すべての主要なRDBMS製品で、SQL制約の主キー 重要な役割を持っています。これらは、テーブルに存在するレコードを一意に識別します。したがって、パフォーマンスを向上させるために、テーブルの設計時に主キーサーバーを慎重に選択する必要があります。
この記事では、主キーの制約とは何かを学びます。また、主キーの制約を作成、変更、または削除する方法についても説明します。
SQLServerの制約
SQL Serverでは、制約 必要な列へのデータの入力を規制するルールです。制約により、データの正確性と、そのデータがビジネス要件にどのように一致するかが決まります。また、エンドユーザーにとってデータの信頼性を高めます。そのため、設計段階で正しい制約を特定することが重要です。 データベースまたはテーブルスキーマの。
SQL Serverは、次の制約タイプをサポートしています データの整合性を強化するには:
主キーの制約 レコードの一意性を強制し、レコードをより迅速に識別するために、単一の列または列の組み合わせで作成されます。関連する列はNULL値を保持するべきではありません。したがって、NOTNULLプロパティを列に定義する必要があります。
外部キーの制約 単一の列または列の組み合わせで作成され、2つのテーブル間の関係を作成し、1つのテーブルに存在するデータを別のテーブルに適用します。理想的には、外部キー制約を使用してデータを適用する必要があるテーブル列は、SQLの主キーまたは一意キー制約を使用してソーステーブルを参照します。つまり、ソーステーブルのプライマリキーまたは一意キーの制約で使用可能なレコードのみを、宛先テーブルに挿入または更新できます。
一意キーの制約 単一の列または列の組み合わせで作成され、列データ全体で一意性を強制します。これらは、1回の変更で主キー制約に似ています。主キーと一意キーの制約の違いは、後者はNullableで作成できることです。 列を作成し、その列に1つのNULL値レコードを許可します。
チェック制約 論理式を介して関係する列の受け入れられるデータ値を制限することにより、単一の列または列の組み合わせで作成されます。外部キー制約とチェック制約には違いがあります。外部キーは、別のテーブルの主キーまたは一意キーからのデータをチェックすることにより、データの整合性を強化します。ただし、チェック制約は論理式を使用してこれを行います。
それでは、主キーの制約について見ていきましょう。
主キー制約は、関連する列内にNULL値がない単一の列または列の組み合わせに一意性を適用します。
一意性を強化するために、SQL Serverは、主キーが作成された列に一意のクラスター化インデックスを作成します。既存のクラスター化インデックスがある場合、SQLServerは主キーのテーブルに一意の非クラスター化インデックスを作成します。
T-SQLスクリプトを使用して、テーブルで主キーを作成、変更、削除、無効化、または有効化する方法を見てみましょう。
テーブルの作成中または作成後に、テーブルに主キーを作成できます。これらのシナリオでは、構文が少し異なります。
構文は次のとおりです。
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Employeesという名前のテーブルを作成しましょう HumanResources 以下のスクリプトを使用したテスト目的のスキーマ:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
HumanResources.Employeesの作成に成功しました AdventureWorksの表 データベース:
上で強調表示されているように、クラスター化インデックスが主キー名と一致するテーブルに作成されたことがわかります。
以下のスクリプトを使用してテーブルを削除し、新しい構文で再試行してみましょう。
DROP TABLE HumanResources.Employeesユーザー定義の主キー名がPK_EmployeesのテーブルにSQLで主キーを作成するには 、次の構文を使用します:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
HumanResources.Employeesを作成しました 主キー名がPK_Employeesのテーブル :
開発者やDBAは、主キーを忘れて、主キーなしでテーブルを作成することがあります。ただし、既存のテーブルに主キーを作成することは可能です。
HumanResources.Employeesを削除しましょう テーブルを作成し、次のスクリプトを使用して再作成します。
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
このスクリプトを正常に実行すると、 HumanResources.Employeesが表示されます。 主キーまたはインデックスなしで作成されたテーブル:

