数週間前、SQL Server2016の新しいネイティブ関数STRING_SPLIT()のパフォーマンスに驚いたことについて書きました。 :
- パフォーマンスの驚きと仮定:STRING_SPLIT()
投稿が公開された後、私はこれらの提案(または私が提案に変えた質問)について(公的および私的に)いくつかのコメントを受け取りました:
- JSONアプローチの明示的な出力データ型を指定して、そのメソッドが
nvarchar(max)のフォールバックによる潜在的なパフォーマンスオーバーヘッドの影響を受けないようにします。 。 - わずかに異なるアプローチをテストします。ここでは、データを使用して実際に何かが実行されます。つまり、
SELECT INTO #temp。 - 特に分割操作をネストする場合に、推定行数が既存の方法とどのように比較されるかを示します。
オフラインで何人かの人に返信しましたが、ここにフォローアップを投稿する価値があると思いました。
JSONに対してより公平であること
元のJSON関数は次のようになり、出力データ型は指定されていません:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); 名前を変更し、次の定義でさらに2つ作成しました。
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); これでパフォーマンスが大幅に向上すると思いましたが、残念ながらそうではありませんでした。もう一度テストを実行したところ、結果は次のとおりでした。
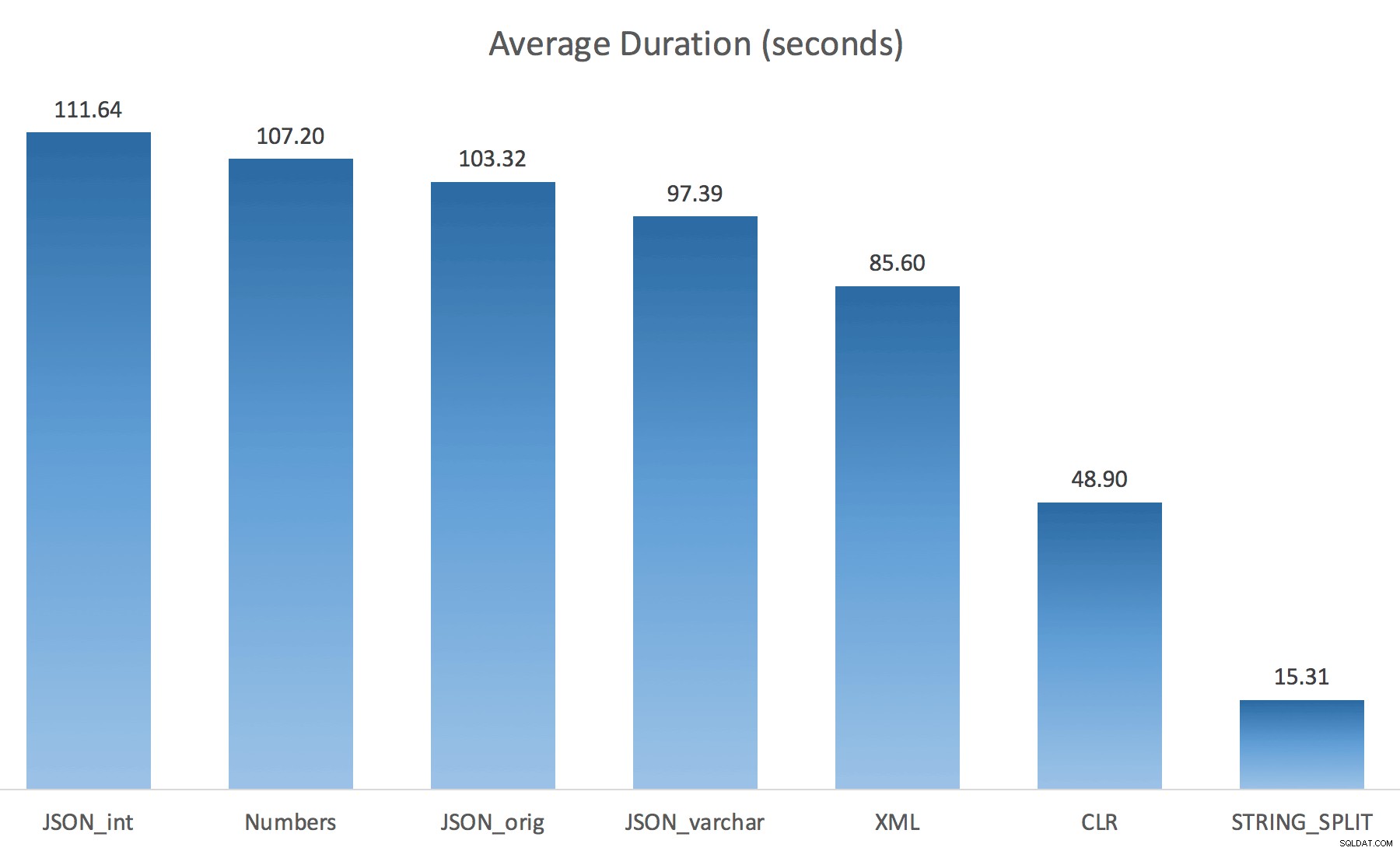
テストのランダムインスタンス中に観察された待機(25を超えるものにフィルタリング):
