SQLサブクエリを使用しますか、それとも使用を避けますか?
たとえば、クレジットおよびコレクションの最高責任者から、人の名前、1か月あたりの未払い残高、現在の現在の残高を一覧表示して、このデータ配列をExcelにインポートするように求められたとします。目的は、データを分析し、COVID19パンデミックの影響を軽減するために支払いを軽くする提案を考え出すことです。
クエリとネストされたサブクエリまたは結合を使用することを選択しますか?どのような決定をしますか?
SQLサブクエリ–それらは何ですか?
構文、パフォーマンスへの影響、および警告について深く掘り下げる前に、まずサブクエリを定義してみませんか?
簡単に言うと、サブクエリはクエリ内のクエリです。サブクエリを具体化するクエリは外部クエリですが、サブクエリを内部クエリまたは内部選択と呼びます。また、括弧は以下の構造のようなサブクエリを囲みます:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)この投稿では、次の点に注目します。
- さまざまなサブクエリタイプと演算子に応じたSQLサブクエリ構文。
- いつ、どのような種類のステートメントでサブクエリを使用できるか。
- パフォーマンスへの影響と参加 。
- SQLサブクエリを使用する際の一般的な注意事項。
いつものように、理解を深めるために例とイラストを提供します。ただし、この投稿の主な焦点はSQLServerのサブクエリにあることに注意してください。
それでは、始めましょう。
自己完結型または相関のあるSQLサブクエリを作成する
1つには、サブクエリは外部クエリへの依存関係に基づいて分類されます。
自己完結型のサブクエリとは何かを説明しましょう。
自己完結型のサブクエリ(または非相関または単純なサブクエリと呼ばれることもあります)は、外部クエリのテーブルから独立しています。これを説明しましょう:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)上記のコードで示されているように、サブクエリ(以下の括弧で囲まれている)には、外部クエリのどの列への参照もありません。さらに、SQL Server Management Studioでサブクエリを強調表示して、ランタイムエラーを発生させずに実行できます。
これにより、自己完結型のサブクエリのデバッグが容易になります。
次に考慮すべきことは、相関サブクエリです。自己完結型の対応物と比較すると、この列には、外部クエリから参照されている列が少なくとも1つあります。明確にするために、例を示します:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)BusinessEntityIDへの参照に気付くのに十分注意しましたか 人から テーブル?よくできました!
外部クエリの列がサブクエリで参照されると、それは相関サブクエリになります。考慮すべきもう1つのポイント:サブクエリを強調表示して実行すると、エラーが発生します。
そして、はい、あなたは絶対に正しいです:これは相関サブクエリをデバッグするのをかなり難しくします。
デバッグを可能にするには、次の手順に従います。
- サブクエリを分離します。
- 外部クエリへの参照を定数値に置き換えます。
デバッグ用にサブクエリを分離すると、次のようになります。
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>それでは、サブクエリの出力についてもう少し詳しく見ていきましょう。
3つの可能な戻り値を使用してSQLサブクエリを作成する
まず、SQLサブクエリから期待できる戻り値について考えてみましょう。
実際、考えられる結果は3つあります。
- 単一の値
- 複数の値
- テーブル全体
単一値
単一値の出力から始めましょう。このタイプのサブクエリは、 WHERE のように、式が期待される外部クエリのどこにでも表示できます。 条項。
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)MAXを使用する場合 ()関数では、単一の値を取得します。上記のサブクエリに起こったことはまさにそれです。等しい( = )演算子は、単一の値が必要であることをSQLServerに通知します。別のこと:サブクエリがequals( =)を使用して複数の値を返す場合 )演算子、エラーが発生します 以下のようなものです:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.複数の値
次に、複数値の出力を調べます。この種のサブクエリは、単一の列を持つ値のリストを返します。さらに、 INのような演算子 およびNOTIN 1つ以上の値が必要です。
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')テーブル全体の値
最後になりましたが、テーブル全体の出力を詳しく調べてみませんか。
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]FROMに気づきましたか 条項?
