データベースは、あらゆるビジネスや組織にとって重要かつ重要な部分です。成長傾向は、82%の企業がデータベースの数が今後12か月で増加すると予測しています。すべてのDBAの主要な課題は、大量のデータの増加に対処する方法を見つけることであり、これが最も重要な目標になります。データベースのパフォーマンスを向上させ、コストを削減し、ダウンタイムを排除して、ユーザーに可能な限り最高のエクスペリエンスを提供するにはどうすればよいでしょうか。データ圧縮はオプションですか?始めて、既存の機能のいくつかがそのような状況を処理するのにどのように役立つかを見てみましょう。
この記事では、データ圧縮ソリューションがデータ管理ソリューションの最適化にどのように役立つかを学びます。このガイドでは、次のトピックについて説明します。
- 圧縮の概要
- 圧縮のメリット
- データの概要は圧縮技術です
- さまざまな種類のデータ圧縮についての議論
- データ圧縮に関する事実
- 実装に関する考慮事項
- その他…
圧縮
圧縮は技術であり、したがってリソースに敏感な操作ですが、ハードウェアのトレードオフがあります。次の利点のために、データ圧縮の展開を検討する必要があります。
- 効果的なスペース管理
- 効率的なコスト削減手法
- データベースのバックアップ管理のしやすさ
- 効果的なN/W帯域幅の使用率
- 安全で迅速な回復または復元
- パフォーマンスの向上–システムのメモリフットプリントを削減します
注: SQL ServerがCPUまたはメモリに制約がある場合、圧縮は環境に適さない可能性があります。
データ圧縮は以下に適用されます:
- ヒープ
- クラスター化インデックス
- 非クラスター化インデックス
- パーティション
- インデックス付きビュー
注: ラージオブジェクトは圧縮されません(たとえば、LOBやBLOB)
次のアプリケーションに最適です:
- ログテーブル
- 監査テーブル
- ファクトテーブル
- レポート
はじめに
データ圧縮は、SQL Server 2008以降に使用されているテクノロジです。データ圧縮の考え方は、データベース内のテーブル、インデックス、またはパーティションを選択的に選択できることです。 I / Oは、データベースの内外で情報を移動する際のボトルネックであり続けます。データ圧縮はこのタイプを利用し、データベースの効率を高めるのに役立ちます。ネットワーク速度は処理速度よりもはるかに遅いことがわかっているので、処理能力を使用してデータベース内のデータを圧縮し、データの移動速度を上げることで、効率の向上を見つけることができます。次に、処理能力を再度使用して、もう一方の端のデータを解凍します。一般に、データ圧縮により、データが占めるスペースが削減されます。データ圧縮の手法はすべてのデータベースで利用でき、SQL Server2016SP1のすべてのエディションでサポートされています。これ以前は、SQL Server EnterpriseまたはDeveloperエディションでのみ使用可能であり、StandardまたはExpressでは使用できませんでした。
