はじめに
数年前、私たちは「調整」と呼ばれる目的で、特定の形式のカードデータに対するビジネス要件を課されました。アイデアは、6か月の保持期間を持つデータを消費および処理するアプリケーションにテーブル内のデータを提示することでした。このビジネスニーズに合わせて新しいデータベースを作成してから、コアテーブルをパーティションテーブルとして作成する必要がありました。ここで説明するプロセスは、6か月以上前のデータをクリーンな方法でテーブルから移動するために使用するプロセスです。
パーティショニングについて少し
テーブルパーティショニングは、SQL Serverのファイルグループと呼ばれる抽象化レイヤーを介して、1つの論理ユニット(テーブル)に属するデータを、個別の物理構造(データファイル)に配置されるパーティションのセットとして格納できるデータベーステクノロジです。このパーティションテーブルを作成するプロセスには、2つの主要なオブジェクトが含まれます。
パーティション関数 :パーティション関数は、指定された列(パーティション列)の値に基づいて、パーティション化されたテーブルの行がどのようにマップされるかを定義します。パーティション化されたテーブルは、リストのいずれかに基づくことができます。 または範囲。ユースケース(6か月分のデータのみを保持)の目的で、範囲パーティションを使用しました 。パーティション関数は、RANGERIGHTまたはRANGELEFTのいずれかとして定義できます。リスト1のコードに示すように、RANGE RIGHTを使用しました。これは、値を左から右に昇順で並べ替えると、境界値が境界値間隔の右側に属することを意味します。
-- Listing 1: Create a Partition Function
USE [post_office_history]
GO
CREATE PARTITION FUNCTION
PostTranPartFunc (datetime)
AS RANGE RIGHT
FOR VALUES
('20190201'
,'20190301'
,'20190401'
,'20190501'
,'20190601'
,'20190701'
,'20190801'
,'20190901'
,'20191001'
,'20191101'
,'20191201'
)
GO パーティションスキーム :パーティションスキームは、パーティション関数に基づいており、各パーティションに属する行を配置する物理構造を決定します。これは、そのような行をファイルグループにマッピングすることによって実現されます。リスト2は、パーティションスキームを作成するためのコードを示しています。パーティションスキームを作成する前に、それが参照するファイルグループが存在している必要があります。
-- Listing 2: Create Partition Scheme -- -- Step 1: Create Filegroups -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILEGROUP [OCT] ALTER DATABASE [post_office_history] ADD FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILEGROUP [DEC] GO -- Step 2: Add Data Files to each Filegroup -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_01', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_02', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_03', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_04', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_04.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_05', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_06', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_06.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_07', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_07.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_08', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_08.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [OCT] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_11.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_12.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [DEC] GO -- Step 3: Create Partition Scheme -- PRINT 'creating partition scheme ...' GO USE [post_office_history] GO CREATE PARTITION SCHEME PostTranPartSch AS PARTITION PostTranPartFunc TO ( JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC ) GO
Nの場合は注意してください パーティションには、常に N-1があります 境界。パーティションスキームで最初のファイルグループを定義するときは注意が必要です。パーティション関数にリストされている最初の境界は、最初のファイルグループと2番目のファイルグループの間にあるため、この境界値(20190201)は2番目のパーティション(FEB)にあります。さらに、実際にはすべてのパーティションを1つのファイルグループに配置することも可能ですが、この場合は別々のファイルグループを選択しました。
手を汚す
それでは、パーティションを切り替えるタスクに飛び込みましょう!
最初に行う必要があるのは、データがパーティション間でどのように分散されているかを正確に判断して、どのパーティションを切り替えるかを判断できるようにすることです。通常、最も古いパーティションを切り替えます。
-- Listing 3: Check Data Distribution in Partitions -- USE POST_OFFICE_HISTORY GO SELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) AS [PARTITION NUMBER] , MIN(DATETIME_TRAN_LOCAL) AS [MIN DATE] , MAX(DATETIME_TRAN_LOCAL) AS [MAX DATE] , COUNT(*) AS [ROWS IN PARTITION] FROM DBO.POST_TRAN_TAB -- PARTITIONED TABLE GROUP BY $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) ORDER BY [PARTITION NUMBER] GO
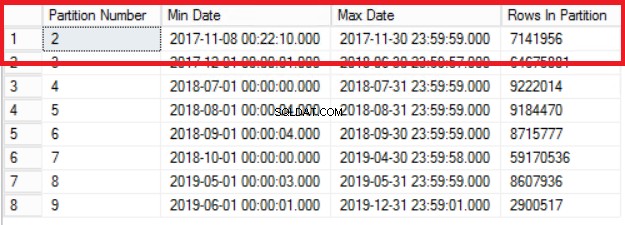
図1リスト3の出力
図1は、リスト3のクエリの出力を示しています。最も古いパーティションは、2017年の行を含むパーティション2です。リスト4のクエリでこれを確認します。リスト4は、パーティション内のデータを保持しているファイルグループも示しています。 2.