テーブルを使用する代わりに、サブクエリを使用しました。これは、派生テーブルまたはテーブルサブクエリと呼ばれます。
それでは、この種のクエリを使用する際の基本的なルールをいくつか紹介します。
- サブクエリのすべての列には一意の名前を付ける必要があります。物理テーブルと同様に、派生テーブルには一意の列名を付ける必要があります。
- 注文者 TOP でない限り、許可されません も指定されています。これは、派生テーブルが、行に順序が定義されていないリレーショナルテーブルを表しているためです。
この場合、派生テーブルには物理テーブルの利点があります。そのため、この例では COUNTを使用できます ()派生テーブルの列の1つ。
サブクエリの出力については以上です。ただし、先に進む前に、複数の値やその他の例の背後にあるロジックも JOINを使用して実行できることに気付いたかもしれません。 。
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'実際、出力は同じになります。しかし、どちらがパフォーマンスが優れていますか?
その前に、私がこのホットなトピックにセクションを捧げたことをお伝えしましょう。完全な実行計画でそれを調べ、イラストを見ていきます。
だから、ちょっと我慢してください。サブクエリを配置する別の方法について話し合いましょう。
SQLサブクエリを使用できるその他のステートメント
これまで、 SELECTでSQLサブクエリを使用してきました ステートメント。そして重要なのは、挿入でサブクエリのメリットを享受できるということです。 、更新 、および削除 ステートメントまたは式を形成する任意のT-SQLステートメント。
それでは、さらにいくつかの例を見てみましょう。
UPDATEステートメントでのSQLサブクエリの使用
UPDATEにサブクエリを含めるのは簡単です ステートメント。この例をチェックしてみませんか?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GO私たちがそこで行ったことを目にしましたか?
重要なのは、サブクエリを場所に配置できるということです。 UPDATEの句 ステートメント。
例には含まれていないため、 SETのサブクエリを使用することもできます SETのような句 列 =(サブクエリ) 。ただし、注意してください。単一の値を出力する必要があります。そうしないと、エラーが発生します。
次に何をしますか?
INSERTステートメントでのSQLサブクエリの使用
すでにご存知のように、 SELECTを使用してテーブルにレコードを挿入できます 声明。サブクエリの構造がどうなるかはわかっていると思いますが、例を挙げてこれを示しましょう。
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)では、ここで何を見ているのでしょうか?
- 最初のサブクエリは、10を追加する前に、従業員の最後の給与レートを取得します。
- 2番目のサブクエリは、従業員の最後の給与レコードを取得します。
- 最後に、 SELECTの結果 EmployeePayHistoryに挿入されます テーブル。
その他のT-SQLステートメント
SELECT以外 、挿入 、更新 、および削除 、次のSQLサブクエリを使用することもできます:
ストアドプロシージャおよび関数の変数宣言またはSETステートメント
この例を使用して明確にしましょう:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)または、次の方法でこれを行うことができます:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)条件式の場合
この例を覗いてみませんか:
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDそれとは別に、次のように行うことができます:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
END比較演算子または論理演算子を使用してSQLサブクエリを作成する
これまでのところ、等しい( = )演算子とIN演算子。しかし、探求することはまだまだたくさんあります。
比較演算子の使用
=、<、>、<>、> =、<=などの比較演算子をサブクエリで使用する場合、サブクエリは単一の値を返す必要があります。さらに、サブクエリが複数の値を返すとエラーが発生します。
以下の例では、ランタイムエラーが生成されます。
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)上記のコードの何が問題になっているのか知っていますか?
まず、コードはサブクエリでequals(=)演算子を使用します。さらに、サブクエリは開始日のリストを返します。
この問題を解決するには、サブクエリで MAXのような関数を使用するようにします。 ()開始日の列に単一の値を返します。
論理演算子の使用
存在するか存在しないかの使用
存在 TRUEを返します サブクエリが行を返す場合。それ以外の場合は、 FALSEを返します 。一方、 NOTを使用する 存在 TRUEを返します 行がなく、 FALSEの場合 、それ以外の場合。
以下の例を検討してください:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDまず、説明させてください。上記のコードは、 sys.tables で見つかった場合、テーブルトークンを削除します 、データベースに存在するかどうかを意味します。もう1つのポイント:列名への参照は関係ありません。
なぜですか?
