ウィキペディアによると、「一括挿入は、データベーステーブルに複数行のデータをロードするためにデータベース管理システムによって提供されるプロセスまたはメソッドです。」この説明をBULKINSERTステートメントに従って調整すると、一括挿入により、外部データファイルをSQLServerにインポートできます。組織に1.500.000行のCSVファイルがあり、このファイルをSQL Serverの特定のテーブルにインポートして、SQLServerでBULKINSERTステートメントを簡単に使用できると仮定します。確かに、このCSVファイルのインポートプロセスを処理するためのいくつかのインポート方法を見つけることができます。 bcp( b )を使用できます ulk c opy p rogram)、SQLServerインポートおよびエクスポートウィザードまたはSQLServerIntegrationServiceパッケージ。ただし、BULK INSERTステートメントは、他の方法を使用するよりもはるかに高速で堅牢です。一括挿入ステートメントのもう1つの利点は、一括挿入プロセスの設定を決定するのに役立ついくつかのパラメーターを提供することです。
最初に、非常に基本的なサンプルを開始し、次にさまざまな高度なシナリオを実行します。
準備
サンプルを開始する前に、サンプルのCSVファイルが必要です。そのため、E for ExcelのWebサイトからサンプルCSVファイルをダウンロードします。ここでは、行番号が異なるさまざまなサンプルCSVファイルを見つけることができます。リンクは記事の最後にあります。このシナリオでは、1.500.000の販売レコードを使用します。 zipファイルをダウンロードしてからCSVファイルを解凍し、ローカルドライブに配置します。

CSVファイルをSQLServerテーブルにインポートする
シナリオ-1:宛先ファイルとCSVファイルの列数は同じです
この最初のシナリオでは、CSVファイルを最も単純な形式で宛先テーブルにインポートします。サンプルのCSVファイルをC:ドライブに配置し、CSVファイルからデータをインポートするテーブルを作成します。
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