| CLR | IO_COMPLETION | 1,595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6,294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4,307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6,110 |
| SOS_SCHEDULER_YIELD | 87 | |
| 数字 | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1,917 |
| IO_COMPLETION | 1,616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
監視された待機>25(STRING_SPLITのエントリがないことに注意してください )
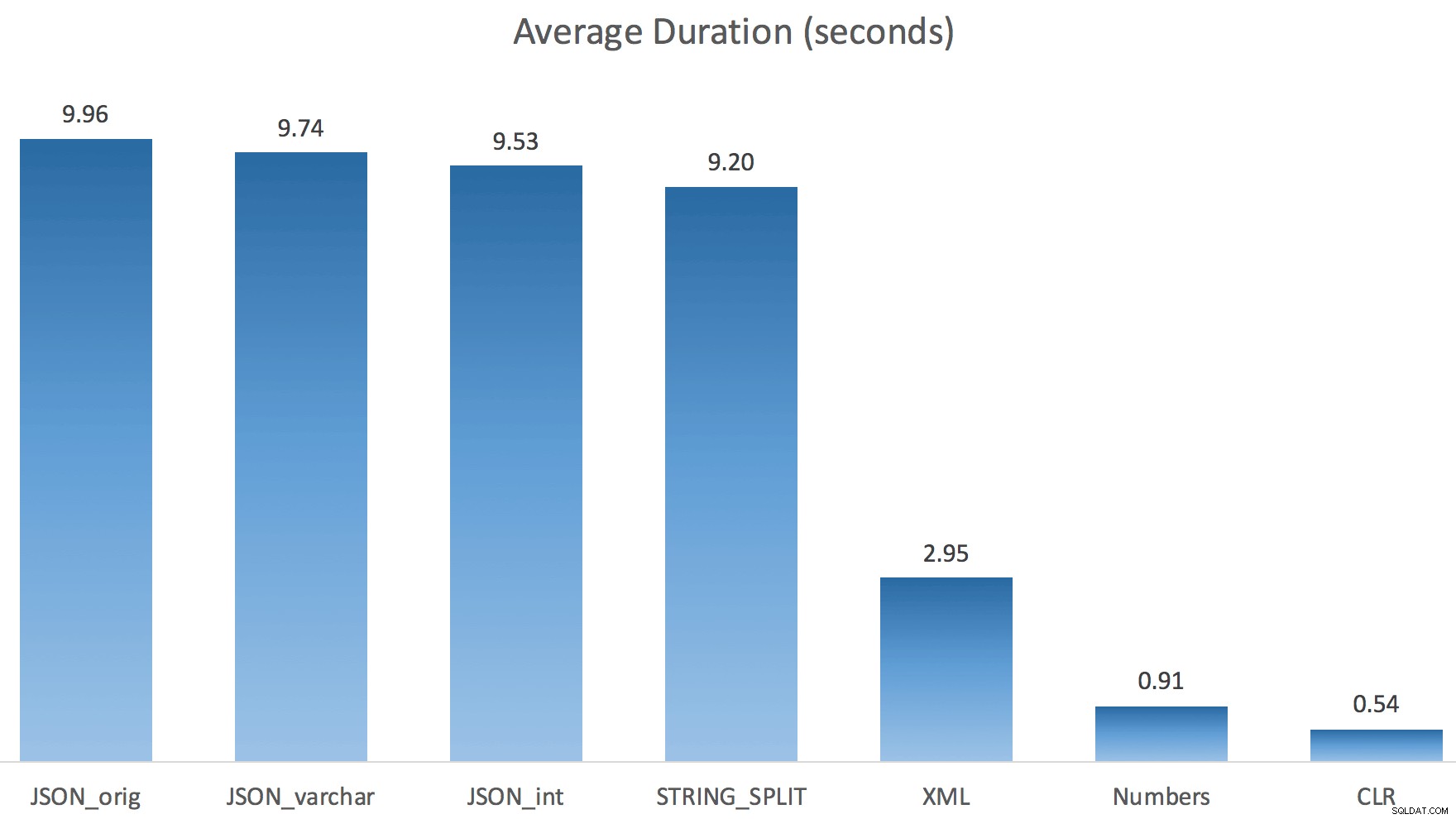
デフォルトからvarchar(100)に変更中 パフォーマンスは少し向上しましたが、ゲインはごくわずかで、intに変更しました。 実際にそれを悪化させました。これに、おそらくSTRING_ESCAPE()を追加する必要があることを追加します。 いくつかのシナリオでは、JSON解析を台無しにする文字が含まれている場合に備えて、着信文字列に追加します。私の結論は、これは新しいJSON機能を使用するための優れた方法ですが、ほとんどの場合、妥当な規模には不適切な目新しさであるということです。
出力の具体化
ジョナサンマグナンは私の前の投稿でこの鋭い観察をしました:
