この記事の焦点は、JOINの利用にあります。まず、JOINがどのように発生するのか、なぜデータをJOINする必要があるのかについて少し説明します。次に、利用可能なJOINタイプとその使用方法を見ていきます。
基本に参加
TSQLのJOINは通常、FROM行で実行されます。
他のことに取り掛かる前に、本当の大きな問題は、「なぜJOINを実行する必要があるのか、そして実際にどのようにJOINを実行するのか」ということです。
結局のところ、これまでに使用したすべてのデータベースでは、データが複数のテーブルに分割されます。これにはさまざまな理由があります:
- データの整合性の維持
- 保存スペースの節約</li>
- データの編集を高速化
- クエリをより柔軟にする
したがって、使用するすべてのデータベースでは、実際に意味をなすために、そのデータを結合する必要があります。
たとえば、注文用と顧客用に別々のテーブルがあります。 「実際にすべてのデータをどのように接続するのか」という質問になります。それがまさにJOINがやろうとしていることです。
結合のしくみ
2つの別々のテーブルがあり、それらのテーブルが継ぎ目を作成することによってまとめられる場合を想像してみてください。
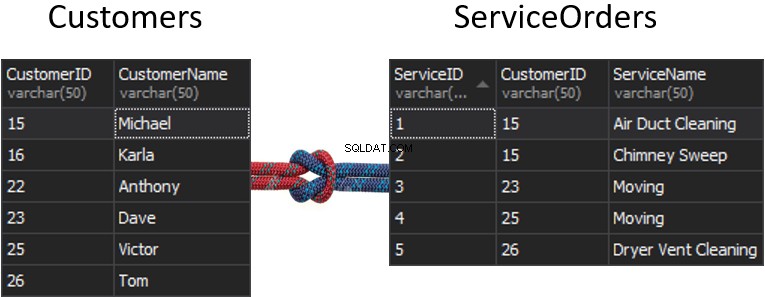
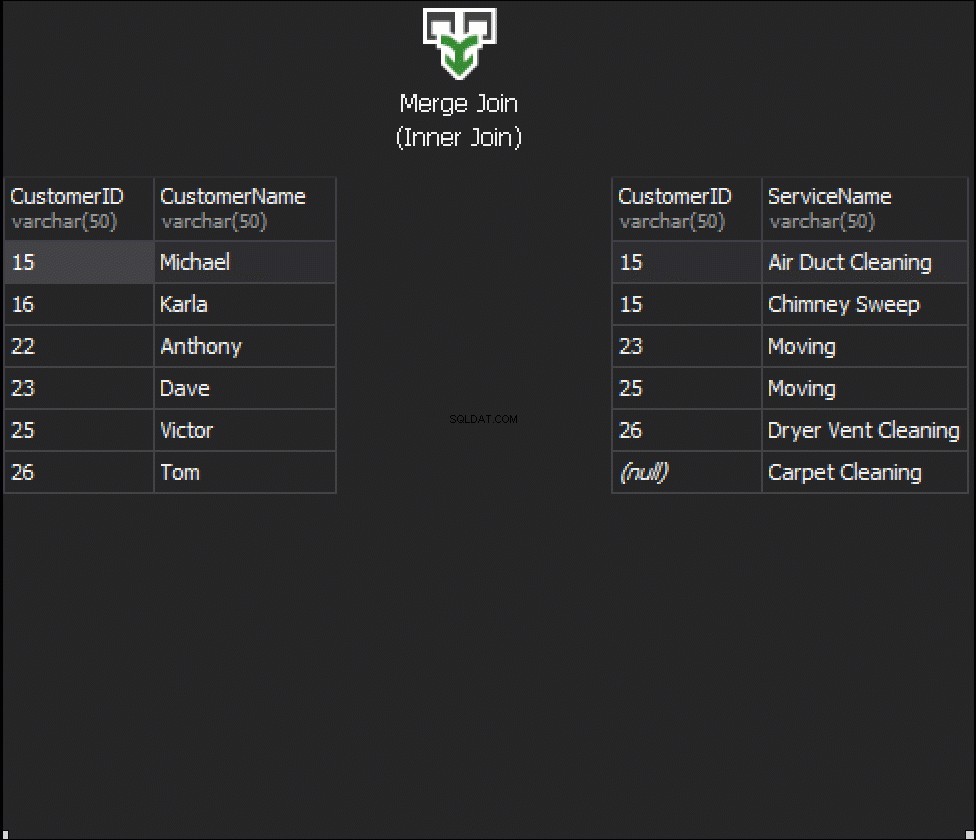
マッチングに使用される各テーブルから1つの列を取得し、それによって返される行と返されない行が決定される場合、シームはどうなりますか?たとえば、左側に顧客、右側にServiceOrdersがあります。すべての顧客とその注文を取得する場合は、これら2つのテーブルを結合する必要があります。このためには、継ぎ目として機能する列を1つ選択する必要があります。もちろん、使用する列はCustomerIDです。
ちなみに、CustomerIDは主キーとして知られています 左側のテーブルの場合、Customersテーブル内のすべての行を一意に識別します。