次のBULKINSERTステートメントは、CSVファイルをSalesテーブルにインポートします。
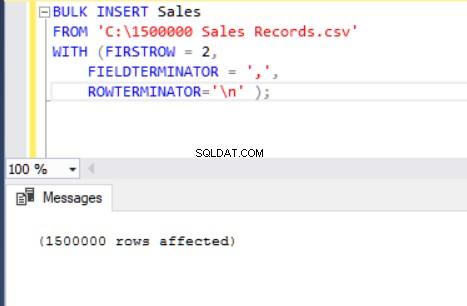
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
次に、上記の一括挿入ステートメントのパラメーターについて説明します。
FIRSTROWパラメーターは、挿入ステートメントの開始点を指定します。次の例では、列ヘッダーをスキップするため、このパラメーターを2に設定します。

FIELDTERMINATORは、フィールドを相互に分離する文字を定義します。 SQL Serverは、このような方法で各フィールドを検出します。 ROWTERMINATORはFIELDTERMINATORと大差ありません。行の分離文字を定義します。サンプルCSVファイルでは、fieldterminatorは非常に明確で、コンマ(、)です。しかし、どうすればフィールドターミネータを検出できますか? Notepad ++でCSVファイルを開き、[表示]->[記号を表示]->[すべてのチャーターを表示]に移動して、各フィールドの最後にあるCRLF文字を見つけます。
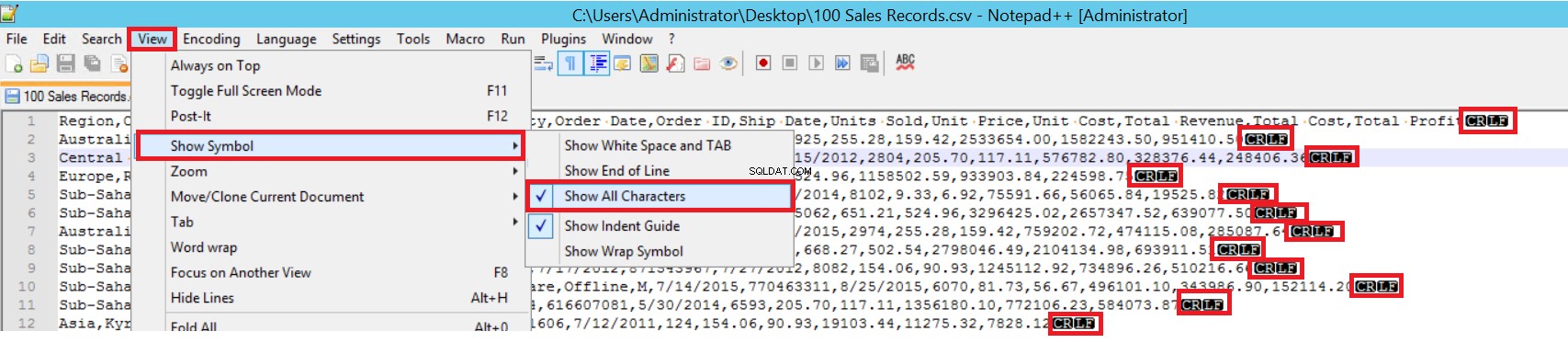
CR=キャリッジリターンおよびLF=ラインフィード。これらは、テキストファイルの改行をマークするために使用され、一括挿入ステートメントでは「\n」文字で示されます。
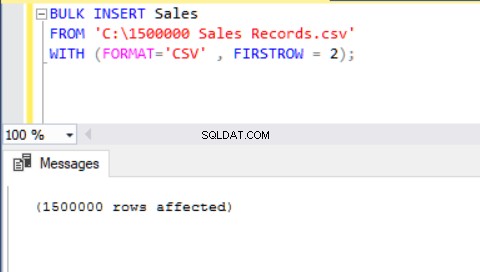
一括挿入を使用してCSVファイルをテーブルにインポートする別の方法は、FORMATパラメーターを使用することです。 FORMATパラメータはSQLServer2017以降のバージョンでのみ使用できることに注意してください。
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
次に、別のシナリオを分析します。
シナリオ-2:宛先テーブルにCSVファイルよりも多くの列があります
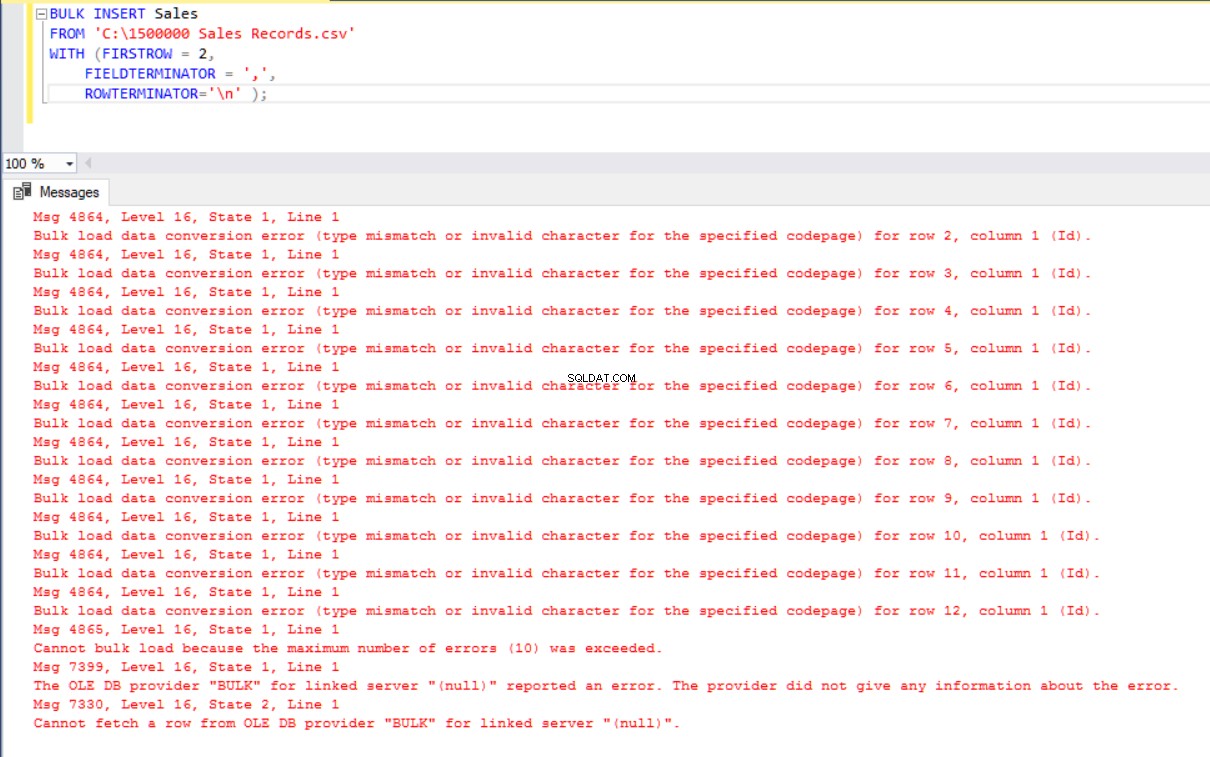
