SQL Server Always ON可用性グループは、SQLServerデータベースの高可用性と障害復旧を実現することを目的としたソリューションです。この機能は、WindowsベースのSQL Serverインストール間、LinuxベースのSQL Serverインストール間、さらにはLinuxとWindowsベースのSQLServerインストール間で一緒に構成できます。
可用性グループは、データをそれぞれのセカンダリレプリカに複製することにより、自動フェイルオーバーおよびデータ保護の形でクラスターテクノロジーと緊密に統合されています。ただし、可用性グループを構成するためにクラスターリソースマネージャーが必要な場合は必ずしもありません。
SQL Serverの可用性グループを構成するには、 WSFCが必要です。 – WindowsServerフェールオーバークラスター Windowsのテクノロジー ベースのSQLServerのインストールとPACEMAKER Linuxの場合 ベースのSQLServerのインストール。
ペースメーカー は、Linuxシステムで障害が発生した場合に、リソースを管理し、システムの可用性を確保するために使用できるオープンソースのクラスターリソースマネージャーです。
WSFC は、Windowsベースのクラスター要件をサポートするために開発されたMicrosoft製品です。
両方のタイプのOSについてSQLServer内で構成された可用性グループを見ると、SQL ServerManagementStudioでも同様のように見えます。
ただし、この記事では、UbuntuLinuxベースのSQLServer間の可用性グループについて説明します。 PACEMAKERを使用したインストール クラスターテクノロジーなので、この構成のみを検討します。
クラスタータイプの構成
上で述べたように、OSに応じて、SQLServerの可用性グループを構成するための3つのバリエーションがあります。
- WindowsベースのSQLServerインストール間;
- LinuxベースのSQLServerインストール間;
- 混合タイプのWindowsとLinuxベースのSQLServerインストールの間。
MicrosoftはCluster_typeを導入しました 可用性グループに適切なクラスターテクノロジーを識別して構成するための構成設定。これは、SQL ServerインスタンスがどのOSに基づいているかに関係なく、可用性グループに使用するクラスターテクノロジの種類を定義する構成アイテムです。
SQL Server動的管理ビュー(DMV)sys.availability_groups を使用して、クラスタータイプの既存の構成をフェッチして検証できます。 。 cluster_typeという名前の2つの列があります およびcluster_type_desc 。これらの列を読み取って、可用性グループ設定のクラスタータイプ構成を定義できます。
この構成設定には、各バリアントのクラスターテクノロジー要件を満たすための3つの値があります。
WSFC .WindowsベースのSQLServerをインストールしている場合は、WSFC(Windowsサーバーフェールオーバークラスター)オプションを使用する必要があります。 LinuxベースのSQLServerインストールではサポートされていません。
外部 。 LinuxベースのSQLServerインストール間で可用性グループを構成する場合は、PACEMAKERクラスターマネージャーを使用して、 EXTERNALを選択する必要があります。 クラスター タイプ 。フェイルオーバーモードも外部である必要があります(WSFCでは自動になります)。
なし 。可用性グループにクラスタリングテクノロジーを使用しない場合は、なしを選択します。 。このオプションは、LinuxとWindowsベースのSQLServerインスタンス間で可用性グループを構成する場合に適用できます。システムにクラスタリングを構成した場合でも、クラスタータイプの値をNONEに設定すると、可用性グループはクラスターテクノロジーを使用しなくなります。クラスタータイプNONEのフェイルオーバーモードは常に手動です。 。
新しい設定:コミットするために必要な同期セカンダリ
SQL Server 2017以降、Microsoftは required_synchronized_secondaries_to_commitという新しい設定を導入しました。 。 PACEMAKERクラスター構成でクラスタータイプをEXTERNALとして構成した場合は、自動フェイルオーバーオプションが有効になります。
