どのような問題を検討しますか?
サーバーが「Eドライブにスペースがありません」と通知した場合、詳細な分析は必要ありません。エラーは考慮されません。エラーの解決策はメッセージのテキストから明らかであり、Googleはすぐに解決策とともにMSDNへのリンクをスローします。
たとえば、パフォーマンスの突然の低下や接続の欠如など、Googleには明らかではない問題を調べてみましょう。カスタマイズと分析のための主なツールを検討してください。ログやその他の役立つ情報がどこにあるか見てみましょう。実際、クイックスタートに必要なすべての情報を1つの記事にまとめようとしています。
まず第一に
最も頻繁な質問から始めて、それらを個別に検討します。
明らかな理由もなく、データベースが突然動作し始めたが、何も変更していなかった場合は、まず、統計を更新してインデックスを再構築します。
インターネット上には、このような方法がたくさんあり、スクリプトの例が提供されています。これらの方法はすべて専門家向けであると思います。さて、私は最も簡単な方法を説明します:それを実装するために必要なのはマウスだけです。
略語
- SSMSは、Microsoft SQL ServerManagementStudioのアプリケーションです。 2016バージョン以降、スタンドアロンアプリケーションとしてMSWebサイトから無料で入手できます。 docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profilerは、SSMSとともにインストールされる「SQLServerProfiler」のアプリケーションです。
- パフォーマンスモニターは、コントロールパネルのスナップインであり、パフォーマンスカウンターを監視し、測定の履歴をログに記録して表示できます。
「サービスプラン」を使用した統計の更新:
- SSMSを実行します;
- 必要なサーバーに接続します;
- Object Inspectorでツリーを展開します:Management \ Maintenance Plans(Service Plans);
- ノードを右クリックして、[メンテナンスプランウィザード]を選択します。
- ウィザードで、必要なタスクをマークします:インデックスの再構築と統計の更新
- 両方のタスクに一度にマークを付けることも、それぞれに1つのタスクを含む2つのメンテナンスプランを作成することもできます(以下の「重要な注意事項」を参照)。
- さらに、必要なDB(またはいくつかのデータベース)をチェックします。これはタスクごとに行います(2つのタスクが選択された場合、データベースを選択するための2つのダイアログが表示されます)。
- 次へ、次へ、終了。
これらのアクションの後、「メンテナンスプラン」が作成されます(実行されません)。右クリックして「実行」を選択すると、手動で実行できます。または、SQLエージェントを介して起動を構成します。
重要な注意事項:
- 統計の更新は非ブロッキング操作です。作業モードで実行できます。
- インデックスの再構築はブロック操作です。営業時間外にのみ実行できます。例外があります—サーバーのEnterprise Editionでは、「オンライン再構築」の実行が許可されています。このオプションは、タスク設定で有効にできます。すべてのエディションにチェックマークが付いていますが、Enterpriseでのみ機能することに注意してください。
- もちろん、これらのタスクは定期的に実行する必要があります。これを行う頻度を判断する簡単な方法をお勧めします:
–最初の問題で、メンテナンス計画を実行します。
–問題が解決した場合は、問題が再び発生するまで待ちます(通常、バルクトランザクションの次の月次決算/給与計算などまで)。
–通常の操作の結果の期間は、参照ポイントになります。
–たとえば、メンテナンスプランの実行を2倍の頻度で構成します。
サーバーが遅い–どうすればよいですか?
