この記事では、初心者の開発者がT-SQLコードを設計するときに直面する可能性のある一般的なエラーについて説明します。さらに、SQL Serverを使用する際に役立つ可能性のあるベストプラクティスといくつかの役立つヒント、およびパフォーマンスを向上させるための回避策についても説明します。
内容:
1.データ型
2。 *
3。エイリアス
4。列の順序
5。 NOT IN vs NULL
6。日付形式
7。日付フィルター
8。計算
9。暗黙的に変換する
10。 LIKE&Suppressed index
11。 UnicodeとANSI
12。 COLLATE
13。バイナリコレート
14。コードスタイル
15。 [var] char
16。データ長
17。 ISNULL vs COALESCE
18。数学
19。 UNION vs UNION ALL
20。再読
21。サブクエリ
22。場合
23。スカラー機能
24。ビュー
25。カーソル
26。 STRING_CONCAT
27。 SQLインジェクション
データ型
SQL Serverを使用するときに直面する主な問題は、データ型の誤った選択です。
2つの同一のテーブルがあると仮定します:
DECLARE @Employees1 TABLE (
EmployeeID BIGINT PRIMARY KEY
, IsMale VARCHAR(3)
, BirthDate VARCHAR(20)
)
INSERT INTO @Employees1
VALUES (123, 'YES', '2012-09-01')
DECLARE @Employees2 TABLE (
EmployeeID INT PRIMARY KEY
, IsMale BIT
, BirthDate DATE
)
INSERT INTO @Employees2
VALUES (123, 1, '2012-09-01') クエリを実行して、違いを確認しましょう。
DECLARE @BirthDate DATE = '2012-09-01' SELECT * FROM @Employees1 WHERE BirthDate = @BirthDate SELECT * FROM @Employees2 WHERE BirthDate = @BirthDate
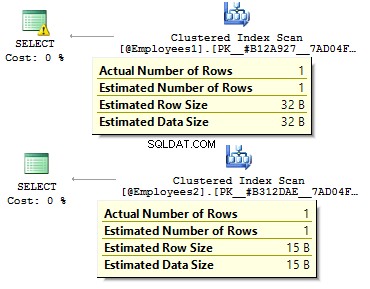
最初のケースでは、データ型は実際よりも冗長です。ビット値をYES/ NOとして保存する必要があるのはなぜですか 行?なぜ日付を行として保存する必要があるのですか?なぜBIGINTを使用する必要があるのですか INT ではなく、テーブル内の従業員の場合 ?
次の欠点があります。
- テーブルはディスク上で多くのスペースを占める可能性があります;
- より多くのページを読み取り、より多くのデータを BufferPoolに配置する必要があります データを処理します。
- パフォーマンスが悪い。
*
開発者がテーブルからすべてのデータを取得し、クライアント側で DataReaderを使用するという状況に直面しました。 必須フィールドのみを選択します。このアプローチの使用はお勧めしません:
USE AdventureWorks2014
GO
SET STATISTICS TIME, IO ON
SELECT *
FROM Person.Person
SELECT BusinessEntityID
, FirstName
, MiddleName
, LastName
FROM Person.Person
SET STATISTICS TIME, IO OFF クエリの実行時間には大きな違いがあります。さらに、カバーリングインデックスにより、論理読み取りの数が減る可能性があります。
Table 'Person'. Scan count 1, logical reads 3819, physical reads 3, ... SQL Server Execution Times: CPU time = 31 ms, elapsed time = 1235 ms. Table 'Person'. Scan count 1, logical reads 109, physical reads 1, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 227 ms.
エイリアス
テーブルを作成しましょう:
USE AdventureWorks2014
GO
IF OBJECT_ID('Sales.UserCurrency') IS NOT NULL
DROP TABLE Sales.UserCurrency
GO
CREATE TABLE Sales.UserCurrency (
CurrencyCode NCHAR(3) PRIMARY KEY
)
INSERT INTO Sales.UserCurrency
VALUES ('USD') 両方のテーブルの同じ行の量を返すクエリがあるとします。
SELECT COUNT_BIG(*)
FROM Sales.Currency
WHERE CurrencyCode IN (
SELECT CurrencyCode
FROM Sales.UserCurrency
) Sales.UserCurrency の列の名前を誰かが変更するまで、すべてが期待どおりに機能します。 テーブル:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
次に、クエリを実行して、 Sales.Currencyのすべての行を取得することを確認します。 1行ではなくテーブル。実行プランを作成するとき、バインディングステージで、SQLServerはSales.UserCurrency、の列をチェックします。 CurrencyCodeは見つかりません そこで、この列が Sales.Currencyに属すると判断します。 テーブル。その後、オプティマイザは CurrencyCode =CurrencyCodeを削除します 状態。
したがって、エイリアスを使用することをお勧めします:
SELECT COUNT_BIG(*)
FROM Sales.Currency c
WHERE c.CurrencyCode IN (
SELECT u.CurrencyCode
FROM Sales.UserCurrency u
) 列の順序
テーブルがあると仮定します:
IF OBJECT_ID('dbo.DatePeriod') IS NOT NULL
DROP TABLE dbo.DatePeriod
GO
CREATE TABLE dbo.DatePeriod (
StartDate DATE
, EndDate DATE
) 列の順序に関する情報に基づいて、常にそこにデータを挿入します。