STRING_SPLIT 確かに非常に高速ですが、一時テーブルを操作するときは地獄のように遅くなります(将来のビルドで修正されない限り)。SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
SQL CLRソリューションよりもはるかに遅くなります(15倍以上!)。
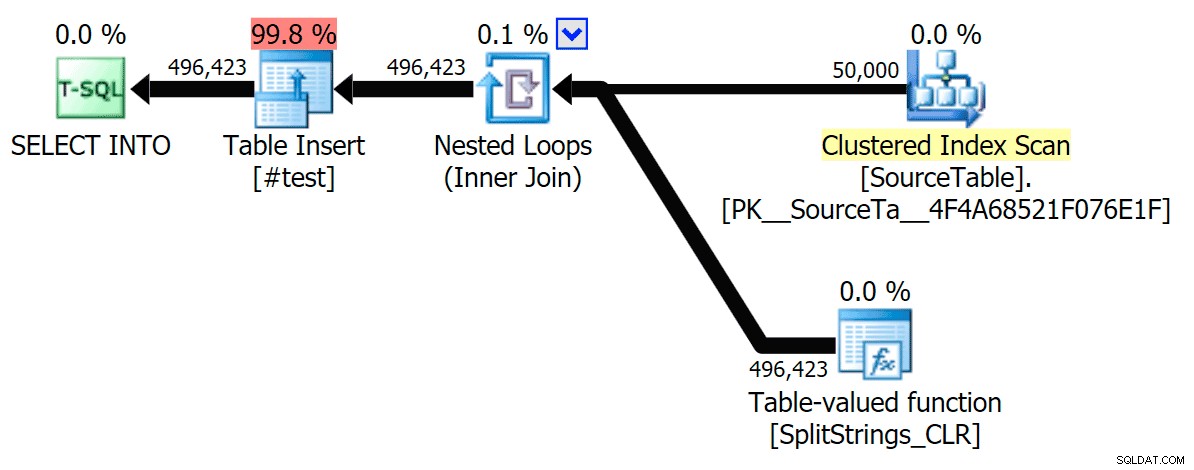
そこで、掘り下げました。各関数を呼び出して結果を#tempテーブルにダンプし、それらの時間を計測するコードを作成しました。
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
システムのI/Oを完全に破壊したくなかったので、各テストを(100回ループするのではなく)1回だけ実行しました。それでも、3回のテスト実行を平均した後、ジョナサンは100%正しかった。各メソッドを使用して、#tempテーブルに最大500,000行を入力する期間は次のとおりです。
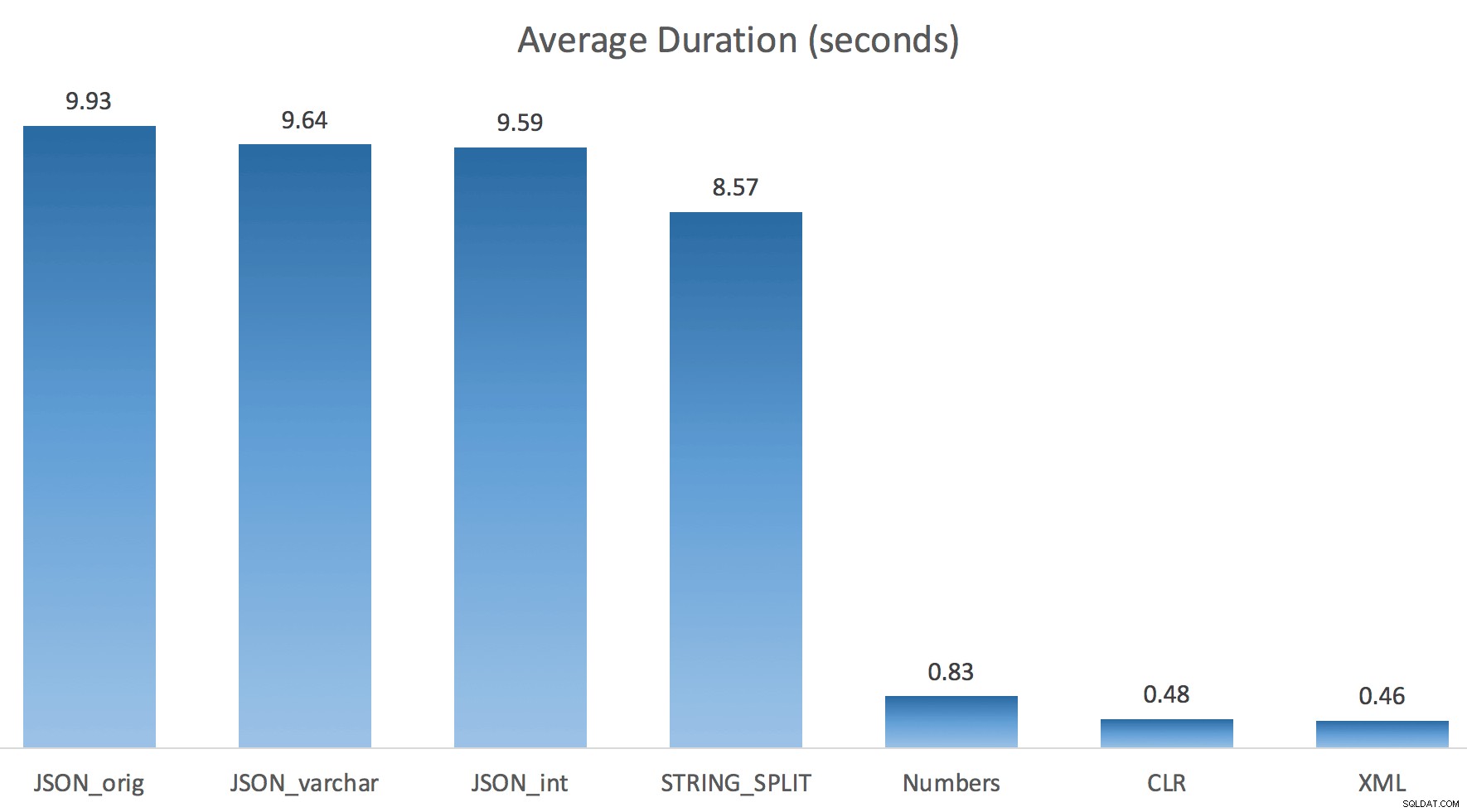
ここでは、JSONとSTRING_SPLIT メソッドはそれぞれ約10秒かかりましたが、Numbersテーブル、CLR、およびXMLアプローチは1秒未満で完了しました。困惑して、私は待機を調査しました、そして確かに、左側の4つのメソッドは重大なLATCH_EXを被りました 他の3つには見られない待機(約25秒)があり、他に重要な待機はありませんでした。
また、ラッチの待機時間が合計時間よりも長いため、これが並列処理に関係していることがわかりました(この特定のマシンには4つのコアがあります)。そこで、テストコードを再度生成し、並列処理なしで何が起こるかを確認するために1行だけ変更しました。