ServiceOrdersテーブルには、外部キーと呼ばれるCustomerID列もあります。 。外部キーは、別のテーブルを指すように設計された単なる列です。この場合、Customersテーブルを指しています。したがって、このようにして、その継ぎ目を提供することにより、すべてのデータをまとめます。
これらの表には、次の一致があります。15の場合は2つの注文、23、25、および26の場合は1つの注文。16と22は省略されています。
ここで注意すべき重要な点の1つは、複数のテーブルを結合できるということです。 。実際、あらゆる形式の情報を取得するために、複数のテーブルを結合することは非常に一般的です。最も一般的なデータベースを見ると、探している情報を取得するためだけに、4つ、5つ、6つ以上のテーブルを結合する必要がある場合があります。データベース図があると便利です。
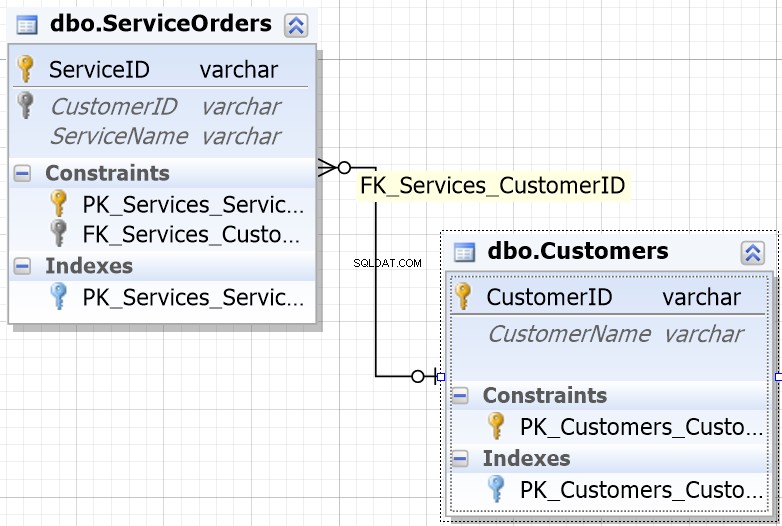
ほとんどのデータベース環境で役立つように、JOINされるように設計された列が同じ名前であることに気付くでしょう。
構文の結合
SQLデータベースクエリ言語の3番目のリビジョン(SQL-92)は、JOIN構文を規制します。
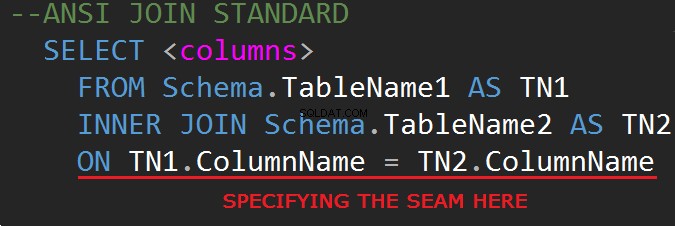
WHERE行でJOINを実行することができます:
リレーションには通常、テーブル形式の単純なグラフィカルな解釈があります。
ベストプラクティスと規則
- エイリアステーブル名。
- 列に2つの部分からなる命名を使用する
- 各JOINを別々の行に配置します
- テーブルを論理的な順序で配置します
参加タイプ
SQL Serverは、次の種類のJOINを提供します。
- 内部参加
- 外部参加
- 自己参加
- クロスジョイン
このトピックの詳細については、SQL Serverの結合の種類に関するこの記事を確認し、SQLCompleteを使用してこのようなクエリを簡単に記述できることを確認してください。
内部結合
実行する可能性のある最初のタイプのJOINは、INNERJOINです。通常、作成者はこのタイプのSQLServerJOINを通常または単純なJOINと呼びます。 INNERプレフィックスを省略しているだけです。このタイプのJOINは、2つのテーブルを結合し、一致する両側の行のみを返します 。