このシナリオでは、Salesテーブルに主キーを追加します。この場合、等式列のマッピングが壊れます。ここで、主キーを使用してSalesテーブルを作成し、一括挿入コマンドを使用してCSVファイルをインポートしようとすると、エラーが発生します。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
このエラーを解決するために、列をCSVファイルにマッピングするSalesテーブルのビューを作成し、このビューを介してCSVデータをSalesテーブルにインポートします。
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); シナリオ-3:CSVファイルを分離して小さなバッチサイズにロードする方法
SQL Serverは、一括挿入操作中に宛先テーブルへのロックを取得します。既定では、BATCHSIZEパラメータを設定しない場合、SQL Serverはトランザクションを開き、CSVデータ全体をこのトランザクションに挿入します。ただし、BATCHSIZEパラメーターを設定すると、SQLServerはこのパラメーター値に従ってCSVデータを分割します。次のサンプルでは、CSVデータ全体をそれぞれ300.000行のいくつかのセットに分割します。したがって、データは5回インポートされます。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
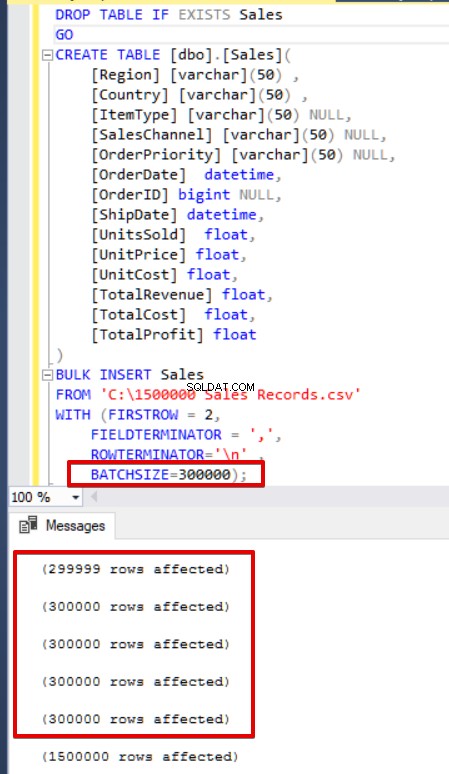
一括挿入ステートメントにバッチサイズ(BATCHSIZE)パラメーターが含まれていない場合、エラーが発生し、SQLServerは一括挿入プロセス全体をロールバックします。一方、バッチサイズパラメータを一括挿入ステートメントに設定すると、SQL Serverは、エラーが発生したこの分割された部分のみをロールバックします。このパラメータ値はデータベースシステム要件に応じて変更できるため、このパラメータの最適値または最適値はありません。
シナリオ-4:キャンセルする方法 エラーが発生したときにプロセスをインポートしますか?