INSERT INTO dbo.DatePeriod SELECT '2015-01-01', '2015-01-31'
誰かが列の順序を変更したと仮定します:
CREATE TABLE dbo.DatePeriod (
EndDate DATE
, StartDate DATE
) データは別の順序で挿入されます。この場合、INSERTステートメントで列を明示的に指定することをお勧めします。
INSERT INTO dbo.DatePeriod (StartDate, EndDate) SELECT '2015-01-01', '2015-01-31'
別の例を次に示します。
SELECT TOP(1) * FROM dbo.DatePeriod ORDER BY 2 DESC
どの列でデータを注文しますか?これは、テーブルの列の順序によって異なります。順序を変更すると、間違った結果が得られます。
NOT IN vs NULL
NOT INについて話しましょう ステートメント。
たとえば、いくつかのクエリを作成する必要があります。最初のテーブルからレコードを返します。これは、2番目のテーブルとビザの詩には存在しません。通常、ジュニア開発者は INを使用します およびNOTIN :
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1)) INSERT INTO @t1 VALUES (1), (2) DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2)) INSERT INTO @t2 VALUES (1) SELECT * FROM @t1 WHERE t1 NOT IN (SELECT t2 FROM @t2) SELECT * FROM @t1 WHERE t1 IN (SELECT t2 FROM @t2)
最初のクエリは2を返し、2番目のクエリは1を返しました。さらに、2番目のテーブルに別の値を追加します– NULL :
INSERT INTO @t2 VALUES (1), (NULL)
NOT INでクエリを実行する場合 、結果は得られません。なぜINは機能し、そうではないのですか?その理由は、SQLServerがT RUEを使用しているためです。 、 FALSE 、および不明 データを比較するときのロジック。
クエリを実行すると、SQLServerはIN条件を次のように解釈します。
a IN (1, NULL) == a=1 OR a=NULL
NOT IN :
a NOT IN (1, NULL) == a<>1 AND a<>NULL
値をNULLと比較する場合、 SQLServerはUNKNOWNを返します。 1 =NULL またはNULL=NULL – どちらも不明になります。 式にANDが含まれている限り、両側でUNKNOWNが返されます。
このケースは珍しいことではないことを指摘したいと思います。たとえば、列をNOTNULLとしてマークします。 しばらくして、別の開発者が NULLsを許可することにしました。 その列。これにより、テーブルにNULL値が挿入されると、クライアントレポートが機能しなくなるという状況が発生する可能性があります。
この場合、NULL値を除外することをお勧めします:
SELECT *
FROM @t1
WHERE t1 NOT IN (
SELECT t2
FROM @t2
WHERE t2 IS NOT NULL
) また、 EXCEPTを使用することもできます :
SELECT * FROM @t1 EXCEPT SELECT * FROM @t2
または、 NOT EXISTSを使用することもできます :
SELECT *
FROM @t1
WHERE NOT EXISTS(
SELECT 1
FROM @t2
WHERE t1 = t2
) どちらのオプションがより好ましいですか? 存在しないの後者のオプション より最適な述語プッシュダウンを生成するため、最も生産的であるように思われます。 2番目のテーブルのデータにアクセスするための演算子。
実際には、NULL値は予期しない結果を返す可能性があります。
この特定の例で考えてみてください:
USE AdventureWorks2014 GO SELECT COUNT_BIG(*) FROM Production.Product SELECT COUNT_BIG(*) FROM Production.Product WHERE Color = 'Grey' SELECT COUNT_BIG(*) FROM Production.Product WHERE Color <> 'Grey'
ご覧のとおり、NULL値には個別の比較演算子があるため、期待した結果が得られていません。
SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NULL SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NOT NULL
CHECKを使用した別の例を次に示します。 制約:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (
Color VARCHAR(15) --NULL
, CONSTRAINT CK CHECK (Color IN ('Black', 'White'))
) 白と黒の色のみを挿入する権限を持つテーブルを作成します:
INSERT INTO #temp VALUES ('Black')
(1 row(s) affected) すべてが期待どおりに機能します。
INSERT INTO #temp VALUES ('Red')
The INSERT statement conflicted with the CHECK constraint...
The statement has been terminated. それでは、NULLを追加しましょう:
INSERT INTO #temp VALUES (NULL) (1 row(s) affected)
CHECK制約がNULL値を渡したのはなぜですか?ええと、その理由は、偽りではないが十分にあるからです。 レコードを作成するための条件。回避策は、列を NOT NULLとして明示的に定義することです。 または、制約でNULLを使用します。
日付形式
多くの場合、データ型に問題がある可能性があります。
たとえば、現在の日付を取得する必要があります。これを行うには、GETDATE関数を使用できます:
SELECT GETDATE()
次に、返された結果を必要なクエリにコピーし、時間を削除します。
SELECT * FROM sys.objects WHERE create_date < '2016-11-14'
それは正しいですか?