データベースエンジンは、 EXISTSを使用して少なくとも1行を取得するだけでよいことがわかりました。 。この例では、サブクエリが行を返す場合、テーブルは削除されます。一方、サブクエリが1行も返さなかった場合、後続のステートメントは実行されません。
したがって、 EXISTSの懸念 行だけで列はありません。
さらに、存在 2値論理を使用します: TRUE またはFALSE 。 NULLを返す場合はありません 。 EXISTSを無効にしても同じことが起こります 使用しない 。
INまたはNOTINの使用
INで導入されたサブクエリ またはNOTIN 0個以上の値のリストを返します。また、既存とは異なります 、適切なデータ型の有効な列が必要です。
別の例でこれを明確にしましょう:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676上記のコードからわかるように、両方の IN およびNOTIN 演算子が導入されました。どちらの場合も、行が返されます。手元にある製品とベンダー1676以外の製品を取得するために、外部クエリの各行が各サブクエリの結果と照合されます。
SQLサブクエリのネスト
最大32レベルまでサブクエリをネストできます。それでも、この機能はサーバーの使用可能なメモリとクエリ内の他の式の複雑さに依存します。
これについてどう思いますか?
私の経験では、4つまでのネストを思い出しません。2つまたは3つのレベルを使用することはめったにありません。しかし、それは私と私の要件だけです。
これを理解するための良い例はどうですか:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))この例でわかるように、ネストは2つのレベルに達しました。
SQLサブクエリはパフォーマンスに悪影響を及ぼしますか?
一言で言えば:はい、いいえ。言い換えれば、それは依存します。
また、これはSQLServerのコンテキストにあることを忘れないでください。
手始めに、サブクエリを使用する多くのT-SQLステートメントは、代わりに JOINを使用して書き直すことができます。 s。そして、両方のパフォーマンスは通常同じです。それにもかかわらず、結合がより高速である特定の場合があります。また、サブクエリがより迅速に機能する場合があります。