この設定の値は、SQLServerリソースエージェントmssql-server-haを構成するときにデフォルトで設定されます。 クラスター構成を作成します。
また、次のコマンドを実行して、要件の値を手動で変更できます。
--Run below commands to change value for setting required_synchronized_secondaries_to_commit
--AGResourceName is the name of the resource configured for the Availability group
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
注:上記の設定は、Linux上のPacemakerを介してのみ変更できます。 Linuxベースの展開では、T-SQLステートメントを使用して変更することはできません。ただし、Windowsベースの展開の場合、T-SQLステートメントによってこの設定を変更できます。
以下は、 required_synchronized_secondaries_to_commitの可能な値です。
0 – これは、セカンダリレプリカをそれぞれのプライマリレプリカと同期する必要がないことを意味します。したがって、自動フェイルオーバーはサポートされていません。プライマリレプリカがダウンした場合は、フェイルオーバーを手動で開始する必要があります。重要:構成にこの値を選択すると、データが失われる可能性があります。
1 – これは、自動フェイルオーバーを実現するには、少なくとも1つのセカンダリレプリカが同期状態である必要があることを意味します。
2 – これは、両方のセカンダリレプリカをプライマリレプリカと同期する必要があることを意味します。自動フェイルオーバーがサポートされています。
可用性グループに参加するためのレプリカ
可用性グループに参加できるレプリカの数は、インストールされているSQLServerのエディションによって異なります。
- SQLServerの標準 エディションは2ノードレプリカのみをサポートします 追加の構成のみのレプリカとともに可用性グループの場合。
- SQLServerエンタープライズ エディションは最大9つをサポートします レプリカ–1つのプライマリレプリカと8つのセカンダリレプリカ。
SQL Server Standard Editionは2つのレプリカ(1つのプライマリレプリカと1つのセカンダリレプリカ)のみをサポートするため、Microsoftは構成のみのレプリカと呼ばれる新しい概念を導入しました。 SQL Server 2017 CU1で、Linuxシステムで実行されているSQLServerの自動フェイルオーバーを実現します。
2つの可能な設計オプションがあります:
- 3つの同期レプリカ。 この構成は、SQLServerEnterpriseエディションでのみ展開できます。可用性データベースのコピーが3つあります。このアーキテクチャにより、読み取りスケール、高可用性、およびデータ保護の3つの機能すべてが可能になります。
- 2つの同期レプリカと構成のみのレプリカ。 この設計は、SQL Server Standardエディションを使用して構成することもでき、SQL Server Standardエディションで2つの同期レプリカを実行し、SQLServerExpressエディションで構成のみのレプリカとして機能する3つのレプリカを実行します。これは、自動フェイルオーバーとデータベース保護により高可用性をサポートする費用対効果の高い設計です。
2ノードレプリカ
2ノードのレプリカ構成 可用性グループの場合は、SQLServerデータベースの高可用性を確保するための非常に一般的な展開オプションです。 Windows Serverフェールオーバークラスターテクノロジと、WindowsベースのSQLServer展開でのファイル共有監視の助けを借りて自動フェールオーバーを実現します。
ファイル共有は通常、WSFCの追加ノードで使用され、2ノードのレプリカ構成のクォーラム構成を提供します。 WSFCは、すべての構成メタデータをレプリカと3番目のノードまたはファイル共有監視の両方に同期して、スムーズなフェイルオーバーを実現します。 WindowsベースのSQLServer可用性グループのすべてのフェールオーバーアービトレーションはWSFCレイヤーで行われます。
