ウィキペディアによると、一括挿入は、データベース管理システムによって提供されるプロセスまたはメソッドであり、データの複数の行をデータベーステーブルにロードします。この説明をBULKINSERTステートメントに合わせると、一括挿入により外部データファイルをSQLServerにインポートできます。
組織に1.500.000行のCSVファイルがあり、それをSQL Serverの特定のテーブルにインポートして、SQLServerでBULKINSERTステートメントを使用するとします。このタスクを処理するためのいくつかの方法を見つけることができます。 BCPを使用している可能性があります( b ulk c opy p rogram)、SQL Serverインポートおよびエクスポートウィザード、またはSQLServer統合サービスパッケージ。ただし、BULKINSERTステートメントははるかに高速で強力です。もう1つの利点は、一括挿入プロセスの設定を決定するのに役立ついくつかのパラメーターを提供することです。
基本的なサンプルから始めましょう。次に、より洗練されたシナリオを実行します。
準備
まず、サンプルのCSVファイルが必要です。 E for Excel WebサイトからサンプルCSVファイルをダウンロードします(異なる行番号のサンプルCSVファイルのコレクション)。ここでは、1.500.000の販売記録を使用します。
zipファイルをダウンロードし、解凍してCSVファイルを取得し、ローカルドライブに配置します。
CSVファイルをSQLServerテーブルにインポートする
CSVファイルを最も簡単な形式で宛先テーブルにインポートします。サンプルCSVファイルをC:ドライブに配置しました。次に、CSVファイルデータをインポートするテーブルを作成します。
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
次のBULKINSERTステートメントは、CSVファイルをSalesテーブルにインポートします。
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); 上記の一括挿入ステートメントの特定のパラメーターに気付いたと思います。それらを明確にしましょう:
- FIRSTROW 挿入ステートメントの開始点を指定します。以下の例では、列ヘッダーをスキップするため、このパラメーターを2に設定します。