一部の一括コピーのシナリオでは、エラーが発生した場合、一括コピープロセスをキャンセルするか、プロセスを続行する必要があります。 MAXERRORSパラメーターを使用すると、エラーの最大数を指定できます。一括挿入プロセスがこの最大エラー値に達すると、一括インポート操作はキャンセルされ、ロールバックされます。このパラメータのデフォルト値は10です。
次の例では、CSVファイルの3行のデータ型を意図的に破損し、MAXERRORSパラメータを2に設定します。その結果、エラー数が最大エラーパラメータを超えたため、一括挿入操作全体がキャンセルされます。

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
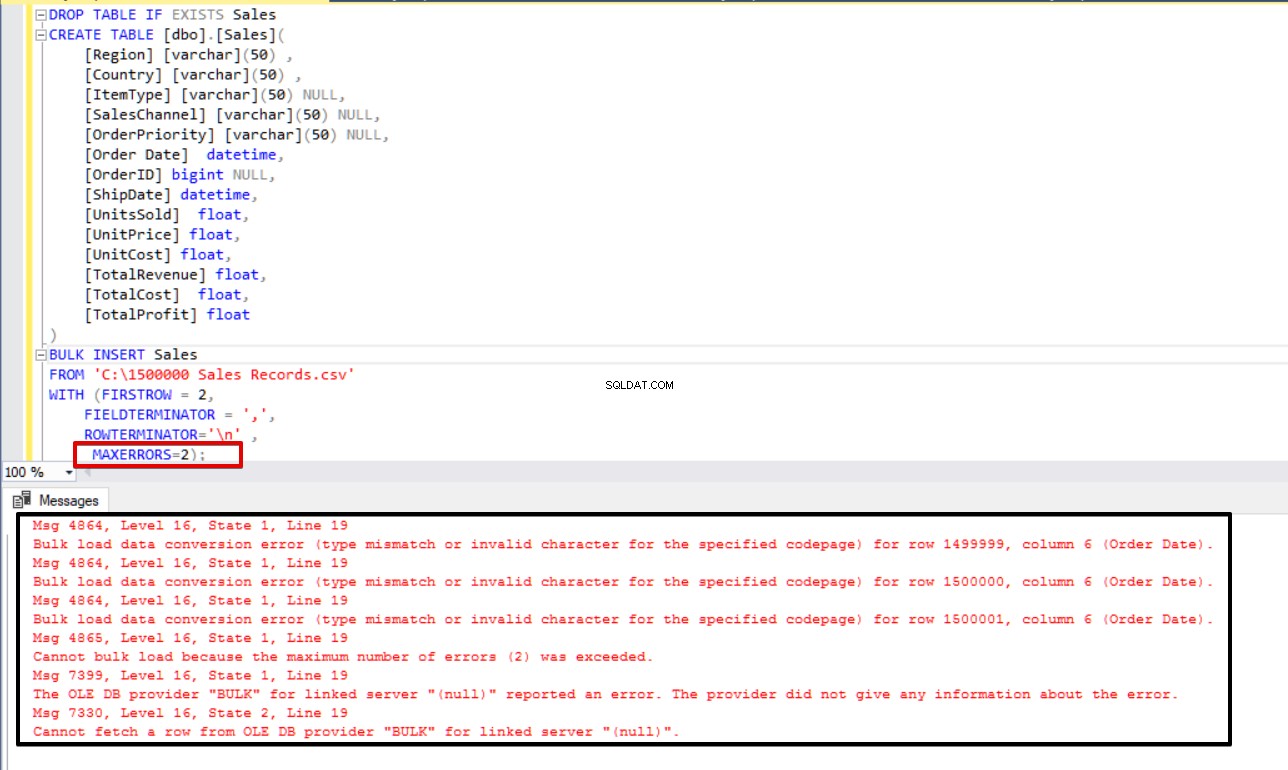
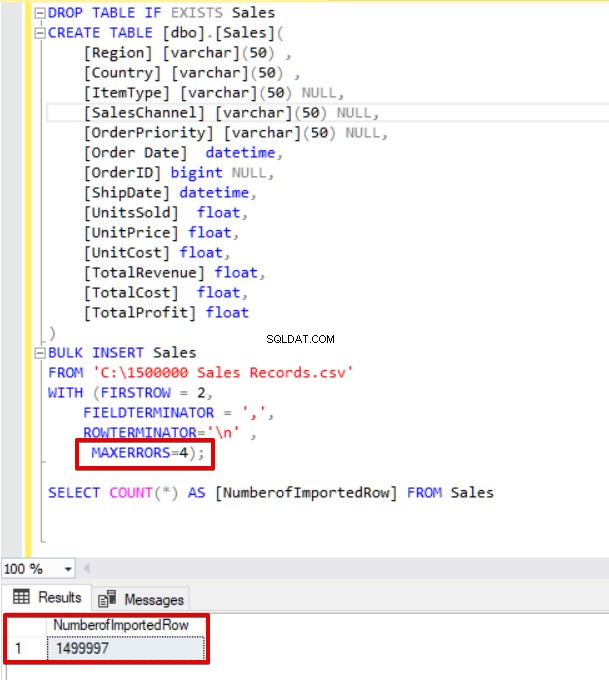
ここで、max errorパラメーターを4に変更します。その結果、一括挿入ステートメントはこれらの行をスキップして適切なデータ構造化行を挿入し、一括挿入プロセスを完了します。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