日付は文字列定数で指定されます:
SET LANGUAGE English
SET DATEFORMAT DMY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4 すべての値には1つの値の解釈があります:
----------- ----------- ----------- ----------- 2016-12-05 2016-05-12 2016-05-12 2016-12-05
このビジネスロジックを使用したクエリが、設定が異なる可能性のある別のサーバーで実行されるまで、問題は発生しません。
SET DATEFORMAT MDY
DECLARE @d1 DATETIME = '05/12/2016'
, @d2 DATETIME = '2016/12/05'
, @d3 DATETIME = '2016-12-05'
, @d4 DATETIME = '05-dec-2016'
SELECT @d1, @d2, @d3, @d4 ただし、これらのオプションは日付の誤った解釈につながる可能性があります:
----------- ----------- ----------- ----------- 2016-05-12 2016-12-05 2016-12-05 2016-12-05
さらに、このコードは目に見えるバグと潜在的なバグの両方につながる可能性があります。
次の例を考えてみましょう。テストテーブルにデータを挿入する必要があります。テストサーバーでは、すべてが完璧に機能します:
DECLARE @t TABLE (a DATETIME)
INSERT INTO @t VALUES ('05/13/2016') それでも、クライアント側では、サーバー設定が異なるため、このクエリには問題があります。
DECLARE @t TABLE (a DATETIME)
SET DATEFORMAT DMY
INSERT INTO @t VALUES ('05/13/2016') Msg 242, Level 16, State 3, Line 28 The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
したがって、日付定数を宣言するためにどの形式を使用する必要がありますか?この質問に答えるには、次のクエリを実行します:
SET DATEFORMAT YMD
SET LANGUAGE English
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
GO
SET LANGUAGE Deutsch
DECLARE @d1 DATETIME = '2016/01/12'
, @d2 DATETIME = '2016-01-12'
, @d3 DATETIME = '12-jan-2016'
, @d4 DATETIME = '20160112'
SELECT @d1, @d2, @d3, @d4
定数の解釈は、インストールされている言語によって異なる場合があります:
----------- ----------- ----------- -----------
2016-01-12 2016-01-12 2016-01-12 2016-01-12
----------- ----------- ----------- -----------
2016-12-01 2016-12-01 2016-01-12 2016-01-12 したがって、最後の2つのオプションを使用することをお勧めします。また、日付を明示的に指定することはお勧めできません。
SET LANGUAGE French DECLARE @d DATETIME = '12-jan-2016' Msg 241, Level 16, State 1, Line 29 Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
したがって、日付の定数を正しく解釈する場合は、次の形式で指定する必要がありますYYYYMMDD。
さらに、いくつかのデータ型の動作に注意を向けたいと思います:
SET LANGUAGE English
SET DATEFORMAT YMD
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2
GO
SET LANGUAGE Deutsch
SET DATEFORMAT DMY
DECLARE @d1 DATE = '2016-01-12'
, @d2 DATETIME = '2016-01-12'
SELECT @d1, @d2 DATETIMEとは異なり、 DATE タイプはサーバーのさまざまな設定で正しく解釈されます:
---------- ---------- 2016-01-12 2016-01-12 ---------- ---------- 2016-01-12 2016-12-01
日付フィルター
次に、データを効果的にフィルタリングする方法を検討します。それらから始めましょうDATETIME/DATE:
USE AdventureWorks2014 GO UPDATE TOP(1) dbo.DatabaseLog SET PostTime = '20140716 12:12:12'
次に、クエリが指定された日に返す行数を調べます。
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime = '20140716'
クエリは0を返します。実行プランを作成するときに、SQLサーバーは、フィルターで除外する必要のある列のデータ型に文字列定数をキャストしようとしています。
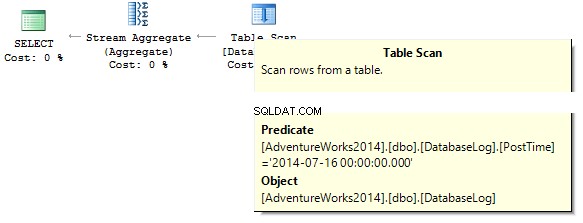
インデックスを作成します:
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)
データを出力するための正しいオプションと正しくないオプションがあります。たとえば、時間列を削除する必要があります:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CAST(PostTime AS DATE) = '20140716'
または、範囲を指定する必要があります:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140716' AND PostTime < '20140717'>
最適化を考慮すると、これら2つのクエリが最も正しいクエリであると言えます。重要なのは、フィルターで除外されているインデックス列のすべての変換と計算により、パフォーマンスが大幅に低下し、ロジック読み取りの時間が長くなる可能性があるということです。
Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 2, ...
PostTime フィールドは以前はインデックスに含まれていなかったため、フィルタリングでこの正しいアプローチを使用しても効率は見られませんでした。もう1つは、1か月分のデータを出力する必要がある場合です。
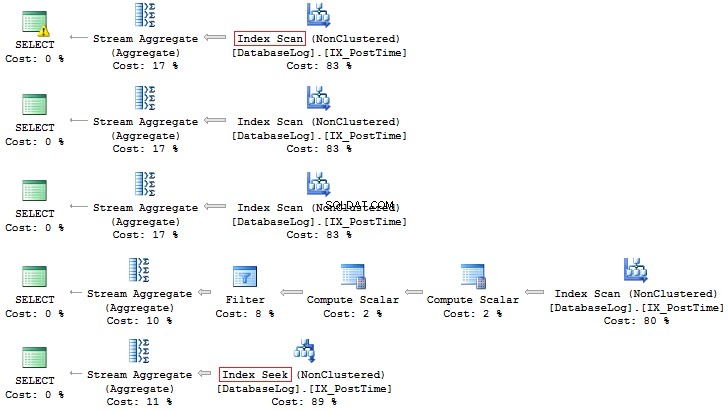
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE DATEPART(YEAR, PostTime) = 2014
AND DATEPART(MONTH, PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE YEAR(PostTime) = 2014
AND MONTH(PostTime) = 7
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE EOMONTH(PostTime) = '20140731'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801' 繰り返しますが、後者のオプションの方が適しています:
さらに、計算フィールドに基づいていつでもインデックスを作成できます:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL
ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDay
GO
ALTER TABLE dbo.DatabaseLog
ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED
GO
CREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay) 前のクエリと比較すると、論理的な読み取り値の違いが重要になる可能性があります(大きなテーブルが問題になっている場合):
SET STATISTICS IO ON SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140701' AND PostTime < '20140801' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE MonthLastDay = '20140731' SET STATISTICS IO OFF Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 3, ...
計算
すでに説明したように、インデックス列の計算はパフォーマンスを低下させ、ロジック読み取りの時間を増やします。
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID * 2 = 10000 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 2500 * 2 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 5000 Table 'Person'. Scan count 1, logical reads 67, ... Table 'Person'. Scan count 0, logical reads 3, ...