- フィールドターミネーター フィールドを互いに分離する文字を定義します。 SQLServerはこの方法で各フィールドを検出します。
- ROWTERMINATOR FIELDTERMINATORと大差ありません。行の分離文字を定義します。
サンプルCSVファイルでは、FIELDTERMINATORは非常に明確であり、コンマ(、)です。このパラメーターを検出するには、Notepad ++でCSVファイルを開き、[表示]->[シンボルの表示]->[すべてのチャーターの表示]に移動します。 CRLF文字は各フィールドの最後にあります。
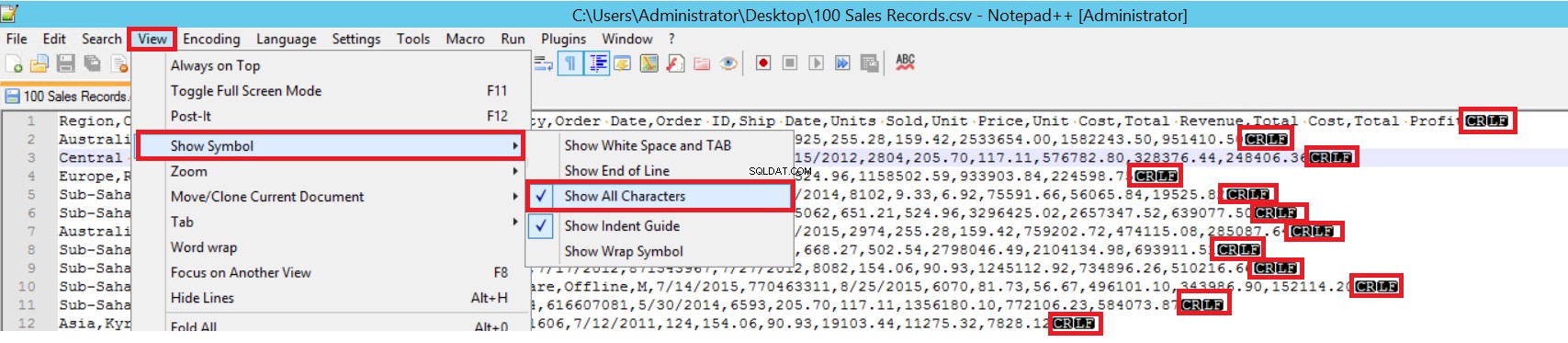
CR=キャリッジリターンおよびLF=ラインフィード。これらは、テキストファイルの改行をマークするために使用されます。一括挿入ステートメントのインジケーターは「\n」です。
一括挿入を使用してCSVファイルをテーブルにインポートする別の方法は、FORMATパラメーターを使用することです。このパラメータは、SQLServer2017以降のバージョンでのみ使用できることに注意してください。
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
これは、宛先テーブルとCSVファイルの列数が同じである最も単純なシナリオでした。ただし、宛先テーブルにさらに多くの列がある場合は、CSVファイルが一般的です。考えてみましょう。
等式列のマッピングを解除するために、Salesテーブルに主キーを追加します。主キーを使用してSalesテーブルを作成し、一括挿入コマンドを使用してCSVファイルをインポートします。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); ただし、エラーが発生します:
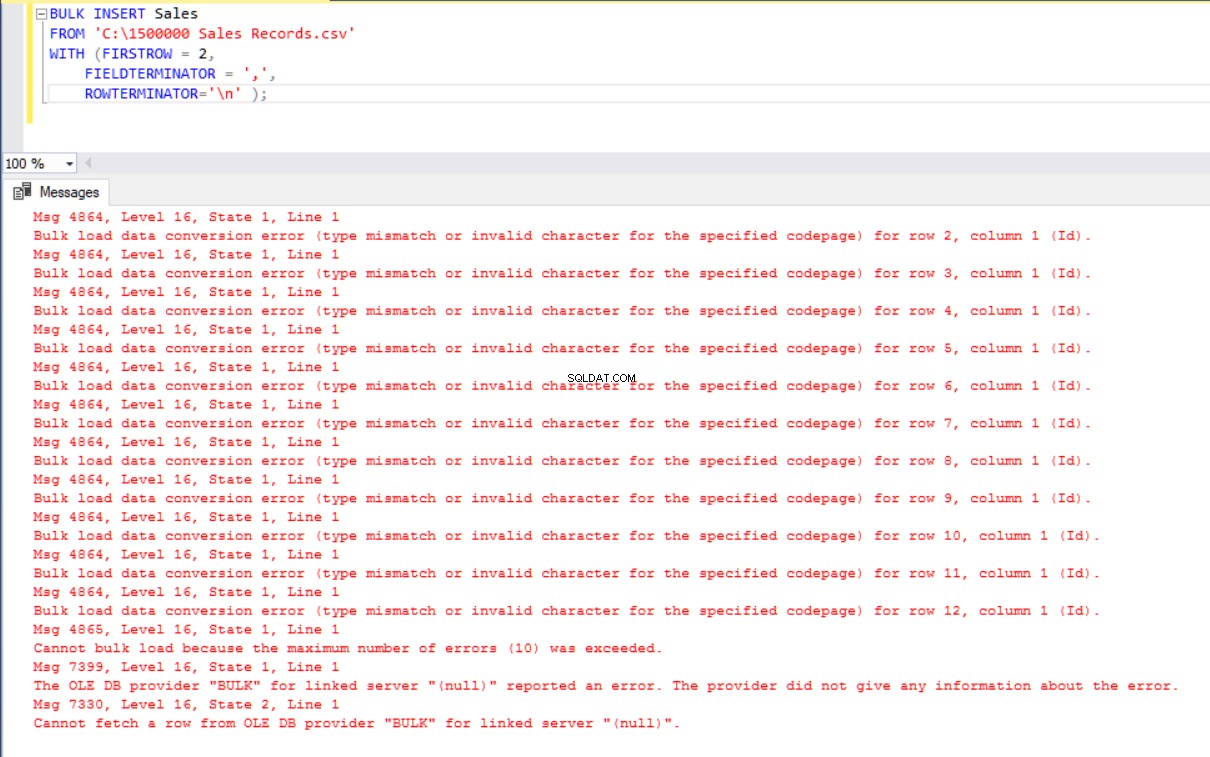
エラーを解決するために、列をCSVファイルにマッピングするSalesテーブルのビューを作成します。次に、このビューを介してCSVデータをSalesテーブルにインポートします。
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); 大きなCSVファイルを分離して小さなバッチサイズにロードします
