私がDjangoを初めて使用したとき、私が経験した最も苛立たしいことの1つは、定期的に少しのコードを実行する必要があることでした。毎日午前12時に実行する必要のあるアクションを実行する素晴らしい関数を作成しました。簡単ですよね?間違い。当時、私は「Cpanelタイプ」のWebホスティングに慣れていたので、これは大きな問題であることがわかりました。この目的のためにcronジョブを設定するための便利なGUIがありました。
多くの調査の結果、私は優れたソリューションを見つけました。Celeryは、バックグラウンドでタスクを実行するために使用される強力な非同期ジョブキューです。しかし、CeleryをDjangoプロジェクトに統合するための簡単な手順が見つからなかったため、これにより追加の問題が発生しました。
もちろん、私は最終的にそれを理解することができました。これについては、この記事で説明します。 CeleryをDjangoプロジェクトに統合し、定期的なタスクを作成する方法。
無料ボーナス: ここをクリックして、無料のDjangoラーニングリソースガイド(PDF)にアクセスします。このガイドには、Python +DjangoWebアプリケーションを構築する際に避けるべきヒントとコツおよび一般的な落とし穴が示されています。
このプロジェクトでは、Python 3.4、Django 1.8.2、Celery 3.1.18、およびRedis3.0.2を利用しています。
概要
便宜上、これは非常に大きな投稿なので、各ステップの簡単な情報と関連するコードを取得するには、この表に戻って参照してください。
| ステップ | 概要 | Gitタグ |
|---|---|---|
| ボイラープレート | ボイラープレートをダウンロード | v1 |
| セットアップ | CeleryとDjangoの統合 | v2 |
| セロリタスク | 基本的なCeleryタスクを追加 | v3 |
| 定期的なタスク | 定期的なタスクを追加 | v4 |
| ローカルで実行 | アプリをローカルで実行する | v5 |
| リモートで実行 | アプリをリモートで実行する | v6 |
セロリとは?
「Celeryは、分散メッセージパッシングに基づく非同期タスクキュー/ジョブキューです。リアルタイム操作に重点を置いていますが、スケジューリングもサポートしています。」この投稿では、定期的にジョブ/タスクを実行するためのスケジューリング機能に焦点を当てます。
なぜこれが役立つのですか?
- 将来、特定のタスクを実行しなければならなかったすべての時間を考えてみてください。おそらく、1時間ごとにAPIにアクセスする必要がありました。または、1日の終わりに大量のメールを送信する必要があるかもしれません。大小を問わず、Celeryを使用すると、このような定期的なタスクのスケジュールを簡単に設定できます。
- エンドユーザーがページの読み込みやアクションの完了を不必要に待つ必要がないようにする必要があります。長いプロセスがアプリケーションのワークフローの一部である場合、リソースが利用可能になったときに、Celeryを使用してそのプロセスをバックグラウンドで実行し、アプリケーションがクライアントの要求に引き続き応答できるようにすることができます。これにより、タスクがアプリケーションのコンテキストから外れます。
セットアップ
セロリに飛び込む前に、Githubリポジトリからスタータープロジェクトを入手してください。必ずvirtualenvをアクティブ化し、要件をインストールして、移行を実行してください。次に、サーバーを起動し、ブラウザーでhttp:// localhost:8000/に移動します。おなじみの「Djangoを利用した最初のページでおめでとうございます」というテキストが表示されます。完了したら、サーバーを強制終了します。
次に、pipを使用してCeleryをインストールしましょう:
$ pip install celery==3.1.18
$ pip freeze > requirements.txt
これで、わずか3つの簡単なステップでCeleryをDjangoプロジェクトに統合できます。
ステップ1: celery.pyを追加します
「picha」ディレクトリ内に、 celery.pyという名前の新しいファイルを作成します。 :
from __future__ import absolute_import
import os
from celery import Celery
from django.conf import settings
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'picha.settings')
app = Celery('picha')