-- Listing 4: Check Filegroup Associated with Partition --
USE POST_OFFICE_HISTORY
GO
SELECT PS.NAME AS PSNAME,
DDS.DESTINATION_ID AS PARTITIONNUMBER,
FG.NAME AS FILEGROUPNAME
FROM (((SYS.TABLES AS T
INNER JOIN SYS.INDEXES AS I
ON (T.OBJECT_ID = I.OBJECT_ID))
INNER JOIN SYS.PARTITION_SCHEMES AS PS
ON (I.DATA_SPACE_ID = PS.DATA_SPACE_ID))
INNER JOIN SYS.DESTINATION_DATA_SPACES AS DDS
ON (PS.DATA_SPACE_ID = DDS.PARTITION_SCHEME_ID))
INNER JOIN SYS.FILEGROUPS AS FG
ON DDS.DATA_SPACE_ID = FG.DATA_SPACE_ID
WHERE (T.NAME = 'POST_TRAN_TAB') AND (I.INDEX_ID IN (0,1))
AND DDS.DESTINATION_ID = $PARTITION.POSTTRANPARTFUNC('20171108') ;> 図1リスト3の出力
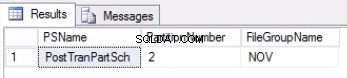
図2リスト4の出力
リスト4は、パーティション2に関連付けられたファイルグループが NOVであることを示しています。 。パーティション2を切り替えるには、ライブテーブルのレプリカであるが、切り替える予定のパーティションと同じファイルグループにある履歴テーブルが必要です。このテーブルはすでにあるので、必要なのは目的のファイルグループに再作成することだけです。また、クラスター化されたインデックスを再作成する必要があります。このクラスター化インデックスは、テーブル post_tran_tabのクラスター化インデックスと同じ定義であることに注意してください。 また、 post_tran_tab_histと同じファイルグループにあります テーブル。
-- Listing 5: Re-create the History Table -- Re-create the History Table -- USE [post_office_history] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO DROP TABLE [dbo].[post_tran_tab_hist] GO CREATE TABLE [dbo].[post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4) NULL, [source_node_name] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_node_currency_code] [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp] [float] NOT NULL, [datetime_tran_gmt] [char](10) NULL, [merchant_type] [char](4) NULL, [pos_entry_mode] [char](3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char](15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved] [float] NOT NULL, [tran_completed] [char](2) NULL ) ON [NOV] GO SET ANSI_PADDING OFF GO -- Re-create the Clustered Index -- USE [post_office_history] GO CREATE CLUSTERED INDEX [IX_Datetime_Local] ON [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [NOV] GO
最後のパーティションの切り替えは、1行のコマンドになりました。この1行のコマンドを実行する前後に両方のテーブルを数えることで、必要なすべてのデータが確実に得られます。
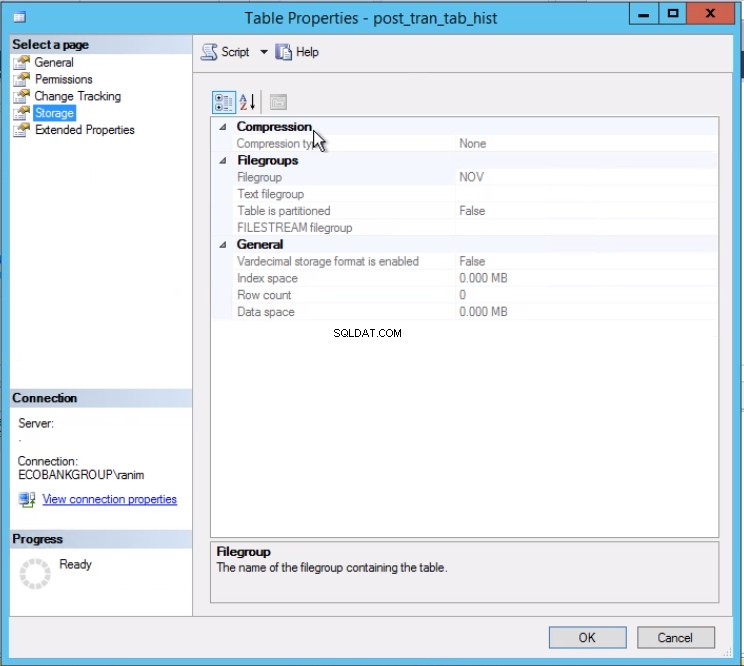
図3テーブルpost_tran_tab_histはNOVファイルグループにあります