SQL Serverは、一括挿入操作中に宛先テーブルへのロックを取得します。既定では、BATCHSIZEパラメータを設定しない場合、SQL Serverはトランザクションを開き、CSVデータ全体をトランザクションに挿入します。このパラメーターを使用すると、SQLServerはパラメーター値に従ってCSVデータを分割します。
CSVデータ全体をそれぞれ300.000行のいくつかのセットに分割しましょう。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); データは部分的に5回インポートされます。
- 一括挿入ステートメントにBATCHSIZEパラメータが含まれていない場合、エラーが発生し、SQLServerは一括挿入プロセス全体をロールバックします。
- このパラメーターを一括挿入ステートメントに設定すると、SQLServerはエラーが発生した部分のみをロールバックします。
このパラメータの値はデータベースシステム要件に応じて変化する可能性があるため、このパラメータに最適な値や最適な値はありません。
エラーが発生した場合の動作を設定します
一部の一括コピーシナリオでエラーが発生した場合は、一括コピープロセスをキャンセルするか、続行する場合があります。 MAXERRORSパラメーターを使用すると、エラーの最大数を指定できます。一括挿入プロセスがこの最大エラー値に達すると、一括インポート操作がキャンセルされ、ロールバックされます。このパラメータのデフォルト値は10です。
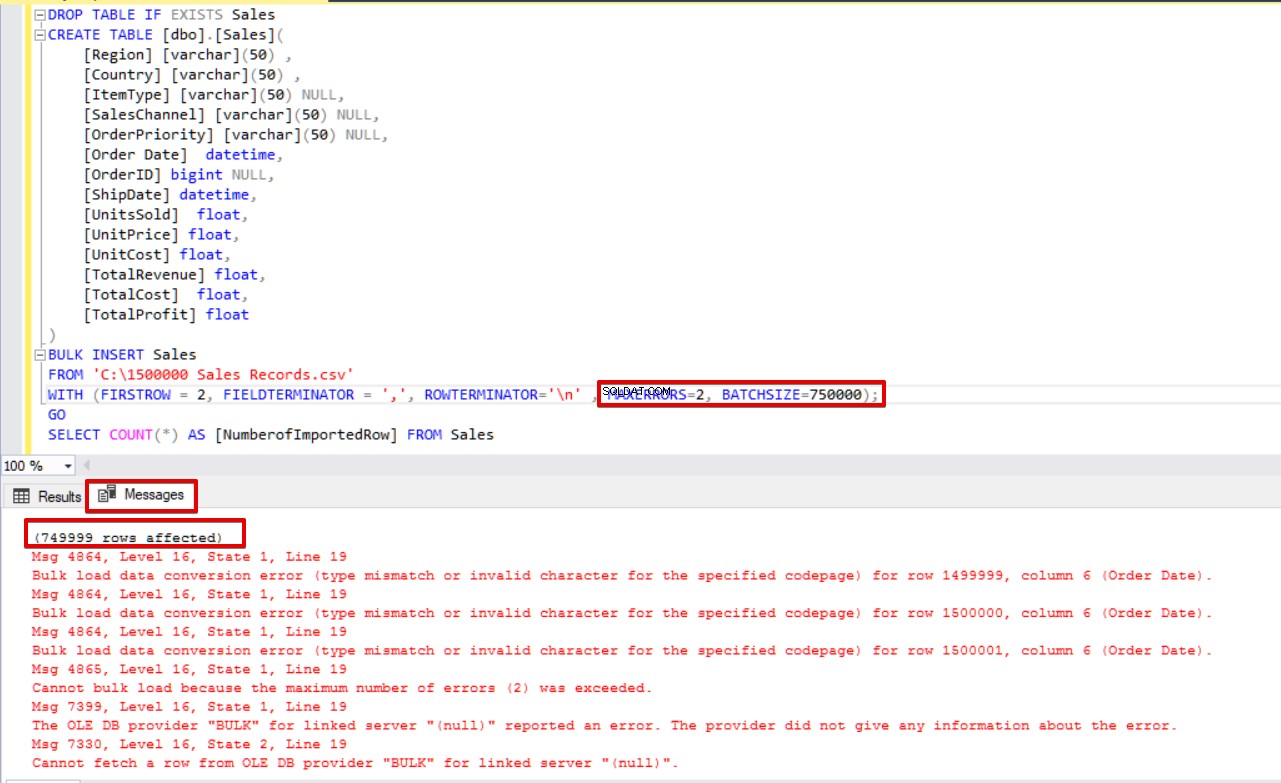
たとえば、CSVファイルの3行のデータ型が破損しています。 MAXERRORSパラメータは2に設定されています。

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); MAXERRORSパラメータ値よりも多くのエラーがあるため、一括挿入操作全体がキャンセルされます。
MAXERRORSパラメーターを4に変更すると、一括挿入ステートメントはエラーのあるこれらの行をスキップし、正しいデータ構造化行を挿入します。一括挿入プロセスが完了します。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales BATCHSIZEとMAXERRORSの両方を同時に使用する場合、一括コピープロセスは挿入操作全体をキャンセルしません。分割された部分のみがキャンセルされます。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