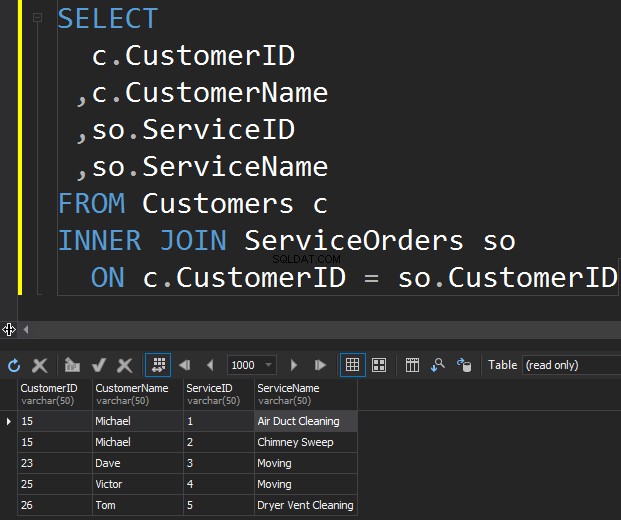
CustomerIDが両方のテーブルで一致しないため、ここではKlaraとAnthonyは表示されません。また、JOIN操作は注文に一致するたびに顧客を返すという事実を強調したいと思います。 。 Michaelには2つの注文があり、Dave、Victor、Tomにはそれぞれ1つの注文があります。
概要:
- INNER JOINは、両方のテーブルにJOIN条件に一致する行が少なくとも1つある場合にのみ、行を返します。
- INNER JOINは、他のテーブルの行と一致しない行を削除します
外部参加
外部JOINは、一致しなくてもテーブルまたはビューから行を返すため、異なります。このタイプのJOINは、注文したことのないすべての顧客を取得する必要がある場合に役立ちます。または、たとえば、注文したことのない製品を探している場合。
外部結合を行う方法は、LEFTまたはRIGHT、またはFULLを示すことです。
次の句に違いはありません:
- LEFT OUTER JOIN =LEFT JOIN
- 右外側の結合=右の結合
- 完全な外部結合=完全な結合
ただし、コードが読みやすくなるため、完全な句を記述することをお勧めします。
LEFTOUTERJOINの使用
余分な行を取得するテーブルを指定するだけであるという事実を除いて、LEFTとRIGHTの間に違いはありません。次の例では、顧客とその注文をリストしました。 LEFTを利用して、注文したことのないすべての顧客を獲得します。 SQL Serverに、左側のテーブルから追加の行を取得するように依頼します。
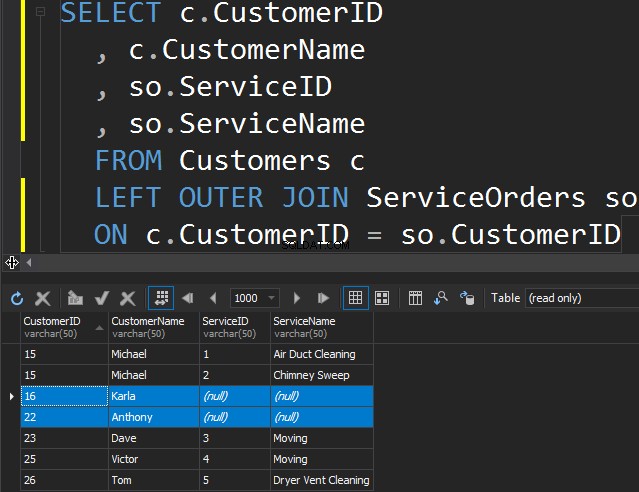
KarlaとAnthonyは注文を行っていないため、ServiceNameとServiceIDの値がNULLになることに注意してください。 SQL Serverはそこに何を配置するかを認識しておらず、NULLを配置します。
右外部結合の使用
ServiceOrdersテーブルからあまり人気のないサービスを取得するには、RIGHT方向を使用する必要があります。