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
今STRING_SPLIT (JSONメソッドと同様に)はるかにうまくいきましたが、それでもCLRにかかる時間は少なくとも2倍になります:
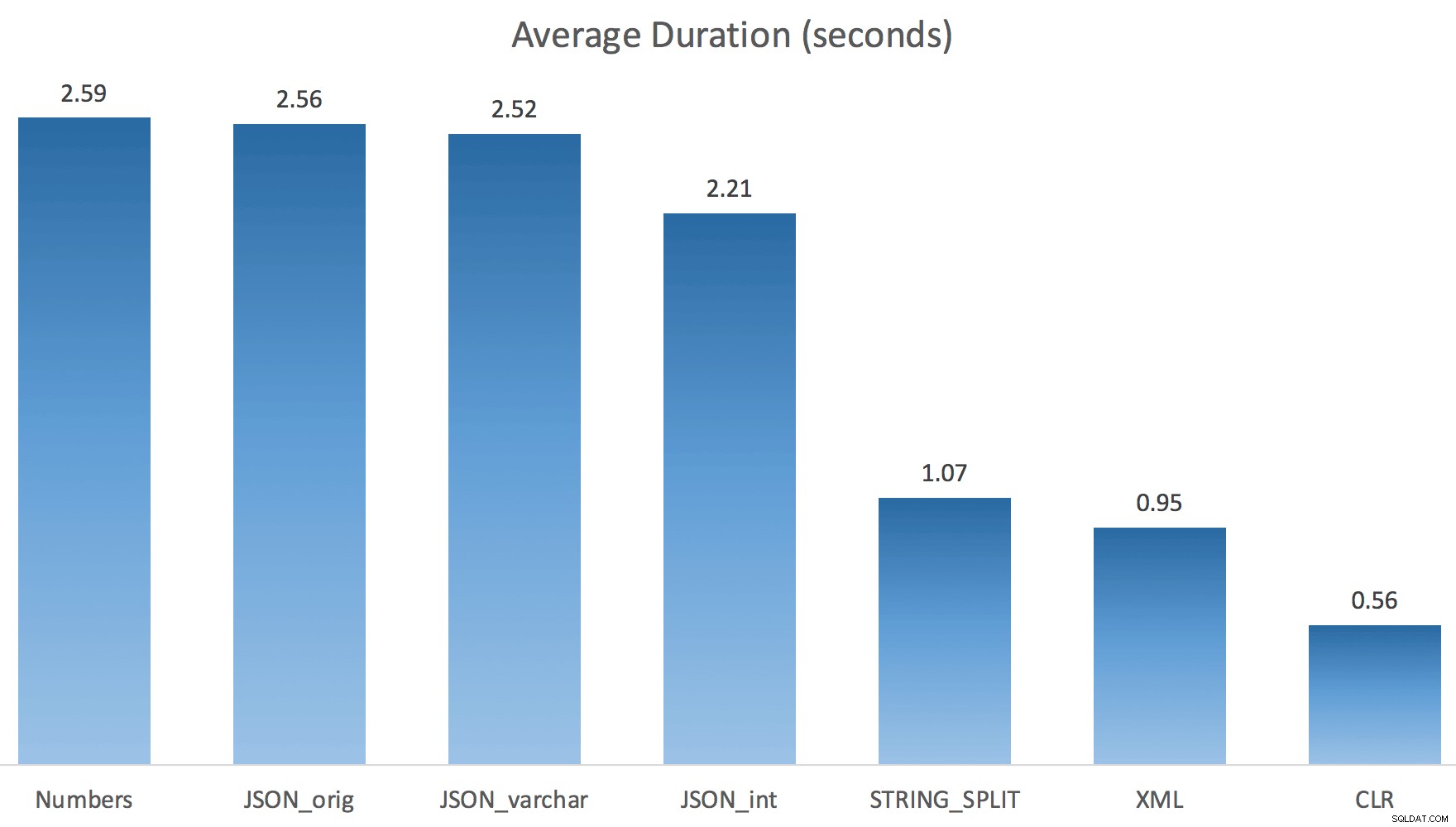
したがって、並列処理が含まれる場合、これらの新しいメソッドには問題が残っている可能性があります。これはスレッド配布の問題ではなく(私はそれを確認しました)、CLRの見積もりは実際にはもっと悪いものでした(STRING_SPLITの場合は実際の100倍対わずか5倍) );私が思うスレッド間でラッチを調整することに関するいくつかの根本的な問題。今のところ、MAXDOP 1を使用する価値があるかもしれません 出力を新しいページに書き込んでいることがわかっている場合。
並列実行とシリアル実行の両方について、CLRアプローチをネイティブアプローチと比較するグラフィカルプランを含めました(SQL Sentryプランエクスプローラーで開いて自分でスヌープできるクエリ分析ファイルもアップロードしました):
STRING_SPLIT
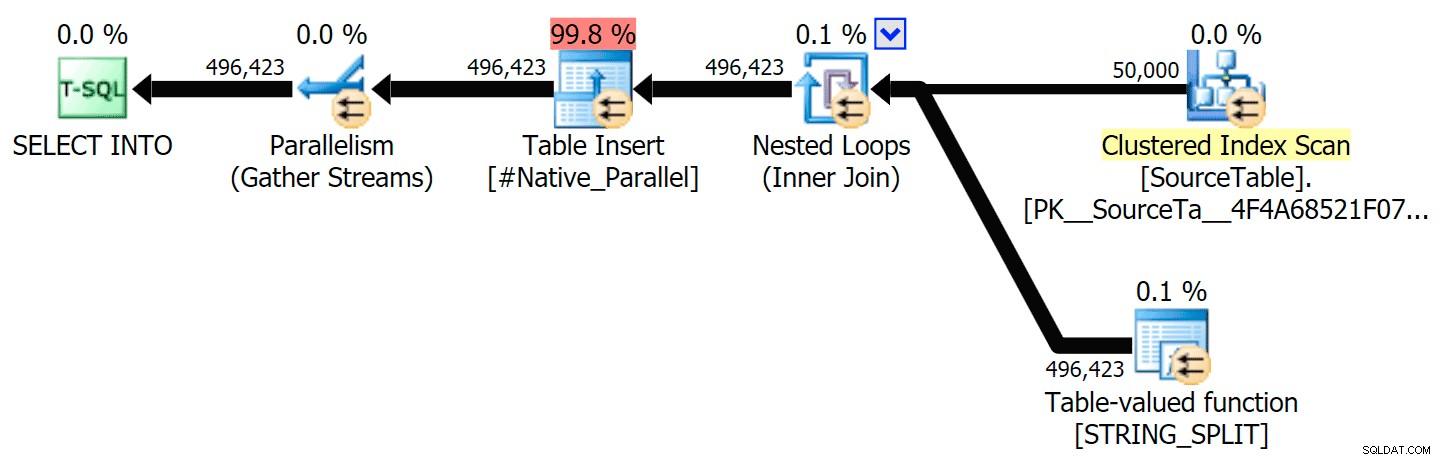
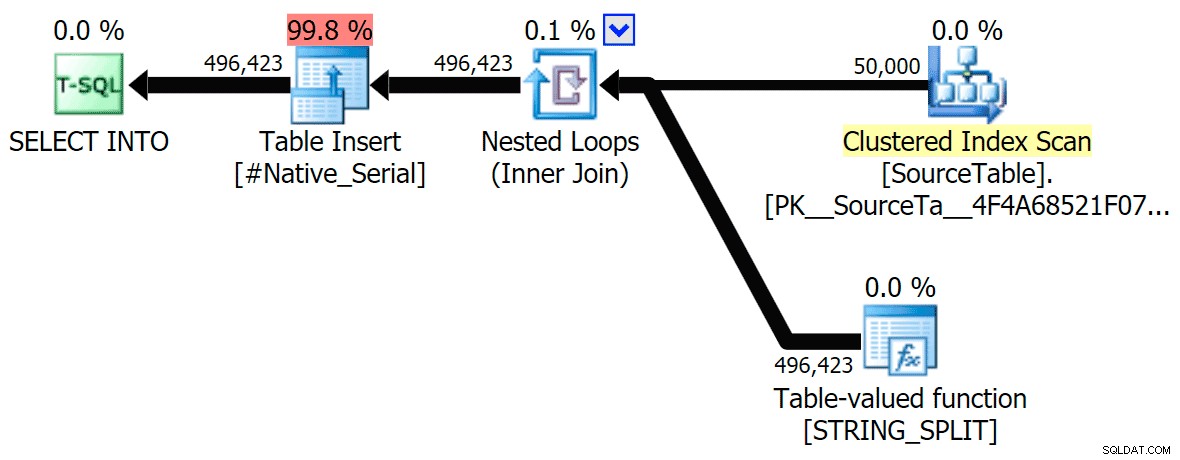
CLR
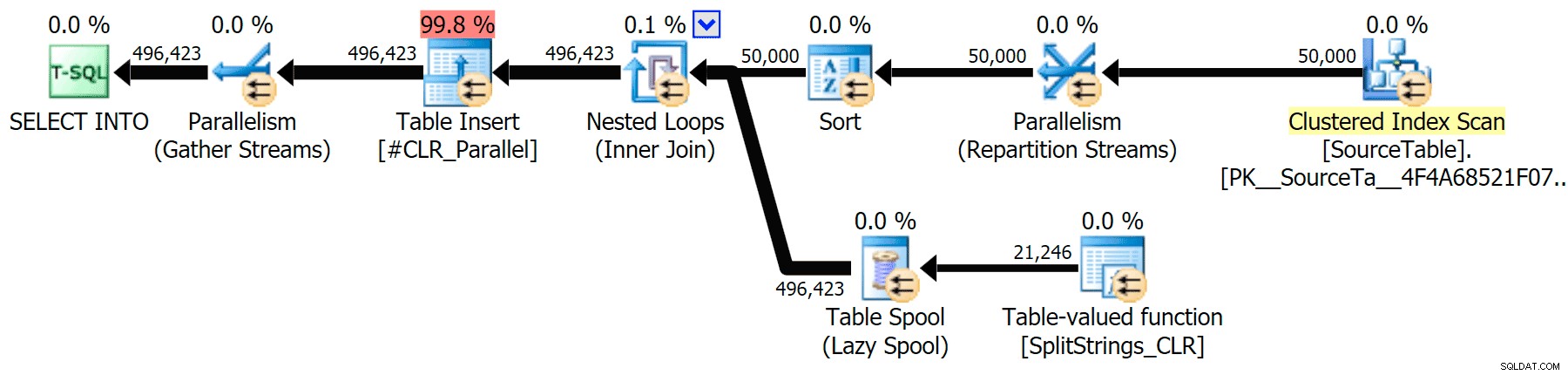
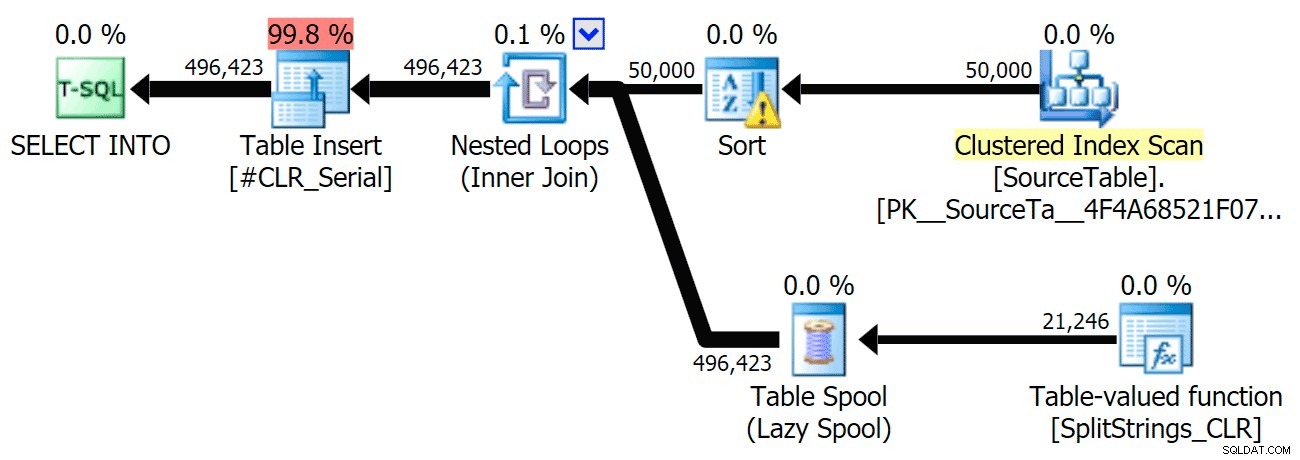
並べ替えの警告であるFYIは、それほど衝撃的なものではなく、明らかにクエリ期間に大きな影響を与えることはありませんでした。

