すべてのPostgreSQLリリースにはいくつかの主要な機能拡張が含まれていますが、同様に興味深いのは、すべてのリリースが過去の機能も改善していることです。
PostgreSQL 13は間もなくリリースされる予定なので、コミュニティがもたらしている機能と改善点を確認するときが来ました。そのようなノイズのない改善の1つは、「パーティショニングの論理レプリケーションの改善」です。
大きなテーブルを複数の物理的な部分に分割して、次のようなメリットを実現する方法:
これらの利点のいくつかは、パーティションのプルーニング(つまり、パーティション定義を使用してパーティションをスキャンするかどうかを決定するクエリプランナー)と、パーティションが有限メモリに収まりやすいという事実によって実現されます。巨大なテーブルと比較して。

名前が示すように、これはデータがID(キーなど)に基づいて段階的に複製される複製方法です。これは、データがバイト単位で送信されるWALまたは物理レプリケーション方式とは異なります。
Publisher-Subscriberパターンに基づいて、データのソースはパブリッシャーを定義する必要があり、ターゲットはサブスクライバーとして登録する必要があります。これの興味深いユースケースは次のとおりです。
- 選択的レプリケーション(データベースの一部のみ)
- データが複製されるデータベースの2つのインスタンスへの同時書き込み
- 異なるオペレーティングシステム(LinuxとWindowsなど)間のレプリケーション
- データの複製に関するきめ細かいセキュリティ
- データが受信側に到着すると実行をトリガーします
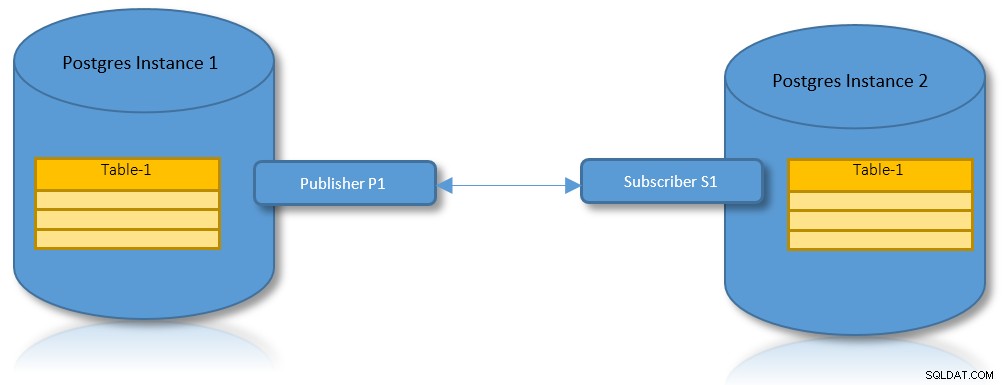
論理レプリケーションとパーティショニングの両方の利点があるため、2つのPostgreSQLインスタンス間でパーティショニングされたテーブルをレプリケートする必要があるシナリオを作成するのが実用的なユースケースです。
以下は、このコンテキストでPostgreSQL13で行われている改善を確立して強調するための手順です。
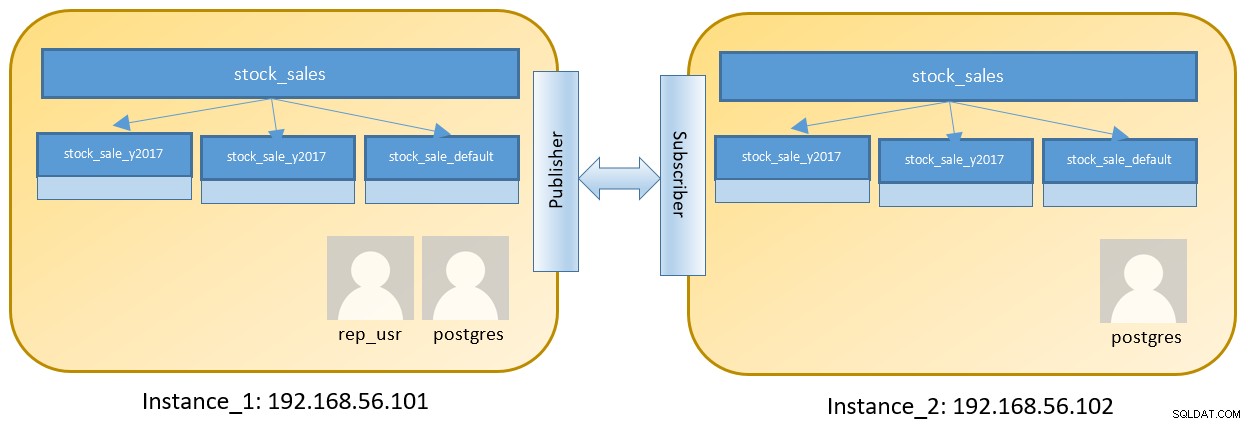
Instance_1の手順は、postgresユーザーとして192.168.56.101にログインした後の手順です。 :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile start「wal_level」の設定は特に「logical」に設定され、このインスタンスからのデータの複製に論理複製が使用されることを示します。構成ファイル「pg_hba.conf」も、192.168.56.102からの接続を許可するように変更されました。
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;postgresの役割はデフォルトでInstance_1データベースに作成されますが、アクセスが制限されている別のユーザーも作成する必要があります。これにより、特定のテーブルのスコープのみが制限されます。