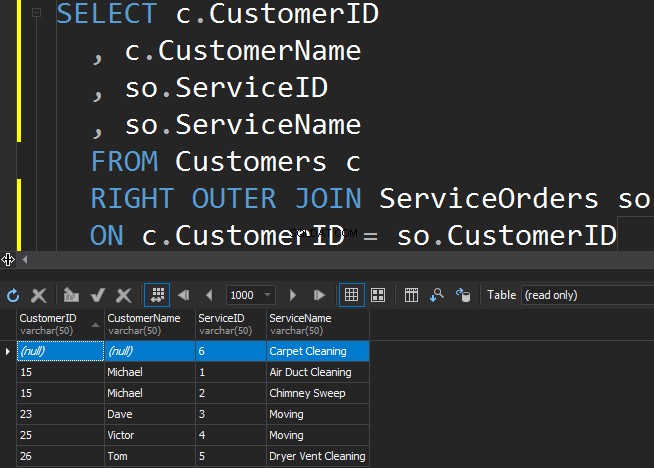
この場合、SQL Serverは右側のテーブルから余分な行を返し、カーペットクリーニングサービスは注文されていません。
完全な外部結合の使用
このタイプのJOINを使用すると、両方のテーブルから一致しない行を含めることで、一致しない情報を取得できます。
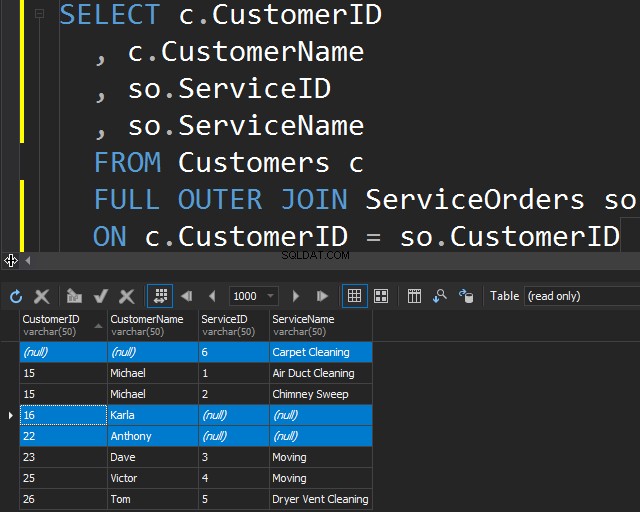
これは、データのクリーンアップを行う必要がある場合にも役立つことがあります。
概要:
フルアウタージョイン
- JOINステートメントと一致しない場合でも、両方のテーブルから行を返します
左または右
- FROM句のテーブルの順序を除いて違いはありません
- 方向は、一致しない行を取得するためのテーブルを指します
自己参加
次のタイプのJOINはSELFJOINです。これはおそらく、これから実行するJOINの中で2番目に一般的でないタイプです。 SELF JOINは、テーブルをそれ自体に結合する場合です。一般的に言って、これは貧弱な設計の兆候です。 1回のクエリで同じテーブルを2回使用するには、テーブルにエイリアスを設定する必要があります。エイリアスは、クエリプロセッサが列にデータを右側から表示するか左側から表示するかを識別するのに役立ちます。さらに、行進する行を削除する必要があります。これは通常、非等価結合で行われます。
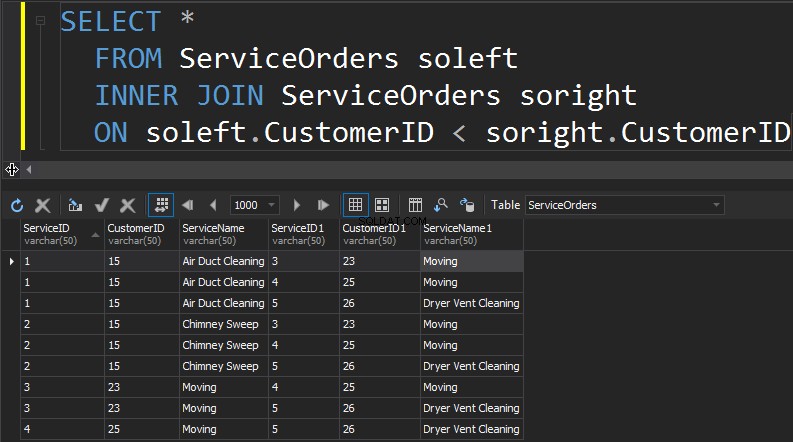
概要:
- テーブルをそれ自体に結合します
- 一般的に、不十分な設計と正規化の兆候
- テーブルはエイリアス化する必要があります
- 一致する行をフィルタリングする必要があります
クロス結合
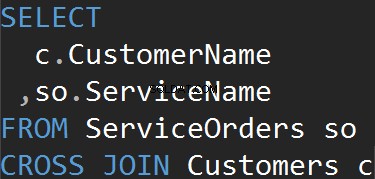
このタイプのJOINにはONがありません 声明。各テーブルのすべての行が一致します。これはデカルト積とも呼ばれます(CROSS JOINにWHERE句がない場合)。このJOINタイプを実際のシナリオで使用することはほとんどありませんが、テストデータを生成するための良い方法です。