実行プランを見ると、最初のプランでは、SQLServerがIndexScanを実行します。 :
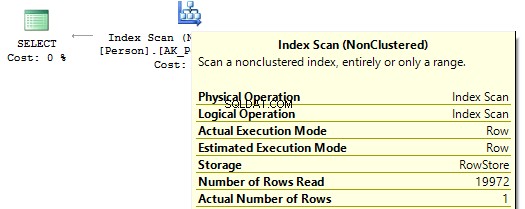
次に、インデックス列に計算がない場合、 IndexSeekが表示されます。 :

暗黙的に変換
同じ値でフィルタリングする次の2つのクエリを見てみましょう。
USE AdventureWorks2014 GO SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = 30845 SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = '30845'
実行計画は次の情報を提供します:
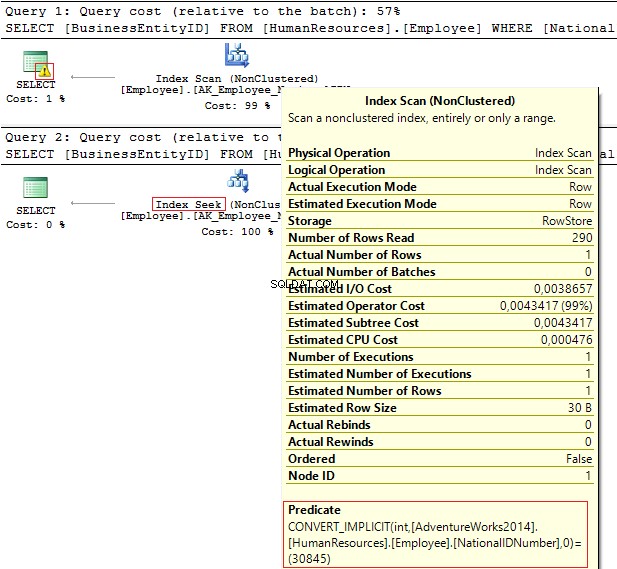
- 警告とIndexScan 最初の計画で
- IndexSeek – 2番目のものに。
Table 'Employee'. Scan count 1, logical reads 4, ... Table 'Employee'. Scan count 0, logical reads 2, ...
NationalIDNumber 列にはNVARCHAR(15)があります データ・タイプ。データを除外するために使用する定数は、 INTとして設定されます。 これにより、暗黙的なデータ型変換が行われます。その結果、パフォーマンスが低下する可能性があります。誰かが列のデータ型を変更したときに監視できますが、クエリは変更されません。
暗黙的なデータ型変換は実行時にエラーを引き起こす可能性があることを理解することが重要です。たとえば、PostalCodeフィールドが数値になる前は、郵便番号に文字を含めることができることが判明しました。したがって、データ型が更新されました。それでも、アルファベットの郵便番号を挿入すると、古いクエリは機能しなくなります:
SELECT AddressID FROM Person.[Address] WHERE PostalCode = 92700 SELECT AddressID FROM Person.[Address] WHERE PostalCode = '92700' Msg 245, Level 16, State 1, Line 16 Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.
もう1つの例は、 EntityFrameworkを使用する必要がある場合です。 プロジェクトでは、デフォルトですべての行フィールドがUnicodeとして解釈されます:
SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = N'AW00000009' SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = 'AW00000009'
したがって、誤ったクエリが生成されます:

この問題を解決するには、データ型が一致していることを確認してください。
LIKE&Suppressed index
実際、カバーリングインデックスがあるからといって、それを効果的に使用できるわけではありません。
この特定の例で確認してみましょう。で始まるすべての行を出力する必要があると仮定します…
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT AddressLine1 FROM Person.[Address] WHERE SUBSTRING(AddressLine1, 1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE LEFT(AddressLine1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE CAST(AddressLine1 AS CHAR(3)) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '100%'
次のロジックの読み取りと実行計画を取得します。
Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 4, ...
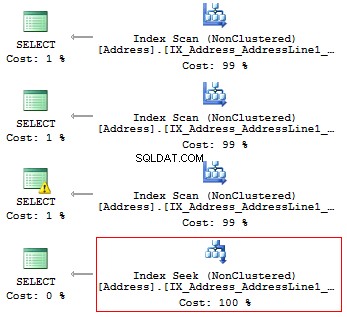
したがって、インデックスがある場合は、タイプや関数などの計算や変換を含めることはできません。
しかし、文字列内の部分文字列の出現を見つける必要がある場合はどうしますか?
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'v
後でこの質問に戻ります。
ユニコードとANSI
UNICODEがあることを覚えておくことが重要です。 およびANSI 文字列。 UNICODEタイプにはNVARCHAR/ NCHARが含まれます (1つのシンボルに対して2バイト)。 ANSIを保存するには 文字列の場合、 VARCHAR / CHARを使用できます。 (1バイトから1シンボル)。 TEXT / NTEXTもあります 、ただし、パフォーマンスが低下する可能性があるため、使用しないことをお勧めします。
クエリでUnicode定数を指定する場合は、その前にN記号を付ける必要があります。確認するには、次のクエリを実行します。
SELECT '文本 ANSI'
, N'文本 UNICODE'
------- ------------
?? ANSI 文本 UNICODE Nが定数の前にない場合、SQLServerはANSIコーディングで適切な記号を見つけようとします。見つからない場合は、疑問符が表示されます。
照合
非常に多くの場合、ミドル/シニアDB開発者のポジションに面接されると、面接官は次の質問をすることがよくあります。このクエリはデータを返しますか?
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b 場合によります。まず、N記号は文字列定数の前にないため、ANSIとして解釈されます。次に、文字列データを選択して比較する場合、ルールのセットである現在のCOLLATE値に大きく依存します。
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CI_AS
GO
USE test
GO
DECLARE @a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @b このCOLLATEステートメントは、記号が等しいため、疑問符を返します。
---- ---- ? ?