-- Listing 6: Switching Out the Last Partition SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST'; USE [POST_OFFICE_HISTORY] GO ALTER TABLE POST_TRAN_TAB SWITCH PARTITION 2 TO POST_TRAN_TAB_HIST GO SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST';
最後のパーティションを切り替えたので、境界はもう必要ありません。リスト7のコマンドを使用して、その境界によって以前に分割された2つの範囲をマージします。リスト8に示すように、履歴テーブルをさらに切り捨てます。これが要点であるため、これを実行しています。不要になった古いデータを削除します。
-- Listing 7: Merging Partition Ranges
-- Merge Range
USE [POST_OFFICE_HISTORY]
GO
ALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');
-- Confirm Range Is Merged
USE [POST_OFFICE_HISTORY]
GO
SELECT * FROM SYS.PARTITION_RANGE_VALUES
GO>
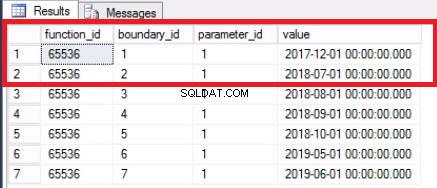
図4マージされた境界
-- Listing 8: Truncate the History Table USE [post_office_history] GO TRUNCATE TABLE post_tran_tab_hist; GO
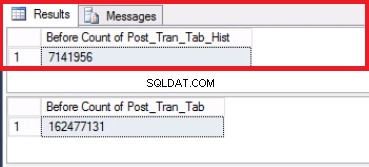
図5切り捨て前の両方のテーブルの行数
履歴テーブルの行数は、図1に示すように、以前にパーティション2にあった行数とまったく同じであることに注意してください。最後のファイルグループに属するファイルグループの空きスペースを回復することで、さらに1マイル進むこともできます。パーティション。これは、以前のパーティションに配置される新しいデータ用にこのスペースが必要な場合に役立ちます。環境に十分なスペースがあると思われる場合は、この手順は必要ない場合があります。
-- Listing 9: Recover Space on Operating System -- Determine that File has been emptied USE [post_office_history] GO SELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS.DATABASE_FILES DF JOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID = DS.DATA_SPACE_ID;
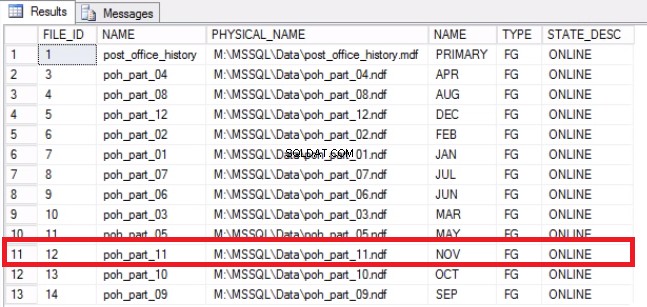
図7ファイルからファイルグループへのマッピング
-- Shrink the file to 2GB USE [post_office_history] GO DBCC SHRINKFILE (N'post_office_history_part_11’, 2048) GO -- From the OS confirm free space on disks SELECT DISTINCT DB_NAME (S.DATABASE_ID) AS DATABASE_NAME, S.DATABASE_ID, S.VOLUME_MOUNT_POINT --, S.VOLUME_ID , S.LOGICAL_VOLUME_NAME , S.FILE_SYSTEM_TYPE , S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)] , S.AVAILABLE_BYTES/1024/1024/1024 AS [FREE_SPACE (GB)] , LEFT ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) AS PERCENT_FREE FROM SYS.MASTER_FILES AS F CROSS APPLY SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.FILE_ID) AS S WHERE DB_NAME (S.DATABASE_ID) = 'POST_OFFICE_HISTORY';

図8オペレーティングシステムの空き領域
結論
この記事では、パーティションテーブルからパーティションを切り替えるプロセスのウォークスルーを行いました。これは、SQLServerでネイティブにデータの増加を管理するための非常に効率的な方法です。現在のバージョンのSQLServerでは、StretchDatabaseなどのより高度なテクノロジを利用できます。
参照
イサコフ、V。(2018)。試験参照70-764SQLデータベースインフラストラクチャの管理。ピアソン教育
SQLServerのパーティション化されたテーブルとインデックス