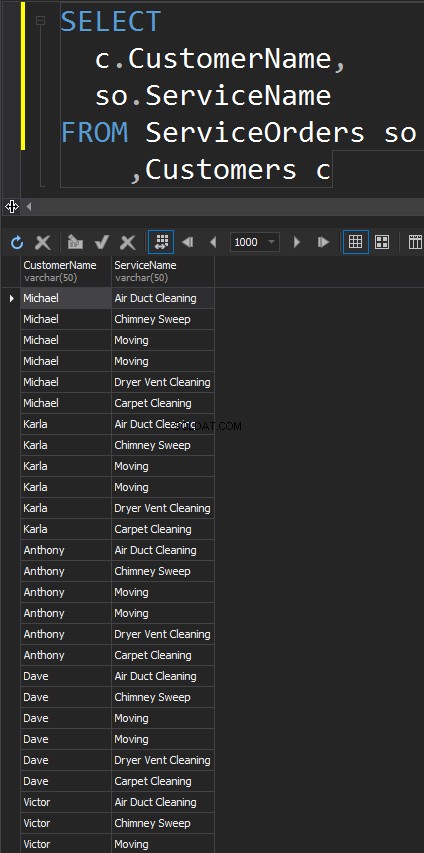
結果はデータセットであり、左側のテーブルの行数に右側のテーブルの行数を掛けたものです。最終的に、すべての顧客がすべてのサービスと一致することがわかります。
CROSSJOIN句を明示的に使用しても同じ結果が得られます。
概要:
- すべての行が各テーブルから一致します
- ONステートメントなし
- テストデータの生成に使用できます
アルゴリズムに参加
記事の最初の部分では、論理について説明しました SQLServerがクエリの解析とバインド中に使用するJOIN演算子。それらは:
- 内部参加
- 外部参加
- クロスジョイン
論理演算子は概念的なものであり、物理とは異なります。 参加します。そうでなければ、論理JOINは実際には参加しません 特定のテーブル列。単一の論理JOINは、多くの物理JOINに対応する場合があります。 SQL Serverは、最適化中に論理JOINを物理JOINに置き換えます。 SQL Serverには、次の物理JOIN演算子があります。
- ネストされたループ
- マージ
- ハッシュ
ユーザーは、これらのタイプのJOINSを作成または使用しません。これらはSQLServerエンジンの一部であり、SQLServerはそれらを内部的に使用して論理JOINを実装します。実行プランを調べると、SQLServerが論理JOIN演算子を3つの物理演算子のいずれかに置き換えていることに気付くかもしれません。
ネストされたループ結合
最も単純な演算子であるネストされたループから始めましょう。アルゴリズムは、1つのテーブル(外部テーブル)のすべての行を他のテーブル(内部テーブル)の各行と比較して、JOIN述語を満たす行を探します。
次の擬似コードは、内部のネストされた結合ループアルゴリズムを示しています。

次の擬似コードは、外側のネストされた結合ループアルゴリズムを説明しています。
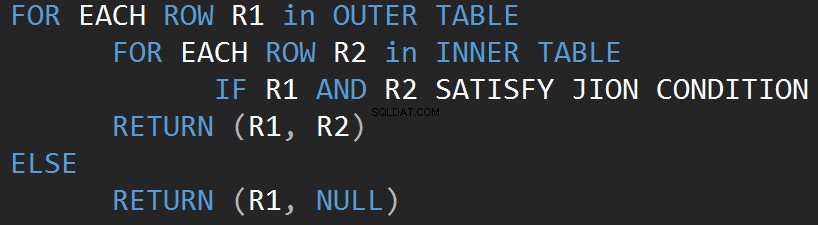