COLLATEステートメントを別のステートメントに変更した場合:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
この場合、キリル文字は正しく解釈されるため、クエリは何も返しません。
したがって、文字列定数がUNICODEを使用する場合は、文字列定数の前にNを設定する必要があります。それでも、上記で説明した理由から、どこにでも設定することはお勧めしません。
インタビューで尋ねられるもう1つの質問は、行の比較です。
次の例を考えてみましょう:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a = @b, 'TRUE', 'FALSE') これらの行は等しいですか?これを確認するには、COLLATEを明示的に指定する必要があります:
DECLARE
@a VARCHAR(10) = 'TEXT'
, @b VARCHAR(10) = 'text'
SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE') 行を比較および選択するときに大文字と小文字を区別する(CS)COLLATEと大文字と小文字を区別しない(CI)COLLATEがあるため、それらが等しいかどうかはわかりません。さらに、テストサーバー側とクライアント側の両方にさまざまなCOLLATEがあります。
ターゲットベースとtempdbのCOLLATEが発生する場合があります 一致しません。
COLLATEを使用してデータベースを作成します:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Albanian_100_CS_AS
GO
USE test
GO
CREATE TABLE t (c CHAR(1))
INSERT INTO t VALUES ('a')
GO
IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL
DROP TABLE #t1
IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL
DROP TABLE #t2
IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL
DROP TABLE #t3
GO
CREATE TABLE #t1 (c CHAR(1))
INSERT INTO #t1 VALUES ('a')
CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)
INSERT INTO #t2 VALUES ('a')
SELECT c = CAST('a' AS CHAR(1))
INTO #t3
DECLARE @t TABLE (c VARCHAR(100))
INSERT INTO @t VALUES ('a')
SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation')
UNION ALL
SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')
UNION ALL
SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t
UNION ALL
SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1
UNION ALL
SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2
UNION ALL
SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3
UNION ALL
SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t テーブルを作成するとき、データベースからCOLLATEを継承します。 COLLATEを使用せずに構造を明示的に決定する最初の一時テーブルの唯一の違いは、 tempdbからCOLLATEを継承することです。 データベース。
------ -------------------------- tempdb Cyrillic_General_CI_AS test Albanian_100_CS_AS t Albanian_100_CS_AS #t1 Cyrillic_General_CI_AS #t2 Albanian_100_CS_AS #t3 Albanian_100_CS_AS @t Albanian_100_CS_AS
特定の例でCOLLATEが#t1と一致しない場合について説明します。
たとえば、COLLATEはケースを考慮しない場合があるため、データは正しく除外されません。
SELECT * FROM #t1 WHERE c = 'A'
または、異なるCOLLATEを使用してテーブルを接続するときに競合が発生する可能性があります:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c
テストサーバーではすべてが完全に機能しているようですが、クライアントサーバーではエラーが発生します:
Msg 468, Level 16, State 9, Line 93 Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.
これを回避するには、どこにでもハックを設定する必要があります:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c COLLATE database_default
バイナリコレート
次に、COLLATEを使用して利益を得る方法を説明します。
文字列に部分文字列が含まれる例を考えてみましょう:
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
このクエリを最適化し、実行時間を短縮することができます。
最初に、大きなテーブルを生成する必要があります:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CS_AS
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB)
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB)
GO
USE test
GO
CREATE TABLE t (
ansi VARCHAR(100) NOT NULL
, unicod NVARCHAR(100) NOT NULL
)
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO t
SELECT v, v
FROM (
SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '')
FROM E8
) t バイナリCOLLATEとインデックスを使用して計算列を作成します:
ALTER TABLE t
ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2
ALTER TABLE t
ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2
CREATE NONCLUSTERED INDEX ansi ON t (ansi)
CREATE NONCLUSTERED INDEX unicod ON t (unicod)
CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin)
CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin) ろ過プロセスを実行します:
SET STATISTICS TIME, IO ON SELECT COUNT_BIG(*) FROM t WHERE ansi LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE unicod LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SELECT COUNT_BIG(*) FROM t WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SET STATISTICS TIME, IO OFF
ご覧のとおり、このクエリは次の結果を返します。
SQL Server Execution Times: CPU time = 350 ms, elapsed time = 354 ms. SQL Server Execution Times: CPU time = 335 ms, elapsed time = 355 ms. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 18 ms. SQL Server Execution Times: CPU time = 17 ms, elapsed time = 18 ms.
重要なのは、バイナリ比較に基づくフィルターの方が時間がかからないということです。したがって、文字列の出現を頻繁かつ迅速にフィルタリングする必要がある場合は、BINで終わるCOLLATEを使用してデータを格納できます。ただし、すべてのバイナリCOLLATEでは大文字と小文字が区別されることに注意してください。
コードスタイル
コーディングのスタイルは厳密に個別です。それでも、このコードは他の開発者によって単純に維持され、特定のルールに一致する必要があります。
内部に個別のデータベースとテーブルを作成します:
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_CI_AS
GO
USE test
GO
CREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY)
次に、クエリを記述します:
select employeeid from employee
次に、COLLATEを大文字と小文字を区別するものに変更します。
ALTER DATABASE test COLLATE Latin1_General_CS_AI
次に、クエリの実行を再試行します:
Msg 208, Level 16, State 1, Line 19 Invalid object name 'employee'.
オプティマイザは、テーブル、列、その他のオブジェクトをチェックするとき、および構文ツリーの各オブジェクトをシステムカタログの実際のオブジェクトと比較するときに、バインディングステップで現在のCOLLATEのルールを使用します。
クエリを手動で生成する場合は、オブジェクト名に常に正しい大文字と小文字を使用する必要があります。
変数に関しては、COLLATEはマスターデータベースから継承されます。したがって、それらを操作するには、正しいケースを使用する必要があります。
SELECT DATABASEPROPERTYEX('master', 'collation')
DECLARE @EmpID INT = 1
SELECT @empid この場合、エラーは発生しません:
----------------------- Cyrillic_General_CI_AS ----------- 1
それでも、別のサーバーでケースエラーが表示される場合があります:
-------------------------- Latin1_General_CS_AS Msg 137, Level 15, State 2, Line 4 Must declare the scalar variable "@empid".