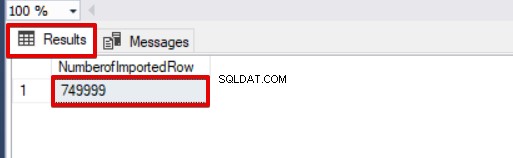
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales スクリプトの実行結果を示す以下の画像をご覧ください。
一括挿入プロセスの他のオプション
FIRE_TRIGGERS –一括挿入操作中に宛先テーブルでトリガーを有効にします
デフォルトでは、一括挿入プロセス中に、ターゲットテーブルで指定された挿入トリガーは起動されません。それでも、状況によっては、それらを有効にしたい場合があります。
解決策は、一括挿入ステートメントでFIRE_TRIGGERSオプションを使用することです。ただし、バルクインサート操作のパフォーマンスに影響を与え、低下させる可能性があることに注意してください。これは、トリガー/トリガーがデータベースで個別の操作を実行できるためです。
最初は、FIRE_TRIGGERSパラメータを設定せず、一括挿入プロセスは挿入トリガーを起動しません。以下のT-SQLスクリプトを参照してください。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogこのスクリプトを実行すると、FIRE_TRIGGERSオプションが設定されていないため、挿入トリガーは起動しません。
それでは、FIRE_TRIGGERSオプションを一括挿入ステートメントに追加しましょう:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 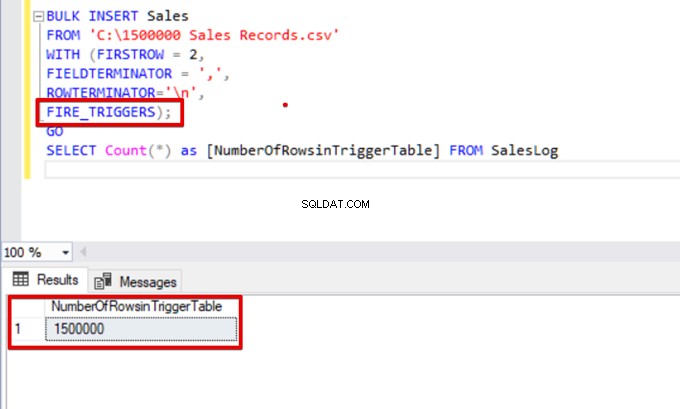
CHECK_CONSTRAINTS –一括挿入操作中にチェック制約を有効にします
チェック制約を使用すると、SQLServerテーブルでデータの整合性を強化できます。制約の目的は、構文規則に従って、挿入、更新、または削除された値をチェックすることです。たとえば、NOT NULL制約は、NULL値が指定された列を変更できないことを提供します。