# Using a string here means the worker will not have to
# pickle the object when using Windows.
app.config_from_object('django.conf:settings')
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))
コード内のコメントに注意してください。
ステップ2:新しいCeleryアプリをインポートする
Djangoの起動時にCeleryアプリが確実に読み込まれるようにするには、次のコードを __init__。pyに追加します。 settings.pyの横にあるファイル ファイル:
from __future__ import absolute_import
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
これで、プロジェクトのレイアウトは次のようになります。
├── manage.py
├── picha
│ ├── __init__.py
│ ├── celery.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└── requirements.txt
ステップ3:RedisをCeleryの「ブローカー」としてインストールする
Celeryは「ブローカー」を使用して、DjangoプロジェクトとCeleryワーカーの間でメッセージを渡します。このチュートリアルでは、メッセージブローカーとしてRedisを使用します。
まず、公式ダウンロードページまたはbrew経由でRedisをインストールします(brew install redis )次に、ターミナルに移動し、新しいターミナルウィンドウで、サーバーを起動します。
$ redis-server
端末に次のように入力することで、Redisが正しく機能していることをテストできます:
$ redis-cli ping
RedisはPONGで返信する必要があります -試してみてください!
Redisが起動したら、settings.pyファイルに次のコードを追加します。
# CELERY STUFF
BROKER_URL = 'redis://localhost:6379'
CELERY_RESULT_BACKEND = 'redis://localhost:6379'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TIMEZONE = 'Africa/Nairobi'
また、Djangoプロジェクトの依存関係としてRedisを追加する必要があります:
$ pip install redis==2.10.3
$ pip freeze > requirements.txt
それでおしまい!これで、DjangoでCeleryを使用できるようになります。 DjangoでCeleryを設定する方法の詳細については、Celeryの公式ドキュメントをご覧ください。
先に進む前に、いくつかの健全性チェックを実行して、すべてが正常であることを確認しましょう…
Celeryワーカーがタスクを受け取る準備ができていることをテストします:
$ celery -A picha worker -l info
...
[2015-07-07 14:07:07,398: INFO/MainProcess] Connected to redis://localhost:6379//
[2015-07-07 14:07:07,410: INFO/MainProcess] mingle: searching for neighbors
[2015-07-07 14:07:08,419: INFO/MainProcess] mingle: all alone
CTRL-Cでプロセスを強制終了します。次に、Celeryタスクスケジューラがアクションの準備ができていることをテストします。
$ celery -A picha beat -l info
...
[2015-07-07 14:08:23,054: INFO/MainProcess] beat: Starting...
ブーム!
繰り返しますが、完了したらプロセスを強制終了します。
セロリタスク
Celeryはタスクを利用します。これは、Celeryで呼び出される通常のPython関数と考えることができます。
たとえば、この基本的な機能をCeleryタスクに変えましょう:
def add(x, y):
return x + y
まず、デコレータを追加します:
from celery.decorators import task
@task(name="sum_two_numbers")
def add(x, y):
return x + y
次に、次のように、このタスクをCeleryと非同期で実行できます。
add.delay(7, 8)
簡単ですよね?