機能のサポート

データ圧縮タイプ
SQL Serverで使用できるデータ圧縮には、行レベルとページレベルの2種類があります。
行レベルの圧縮はバックグラウンドで機能し、固定長のデータ型を可変長の型に変換します。ここでの前提は、多くの場合、データはchar 100などの固定長タイプで格納され、すべてのレコードの100文字全体を実際に埋めるわけではないということです。テーブルからこの余分なスペースを削除することで、わずかなゲインを実現できます。もちろん、データテーブルが固定長のテキストと数値フィールドを使用していない場合、またはそれらが実際に完全に許容される文字数と桁数を格納している場合、行レベルのスキームでの圧縮ゲインは最小限になります。せいぜい。
圧縮の概念は、char、int、floatを含むすべての固定長データ型に拡張されています。 SQL Serverでは、可変サイズのタイプのようにデータを格納することでスペースを節約できます。データが表示され、固定長のように動作します。
たとえば、値100を intに保存した場合 列では、SQL Serverは32ビットすべてを使用する必要はなく、代わりに8ビット(1バイト)を使用します。
ページレベルの圧縮は、物事を別のレベルに引き上げます。まず、固定長のデータフィールドに行レベルの圧縮が自動的に適用されるため、デフォルトでこれらのゲインが自動的に取得されます。次に、その上に、プレフィックス圧縮と呼ばれるものと、辞書圧縮と呼ばれる別の手法を適用します。
行の圧縮
行圧縮は、空白文字を格納しないことにより可変長フォーマットを使用して固定文字ストリングを格納する内部レベルの圧縮です。次の手順は、行レベルの圧縮で実行されます。
- intなどのすべての数値データ型 、フロート 、 10進数、 およびお金 可変長データ型に変換されます。たとえば、列に格納されている125と列のデータ型は整数です。次に、整数値を格納するために4バイトが使用されていることがわかります。ただし、1バイトは0から255までの値を格納できるため、125は1バイトに格納できます。したがって、125は小さな intとして格納できます。 、3バイトを節約できるように。
- Char およびNchar データ型は可変長データ型として格納されます。たとえば、「SQL」は charに格納されます (20)列を入力します。ただし、圧縮後は3バイトのみが使用されます。データ圧縮後、このタイプのデータには空白文字は保存されません。
- レコードのメタデータが削減されます。
- NULLと0の値が最適化され、スペースは消費されません。
ページ圧縮
ページ圧縮は、高度なレベルのデータ圧縮です。デフォルトでは、ページ圧縮は行レベルの圧縮も実装します。ページ圧縮は2つのタイプに分類されます
- プレフィックス圧縮と
- 辞書圧縮。
プレフィックス圧縮
各ページのプレフィックス圧縮では、ページの各列について、すべての行から共通の値が取得され、各列のヘッダーの下に格納されます。これで、各行に、共通の値の代わりにその値への参照が格納されます。
辞書圧縮