[var] char
ご存知のように、固定されています( CHAR 、 NCHAR )および変数( VARCHAR 、 NVARCHAR )データ型:
DECLARE @a CHAR(20) = 'text'
, @b VARCHAR(20) = 'text'
SELECT LEN(@a)
, LEN(@b)
, DATALENGTH(@a)
, DATALENGTH(@b)
, '"' + @a + '"'
, '"' + @b + '"'
SELECT [a = b] = IIF(@a = @b, 'TRUE', 'FALSE')
, [b = a] = IIF(@b = @a, 'TRUE', 'FALSE')
, [a LIKE b] = IIF(@a LIKE @b, 'TRUE', 'FALSE')
, [b LIKE a] = IIF(@b LIKE @a, 'TRUE', 'FALSE') 行の長さが固定されている場合、たとえば20シンボルで、4つのシンボルしか記述していない場合、SQLServerはデフォルトで右側に16個の空白を追加します。
--- --- ---- ---- ---------------------- ---------------------- 4 4 20 4 "text " "text"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a = b b = a a LIKE b b LIKE a ----- ----- -------- -------- TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1 WHERE 'a ' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a ' -- !!! SELECT 1 WHERE 'a' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL
, @b VARCHAR(10) = '0.1'
, @c SQL_VARIANT
SELECT @a = @b
, @c = @a
SELECT @a
, @c
, SQL_VARIANT_PROPERTY(@c,'BaseType')
, SQL_VARIANT_PROPERTY(@c,'Precision')
, SQL_VARIANT_PROPERTY(@c,'Scale') As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- ----- 0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ---- 40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) = NULL SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL') DECLARE @i INT = NULL SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ---- N NULL ---- ---- 7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN オペレーター。
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3 SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
----------- 0 ----------- 0.333333
Also, let’s consider this particular example:
SELECT COUNT(*)
, COUNT(1)
, COUNT(val)
, COUNT(DISTINCT val)
, SUM(val)
, SUM(DISTINCT val)
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val)
SELECT AVG(val)
, SUM(val) / COUNT(val)
, AVG(val * 1.)
, AVG(CAST(val AS FLOAT))
FROM (
VALUES (1), (2), (2), (NULL), (NULL)
) t (val) This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id] FROM sys.system_objects UNION SELECT [object_id] FROM sys.objects SELECT [object_id] FROM sys.system_objects UNION ALL SELECT [object_id] FROM sys.objects
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)
SET @AddressLine = '4775 Kentucky Dr.'
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
OR AddressLine2 = @AddressLine As we have OR in the statement, we will receive IndexScan:
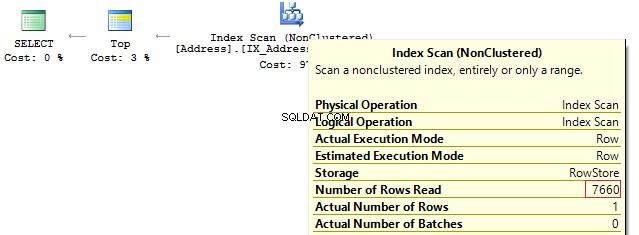
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressID
FROM (
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine
UNION ALL
SELECT TOP(1) AddressID
FROM Person.[Address]
WHERE AddressLine2 = @AddressLine
) t When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
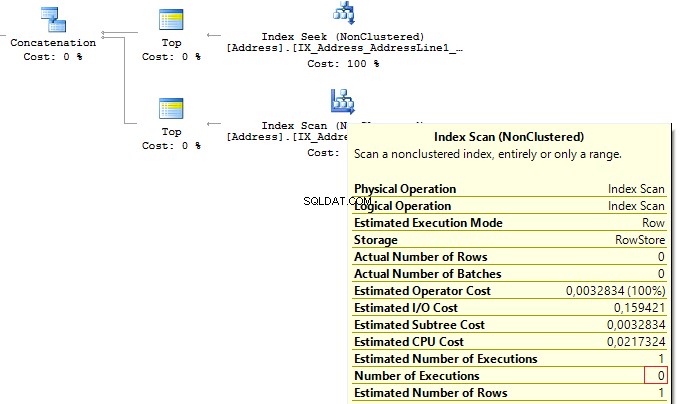
Table 'Worktable'. Scan count 0, logical reads 0, ... Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT e.BusinessEntityID
, (
SELECT p.LastName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
, (
SELECT p.FirstName
FROM Person.Person p
WHERE e.BusinessEntityID = p.BusinessEntityID
)
FROM HumanResources.Employee e
SELECT e.BusinessEntityID
, p.LastName
, p.FirstName
FROM HumanResources.Employee e
JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ... Table 'Employee'. Scan count 1, logical reads 2, ... Table 'Person'. Scan count 0, logical reads 888, ... Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014
GO
SET STATISTICS IO ON
SELECT p.BusinessEntityID
, (
SELECT s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
)
FROM Person.Person p However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID
, (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
)
FROM Person.Person p
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
OUTER APPLY (
SELECT TOP(1) s.SalesQuota
FROM Sales.SalesPersonQuotaHistory s
WHERE s.BusinessEntityID = p.BusinessEntityID
ORDER BY s.QuotaDate DESC
) t When executing these queries, we will get the same issue – multiple IndexSeek operators:
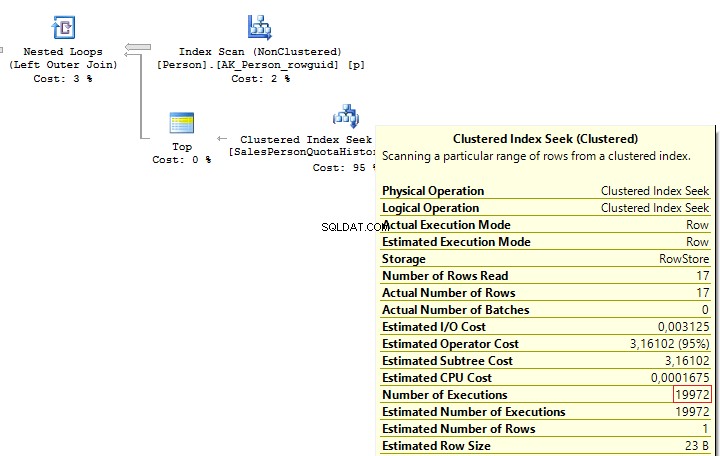
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ... Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID
, t.SalesQuota
FROM Person.Person p
LEFT JOIN (
SELECT s.BusinessEntityID
, s.SalesQuota
, RowNum = ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC)
FROM Sales.SalesPersonQuotaHistory s
) t ON p.BusinessEntityID = t.BusinessEntityID
AND t.RowNum = 1 We get the following result:
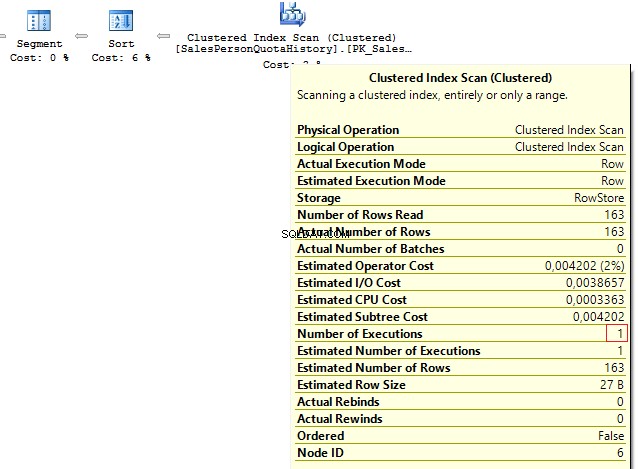
Table 'Person'. Scan count 1, logical reads 67, ... Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014
GO
SELECT BusinessEntityID
, Gender
, Gender =
CASE Gender
WHEN 'M' THEN 'Male'
WHEN 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee SQL Server will decompose the statement to the following:
SELECT BusinessEntityID
, Gender
, Gender =
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'F' THEN 'Female'
ELSE 'Unknown'
END
FROM HumanResources.Employee Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL
DROP FUNCTION dbo.GetMailUrl
GO
CREATE FUNCTION dbo.GetMailUrl
(
@Email NVARCHAR(50)
)
RETURNS NVARCHAR(50)
AS BEGIN
RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))
END Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed 。
Execute the query:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
--WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID
, EmailAddress
, CASE dbo.GetMailUrl(EmailAddress)
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM Person.EmailAddress In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID
, EmailAddress
, CASE MailUrl
WHEN 'microsoft.com' THEN 'Microsoft'
WHEN 'adventure-works.com' THEN 'AdventureWorks'
END
FROM (
SELECT TOP(10) EmailAddressID
, EmailAddress
, MailUrl = dbo.GetMailUrl(EmailAddress)
FROM Person.EmailAddress
) t In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT
CASE
WHEN Gender = 'M' THEN 'Male'
WHEN Gender = 'M' THEN '...'
WHEN Gender = 'M' THEN '......'
WHEN Gender = 'F' THEN 'Female'
WHEN Gender = 'F' THEN '...'
ELSE 'Unknown'
END
FROM HumanResources.Employee Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE 1/0
END
GO
DECLARE @i INT = 1
SELECT
CASE WHEN @i = 1
THEN 1
ELSE MIN(1/0)
END Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014
GO
UPDATE TOP(1) Person.[Address]
SET AddressLine2 = AddressLine1
GO
IF OBJECT_ID('dbo.isEqual') IS NOT NULL
DROP FUNCTION dbo.isEqual
GO
CREATE FUNCTION dbo.isEqual
(
@val1 NVARCHAR(100),
@val2 NVARCHAR(100)
)
RETURNS BIT
AS BEGIN
RETURN
CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 = @val2
THEN 1
ELSE 0
END
END The queries return the identical data:
SET STATISTICS TIME ON
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE dbo.IsEqual(AddressLine1, AddressLine2) = 1
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL)
OR AddressLine1 = AddressLine2
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE AddressLine1 = ISNULL(AddressLine2, '')
SET STATISTICS TIME OFF However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times: CPU time = 63 ms, elapsed time = 57 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL
DROP FUNCTION dbo.GetPI
GO
CREATE FUNCTION dbo.GetPI ()
RETURNS FLOAT
WITH SCHEMABINDING
AS BEGIN
RETURN PI()
END
GO
SELECT dbo.GetPI()
FROM Sales.Currency In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (a INT, b INT)
GO
INSERT INTO dbo.tbl VALUES (0, 1)
GO
IF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL
DROP VIEW dbo.vw_tbl
GO
CREATE VIEW dbo.vw_tbl
AS
SELECT * FROM dbo.tbl
GO
SELECT * FROM dbo.vw_tbl As you can see, we get the correct result:
a b ----------- ----------- 0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl
ADD c INT NOT NULL DEFAULT 2
GO
SELECT * FROM dbo.vw_tbl We receive the same result:
a b ----------- ----------- 0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname = N'dbo.vw_tbl' GO SELECT * FROM dbo.vw_tbl
Result:
a b c ----------- ----------- ----------- 0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployee
AS
SELECT e.BusinessEntityID
, p.Title
, p.FirstName
, p.MiddleName
, p.LastName
, p.Suffix
, e.JobTitle
, pp.PhoneNumber
, pnt.[Name] AS PhoneNumberType
, ea.EmailAddress
, p.EmailPromotion
, a.AddressLine1
, a.AddressLine2
, a.City
, sp.[Name] AS StateProvinceName
, a.PostalCode
, cr.[Name] AS CountryRegionName