サーバーが使用するリソース
他のプログラムと同様に、サーバーにはプロセッサ時間、ディスク上のデータ、RAMの量、およびネットワーク帯域幅が必要です。
タスクマネージャーは、どんなにひどく聞こえても、最初の概算で特定のリソースの不足を評価するのに役立ちます。
CPU ロード
男子生徒でもマネージャーで使用率を確認できます。プロセッサがロードされている場合は、それがsqlserver.exeプロセスであることを確認する必要があります。
これが当てはまる場合は、ユーザーアクティビティの分析に進んで、負荷の正確な原因を理解する必要があります(以下を参照)。
ディスク ロア d
多くの人はCPUの負荷だけを見て、DBMSがデータストアであることを忘れています。データ量は増加し、プロセッサのパフォーマンスは向上していますが、HDDの速度はほぼ同じです。 SSDを使用すると状況は良くなりますが、テラバイトをSSDに保存するにはコストがかかります。
CPUではなくディスクシステムがボトルネックになることがよくあります。
ディスクの場合、次のメトリックが重要です。
- 平均キュー長(未処理のI / O操作、数);
- 読み取り/書き込み速度(Mb /秒)。
タスクマネージャのサーバーバージョンは、原則として(システムバージョンによって異なります)、両方を表示します。そうでない場合は、パフォーマンスモニタースナップイン(システムモニター)を実行します。次のカウンターに関心があります:
- 物理(論理)ディスク/平均読み取り(書き込み)時間
- 物理(論理)ディスク/平均ディスクキュー長
- 物理(論理)ディスク/ディスク速度
詳細については、製造元のマニュアルを読むことができます。たとえば、social.technet.microsoft.com / wiki / contents / articles/3214.monitoring-disk-usage.aspx。
要するに:
- キューは1を超えてはなりません。すぐに治まる場合は、短いバーストが許可されます。バーストは、システムによって異なる場合があります。 2台のHDDの単純なRAIDミラーの場合、10〜20を超えるキューが問題になります。スーパーキャッシングを備えたクールなライブラリの場合、最大600〜800のバーストが発生し、遅延を発生させることなく即座に解決されました。
- 通常の為替レートは、ディスクシステムの種類によっても異なります。通常の(デスクトップ)HDDは50〜100MB/秒で送信します。優れたディスクライブラリ–500MB/秒以上。小さなランダム操作の場合、速度は遅くなります。これが基準点になる可能性があります。
- これらのパラメータは全体として考慮する必要があります。ライブラリが50MB/秒を送信し、50の操作のキューが並んでいる場合、明らかに、ハードウェアに問題があります。送信が最大値に近づいたときにキューが並んでいる場合(ほとんどの場合、ディスクのせいではありません)、それ以上のことはできません。負荷を減らす方法を探す必要があります。
- 負荷はディスク上で個別にチェックし(複数ある場合)、サーバーファイルの場所と比較する必要があります。タスクマネージャは、最もアクティブに使用されているファイルを表示できます。これを使用して、負荷がDBMSによって引き起こされていることを確認できます。
ディスクシステムの問題の原因:
- ハードウェアの問題
- キャッシュが切れ、パフォーマンスが大幅に低下しました。
- ディスクシステムは他の人によって使用されています;
- RAM不足。スワッピング。動作が低下し、パフォーマンスが低下しました(以下のRAMに関するセクションを参照してください)。
- ユーザーの負荷が増加しました。ユーザーの作業を評価する必要があります(問題のあるクエリ/新機能/ユーザー数の増加/データ量の増加など)。
- データベースデータの断片化(上記のインデックスの再構築を参照)、システムファイルの断片化。
- ディスクシステムが最大機能に達しました。
最後のオプションの場合–ハードウェアを一度に捨てないでください。問題に賢明に取り組むと、システムからもう少し多くのことを引き出すことができる場合があります。推奨要件に準拠しているかどうか、システムファイルの場所を確認してください。
- OSファイルとデータベースデータファイルを混在させないでください。システムがI/Oに関してDBMSと競合しないように、それらを異なる物理メディアに保存します。
- データベースは、データ(* .mdf、*。ndf)とログ(* .ldf)の2つのファイルタイプで構成されています。