- StringSplit.queryanalysis.zip(25kb)
夏に向けてスプールアウト
それらの計画をもう少し詳しく見てみると、CLR計画に怠惰なスプールがあることに気づきました。これは、複製が一緒に処理されるようにするために導入されました(実際の分割を少なくして作業を節約するため)が、このスプールはすべての平面形状で常に可能であるとは限らず、それを使用できる人に少し利点を与えることができます(見積もりに応じて、CLRプランなど)。スプールなしで比較するために、トレースフラグ8690を有効にして、テストを再実行しました。まず、スプールなしの並列CLRプランは次のとおりです。
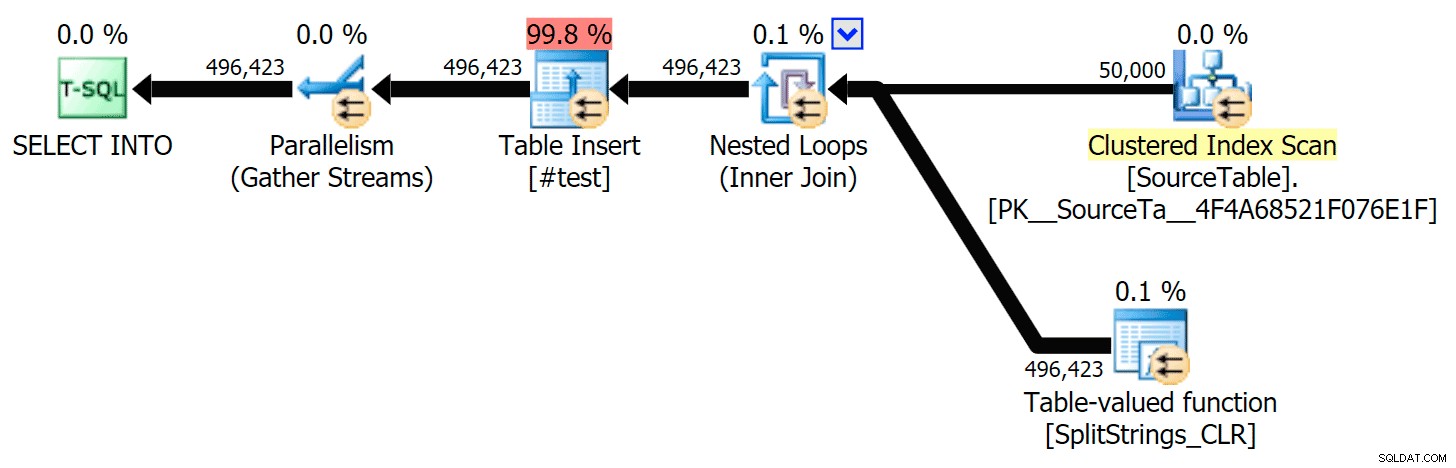
そして、TF8690を有効にして並行して実行されるすべてのクエリの新しい期間は次のとおりです。
さて、これがスプールなしのシリアルCLRプランです:
そして、TF8690とMAXDOP 1の両方を使用したクエリのタイミング結果は次のとおりです。 :
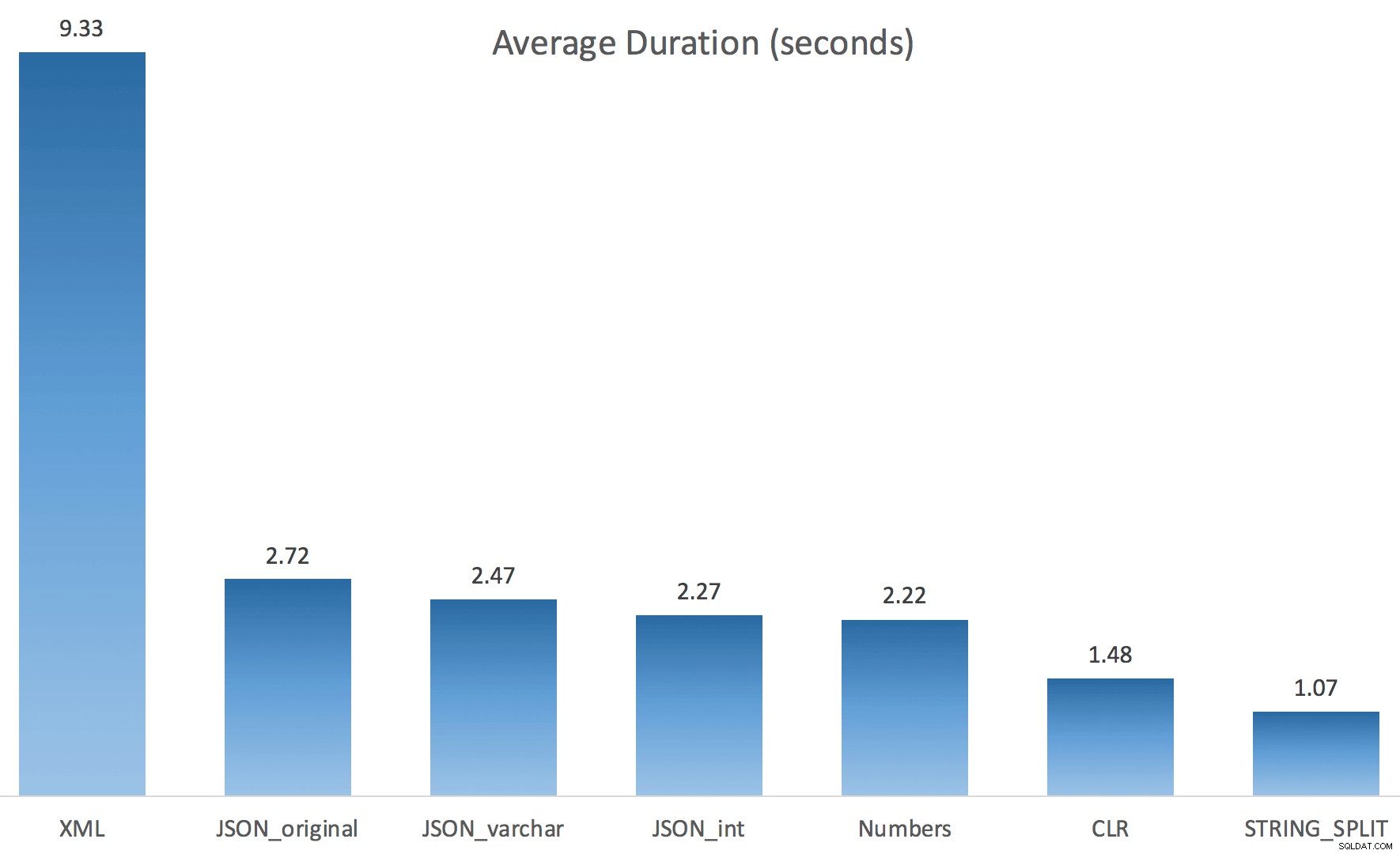
(XMLプランを除いて、トレースフラグの有無にかかわらず、他のほとんどはまったく変更されていないことに注意してください。)
推定行数の比較
ダンホームズは次の質問をしました:
別の(または複数の)分割関数に結合された場合、データサイズをどのように推定しますか?以下のリンクは、CLRベースの分割実装の記述です。 2016年はデータ推定で「より良い」仕事をしますか? (残念ながら、RCをインストールする機能はまだありません。)https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and。 html