例1
サブクエリの例を見てみましょう。それらを実行する前に、 Control-Mを押してください または、実際の実行プランを含めるを有効にします SQL ServerManagementStudioのツールバーから。
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')または、同じ結果が得られる結合を使用して、上記のクエリを書き換えることもできます。
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'最終的に、両方のクエリの結果は200行になります。
それだけでなく、両方のステートメントの実行プランを確認できます。
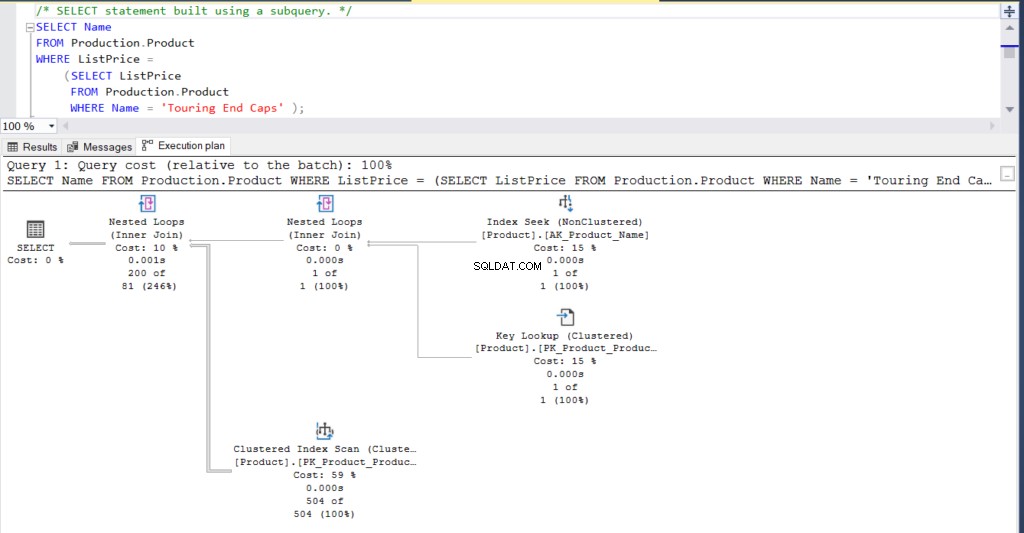
図1:サブクエリを使用した実行プラン
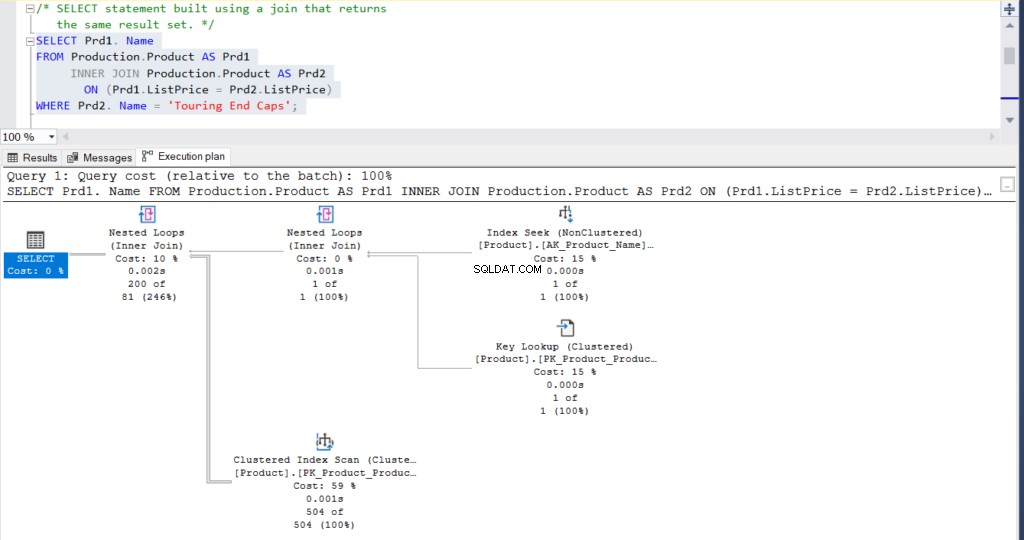
図2:結合を使用した実行プラン
どう思いますか?それらは実質的に同じですか?各ノードの実際の経過時間を除いて、他のすべては基本的に同じです。
しかし、視覚的な違いは別として、これを比較する別の方法があります。 ショープランの比較を使用することをお勧めします 。
実行するには、次の手順に従います。
- サブクエリを使用して、ステートメントの実行プランを右クリックします。
- 名前を付けて実行プランを保存を選択します 。
- ファイルにsubquery-execution-plan.sqlplanという名前を付けます 。
- 結合を使用してステートメントの実行プランに移動し、右クリックします。
- ショープランの比較を選択します 。
- #3で保存したファイル名を選択します。
Showplanの比較の詳細については、こちらをご覧ください。 。
これに似たものが表示されるはずです:
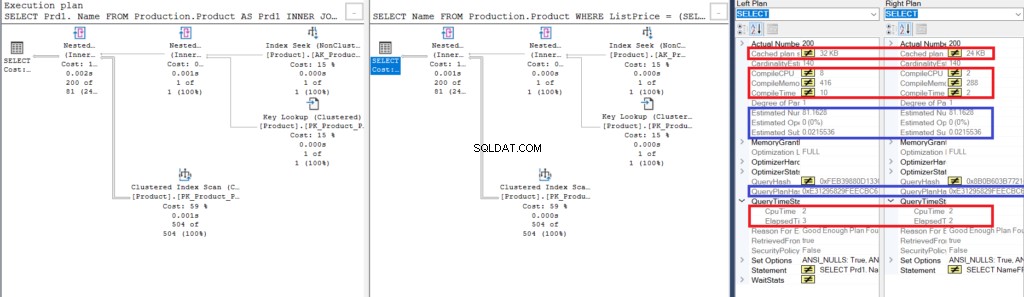
図3:結合を使用する場合とサブクエリを使用する場合のShowplanの比較
類似点に注意してください:
- 推定行数とコストは同じです。
- QueryPlanHash も同じです。つまり、実行計画は似ています。
それでも、違いに注意してください:
- キャッシュプランのサイズは、サブクエリを使用するよりも結合を使用する方が大きくなります
- 実行プランの解析、バインド、最適化に使用されるCPUと時間(ミリ秒単位)(KB単位のメモリを含む)は、サブクエリを使用するよりも結合を使用する方が高くなります。
- プランを実行するためのCPU時間と経過時間(ミリ秒単位)は、結合とサブクエリを使用するとわずかに長くなります
この例では、結果の行が同じであっても、サブクエリは結合よりも高速です。
例2
前の例では、1つのテーブルのみを使用しました。次の例では、3つの異なるテーブルを使用します。
これを実現させましょう:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'どちらのクエリも同じ3806行を出力します。
次に、彼らの実行計画を見てみましょう:
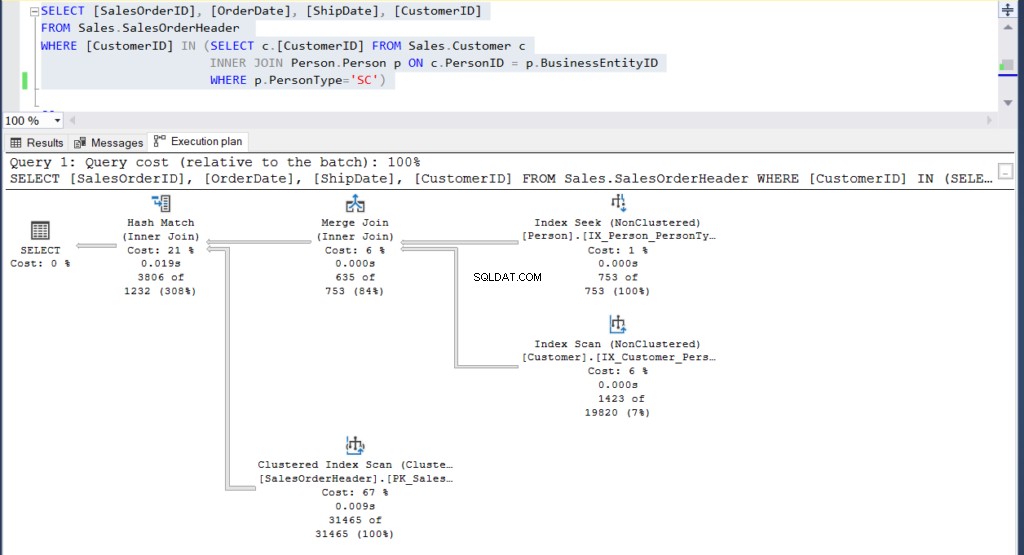
図4:サブクエリを使用した2番目の例の実行プラン
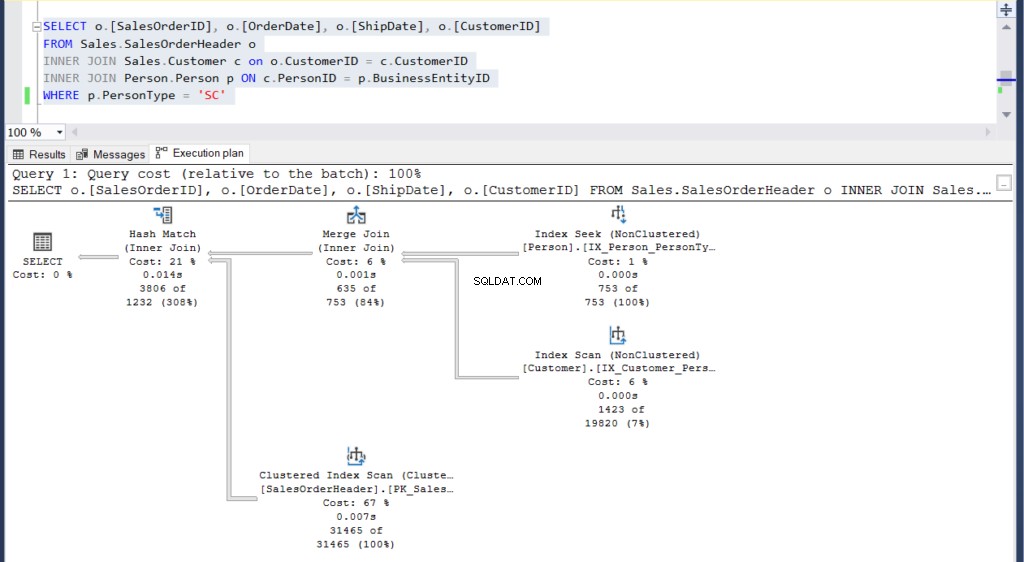
図5:結合を使用した2番目の例の実行プラン
2つの実行計画を見て、それらの違いを見つけることができますか?一見同じように見えます。
ただし、ショープランの比較を使用したより慎重な検討 実際に何が入っているかを明らかにします。
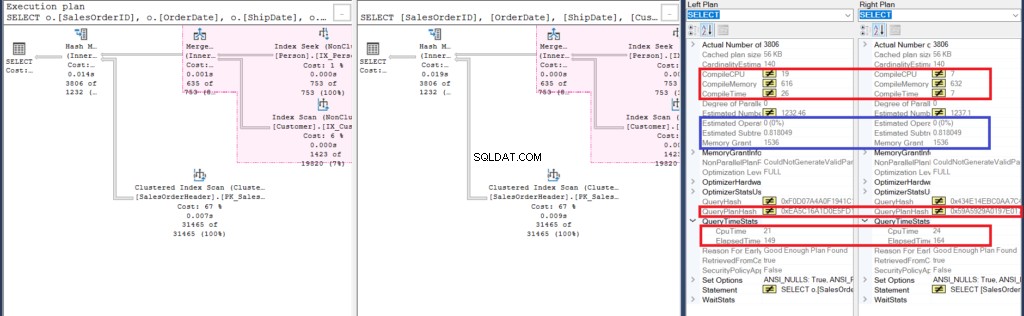
図6:2番目の例の比較ショープランの詳細
いくつかの類似点を分析することから始めましょう:
- 実行プランのピンク色のハイライトは、両方のクエリで同様の操作が行われていることを示しています。内部クエリはサブクエリをネストする代わりに結合を使用するため、これは非常に理解しやすいものです。
- 推定されるオペレーターとサブツリーのコストは同じです。
次に、違いを見てみましょう:
- まず、結合を使用するとコンパイルに時間がかかりました。これは、CPUのコンパイルとコンパイル時間で確認できます。ただし、サブクエリを使用したクエリでは、KB単位でより高いコンパイルメモリが必要でした。
- 次に、両方のクエリのQueryPlanHashが異なります。つまり、実行プランが異なります。