入力のサイズは、アルゴリズムのコストに直接影響します。入力が増えると、コストも増えます。このタイプのJOINアルゴリズムは、入力が少ない場合に効率的です。 SQL Serverは、両方の入力のすべての行のJOIN述語を推定します。
例として、顧客とその注文を取得する次のクエリについて考えてみます。
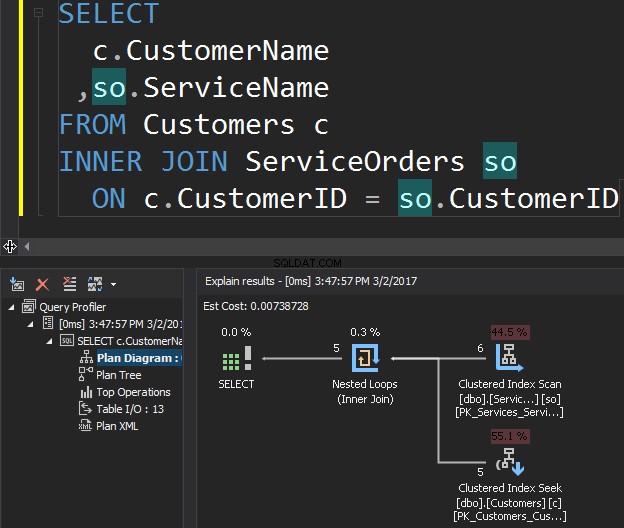
ClusteredIndexScan演算子は外部入力です ClusteredIndexSeekは内部入力です 。ネストされたループ演算子は、実際に一致するものを見つけます。オペレーターは、外部入力で各レコードを検索し、内部入力で一致する行を見つけます。 SQL Serverは、クラスター化インデックススキャン操作(外部入力)を1回だけ実行して、関連するすべてのレコードを取得します。 Clustered Index Seekは、外部入力からのレコードごとに実行されます。これを確認するには、カーソルをオペレーターアイコンに移動し、ツールチップを調べます。
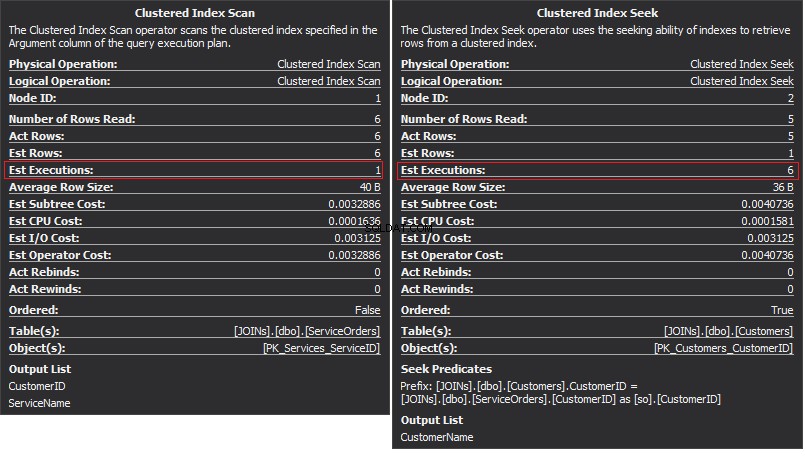
複雑さについて話しましょう。 Nと仮定します は外部出力の行番号です。 M SalesOrdersの合計行数です テーブル。したがって、クエリの複雑さは O(NLogM)です。 ここで、 LogM 内部入力の各シークの複雑さです。オプティマイザーは、外側の入力が小さく、内側の入力にシームとして機能するインデックスが列に含まれている場合は常に、この演算子を選択します。したがって、このJOINタイプにはインデックスと統計が不可欠です。そうしないと、SQLServerは入力の1つにそれほど多くの行がないと誤って判断する可能性があります。インデックスシークを100K回実行するよりも、1回のテーブルスキャンを実行する方が適切です。特に内部入力サイズが100Kを超える場合。
概要:
ネストされたループ
- 複雑さ:O(NlogM)
- 通常、1つのテーブルが小さい場合に適用されます
- 大きい方のテーブルには、結合キーを使用してテーブルを検索できるインデックスが含まれています
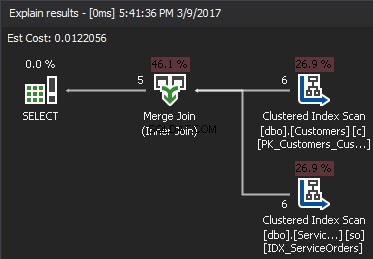
マージ参加
一部の開発者は、Hash and Merge JOINを完全には理解しておらず、パフォーマンスの低いクエリに関連付けることがよくあります。
JOIN述部を受け入れるネストされたループとは対照的に、マージ結合には少なくとも1つの等結合が必要です。さらに、両方の入力をJOINキーで並べ替える必要があります。
MERGE JOINアルゴリズムの擬似コード:
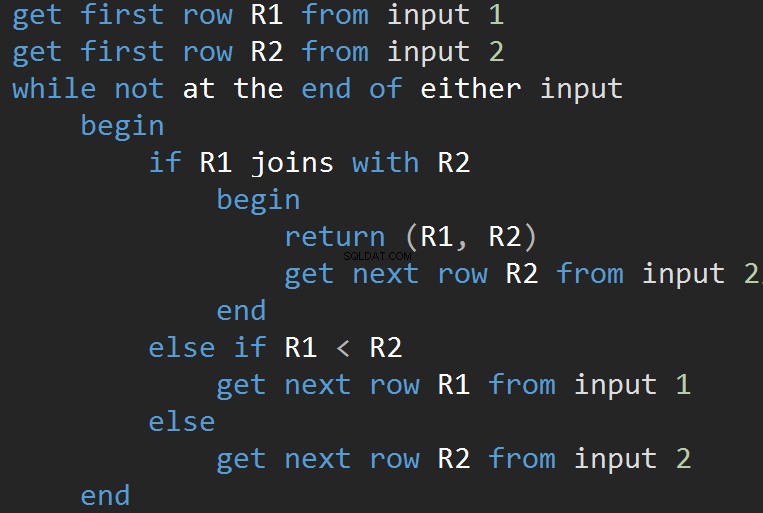
アルゴリズムは、2つのソートされた入力を比較します。一度に1行。 2つの行が等しい場合、アルゴリズムは結合行を出力して続行します。そうでない場合、アルゴリズムは2つの入力のうち小さい方を破棄して続行します。ネストされたループとは異なり、ここでのコストは入力行の数の合計に比例します。複雑さの観点から– O(N + M)。 したがって、このタイプのJOINは、多くの場合、大規模な入力に適しています。
次のアニメーションは、MERGEJOINアルゴリズムが実際にテーブルの行を結合する方法を示しています。
概要
- 複雑さ:O(N + M)
- 両方の入力を結合キーで並べ替える必要があります
- 等式演算子が使用されます
- 大きなテーブルに最適
ハッシュ結合
ハッシュ結合は、使用可能なインデックスのない大きなテーブルに適しています。最初のステップ–ビルドフェーズ アルゴリズムは、左側の入力にメモリ内ハッシュインデックスを作成します。 2番目のステップはプローブフェーズと呼ばれます 。アルゴリズムは右側の入力を通過し、ビルドフェーズ中に作成されたインデックスを使用して一致を検索します。正直なところ、オプティマイザーがこのタイプのJOINアルゴリズムを選択する場合、それは良い兆候ではありません。
このタイプのJOINの基礎となる2つの重要な概念があります。ハッシュ関数とハッシュテーブルです。
ハッシュ関数 可変サイズのデータを固定サイズのデータにマップするために使用できる関数です。
ハッシュテーブル は、連想配列を実装するために使用されるデータ構造であり、キーを値にマップできる構造です。ハッシュテーブルはハッシュ関数を使用して、バケットまたはスロットの配列へのインデックスを計算し、そこから目的の値を見つけることができます。