, p.AdditionalContactInfo
FROM HumanResources.Employee e
JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID
JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = e.BusinessEntityID
JOIN Person.[Address] a ON a.AddressID = bea.AddressID
JOIN Person.StateProvince sp ON sp.StateProvinceID = a.StateProvinceID
JOIN Person.CountryRegion cr ON cr.CountryRegionCode = sp.CountryRegionCode
LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID = p.BusinessEntityID
LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID = pnt.PhoneNumberTypeID
LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityID What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID
, FirstName
, LastName
FROM HumanResources.vEmployee
SELECT p.BusinessEntityID
, p.FirstName
, p.LastName
FROM Person.Person p
WHERE p.BusinessEntityID IN (
SELECT e.BusinessEntityID
FROM HumanResources.Employee e
) Look at the execution plan in the case of using a view:
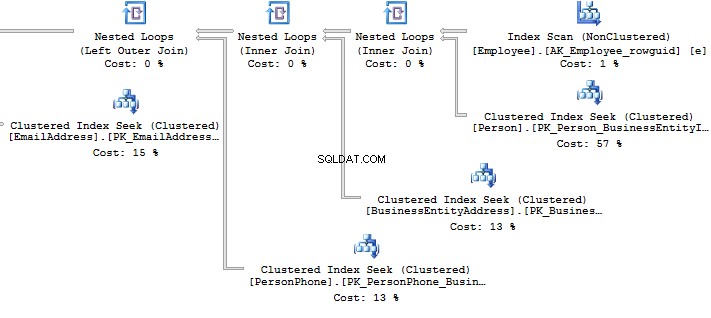
Table 'EmailAddress'. Scan count 290, logical reads 640, ... Table 'PersonPhone'. Scan count 290, logical reads 636, ... Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ... Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
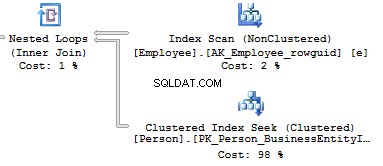
Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INT
DECLARE cur CURSOR FOR
SELECT BusinessEntityID
FROM HumanResources.Employee
OPEN cur
FETCH NEXT FROM cur INTO @BusinessEntityID
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE BusinessEntityID = @BusinessEntityID
FETCH NEXT FROM cur INTO @BusinessEntityID
END
CLOSE cur
DEALLOCATE cur Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.Employee SET VacationHours = 0 WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL
DROP TABLE #t
GO
CREATE TABLE #t (i CHAR(1))
INSERT INTO #t
VALUES ('1'), ('2'), ('3') Then, assign values to the variable:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t SELECT @txt -------- 123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t ORDER BY LEN(i) SELECT @txt -------- 3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] = i
FROM #t
FOR XML PATH('')
--------
123 It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
------------------------ ------------------------------------
ScrapReason ScrapReasonID, Name, ModifiedDate
Shift ShiftID, Name, StartTime, EndTime In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
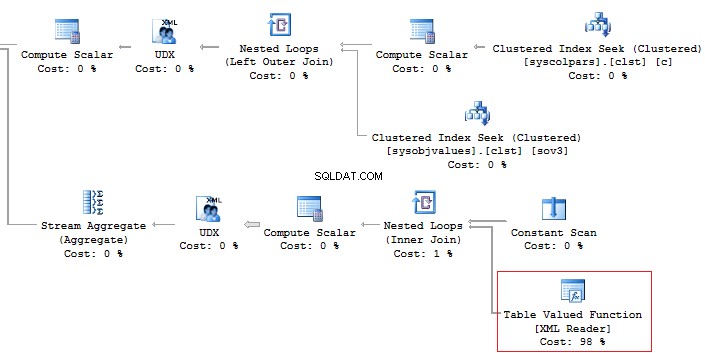
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF((
SELECT ', ' + c.[name]
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U' But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name
, STUFF((
SELECT ', ' + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U'
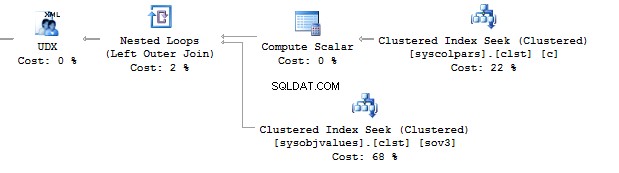
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name
, STUFF((
SELECT ', ' + CHAR(13) + c.name
FROM sys.columns c
WHERE c.[object_id] = t.[object_id]
FOR XML PATH('')), 1, 2, '')
FROM sys.objects t
WHERE t.[type] = 'U' If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… 。
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX) SET @param = 1 DECLARE @SQL NVARCHAR(MAX) SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = ' + @param PRINT @SQL EXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1
If we add any additional value to the property,
SET @param = '1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id = {0}", value), conn);
using (SqlDataReader reader = command.ExecuteReader())
{
while (reader.Read()) {}
}
} When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)
SET @param = '1; select ''hack'''
DECLARE @SQL NVARCHAR(MAX)
SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id'
PRINT @SQL
EXEC sys.sp_executesql @SQL
, N'@schema_id INT'
, @schema_id = @param It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn = new SqlConnection())
{
conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true";
conn.Open();
SqlCommand command = new SqlCommand(
"SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id", conn);
command.Parameters.Add(new SqlParameter("schema_id", value));
...
} Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.