- 最後に、プランを実行するための経過時間とCPU時間は、結合を使用すると高速になります。 サブクエリを使用するよりも。
サブクエリと参加パフォーマンスのポイント
結合またはサブクエリを使用して解決できる、他のクエリ関連の問題が多すぎる可能性があります。
しかし、肝心なのは、サブクエリは結合と比較して本質的に悪いわけではないということです。また、特定の状況では、結合がサブクエリまたはその逆よりも優れているという経験則はありません。
したがって、最良の選択があることを確認するには、実行計画を確認してください。その目的は、SQLServerが特定のクエリを処理する方法についての洞察を得ることです。
ただし、サブクエリを使用する場合は、スキルをテストする問題が発生する可能性があることに注意してください。
SQLサブクエリの使用に関する一般的な警告
SQLサブクエリを使用するときにクエリが乱暴に動作する原因となる可能性のある2つの一般的な問題があります。
列名解決の苦痛
この問題により、クエリに論理的なバグが発生し、見つけるのが非常に難しい場合があります。例を使用すると、この問題をさらに明確にすることができます。
デモ用のテーブルを作成し、データを入力することから始めましょう。
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GOテーブルが設定されたので、それを使用していくつかのサブクエリを実行してみましょう。ただし、以下のクエリを実行する前に、前のコードで使用したベンダーIDが「14」で始まることを忘れないでください。
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)以下に示すように、上記のコードはエラーなしで実行されます。とにかく、 BusinessEntityIDsのリストに注意してください 。
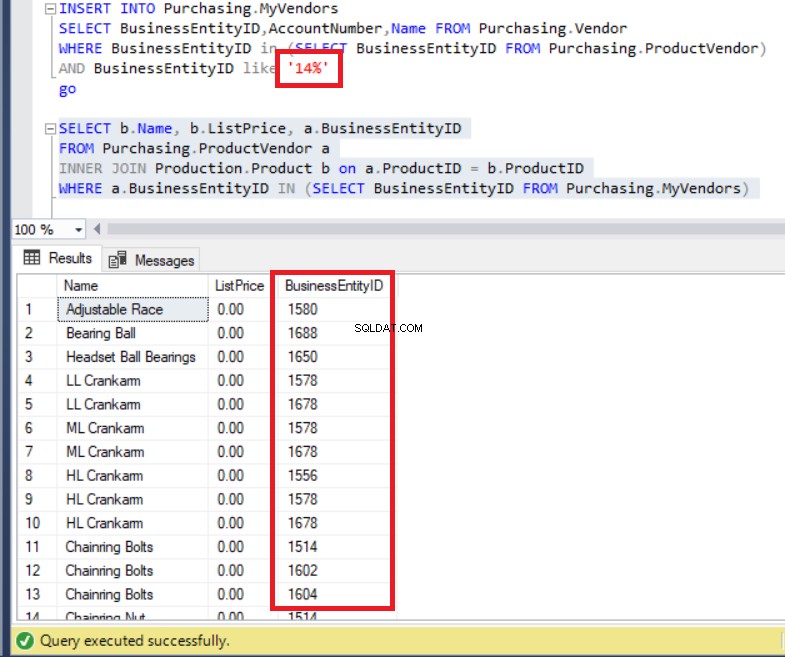
図7:結果セットのBusinessEntityIDがMyVendorsテーブルのレコードと矛盾しています
BusinessEntityIDでデータを挿入しませんでした 「14」で始まりますか?では、どうしたの?実際、 BusinessEntityIDsを確認できます。 「15」と「16」で始まります。これらはどこから来たのですか?