そこで、Danの投稿からコードをスワイプし、関数を使用するようにコードを変更して、プランエクスプローラーで実行しました:
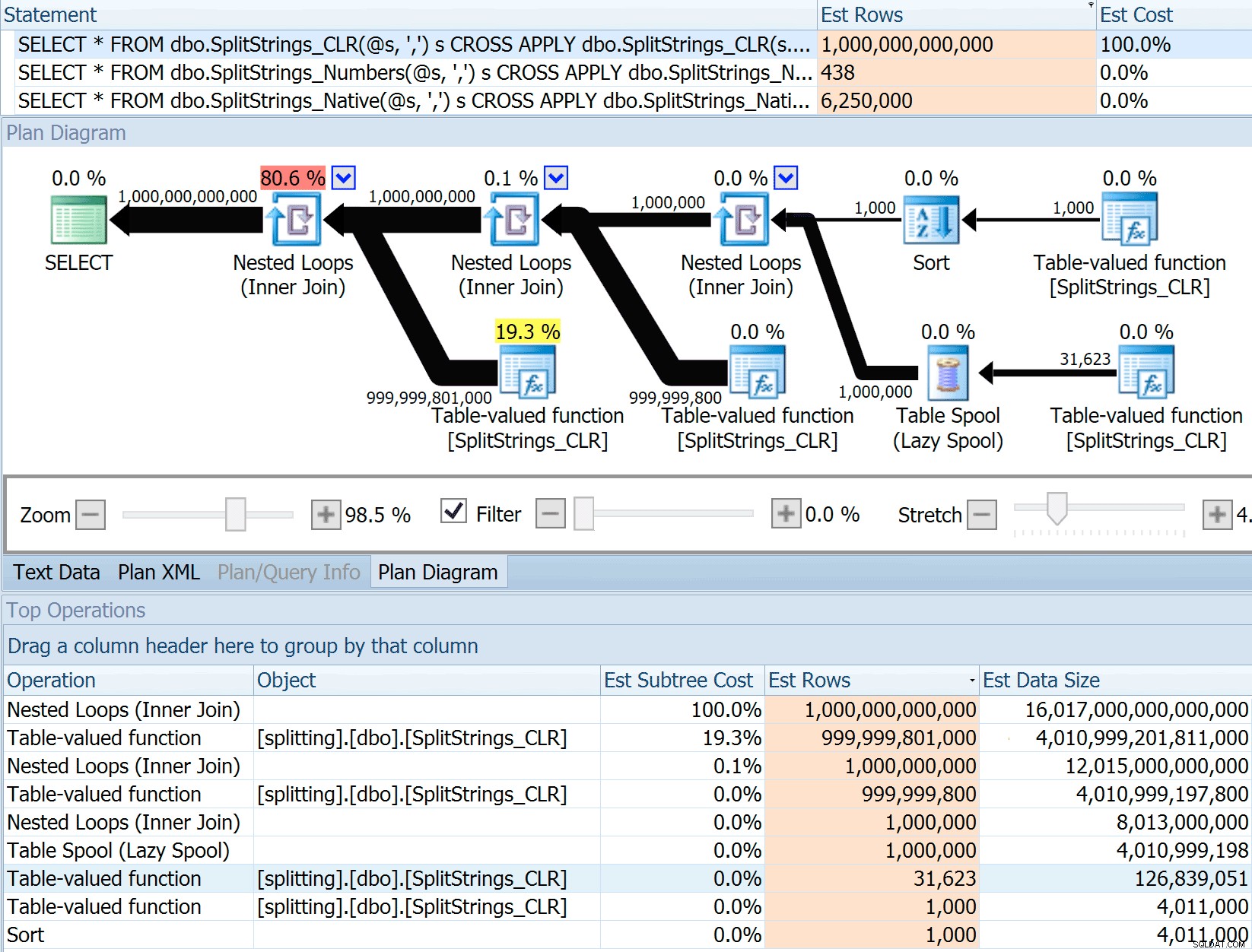
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING アプローチは確かにCLRよりも*優れた*見積もりを出しますが、それでも大幅に終わります(この場合、文字列が空の場合。これが常に当てはまるとは限りません)。この関数には、着信文字列に50個の要素があると推定する組み込みのデフォルトがあるため、それらをネストすると、50 x 50(2,500)になります。それらを再度ネストすると、50 x 2,500(125,000)になります。そして最後に、50 x 125,000(6,250,000):
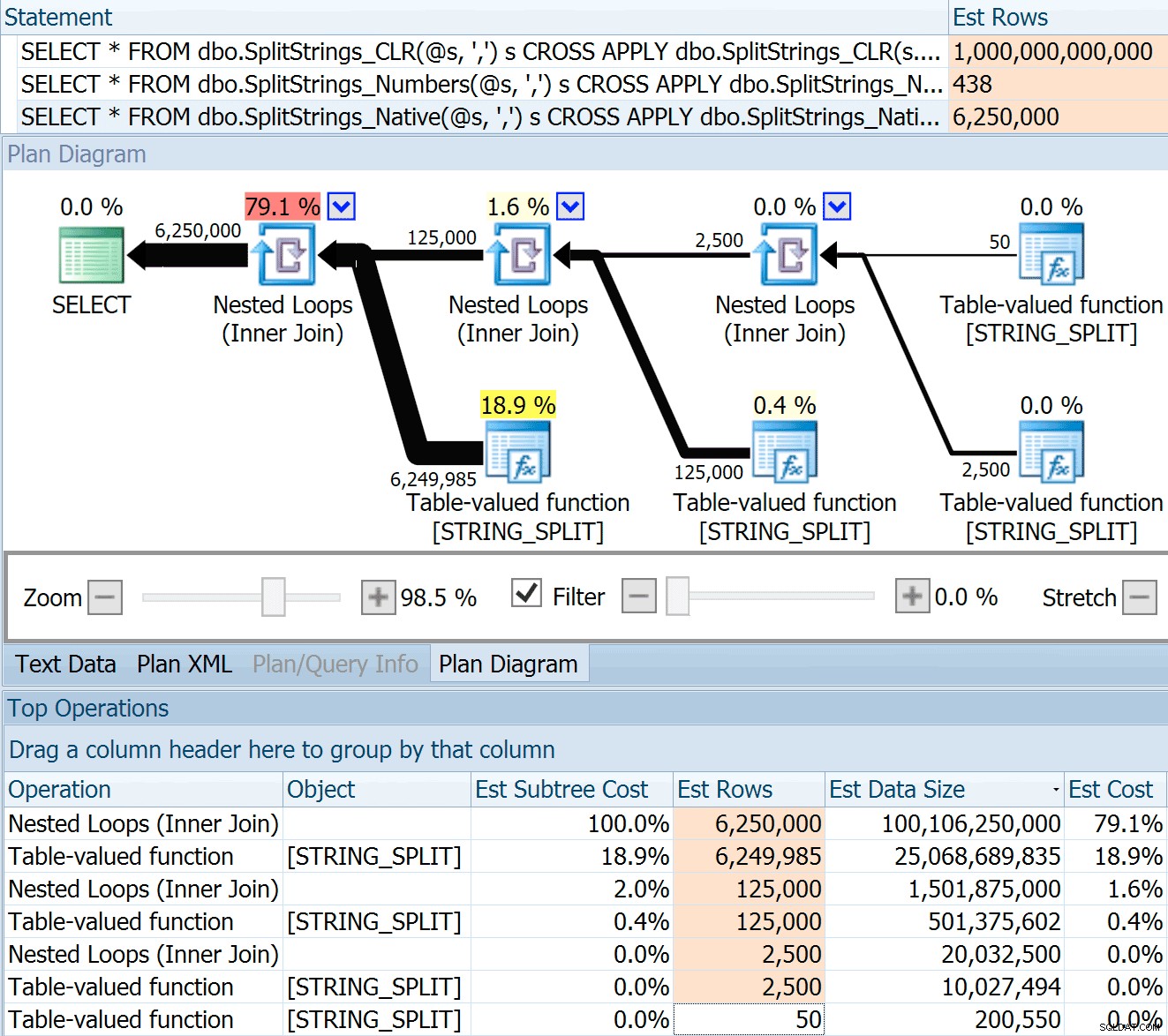
注:OPENJSON() STRING_SPLITとまったく同じように動作します –これも、特定の分割操作から50行が出力されることを前提としています。 4137(2014年以前)、9471&9472(2014+)、そしてもちろん9481のようなトレースフラグに加えて、このような関数のカーディナリティを示唆する方法があると便利だと思います…
この625万行の見積もりは素晴らしいものではありませんが、Danが話していた A TRILLION ROWSを見積もるCLRアプローチよりもはるかに優れています。 、およびデータサイズを決定するためのコンマの数を失いました– 16ペタバイト? exabytes?