したがって、これらのタイプのタスクは、バックグラウンドプロセスが完了するのをユーザーに待たせずにWebページをロードする場合に最適です。
例を見てみましょう…
Djangoプロジェクトに戻って、バージョン3を入手します。このバージョンには、ユーザーからのフィードバックを受け入れるアプリが含まれており、適切にはfeedbackと呼ばれます。 :
├── feedback
│ ├── __init__.py
│ ├── admin.py
│ ├── emails.py
│ ├── forms.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
├── picha
│ ├── __init__.py
│ ├── celery.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── requirements.txt
└── templates
├── base.html
└── feedback
├── contact.html
└── email
├── feedback_email_body.txt
└── feedback_email_subject.txt
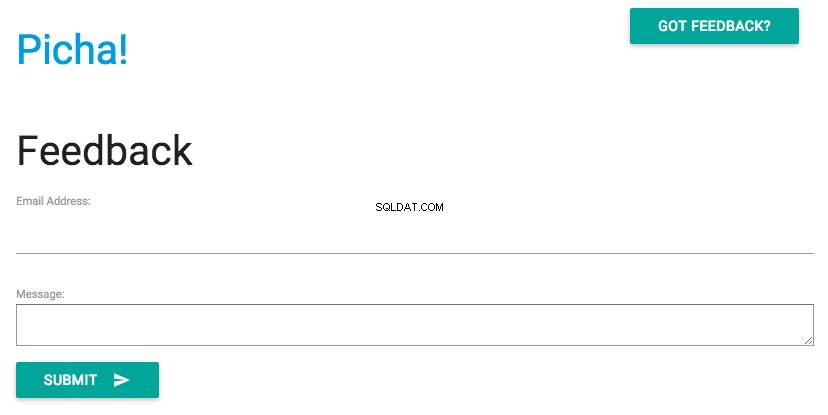
新しい要件をインストールし、アプリを起動して、http:// localhost:8000 /Feedback/に移動します。表示されるはずです:
Celeryタスクを接続しましょう。
タスクを追加
基本的に、ユーザーがフィードバックフォームを送信した後、フィードバックの処理やメールの送信などをすべてバックグラウンドで実行している間、すぐにユーザーに楽しい道を進んでもらいたいと考えています。
これを行うには、最初に tasks.pyというファイルを追加します 「フィードバック」ディレクトリへ:
from celery.decorators import task
from celery.utils.log import get_task_logger
from feedback.emails import send_feedback_email
logger = get_task_logger(__name__)
@task(name="send_feedback_email_task")
def send_feedback_email_task(email, message):
"""sends an email when feedback form is filled successfully"""
logger.info("Sent feedback email")
return send_feedback_email(email, message)
次に、 forms.pyを更新します そのように:
from django import forms
from feedback.tasks import send_feedback_email_task
class FeedbackForm(forms.Form):
email = forms.EmailField(label="Email Address")
message = forms.CharField(
label="Message", widget=forms.Textarea(attrs={'rows': 5}))
honeypot = forms.CharField(widget=forms.HiddenInput(), required=False)
def send_email(self):
# try to trick spammers by checking whether the honeypot field is
# filled in; not super complicated/effective but it works
if self.cleaned_data['honeypot']:
return False
send_feedback_email_task.delay(
self.cleaned_data['email'], self.cleaned_data['message'])
本質的に、send_feedback_email_task.delay(email, message) 関数は、ユーザーがサイトを使い続けると、バックグラウンドでフィードバックメールを処理して送信します。
注 :
success_urlviews.pyで ユーザーを/にリダイレクトするように設定されています 、まだ存在していません。このエンドポイントは次のセクションで設定します。
定期的なタスク
多くの場合、タスクを特定の時間に頻繁に実行するようにスケジュールする必要があります。たとえば、ウェブスクレイパーを毎日実行する必要がある場合があります。定期的なタスクと呼ばれるこのようなタスクは、Celeryで簡単に設定できます。
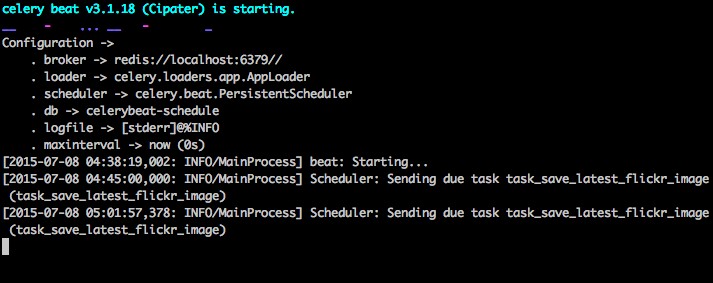