原則として、データファイルは主に読み取りに使用されます。ログは書き込みに使用されます(書き込みは連続しています)。したがって、ログとデータを別の物理メディアに保存して、ログがデータの読み取りを中断しないようにすることをお勧めします(原則として、書き込み操作が読み取りよりも優先されます)。 - MS SQLは、クエリ処理に「一時テーブル」を使用できます。それらはtempdbシステムデータベースに保存されます。このデータベースのファイルの負荷が高い場合は、物理的に別のメディアにレンダリングしてみてください。
ファイルの場所に関する問題を要約し、「分割統治」の原則を使用します。アクセスされているファイルを評価し、それらを別のメディアに配布してみてください。また、RAIDシステムの機能を使用してください。たとえば、RAID-5の読み取りは書き込みよりも高速です。これはデータファイルに適しています。
ユーザーのパフォーマンスに関する情報を取得する方法を見てみましょう。誰が何を作成し、どのくらいのリソースが消費されているか
ユーザーアクティビティの監査のタスクを次のグループに分けました:
- 特定のリクエストを分析するタスク。
- 特定の条件(たとえば、ユーザーがデータベースと互換性のあるサードパーティアプリケーションのボタンをクリックしたとき)でのアプリケーションからの負荷を分析するタスク。
- 現在の状況を分析するタスク。
それぞれについて詳しく考えてみましょう。
警告
パフォーマンス分析には、データベースサーバーとオペレーティングシステムの構造と動作原理を深く理解する必要があります。そのため、これらの記事だけを読んでも専門家にはなりません。
実際のシステムで考慮される基準とカウンターは、互いに大きく依存しています。たとえば、HDDの負荷が高いのは、RAMが不足していることが原因であることがよくあります。いくつかの測定を行ったとしても、問題を合理的に評価するにはこれだけでは不十分です。
記事の目的は、簡単な例の要点を紹介することです。私の推奨事項をガイドとして考えるべきではありません。思考の流れを説明できるトレーニングタスクとして使用することをお勧めします。
サーバーのパフォーマンスに関する結論を数値で合理化する方法を学習していただければ幸いです。
「サーバーの速度が低下する」と言う代わりに、特定のインジケーターの特定の値を提供します。
Pを分析します 関節R equest
最初のポイントは非常に単純です。簡単に説明しましょう。あまり目立たない問題を検討します。
SSMSでは、クエリ結果に加えて、クエリの実行に関する追加情報を取得できます。
- 「推定実行プランの表示」ボタンと「実際の実行プランを含める」ボタンをクリックすると、クエリプランを取得できます。それらの違いは、見積もりプランがクエリを実行せずに作成されることです。したがって、処理された行の数に関する情報が推定されます。実際の計画には、推定データと実際のデータの両方があります。これらの値の大きな不一致は、統計が関連していないことを示しています。ただし、計画の分析は別の記事の主題です。これまでのところ、これ以上詳しくは説明しません。
- サーバーのプロセッサコストとディスク操作の測定値を取得できます。これを行うには、SETオプションを有効にする必要があります。次のような[クエリオプション]ダイアログボックスで実行できます。
または、クエリで直接SETコマンドを使用します:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDその結果、コンパイルと実行に費やされた時間、およびディスク操作の数に関するデータが取得されます。
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.コンパイル時、論理読み取り96、物理読み取り5に注目したいと思います。同じクエリを2回目以降に実行すると、物理読み取りが減少し、再コンパイルが不要になる場合があります。このため、2回目以降は、1回目よりもクエリの実行速度が速くなることがよくあります。ご存知のとおり、その理由は、データとコンパイルされたクエリプランをキャッシュすることです。
- [クライアント統計を含める]ボタンには、ネットワーク交換、実行された操作の量、およびネットワーク交換とクライアントによる処理のコストを含む合計実行時間に関する情報が表示されます。この例は、クエリを初めて実行するのに時間がかかることを示しています。