実際、クエリには ProductVendorからのすべてのデータがリストされていました テーブル。
その場合、エイリアスがこの問題を解決して、 MyVendorsを参照するようになると思うかもしれません。 以下のような表:
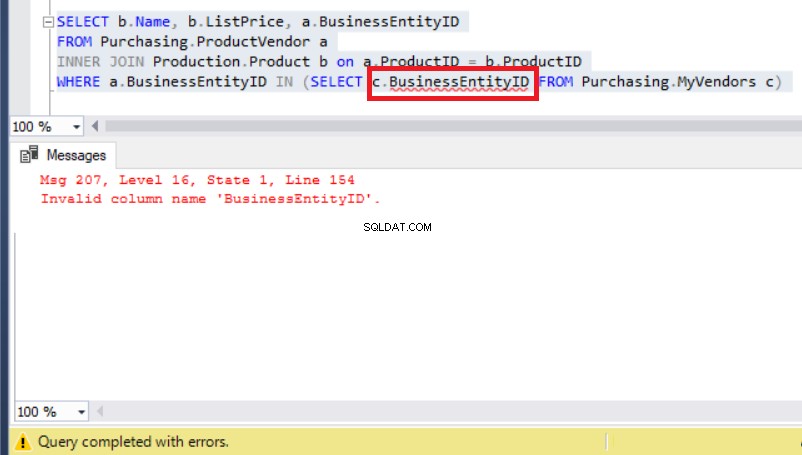
図8:BusinessEntityIDにエイリアスを追加すると、エラーが発生します
ただし、実行時エラーが原因で実際の問題が発生しました。
MyVendorsを確認してください テーブルをもう一度見ると、 BusinessEntityIDの代わりにそれが表示されます 、列名は BusinessEntity_idである必要があります (アンダースコア付き)。
したがって、以下に示すように、正しい列名を使用すると、最終的にこの問題が修正されます。
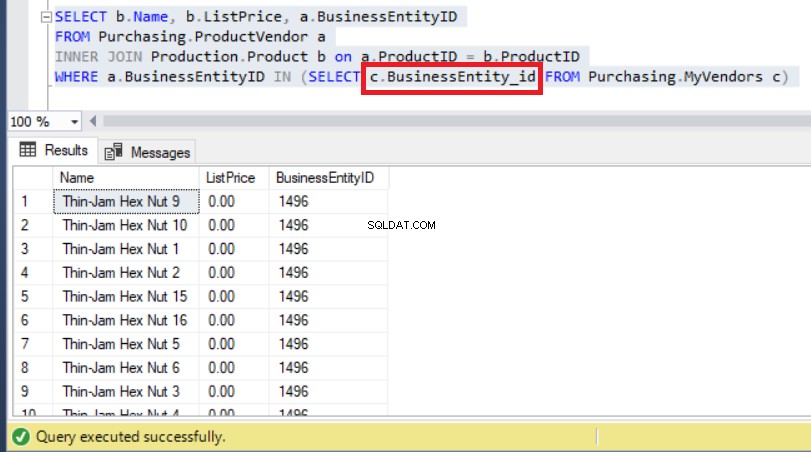
図9:サブクエリを正しい列名に変更すると問題が解決しました
上記のように、 BusinessEntityIDsを監視できるようになりました。 以前に予想したとおり、「14」から開始します。
しかし、疑問に思われるかもしれません。なぜSQL Serverは、そもそもクエリを正常に実行できるのでしょうか?
キッカーは次のとおりです。エイリアスのない列名の解決は、サブクエリのコンテキストで、それ自体が外部クエリに送信されることで機能します。そのため、 BusinessEntityIDへの参照 サブクエリの内部( ProductVendor )で見つかったため、サブクエリの内部ではエラーは発生しませんでした テーブル。
つまり、SQLServerはエイリアス化されていない列 BusinessEntityIDを探します。 MyVendors テーブル。そこにないので、外を見て ProductVendorで見つけました テーブル。クレイジーですね。
これはSQLServerのバグであると言うかもしれませんが、実際には、SQL標準の設計によるものであり、Microsoftがそれに準拠しています。
わかりました、それは明らかです。標準については何もできませんが、エラーが発生しないようにするにはどうすればよいですか?