ここでは、制約と一括挿入の相互作用に焦点を当てます。デフォルトでは、一括挿入プロセス中、チェックと外部キーの制約は無視されます。ただし、いくつかの例外があります。
Microsoftによると、「UNIQUEおよびPRIMARYKEY制約は常に適用されます。 NOT NULL制約が定義されている文字列にインポートする場合、テキストファイルに値がない場合、BULKINSERTは空白の文字列を挿入します。」
次のT-SQLスクリプトでは、2016年1月1日より後の注文日を制御するCheck制約をOrderDate列に追加します。
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'その結果、一括挿入プロセスはチェック制約制御をスキップします。ただし、SQL Serverは、チェック制約を信頼できないものとして示しています:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'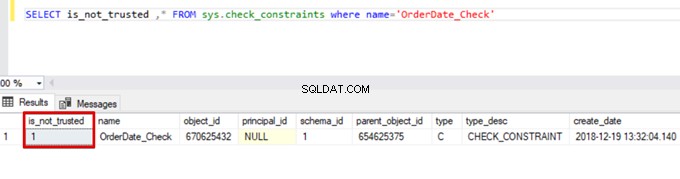
この値は、チェック制約をスキップすることにより、誰かがこの列にデータを挿入または更新したことを示します。同時に、この列には、その制約に関する一貫性のないデータが含まれている可能性があります。
CHECK_CONSTRAINTSオプションを指定して一括挿入ステートメントを実行してみてください。結果は簡単です。データが不適切なため、チェック制約はエラーを返します。
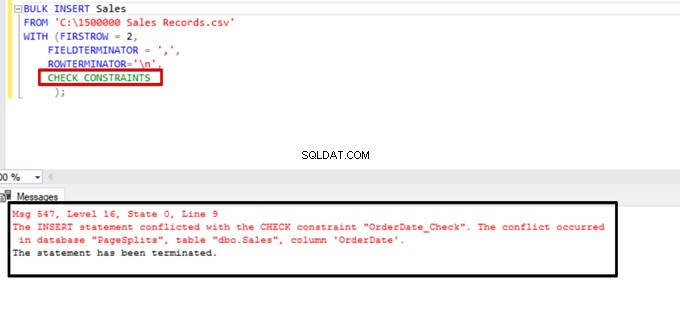
TABLOCK –1つの宛先テーブルへの複数の一括挿入のパフォーマンスを向上させます
SQL Serverのロックメカニズムの主な目的は、データの整合性を保護および保証することです。 SQL Serverのロックに関する記事のメインコンセプトには、ロックメカニズムの詳細が記載されています。
一括挿入プロセスのロックの詳細に焦点を当てます。
TABLELOCKオプションを指定せずに一括挿入ステートメントを実行すると、ロック階層に従って行またはテーブルのロックが取得されます。ただし、場合によっては、1つの宛先テーブルに対して複数の一括挿入プロセスを実行して、操作時間を短縮したい場合があります。