セロリは「セロリビート」を使用して定期的なタスクをスケジュールします。セロリビートは定期的にタスクを実行し、その後セロリワーカーによって実行されます。
たとえば、次のタスクは15分ごとに実行されるようにスケジュールされています。
from celery.task.schedules import crontab
from celery.decorators import periodic_task
@periodic_task(run_every=(crontab(minute='*/15')), name="some_task", ignore_result=True)
def some_task():
# do something
この機能をDjangoプロジェクトに追加して、より堅牢な例を見てみましょう…
Djangoプロジェクトに戻り、バージョン4を入手します。このバージョンには、photosと呼ばれる別の新しいアプリが含まれています。 、Flickr APIを使用して、サイトに表示する新しい写真を取得します:
├── feedback
│ ├── __init__.py
│ ├── admin.py
│ ├── emails.py
│ ├── forms.py
│ ├── models.py
│ ├── tasks.py
│ ├── tests.py
│ └── views.py
├── manage.py
├── photos
│ ├── __init__.py
│ ├── admin.py
│ ├── models.py
│ ├── settings.py
│ ├── tests.py
│ ├── utils.py
│ └── views.py
├── picha
│ ├── __init__.py
│ ├── celery.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── requirements.txt
└── templates
├── base.html
├── feedback
│ ├── contact.html
│ └── email
│ ├── feedback_email_body.txt
│ └── feedback_email_subject.txt
└── photos
└── photo_list.html
新しい要件をインストールし、移行を実行してから、サーバーを起動して、すべてが正常であることを確認します。フィードバックフォームをもう一度テストしてみてください。今回は問題なくリダイレクトされるはずです。
次は?
サイトに写真を追加するには、定期的にFlickr APIを呼び出す必要があるため、Celeryタスクを追加できます。
タスクを追加
tasks.pyを追加します photosへ アプリ:
from celery.task.schedules import crontab
from celery.decorators import periodic_task
from celery.utils.log import get_task_logger
from photos.utils import save_latest_flickr_image
logger = get_task_logger(__name__)
@periodic_task(
run_every=(crontab(minute='*/15')),
name="task_save_latest_flickr_image",
ignore_result=True
)
def task_save_latest_flickr_image():
"""
Saves latest image from Flickr
"""
save_latest_flickr_image()
logger.info("Saved image from Flickr")
ここでは、save_latest_flickr_image()を実行します 関数呼び出しをtaskでラップすることにより、15分ごとに関数を実行します 。 @periodic_task デコレータは、Celeryタスクを実行するためのコードを抽象化し、 tasks.pyを残します。 ファイルがきれいで読みやすい!
ローカルで実行
これを実行する準備はできましたか?
DjangoアプリとRedisを実行した状態で、2つの新しいターミナルウィンドウ/タブを開きます。新しいウィンドウごとに、プロジェクトディレクトリに移動し、virtualenvをアクティブにしてから、次のコマンドを実行します(各ウィンドウに1つずつ)。
$ celery -A picha worker -l info
$ celery -A picha beat -l info
https://127.0.0.1:8000/のサイトにアクセスすると、1つの画像が表示されます。私たちのアプリは、15分ごとにFlickrから1つの画像を取得します:
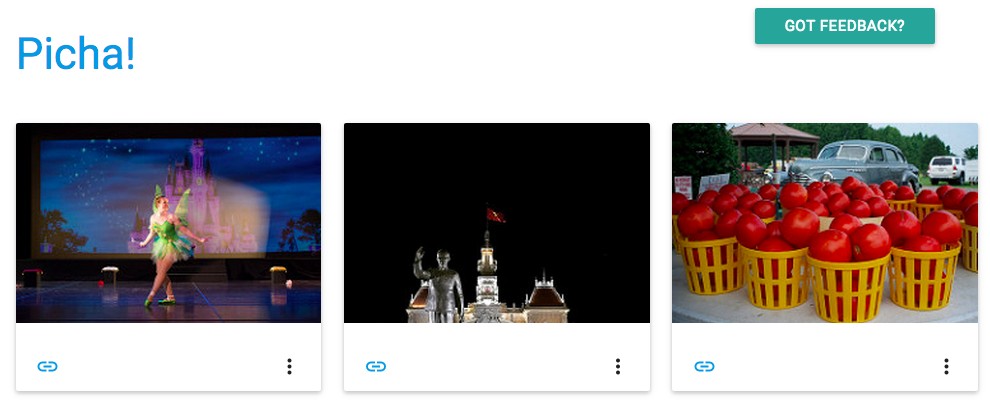