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startInstance_2は他のノードのデータのソースではないため、wal_level設定とpg_hba.confファイルに追加の設定は必要ありません。言うまでもなく、pg_hba.confは本番環境のニーズに応じて更新する必要がある場合があります。
論理レプリケーションはDDLをサポートしていません。また、Instance_2にもテーブル構造を作成する必要があります。上記のパーティション作成を使用してパーティションテーブルを作成し、Instance_2にも同じテーブル構造を作成します。
PostgreSQL 13を使用すると、論理レプリケーションのセットアップがはるかに簡単になります。PostgreSQL12までは、構造は次のようになりました。
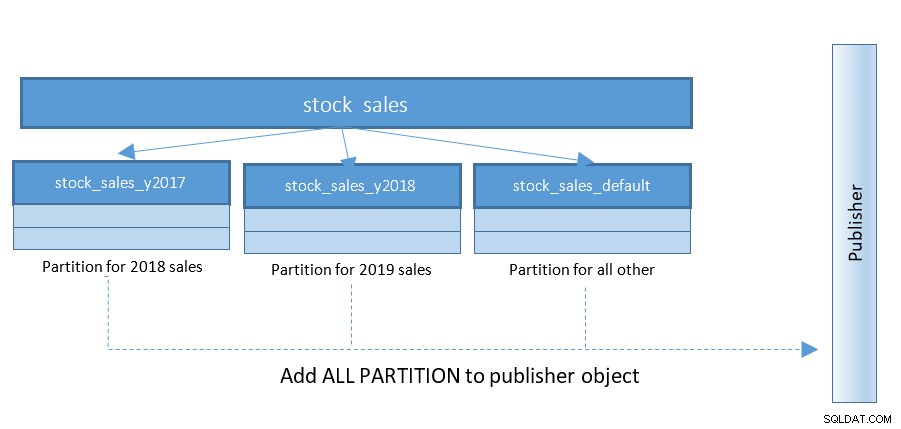
PostgreSQL 13を使用すると、パーティションの公開がはるかに簡単になります。下の図を参照して、前の図と比較してください。
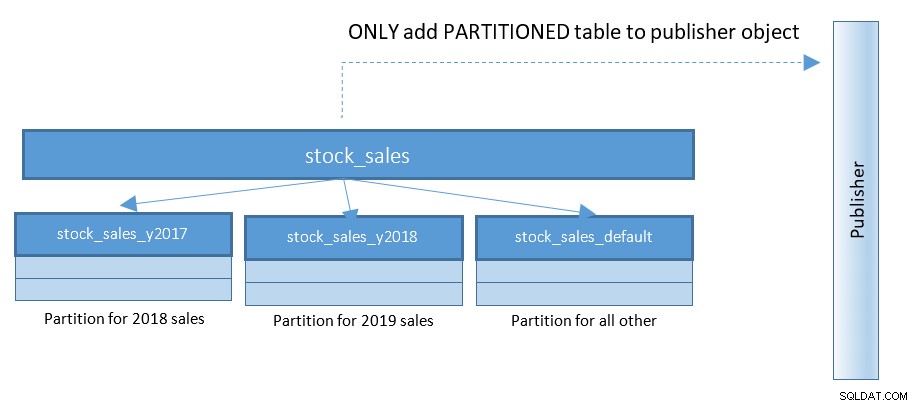
数百、数千のパーティションテーブルで荒れ狂うセットアップ–この小さな変更により、物事の大部分。
PostgreSQL 13では、このようなパブリケーションを作成するためのステートメントは次のようになります。
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.PostgreSQL 12の制限を無視し、PostgreSQL 13でこの機能を実際に使用して続行するには、次のステートメントを使用してInstance_2にサブスクライバーを確立する必要があります。
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;セットアップはほぼ完了しましたが、いくつかのテストを実行して、機能しているかどうかを確認しましょう。
Instance_1で、複数の行を挿入して、それらが複数のパーティションに生成されるようにします。
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721次に、受信者側でリーフノードが同じでなくても、論理レプリケーションが機能するかどうかを確認しましょう。
Instance_1に別のパーティションを追加し、レコードを挿入します:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174PostgreSQL13のその他のパーティショニング機能
PostgreSQL 13には、パーティショニングに関連する他の改善点もあります。つまり、次のとおりです。
次のブログセットで、前述の2つの今後の機能を確実に確認します。それまでは、パーティション分割と論理レプリケーションの組み合わせの力で、PostgreSQLはマスターマスターセットアップに近づいていますか?