- 最初に、列名の前にテーブル名を付けるか、エイリアスを使用します。つまり、プレフィックスなしまたはエイリアスなしのテーブル名は避けてください。
- 次に、列に一貫した名前を付けます。 BusinessEntityIDの両方を使用しないでください およびBusinessEntity_id 、たとえば。
いいですね?うん、これは状況にいくらかの正気をもたらす。
しかし、これで終わりではありません。
クレイジーNULL
私が言ったように、カバーすることがもっとあります。 T-SQLは、 NULL をサポートしているため、3値論理を使用します 。そしてNULL NOT IN でSQLサブクエリを使用すると、ほとんど気が狂う可能性があります 。
この例を紹介することから始めましょう:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)クエリの出力により、 MyVendorsにない製品のリストが表示されます。 表、以下に示すように:
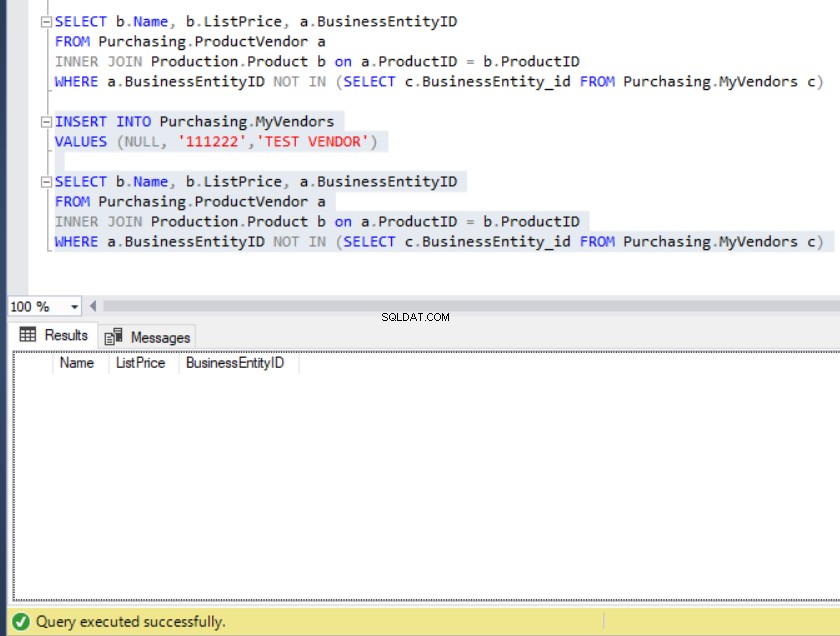
図10:NOTINを使用したサンプルクエリの出力
ここで、誰かが意図せずに MyVendorsにレコードを挿入したとします。 NULLのテーブル BusinessEntity_id 。それについてどうしますか?
図11:NULLのBusinessEntity_idがMyVendorsに挿入されると、結果セットは空になります
すべてのデータはどこに行きましたか?
ほら、ない オペレーターがINを否定しました 述語。したがって、正しくない FALSEになります 。ただし、NULLではありません 不明です。これにより、フィルターは不明な行を破棄しました。これが原因です。
これがあなたに起こらないようにするには:
- テーブル列でNULLを禁止する データがそのようになってはいけない場合。
- またはcolumn_nameを追加しますISNOT NULL どこに 句。この場合、サブクエリは次のとおりです。
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)要点
サブクエリについてはかなり話しましたが、この投稿の主なポイントを要約リストの形式で提供するときが来ました:
サブクエリ:
- はクエリ内のクエリです。
- 括弧で囲まれています。
- どこでも式を置き換えることができます。
- SELECTで使用できます 、挿入 、更新 、削除、 または他のT-SQLステートメント。
- 自己完結型または相互に関連している可能性があります。
- 単一、複数、またはテーブルの値を出力します。
- =、<>、>、<、> =、<=などの比較演算子と INなどの論理演算子で機能します /入っていない および存在 /存在しません 。
- 悪いことでも悪いことでもありません。 JOINよりもパフォーマンスが良くも悪くもなります ■状況によって異なります。ですから、私のアドバイスを参考にして、常に実行計画を確認してください。
- NULLで厄介な動作をする可能性があります ■NOTINとともに使用する場合 、および列がテーブルまたはテーブルエイリアスで明示的に識別されていない場合。
読書を楽しむためのいくつかの追加の参考資料に慣れてください:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators