースの一部ではありません。
つまり、SQL Serverは、テーブルとインデックスだけでなく、これらの構造にアクセスして変更するためのDDLもメモリに保持します。テーブルが変更されると、SQLServerはテーブル操作のためにすべてのDDLを再作成する必要があります。そのため、一度作成したテーブルを変更することはできません。これらの操作はユーザーには見えません。
ネイティブにコンパイルされたストアドプロシージャ
ネイティブにコンパイルされたストアドプロシージャを利用してネイティブにコンパイルされたテーブルにアクセスすると、最高のパフォーマンスが得られます。このようなプロシージャにはプロセッサ命令が含まれており、さらにコンパイルすることなくCPUから直接実行できます。ただし、ネイティブにコンパイルされたストアドプロシージャのT-SQL構造には、(従来のインタープリターコードと比較して)いくつかの制限があります。もう1つの重要な点は、ネイティブにコンパイルされたストアドプロシージャは、メモリに最適化されたテーブルにしかアクセスできないことです。
ロックなし
インメモリOLTPはロックフリーシステムです。これが可能なのは、SQLServerが既存の行を変更しないためです。 UPDATE操作は、新しいバージョンを作成し、前のバージョンを削除済みとしてマークします。次に、新しいデータを含む新しい行バージョンを挿入します。
インデックス
ご想像のとおり、インデックスは従来のインデックスとは大きく異なります。メモリ内で最適化されたテーブルにはページがありません。 SQL Serverは、インデックスを利用して、テーブルに属するすべての行を単一の構造にリンクします。 CREATE INDEXステートメントを使用して、メモリ内に最適化されたテーブルのインデックスを作成することはできません。列にPRIMARYKEYを作成すると、SQLServerはその列に一意のインデックスを自動的に作成します。実際には、これが唯一許可されている一意のインデックスです。メモリ最適化テーブルには最大8つのインデックスを作成できます。
テーブルと同様に、SQLServerはメモリに最適化されたインデックスをメモリに保持します。ただし、SQLServerはインデックスの操作をログに記録しません。 SQL Serverは、テーブルの変更中にインデックスを自動的に維持します。
メモリ最適化テーブルは、次の2種類のインデックスをサポートします。ハッシュインデックス および範囲インデックス 。どちらもクラスター化されていない構造です。
ハッシュインデックス は、メモリ最適化テーブル用に特別に設計された新しいタイプのインデックスです。特定の値のルックアップを実行するのに非常に役立ちます。インデックス自体はハッシュテーブルとして保存されます。これはハッシュバケットの配列であり、各バケットは単一の行へのポインタです。
範囲インデックス (非クラスター化)は、値の範囲を取得するのに役立ちます。
回復
メモリ最適化テーブルを備えたデータベースの基本的な復元メカニズムは、ディスクベースのテーブルを備えたデータベースのリカバリメカニズムと同じです。ただし、メモリ最適化テーブルの回復には、データベースがユーザーアクセスに使用できるようになる前に、メモリ最適化テーブルをメモリにロードするステップが含まれます。
SQL Serverが再起動すると、すべてのデータベースは回復プロセスの次のフェーズを通過します。分析 、やり直し 、および元に戻す 。
分析フェーズでは、インメモリOLTPエンジンは、ロードするチェックポイントインベントリを識別し、システムテーブルのログエントリをプリロードします。また、一部のファイル割り当てログレコードも処理します。
REDOフェーズでは、データとデルタファイルのペアからのデータがメモリにロードされます。次に、最後の永続チェックポイントに基づいてアクティブなトランザクションログからデータが更新され、メモリ内のテーブルにデータが入力され、インデックスが再構築されます。このフェーズでは、ディスクベースとメモリ最適化のテーブルリカバリが同時に実行されます。
インメモリOLTPはメモリ最適化テーブルのコミットされていないトランザクションを記録しないため、メモリ最適化テーブルには元に戻すフェーズは必要ありません。
すべての操作が完了すると、データベースにアクセスできるようになります。
概要
この記事では、SQLServerインメモリOLTPエンジンについて簡単に説明しました。メモリ最適化構造がメモリに格納されることを学びました。アプリケーションプロセスは、ディスクI / Oを必要とせずに、メモリ内のこれらの構造にアクセスすることにより、必要なデータを見つけることができます。次の記事では、インメモリOLTPデータベースとテーブルを作成してアクセスする方法を見ていきます。
さらに読む
インメモリOLTP:SQLServer2016の新機能
SQLServerのメモリ最適化テーブルでのインデックスの使用