辞書圧縮はプレフィックス圧縮に似ていますが、共通の値がすべての列から取得され、ヘッダーの後の2番目の行に格納されます。辞書圧縮は、各ページのすべての列と行で完全に一致する値を探します。
次のデータベースオブジェクトに対して行およびページレベルの圧縮を実行できます。
- ヒープに格納されているテーブル。
- クラスター化されたインデックスとして保存されたテーブル全体。
- インデックス付きビュー。
- 非クラスター化インデックス。
- パーティション化されたインデックスとテーブル。
注: データ圧縮は、CREATE TABLE、CREATE INDEXのように作成時、またはALTERTABLE…のようにREBUILDオプションを指定したALTERコマンドを使用して作成した後に実行できます。再構築。
デモ
WideWorldImporters データベースはデモ全体を通して使用されます。また、リアルタイムの DW データベースは圧縮操作の対象と見なされます。
手順を詳しく見ていきましょう:
1.データベース内のオブジェクトの圧縮設定を表示するには、次のT-SQLを実行します。
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
次の出力は、圧縮タイプをPAGE、ROWとして示しており、いくつかのテーブルではNONEです。これは、圧縮用に構成されていないことを意味します。
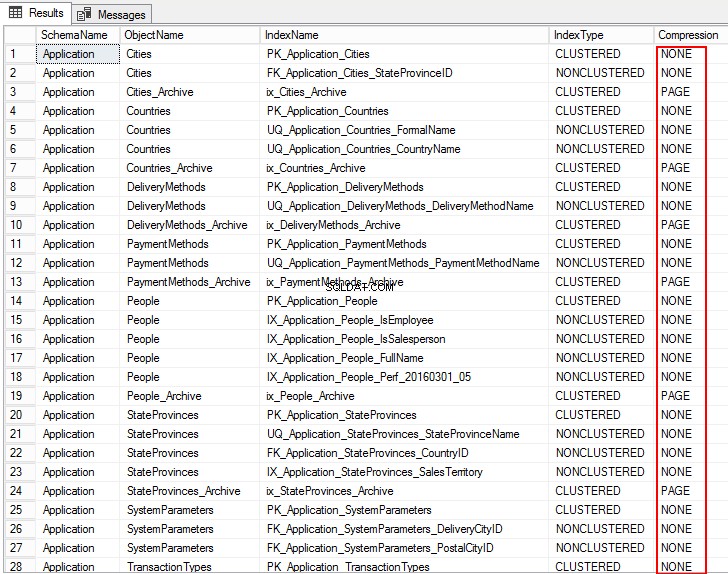
2.圧縮を見積もるには、次のシステムストアドプロシージャ sp_estimate_data_compression_savingsを実行します。 。この場合、ストアドプロシージャはPurchaseOrderLinesテーブルで実行されます。
3.次のT-SQLを実行して、PurchaseOrderLines圧縮設定を確認しましょう。
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
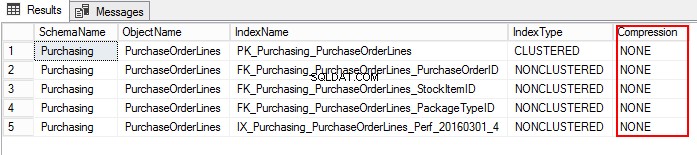
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

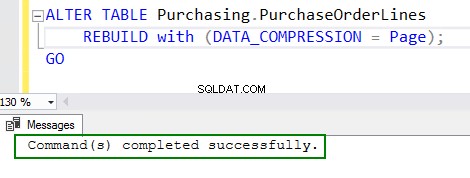
4.ALTERtableコマンドを実行して圧縮を有効にします。
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
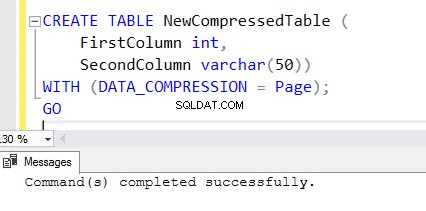
5.圧縮が有効な機能を使用して新しいテーブルを作成するには、CREATETABLEステートメントの最後にWITH句を追加します。 NewCompressedTableの作成に使用される以下のCREATETABLEステートメントを確認できます。 。
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
データ圧縮の事実
圧縮に関する実際の情報のいくつかを見ていきましょう
- システムテーブルに圧縮を適用することはできません
- 行サイズが8060バイトを超える場合、テーブルの圧縮を有効にすることはできません。
- 圧縮されたデータはバッファプールにキャッシュされます。応答時間が速くなることを意味します
- 圧縮を有効にすると、データが異なるページ数とページあたりの行数を使用して保存されるため、クエリプランが変更される可能性があります。
- 非クラスター化インデックスは圧縮プロパティを継承しません
- クラスター化インデックスがヒープ上に作成されると、代替の圧縮状態が指定されていない限り、クラスター化インデックスはヒープの圧縮状態を継承します。
- ROWおよびPAGEレベルの圧縮は、オフラインまたはオンラインで有効または無効にできます。
- ヒープ設定が変更された場合、すべての非クラスター化インデックスが再構築されます。
- 行またはページの圧縮を有効または無効にするためのディスク容量要件は、インデックスを作成または再構築する場合と同じです。
- ALTER PARTITIONステートメントを使用してパーティションを分割すると、両方のパーティションが元のパーティションのデータ圧縮属性を継承します。
- 2つのパーティションがマージされると、結果のパーティションは宛先パーティションのデータ圧縮属性を継承します。
- パーティションを切り替えるには、パーティションのデータ圧縮プロパティがテーブルの圧縮プロパティと一致している必要があります。
- 列ストアのテーブルとインデックスは、常に列ストア圧縮で保存されます。
- データ圧縮はスパース列と互換性がないため、テーブルを圧縮できません。
リアルタイムシナリオ
データ圧縮技術をウォークスルーし、データ圧縮の主要なパラメータを理解しましょう。
各テーブルで使用されているスペースを確認するには、次のT-SQLを実行します。クエリの出力は、各テーブルの使用法に関する詳細情報を提供します。これは、データ圧縮を実装するための決定的な要因になります。
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
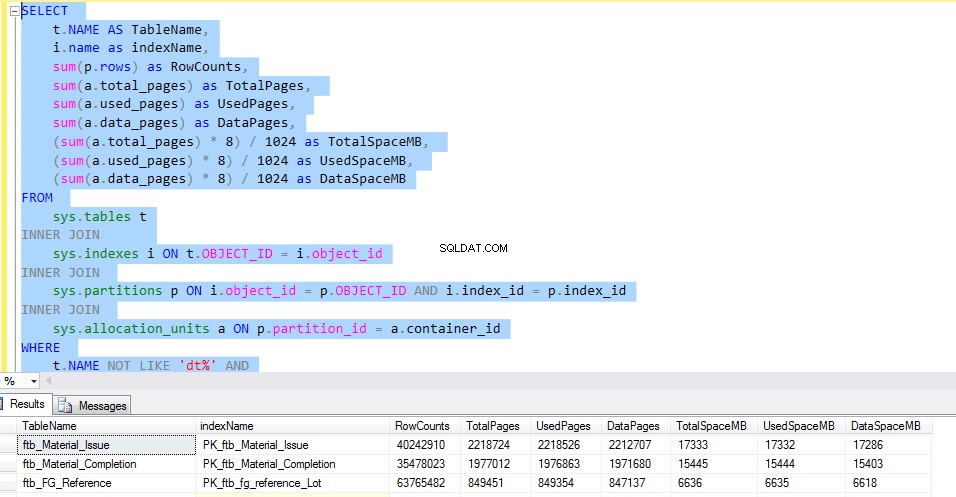
ftb_material_Issueについて考えてみましょう。 ファクトテーブル。ファクトテーブルには数値のBIGINTデータ型があります。
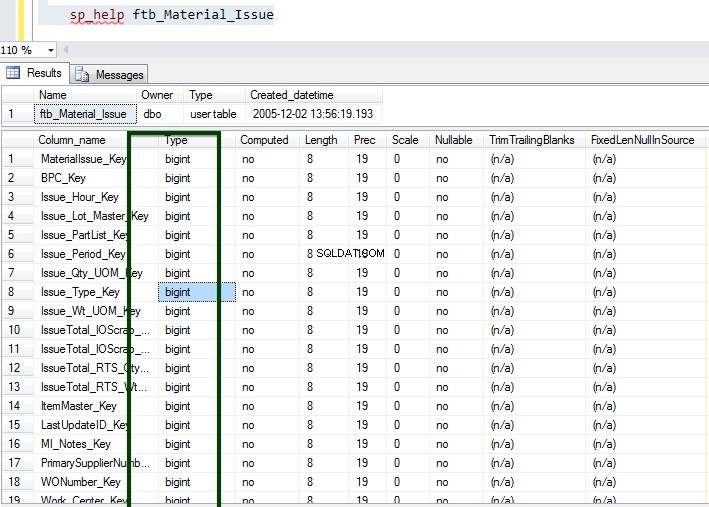
次に、sp_spaceusedストアドプロシージャを実行して、テーブルの詳細を理解します。 sp_spaceusedコマンドについて詳しくは、こちらをご覧ください。
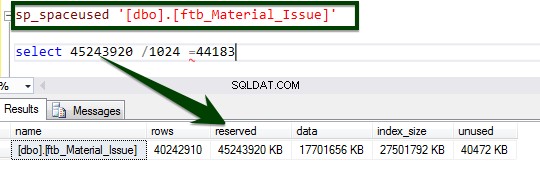
次のT-SQLを実行して、テーブルレベルの圧縮を有効にします。次のT-SQLがサーバーで実行され、テーブルレベルでページを圧縮するのに34分14秒かかりました。
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
ALTERtableコマンドの実行中のCPUとI/Oの変動を確認できます。