- SSMS 2016には、[ライブクエリ統計を含める]ボタンがあります。クエリプランの場合と同じように画像が表示されますが、処理された行のランダムでない数字が含まれ、クエリの実行中に画面上で変化します。絵は非常にはっきりしています–点滅する矢印と数字が点滅しているので、時間が無駄になっている場所をすぐに確認できます。このボタンは、SQLServer2014以降でも機能します。
要約すると:
- SET STATISTICSTIMEONを使用してCPUコストを確認します。
- ディスク操作:SET STATISTICSIOON。ロジック読み取りは、ディスクシステムに物理的にアクセスせずにディスクキャッシュで完了する読み取り操作であることを忘れないでください。 「物理的な読み取り」にはさらに時間がかかります。
- «クライアント統計を含める»を使用して、ネットワークトラフィックの量を評価します。
- 「実際の実行プランを含める」と「ライブクエリ統計を含める」を使用して、実行プランによってクエリを実行するアルゴリズムを分析します。
アプリケーションの負荷を分析する
ここでは、SQLServerプロファイラーを使用します。サーバーを起動して接続した後、ログイベントを選択する必要があります。これを行うには、標準のトレーステンプレートを使用してプロファイリングを実行します。 一般について テンプレートを使用のタブ フィールドで、 標準(デフォルト)を選択します 実行をクリックします 。
より複雑な方法は、選択したテンプレートにフィルターまたはイベントを追加/ドロップすることです。これらのオプションは、ダイアログメニューの2番目のタブにあります。選択可能なイベントと列の全範囲を表示するには、すべてのイベントを表示を選択します およびすべての列を表示 チェックボックス。

次のイベントが必要になります:
- ストアドプロシージャ\RPC:完了
- TSQL \ SQL:BatchCompleted
これらのイベントは、サーバーへのすべての外部SQL呼び出しを監視します。クエリ処理の完了後に表示されます。 SQLServerの起動を追跡する同様のイベントがあります。
- ストアドプロシージャ\RPC:開始
- TSQL \ SQL:BatchStarting
ただし、これらのプロシージャには、クエリの実行に費やされたサーバーリソースに関する情報が含まれていないため、これらのプロシージャは必要ありません。そのような情報は、実行プロセスの完了後にのみ利用可能であることは明らかです。したがって、* StartingイベントのCPU、読み取り、書き込みに関するデータを含む列は空になります。
次のイベントも私たちの興味を引く可能性がありますが、現時点では有効にしません。
- ストアドプロシージャ\SP:Starting(* Completed)は、クライアントからではなく、現在のリクエストまたは他のプロシージャ内でのストアドプロシージャへの内部呼び出しを監視します。
- ストアドプロシージャ\SP:StmtStarting(* Completed)は、ストアドプロシージャ内の各ステートメントの開始を追跡します。手順にサイクルがある場合、そのサイクル内のコマンドのイベント数は、そのサイクル内の反復回数と等しくなります。
- TSQL \ SQL:StmtStarting(* Completed)は、SQLバッチ内の各ステートメントの開始を監視します。クエリに複数のコマンドがある場合、それぞれに1つのイベントが含まれます。したがって、クエリ内にあるコマンドに対して機能します。
これらのイベントは、実行プロセスを監視するのに便利です。
Cによる olumns
どの列を選択するかは、ボタン名から明らかです。次のものが必要になります:
- TextData、BinaryDataにはクエリテキストが含まれています。
- CPU、読み取り、書き込み、期間はリソース消費データを表示します。
- StartTime、EndTimeは、実行プロセスを開始および終了する時間です。並べ替えに便利です。
好みに応じて他の列を追加します。
列フィルター… ボタンをクリックすると、イベントフィルターを構成するためのダイアログボックスが開きます。特定のユーザーのアクティビティに関心がある場合は、SID番号またはユーザー名でフィルターを設定できます。残念ながら、接続をプルしてアプリサーバーを介してアプリを接続する場合、特定のユーザーの監視はより複雑になります。
フィルタを使用して、複雑なクエリ(Duration> X)、集中的な書き込みを引き起こすクエリ(Writes> Y)、およびクエリコンテンツの選択などのみを選択できます。
プロファイラーから他に何が必要ですか?もちろん、実行計画!