PK_Employeesという名前の主キーを作成するには このテーブルでは、次の構文を使用します。
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
このスクリプトを実行すると、テーブルに主キーが作成されます:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
この例では、単一の列に主キーを作成しました。複数の列に主キーを作成する場合は、別の構文が必要です。
主キーの一部として複数の列を追加するには、主キーの一部である必要がある列名のカンマ区切り値を追加するだけです。
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
主キーを削除するには、次の構文を使用します。主キーが単一の列にあるか複数の列にあるかは関係ありません。
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
HumanResources.Employeesの主キー制約を削除するには 表については、以下のスクリプトを使用してください:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
主キーを削除すると、主キーと、主キーの作成とともに作成されたクラスター化インデックスまたは非クラスター化インデックスの両方が削除されます。
SQL Serverには、主キーを変更するための直接コマンドはありません。既存の主キーを削除し、必要な変更を加えて再作成する必要があります。したがって、主キーを変更する手順は次のとおりです。
- 既存の主キーを削除します。
- 必要な変更を加えた新しい主キーを作成します。
多くのレコードがあるテーブルで一括ロードを実行している間、パフォーマンスを向上させるために主キーを無効にしてから元に戻します。手順は次のとおりです。
次の構文で既存の主キーを無効にします。
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;HumanResources.Employeesの主キーを無効にするには テーブルの場合、スクリプトは次のとおりです。
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
無効状態にある既存の主キーを有効にします。次の構文を使用してインデックスを再構築する必要があります:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;HumanResources.Employeesで主キーを有効にするには 表では、次のスクリプトを使用します:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
多くの人が、SQLServerの主キーに関連する以下の神話について混乱しています。
- 主キーのあるテーブルはヒープテーブルではありません
- 主キーには、クラスター化インデックスとデータが物理的な順序で並べ替えられています
それらを明確にしましょう。
深く掘り下げる前に、主キーとヒープテーブルの定義を修正しましょう。
他に使用可能なクラスター化インデックスがない場合、主キーはテーブル上にクラスター化インデックスを作成します。クラスタ化インデックスのないテーブルはヒープテーブルになります。
これらの定義に基づいて、テーブルに他のクラスター化インデックスがない場合にのみ、主キーがクラスター化インデックスを作成することを理解できます。既存のクラスター化インデックスがある場合、主キーを作成すると、主キーに一致する非クラスター化インデックスがテーブルに作成されます。
HumanResources.Employees を削除して、これを確認しましょう。 テーブルとその再作成:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
主キーにNONCLUSTEREDインデックスオプションを指定できます(上記を参照)。テーブルは、プライマリ Key PK_Employeesの一意の非クラスター化インデックスを使用して作成されました 。
したがって、このテーブルは主キーを持っていてもヒープテーブルです。
キーワード非クラスター化を指定しない場合に、SQLServerが主キーの非クラスター化インデックスを作成できるかどうかを見てみましょう。 主キーの作成中。以下のスクリプトを使用してください:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
ここでは、主キーを作成する前に、クラスター化インデックスを個別に作成しました。また、テーブルに含めることができるクラスター化インデックスは1つだけです。したがって、SQL Serverは、一意の非クラスター化インデックスとして主キーを作成しました。現在、テーブルにはクラスター化されたインデックスがあるため、テーブルはヒープテーブルではありません。
気が変わって、クラスター化されたインデックスを First_Nameにドロップした場合 およびLast_Name 以下のスクリプトを使用した列:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
クラスタ化されたインデックスを正常に削除しました。 HumanResources.Employees テーブルで使用可能な主キーがある場合でも、テーブルはヒープテーブルです:
これにより、テーブルに使用可能なクラスター化インデックスがない場合、主キーを持つテーブルがヒープテーブルになる可能性があるという神話が明らかになります。
主キーには、クラスター化インデックスとデータが物理的な順序で並べ替えられます
前の例から学んだように、SQLの主キーは非クラスター化インデックスを持つことができます。その場合、レコードは物理的な順序で並べ替えられません。
主キーのクラスター化インデックスを使用してテーブルを確認しましょう。レコードが物理的な順序で並べ替えられているかどうかを確認します。
HumanResources.Employeesを再作成します Employee_ID の列が最小限で、IDENTITYプロパティが削除されたテーブル 列:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
主キーまたはクラスター化されたインデックスなしでテーブルを作成したので、 Employee_Idに対してソートされていない順序で3つのレコードを挿入できます。 列:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

HumanResources.Employeesから選択しましょう テーブル:
SELECT *
FROM HumanResources.Employees
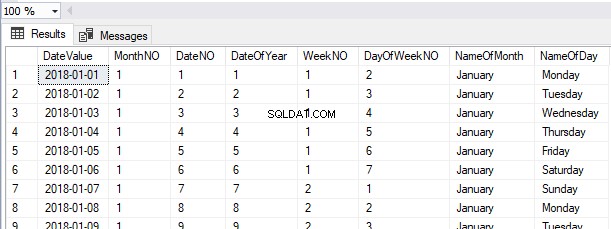
この時点でヒープテーブルから挿入されたレコードと同じ順序でフェッチされたレコードを確認できます。
このヒープテーブルに主キーを作成して、それがSELECTステートメントに影響を与えるかどうかを確認しましょう。
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

主キーの作成後、SELECTステートメントが Employee_Idの昇順でレコードをフェッチしたことがわかります。 (主キー列)。これは、 Employee_Idのクラスター化されたインデックスが原因です。 。
非クラスター化オプションを使用して主キーを作成した場合、テーブルデータは主キー列に基づいて並べ替えられません。
テーブル内の単一レコードの長さが4030バイトを超える場合、1ページに収まるのは1つのレコードのみです。クラスター化されたインデックスにより、ページが物理的な順序になっていることが保証されます。
ページは、サイズが8 KB(8192バイト)のSQLServerデータファイルのストレージの基本単位です。そのユニットの8060バイトのみがデータストレージに使用できます。残りの金額は、ページヘッダーおよびその他の内部用です。
- 整数データ型の列は、占有するストレージサイズが小さく、データの取得を高速化できるため、主キー列に最適です。
- 主キー列にはデフォルトでクラスター化インデックスがあるため、整数データ型の列でIDENTITYオプションを使用して、新しい値を増分順に生成します。
- 複数の列に主キーを作成する代わりに、IDENTITYプロパティが定義された新しい整数列を作成します。また、パフォーマンスを向上させるために最初に識別された複数の列に一意のインデックスを作成します。
- varchar、nvarcharなどの文字列データ型の列は避けてください。これらのデータ型のデータの順次増分を保証することはできません。これらの列のINSERTパフォーマンスに影響を与える可能性があります。
- 値が主キーとして更新されない列を選択します。たとえば、主キーの値を5から1000に変更できる場合、クラスター化インデックスに関連付けられているBツリーを更新する必要があり、パフォーマンスがわずかに低下します。
- 主キー列として文字列データ型列を選択する必要がある場合は、パフォーマンスを向上させるために、varcharまたはnvarcharデータ型列の長さを短くしてください。
SQLServerで使用できる制約の基本について説明しました。主キーの制約を詳細に調べ、主キーを作成、削除、変更、無効化、および再構築する方法を学びました。さらに、主キーに関するいくつかの一般的な神話を例を挙げて明らかにしました。
次の記事をお楽しみに!