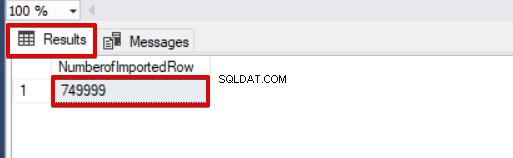
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
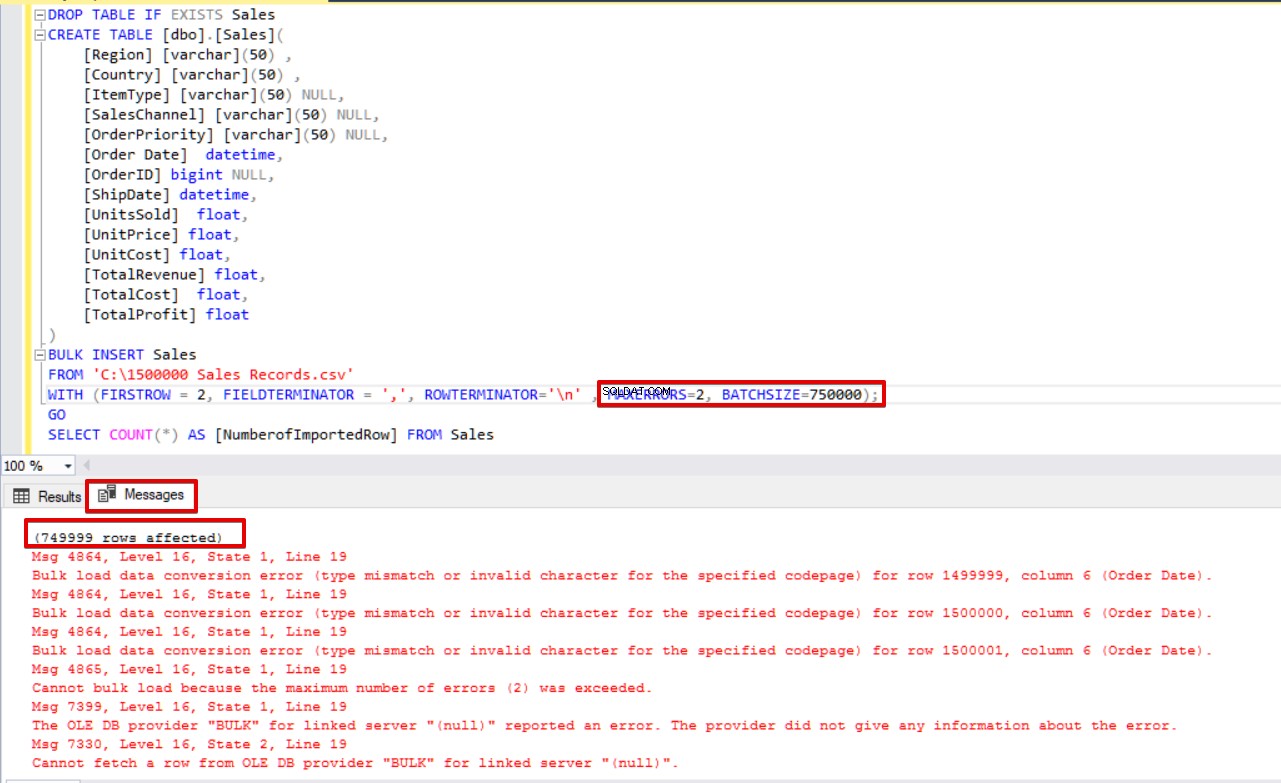
さらに、バッチサイズと最大エラーパラメータの両方を同時に使用すると、一括コピープロセスは挿入操作全体をキャンセルせず、分割された部分のみをキャンセルします。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
この一連の記事の最初のパートでは、SQL Serverで一括挿入操作を使用する基本について説明し、実際の問題に近いいくつかのシナリオを分析しました。
SQL Server一括挿入–パート2
便利なリンク:
一括挿入
E for Excel –テスト用のサンプルCSVファイル/データセット(150万レコードまで)
Notepad++のダウンロード
便利なツール:
dbForge Data Pump – SQLデータベースに外部ソースデータを入力し、システム間でデータを移行するためのSSMSアドイン。