トレースに«Performance\Showplan XMLStatisticsProfile»イベントを追加する必要があります。クエリを実行すると、次の画像が表示されます。
クエリテキスト:
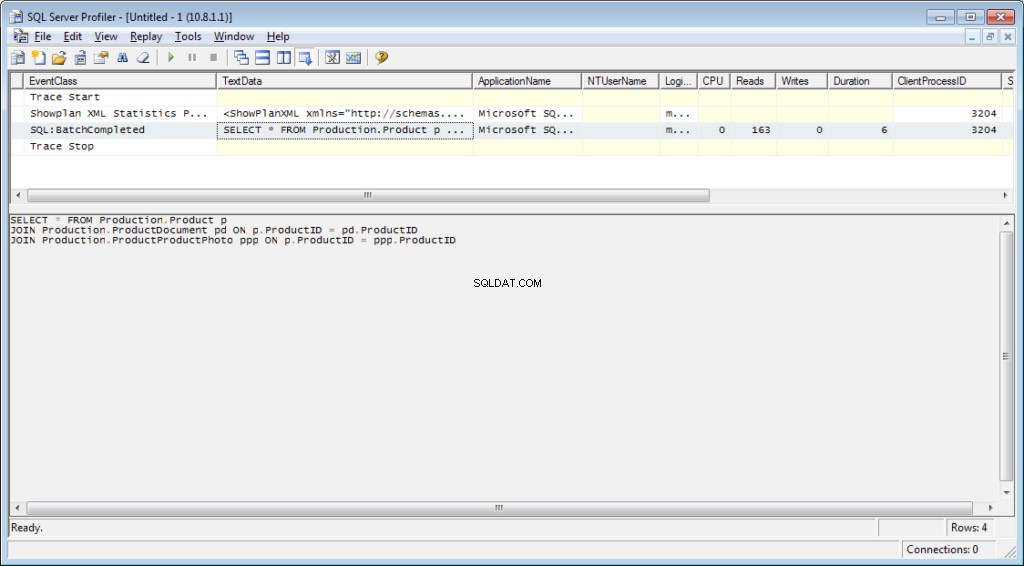
実行計画:
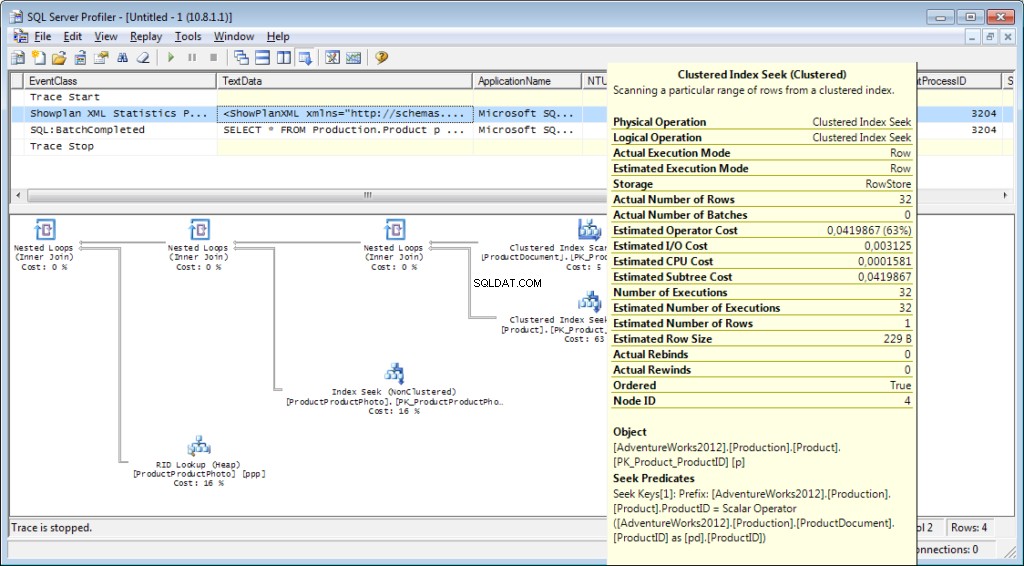
それだけではありません
トレースをファイルまたはデータベーステーブルに保存することができます。トレース設定は、クイック実行用の個人用テンプレートとして保存できます。 T-SQLコードと、sp_trace_create、sp_trace_setevent、sp_trace_setstatus、sp_trace_getdataプロシージャを使用するだけで、プロファイラーなしでトレースを実行できます。ここに例があります。このアプローチは、たとえば、スケジュールに従ってファイルへのトレースの保存を自動的に開始する場合に役立ちます。プロファイラーで卑劣なピークを設定して、これらのコマンドの使用方法を確認できます。 2つのトレースを実行し、そのうちの1つで、2番目のトレースが開始したときに何が起こるかを追跡できます。プロファイラー自体の「ApplicationName」列によるフィルターがないことを確認してください。
プロファイラーによって監視されるイベントのリストは非常に大きく、クエリテキストの受信に限定されません。フルスキャン、再コンパイル、自動拡張、デッドロックなどを追跡するイベントがあります。
サーバーでのユーザーアクティビティの分析
さまざまな状況があります。クエリは「実行」に長時間かかる可能性があり、完了するかどうかは不明です。問題のあるクエリを個別に分析したいと思います。ただし、最初にクエリが何であるかを判断する必要があります。プロファイラーでそれをキャッチすることは無意味です。すでに開始イベントを見逃しており、プロセスが完了するまでどのくらい待つかは明確ではありません。
理解しましょう
「ActivityMonitor」について聞いたことがあるかもしれません。その上位エディションには、非常に豊富な機能があります。それはどのように私たちを助けることができますか? Activity Monitorには、多くの便利で興味深い機能が含まれています。システムビューと関数から必要なものすべてを取得します。モニター自体は、プロファイラーを設定して実行するクエリを確認できるので便利です。
必要なもの:
- dm_exec_sessionsは、接続されたユーザーのセッションに関する情報を提供します。この記事では、有用なフィールドは、ユーザーを識別するフィールド(login_name、login_time、host_name、program_name、…)と、使用済みリソースに関する情報(cpu_time、読み取り、書き込み、memory_usage、…)を含むフィールドです。
- dm_exec_requestsは、現在実行されているクエリに関する情報を提供します。
- session_idは、前のビューにリンクするセッションの識別子です。
- start_timeは、ビューの実行時間です。
- commandは、実行されたコマンドのタイプを含むフィールドです。ユーザークエリの場合は、選択/更新/削除/
- sql_handle、statement_start_offset、statement_end_offsetは、クエリテキストを取得するための情報を提供します:ハンドル、およびクエリのテキストの開始位置と終了位置。これは、現在実行されている部分を意味します(クエリに複数のテキストが含まれている場合)。コマンド)。
- plan_handleは、生成されたプランのハンドルです。
- blocking_session_idは、クエリの実行を妨げるブロックがある場合に、ブロックを引き起こしたセッションの数を示します
- wait_type、wait_time、wait_resourceは、待機の理由と期間に関する情報を含むフィールドです。データロックなど、一部の種類の待機では、ブロックされたリソースのコードを追加で指定する必要があります。
- percent_completeは完了のパーセンテージです。残念ながら、進行状況が明確に予測できるコマンド(バックアップや復元など)でのみ使用できます。
- cpu_time、読み取り、書き込み、logical_reads、granted_query_memoryはリソースコストです。
- dm_exec_sql_text(sql_handle | plan_handle)、sys.dm_exec_query_plan(plan_handle)は、テキストと実行プランを取得する関数です。以下に、その使用例を検討します。
- dm_exec_query_statsは、実行中のクエリの要約統計量です。クエリ、その実行回数、および使用済みリソースの量が表示されます。
重要な注意事項
上記のリストはほんの一部です。すべてのシステムビューと機能の完全なリストは、ドキュメントに記載されています。また、主要なオブジェクト間のリンクの図を示す美しい画像があります。
クエリテキスト、その計画、および実行統計は、プロシージャキャッシュに格納されているデータです。それらは実行中に利用可能です。その場合、可用性は保証されず、キャッシュの負荷に依存します。はい、キャッシュは手動でクリーンアップできます。場合によっては、実行計画が「反転」したときに推奨されます。それでも、ニュアンスはたくさんあります。
「コマンド」フィールドは、全文を取得できるため、ユーザーの要求には意味がありません。ただし、システムプロセスに関する情報を取得するためには非常に重要です。原則として、それらはいくつかの内部タスクを実行し、SQLテキストを持っていません。このようなプロセスの場合、コマンドに関する情報がアクティビティタイプの唯一のヒントになります。
前回の記事へのコメントでは、サーバーが機能しないはずのときにサーバーが何に関与しているかについての質問がありました。答えはおそらくこの分野の意味にあるでしょう。私の実践では、「コマンド」フィールドは常にアクティブなシステムプロセスに非常に理解しやすいものを提供していました:自動縮小/自動拡張/チェックポイント/ログライターなど
使い方
実用的な部分に行きます。その使用例をいくつか紹介します。サーバーの可能性は制限されていません-あなたはあなた自身の例を考えることができます。
例1.どのプロセスがCPU/読み取り/書き込み/メモリを消費するか
まず、CPUなど、より多くのリソースを消費するセッションを見てみましょう。この情報はsys.dm_exec_sessionsにあります。ただし、読み取りと書き込みを含むCPU上のデータは累積的です。これは、接続中のすべての時間の合計が数値に含まれていることを意味します。 1か月前に接続し、切断されていないユーザーの方が高い値になることは明らかです。システムに過負荷がかかるという意味ではありません。