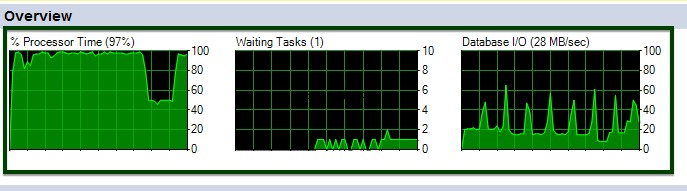
それでは、データ圧縮前とデータ圧縮後の比較を行いましょう。テーブルサイズは約45GBから約15GBに削減されます。
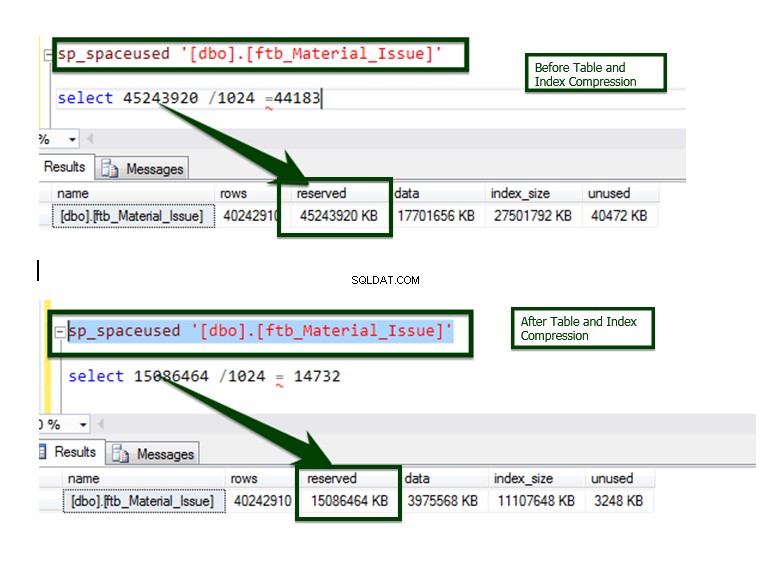
このプロセスは、自動化されたスクリプトを使用してほとんどのオブジェクトに実装されており、これが比較の最終結果です。
インデックス圧縮操作の前後のデータ比較。

概要
データ圧縮は、データのサイズを縮小するための非常に効果的な手法です。データが削減されると、必要なI/Oプロセスが少なくなります。データベースに圧縮を追加すると、CPU要件の負荷が増加します。これらの変更に効率的に対応するために、利用可能な処理能力があることを確認する必要があります。したがって、データ圧縮を有効にするための変更を適用する前に、最初に少し調査を行い、期待できるゲインの種類を確認することをお勧めします。コストがかかるクラウドデータベースのセットアップでは非常に有益です。
圧縮をステージングし(一度にすべて実行しないでください)、アクティビティの少ない時間帯に圧縮します。データ圧縮とバックアップ圧縮はうまく共存しており、ストレージスペースをさらに節約できる可能性があるので、どうぞお楽しみください。
圧縮により、物理ファイルサイズが削減されるだけでなく、ディスクI / Oも削減されます。これにより、データベースのバックアップとともに、多くのデータベースアプリケーションのパフォーマンスが大幅に向上します。
基盤となるインフラストラクチャとビジネス要件がわかっていれば、圧縮の実装を決定するのは簡単です。利用可能なシステム手順を確実に使用して、圧縮の節約を理解および見積もることができます。このストアドプロシージャは、圧縮がシステムにどのようにプラスまたはマイナスの影響を与えるかを示す詳細を提供しません。あらゆる種類の圧縮にはトレードオフがあることは明らかです。同じパターンの巨大なデータがある場合は、圧縮がスペースを節約するための鍵となります。 CPUパワーが増大し、すべてのシステムがマルチコア構造にバインドされると、圧縮は多くのシステムに適合する可能性があります。システムをテストすることをお勧めします。パフォーマンスに悪影響がないことを確認するためにテストします。インデックスに多くの更新と削除がある場合、データを圧縮および解凍するためのCPUコストは、データ圧縮によるI/OおよびRAMの節約を上回る可能性があります。すべてのデータベースまたはテーブルが自動的に圧縮を適用するのに適しているわけではないため、データベースでデータ圧縮を有効にするための変更を適用する前に、最初に少し調べて、期待できる利益の種類を確認することをお勧めします。圧縮をテストして、ご使用の環境で適切に機能するかどうかを確認する必要があります。これは、大量挿入データベースでは適切に機能しない可能性があるためです。
参考資料
SQLServer2016のエディションとサポートされている機能
データ圧縮
行圧縮の実装
ページ圧縮の実装