photos/tasks.pyをご覧ください コードを表示します。 「フィードバック」ボタンをクリックすると、…フィードバックを送信できます:
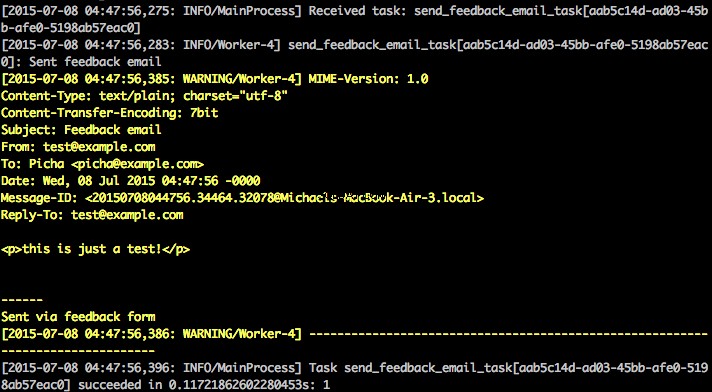
これはセロリタスクを介して機能します。 feedback/tasks.pyをご覧ください 詳細については。
これで、Pichaプロジェクトが稼働しました!
これは、Djangoプロジェクトをローカルで開発する際のテストには適していますが、おそらくDigitalOceanのように、本番環境にデプロイする必要がある場合はあまりうまく機能しません。そのためには、CeleryワーカーとスケジューラーをSupervisorを使用するデーモンとしてバックグラウンドで実行することをお勧めします。
リモートで実行
インストールは簡単です。リポジトリからバージョン5を入手します(まだ持っていない場合)。次に、リモートサーバーにSSHで接続し、次のコマンドを実行します。
$ sudo apt-get install supervisor
次に、リモートサーバーの「/etc/supervisor/conf.d/」ディレクトリに構成ファイルを追加して、CeleryワーカーについてSupervisorに通知する必要があります。この場合、2つのそのような構成ファイルが必要です。1つはCeleryワーカー用で、もう1つはCeleryスケジューラー用です。
ローカルで、プロジェクトルートに「supervisor」というフォルダを作成します。次に、次のファイルを追加します…
セロリワーカー: picha_celery.conf
; ==================================
; celery worker supervisor example
; ==================================
; the name of your supervisord program
[program:pichacelery]
; Set full path to celery program if using virtualenv
command=/home/mosh/.virtualenvs/picha/bin/celery worker -A picha --loglevel=INFO
; The directory to your Django project
directory=/home/mosh/sites/picha
; If supervisord is run as the root user, switch users to this UNIX user account
; before doing any processing.
user=mosh
; Supervisor will start as many instances of this program as named by numprocs
numprocs=1
; Put process stdout output in this file
stdout_logfile=/var/log/celery/picha_worker.log
; Put process stderr output in this file
stderr_logfile=/var/log/celery/picha_worker.log
; If true, this program will start automatically when supervisord is started
autostart=true
; May be one of false, unexpected, or true. If false, the process will never
; be autorestarted. If unexpected, the process will be restart when the program
; exits with an exit code that is not one of the exit codes associated with this
; process’ configuration (see exitcodes). If true, the process will be
; unconditionally restarted when it exits, without regard to its exit code.
autorestart=true
; The total number of seconds which the program needs to stay running after
; a startup to consider the start successful.
startsecs=10
; Need to wait for currently executing tasks to finish at shutdown.