利用可能な統計に基づいて、SQL Serverはビルド入力として最小の入力を選択し、それを使用してメモリ内にハッシュテーブルをビルドします。十分なメモリがない場合、SQLServerはTempDBの物理ディスク領域を使用します。ハッシュテーブルが作成されると、SQL Serverはプローブ入力(大きい方のテーブル)からデータを取得し、ハッシュ一致関数を使用してそれをハッシュテーブルと比較します。その結果、一致した行が返されます。
実行プランを見ると、右上の要素はビルド入力です。 、右下の要素はプローブ入力 。両方の入力が非常に大きい場合、コストが高すぎます。
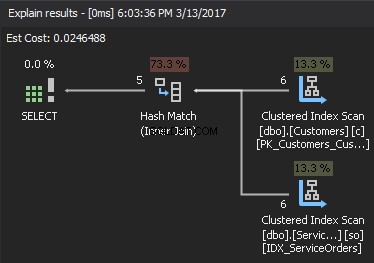
複雑さを見積もるには、次のことを想定します。
h c –ハッシュテーブル作成の複雑さ
h m –ハッシュ一致関数の複雑さ
N –小さいテーブル
M –より大きなテーブル
J – ハッシュ関数の動的計算と作成のための複雑さの追加
複雑さは次のようになります: O(N * h c + M * h m + J)
オプティマイザは、統計を使用して値のカーディナリティを決定します。次に、データを同じサイズの多数のバケットに分割するハッシュ関数を動的に作成します。動的な性質のため、ハッシュテーブル作成プロセスの複雑さ、および各ハッシュ一致の複雑さを見積もることはしばしば困難です。オプティマイザは実行時間中にこれらすべての動的操作を実行するため、実行プランに誤った見積もりが表示されることもあります。場合によっては、実行プランでネストされたループがハッシュ結合よりも高価であることが示されることがありますが、実際には、コスト見積もりが正しくないため、ハッシュ結合の実行が遅くなります。
概要
- 複雑さ:O(N * h c + M * h m + J)
- 最後のリゾートの参加タイプ
- ハッシュテーブルと動的ハッシュ一致関数を使用して行を一致させます
便利な製品:
SQL Complete –コードの記述、美化、リファクタリングを簡単に行い、生産性を向上させます。