まず、2つの一括挿入ステートメントを同時に実行し、ロックメカニズムの動作を分析します。 SQL Server Management Studioで2つのクエリウィンドウを開き、次の一括挿入ステートメントを同時に実行します。
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
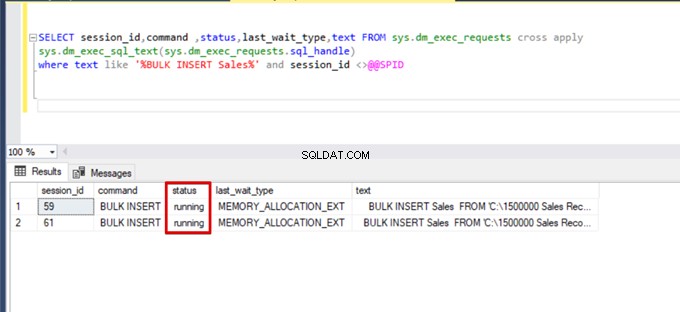
);次のDMV(動的管理ビュー)クエリを実行します–一括挿入プロセスのステータスを監視するのに役立ちます:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID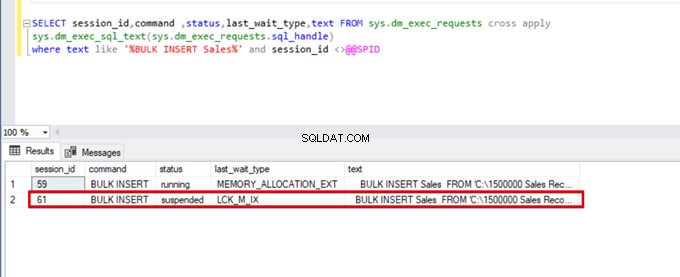
上の画像のセッション61でわかるように、一括挿入プロセスのステータスはロックのために一時停止されています。問題を確認すると、セッション59は一括挿入先テーブルをロックします。次に、セッション61は、このロックが解放されるのを待って、一括挿入プロセスを続行します。
ここで、TABLOCKオプションを一括挿入ステートメントに追加し、クエリを実行します。
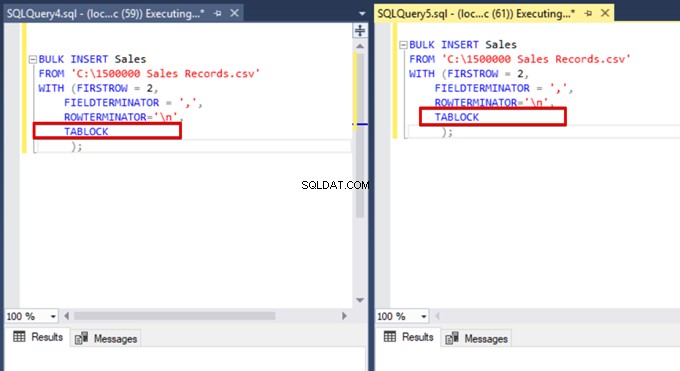
DMV監視クエリを再度実行すると、SQL Serverがバルク更新ロック(BU)と呼ばれる特定のロックの種類を使用しているため、中断された一括挿入プロセスを確認できません。このロックタイプでは、同じテーブルに対して複数の一括挿入操作を同時に処理できます。このオプションにより、一括挿入プロセスの合計時間も短縮されます。
一括挿入プロセス中に次のクエリを実行すると、ロックの詳細とロックの種類を監視できます。
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()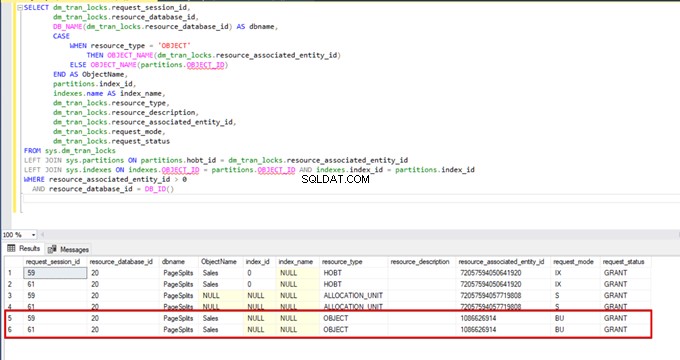
結論
現在の記事では、SQLServerでの一括挿入操作のすべての詳細について説明しました。特に、BULKINSERTコマンドとその設定およびオプションについて説明しました。また、実際の問題に近いさまざまなシナリオを分析しました。
便利なツール:
dbForge Data Pump – SQLデータベースに外部ソースデータを入力し、システム間でデータを移行するためのSSMSアドイン。