次のアルゴリズムを使用したコードでこの問題を解決できる場合があります。
- 選択して一時テーブルに保存します
- しばらく待ちます
- 2回目の選択
- これらの結果を比較します。それらの違いは、ステップ2で費やされたコストを示します。
- 便宜上、平均「1秒あたりのコスト」を取得するために、差をステップ2の期間で割ることができます。
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 コードでは2つのテーブルを使用しています。最初の選択には#tmp–、2番目の選択には#tmp1 –です。最初の実行中に、スクリプトは1秒間隔で#tmpと#tmp1を作成して入力し、他のタスクを実行します。次の実行では、スクリプトは前の実行の結果を比較のベースとして使用します。したがって、ステップ2の期間は、スクリプトの実行間の待機時間と同じになります。
本番サーバーでも実行してみてください。スクリプトは「一時テーブル」(現在のセッション内で使用可能で、無効にすると削除されます)のみを作成し、スレッドはありません。
MS SSMSでクエリを実行したくない場合は、お気に入りのプログラミング言語で記述されたアプリケーションでクエリをラップできます。 1行のコードなしでMSExcelでこれを行う方法を紹介します。
[データ]メニューで、サーバーに接続します。テーブルを選択するように求められたら、ランダムなテーブルを選択します。 [データのインポート]ダイアログが表示されるまで、[次へ]をクリックして[完了]をクリックします。そのウィンドウで、[プロパティ]をクリックする必要があります。 [プロパティ]で、コマンドタイプをSQL値に置き換え、変更したクエリを[コマンド]テキストフィールドに挿入する必要があります。
クエリを少し変更する必要があります:
- «SETNOCOUNTON»を追加
- 一時テーブルを可変テーブルに置き換えます
- 遅延は1秒以内に続きます。平均値のフィールドは必要ありません
変更されたExcelのクエリ
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id 結果:
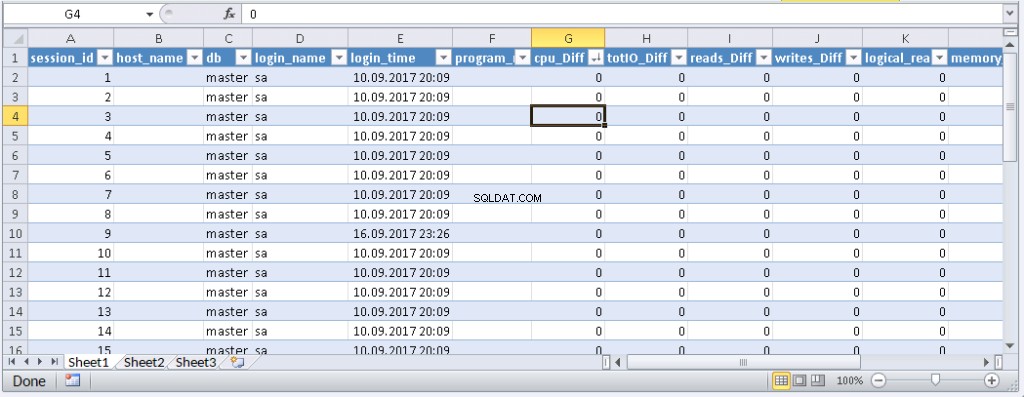
データがExcelに表示されたら、必要に応じて並べ替えることができます。情報を更新するには、[更新]をクリックします。ブックの設定では、指定した期間に「自動更新」と「開始時に更新」を設定できます。ファイルを保存して同僚に渡すことができます。そこで、便利でシンプルなツールを作成しました。
例2.セッションは何にリソースを費やしますか?
次に、問題のあるセッションが実際に何をするかを判断します。これを行うには、sys.dm_exec_requestsと関数を使用してクエリテキストとクエリプランを受信します。
セッション番号によるクエリと実行プラン
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
セッション番号をクエリに挿入して実行します。 After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusion
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.