他のアプローチのいくつかは、見積もりの点で明らかにうまくいきます。たとえば、Numbersテーブルは、はるかに妥当な438行を推定しました(SQL Server 2016 RC2の場合)。この番号はどこから来たのですか?テーブルには8,000行あります。覚えていると思いますが、この関数には等式と不等式の両方の述語があります。
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter したがって、SQL Serverは、テーブル内の行数に(推測として)10%を掛けて、等式フィルターを作成し、次に平方根を掛けます。 不等式フィルターの場合は30%(これも推測です)。平方根は指数バックオフによるもので、PaulWhiteがここで説明しています。これにより、次のことが可能になります:
8000 * 0.1 * SQRT(0.3)=438.178XMLのバリエーションは10億行強と推定されましたが(テーブルスプールは580万回実行されると推定されたため)、その計画は複雑すぎてここで説明することはできませんでした。いずれにせよ、見積もりが全体像を明らかにしているわけではないことを忘れないでください。クエリの見積もりがより正確であるからといって、パフォーマンスが向上するとは限りません。
見積もりを少し調整する方法は他にもいくつかありました。つまり、古いカーディナリティ見積もりモデル(XMLとNumbersテーブルのバリエーションの両方に影響を与える)を強制する方法と、TF 9471と9472(Numbersテーブルのバリエーションのみに影響を与える)を使用する方法です。それらは両方とも、複数の述語の周りのカーディナリティを制御します)。見積もりを少しだけ変更する方法は次のとおりです(または A LOT 、古いCEモデルに戻す場合):