LinuxベースのSQLServer可用性グループの展開で自動フェイルオーバーを実現する場合、上記の構成は機能しません。これは、WSFCはWindowsベースのSQLServerのインストールにのみ使用できるためです。
この制限に対処し、Linuxベースの2レプリカ展開の自動フェイルオーバーを有効にするために、Microsoftは新しい概念を導入しました。
構成のみのレプリカ
構成のみのレプリカは、3番目のノードにSQLServerの追加インスタンスをインストールするオプションです。そのノードは、自動フェイルオーバーをサポートする2ノードレプリカ構成の監視サーバーとして機能します。 可用性グループごとに1つの構成のみのレプリカを作成できます 。
PACEMAKERのEXTERNALとしてクラスタータイプを使用するLinuxベースのSQLServerインスタンスの場合、フェールオーバーアービトレーションはWSFCのようなクラスターレイヤーでは機能しません。すべての可用性グループ構成メタデータが各レプリカのマスターデータベースに格納されているため、すべてのフェールオーバーアービトレーションはSQLServerレイヤーで行われます。
Microsoftは、LinuxベースのSQLServer可用性グループのクォーラムを処理するための構成のみのレプリカの概念を導入しました。この概念は、可用性グループに参加するためのユーザーデータベースをホストしません。すべてのフェイルオーバーアービトレーションがスムーズに行われるように、すべての可用性グループ構成情報をマスターデータベースに保存します。
構成のみのレプリカには、任意のエディションのSQLServerを使用できます。 SQL Server Expressエディションでさえ、3番目のレプリカのライセンスコストを節約するのに適しています。構成のみのレプリカは、可用性グループ内のデータベースをホストしないことに注意してください。したがって、可用性グループにはデータベースのコピーが2つだけあります。
デフォルトでは、 required_synchronized_secondaries_to_commit 0に設定されています 構成のみのレプリカを使用する場合。必要に応じて、この値を手動で1に変更できます。
自動フェイルオーバーとデータ保護を実現するために、2ノードの同期レプリカと構成のみのレプリカの設計図をご覧ください。
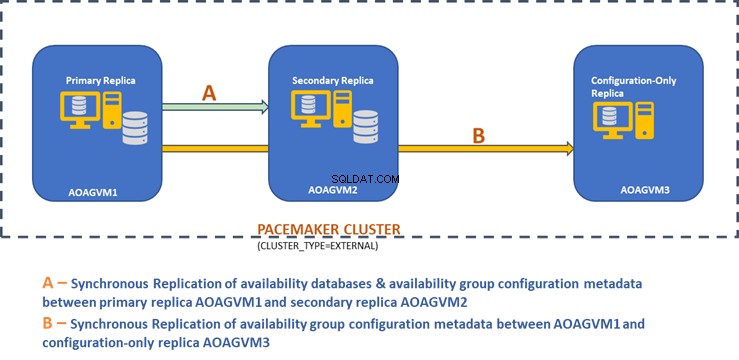
AOAGVM1、AOAGVM2、AOAGVM3という名前の3つのVMがあることがわかります。これらはすべてUbuntuLinuxシステムで実行されており、SQLServerは3つのLinuxシステムすべてで構成されています。可用性データベースは、AOAGVM1およびAOAGVM2でホストされています。
AOAGVM1はプライマリレプリカとして機能していますが、AOAGVM2はセカンダリレプリカです。 AOAGVM3は、SQLServerExpressエディションである構成のみのレプリカとして機能します。この3番目のレプリカでホストされているユーザーデータベースはありません。
Pacemakerクラスターは、Linuxベースの可用性グループ構成のクラスターテクノロジーをサポートするために、3つのノードすべての間に構成されています。
上記の設計を構成または実装するには、次の手順を実行する必要があります。
- 3つのUbuntuシステムにSQLServerをインストールします(SQL Server Expressエディションは構成専用レプリカに適しています)。
- 3つのノード間で可用性グループを構成します。
- 3つのノード間でPACEMAKERクラスターを構成します。
- 可用性グループをクラスターグループのリソースとして追加または統合します。
ステップ1(3つのノードへのSQL Serverインスタンスのインストール)を完了するには、関連記事を参照してください。
上記の設計を実装するためのステップバイステップのプロセスを説明する次の記事にご期待ください。私たちの目標は、2ノードの同期レプリカと構成のみのレプリカを使用して自動フェイルオーバーとデータ保護を実現することです。
この件に関するご意見や実践的なヒントをお聞かせいただければ幸いです。コメントセクションで自由に共有してください。