; Increase this if you have very long running tasks.
stopwaitsecs = 600
; When resorting to send SIGKILL to the program to terminate it
; send SIGKILL to its whole process group instead,
; taking care of its children as well.
killasgroup=true
; if your broker is supervised, set its priority higher
; so it starts first
priority=998
セロリスケジューラ: picha_celerybeat.conf
; ================================
; celery beat supervisor example
; ================================
; the name of your supervisord program
[program:pichacelerybeat]
; Set full path to celery program if using virtualenv
command=/home/mosh/.virtualenvs/picha/bin/celerybeat -A picha --loglevel=INFO
; The directory to your Django project
directory=/home/mosh/sites/picha
; If supervisord is run as the root user, switch users to this UNIX user account
; before doing any processing.
user=mosh
; Supervisor will start as many instances of this program as named by numprocs
numprocs=1
; Put process stdout output in this file
stdout_logfile=/var/log/celery/picha_beat.log
; Put process stderr output in this file
stderr_logfile=/var/log/celery/picha_beat.log
; If true, this program will start automatically when supervisord is started
autostart=true
; May be one of false, unexpected, or true. If false, the process will never
; be autorestarted. If unexpected, the process will be restart when the program
; exits with an exit code that is not one of the exit codes associated with this
; process’ configuration (see exitcodes). If true, the process will be
; unconditionally restarted when it exits, without regard to its exit code.
autorestart=true
; The total number of seconds which the program needs to stay running after
; a startup to consider the start successful.
startsecs=10
; if your broker is supervised, set its priority higher
; so it starts first
priority=999
これらのファイルのパスを、リモートサーバーのファイルシステムと一致するように更新してください。
基本的に、これらのスーパーバイザー構成ファイルは、「プログラム」を実行および管理する方法をスーパーバイザーに指示します(スーパーバイザーによって呼び出されます)。
上記の例では、「pichacelery」と「pichacelerybeat」という名前の2つの監視対象プログラムを作成しました。
次に、これらのファイルを「/etc/supervisor/conf.d/」ディレクトリのリモートサーバーにコピーします。
また、リモートサーバーで上記のスクリプトに記載されているログファイルを作成する必要があります。
$ touch /var/log/celery/picha_worker.log
$ touch /var/log/celery/picha_beat.log
最後に、次のコマンドを実行して、スーパーバイザーにプログラムを認識させます(例:pichacelery) およびpichacelerybeat :
$ sudo supervisorctl reread
$ sudo supervisorctl update
次のコマンドを実行して、pichaceleryのステータスを停止、開始、または確認します。 プログラム:
$ sudo supervisorctl stop pichacelery
$ sudo supervisorctl start pichacelery
$ sudo supervisorctl status pichacelery
スーパーバイザーの詳細については、公式ドキュメントをご覧ください。
最後のヒント
- DjangoモデルオブジェクトをCeleryタスクに渡さないでください。 モデルオブジェクトがCeleryタスクに渡される前にすでに変更されている場合を回避するには、オブジェクトの主キーをCeleryに渡します。もちろん、作業する前に、データベースからオブジェクトを取得するために主キーを使用する必要があります。
- デフォルトのCeleryスケジューラーは、スケジュールをローカルに保存するためにいくつかのファイルを作成します。 これらのファイルは「celerybeat-schedule.db」と「celerybeat.pid」になります。 Gitのようなバージョン管理システムを使用している場合(そうすべきです!)、このファイルはローカルでプロセスを実行するためのものであるため、このファイルを無視してリポジトリに追加しないことをお勧めします。
次のステップ
これで、CeleryをDjangoプロジェクトに統合するための基本的な紹介は終わりです。
もっと知りたいですか?
- 詳細については、Celeryの公式ユーザーガイドをご覧ください。
- Fabfileを作成して、Supervisorと構成ファイルをセットアップします。必ず
rereadにコマンドを追加してください およびupdateスーパーバイザー。 - リポジトリからプロジェクトをフォークし、プルリクエストを開いて新しいCeleryタスクを追加します。
無料ボーナス: ここをクリックして、無料のDjangoラーニングリソースガイド(PDF)にアクセスします。このガイドには、Python +DjangoWebアプリケーションを構築する際に避けるべきヒントとコツおよび一般的な落とし穴が示されています。
ハッピーコーディング!