古いCEモデルでは、XMLの見積もりが桁違いに減少しましたが、Numbersテーブルの場合は完全に爆発しました。述語フラグはNumbersテーブルの見積もりを変更しましたが、これらの変更はそれほど興味深いものではありません。
これらのトレースフラグはいずれも、CLR、JSON、またはSTRING_SPLITの見積もりに影響を与えませんでした。 バリエーション。
結論
それで私はここで何を学びましたか?実際には、たくさんあります:
- 並列処理が役立つ場合もありますが、役に立たない場合は、本当に 助けにはなりません。 JSONメソッドは、並列処理なしで最大5倍高速であり、
STRING_SPLITほぼ10倍高速でした。 - この場合、スプールは実際にCLRアプローチのパフォーマンスを向上させるのに役立ちましたが、TF 8690は、スプールが表示されてパフォーマンスを向上させようとしている他のケースで実験するのに役立つ場合があります。スプールをなくすと全体的に良くなる状況があると確信しています。
- スプールを削除すると、XMLアプローチが実際に損なわれます(ただし、シングルスレッドを強制された場合にのみ大幅に影響を受けます)。
- 通常の統計、分布、トレースフラグに加えて、アプローチに応じた見積もりでは、多くのファンキーなことが発生する可能性があります。まあ、私はすでにそれを知っていたと思いますが、ここには確かにいくつかの良い、具体的な例があります。
質問をしたり、より多くの情報を含めるように私に勧めてくれた人々に感謝します。タイトルからお察しのとおり、2回目のフォローアップで、TVPに関するもう1つの質問に答えます。
- SQL Server 2016のSTRING_SPLIT():フォローアップ#2