追加: SQL Server 2012は、この領域でパフォーマンスが向上していることを示していますが、以下に示す特定の問題に取り組んでいないようです。これは、次のメジャーバージョンで後に修正されるはずです。 SQL Server 2012!
あなたの計画は、単一の挿入がパラメータ化された手順(おそらく自動パラメータ化)を使用していることを示しているので、これらの解析/コンパイル時間は最小限である必要があります。
もう少し調べてみようと思ったので、ループ(スクリプト)を設定してVALUESの数を調整してみました 句とコンパイル時間を記録します。
次に、コンパイル時間を行数で割って、句ごとの平均コンパイル時間を取得しました。結果は以下のとおりです
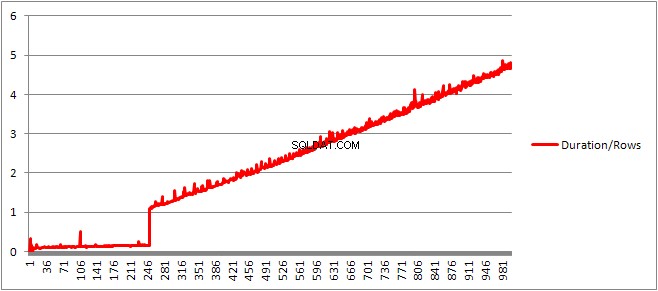
250までのVALUES 句はコンパイル時間を示します/句の数はわずかに増加傾向にありますが、それほど劇的なものではありません。
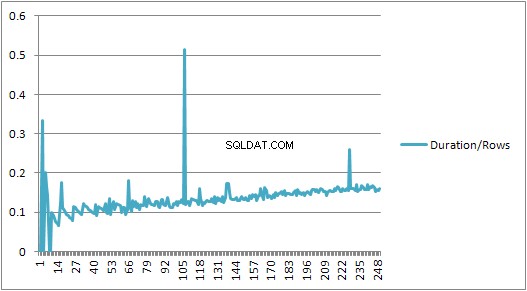
しかし、その後、突然の変化があります。
データのそのセクションを以下に示します。
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
直線的に増加していたキャッシュされたプランのサイズは突然減少しますが、CompileTimeは7倍に増加し、CompileMemoryは急上昇します。これは、自動パラメーター化されたプラン(1,000個のパラメーターを使用)とパラメーター化されていないプランの間のカットオフポイントです。その後、(特定の時間に処理される値句の数に関して)線形的に効率が低下するようです。
なぜそうあるべきかわからない。おそらく、特定のリテラル値の計画をコンパイルするときは、線形にスケーリングしないアクティビティ(並べ替えなど)を実行する必要があります。
完全に重複する行で構成されるクエリを試した場合、キャッシュされたクエリプランのサイズには影響しないようです。また、定数のテーブルの出力の順序にも影響しません(また、ヒープに挿入するときに、並べ替えに費やされる時間も影響しません)。とにかく無意味だろう)。
さらに、クラスター化されたインデックスがテーブルに追加された場合でも、プランには明示的な並べ替え手順が表示されるため、実行時の並べ替えを回避するために、コンパイル時に並べ替えられていないように見えます。

デバッガーでこれを確認しようとしましたが、私のバージョンのSQL Server 2008のパブリックシンボルが利用できないようであるため、代わりに同等のUNION ALLを確認する必要がありました。 SQLServer2005での構築。
典型的なスタックトレースは以下のとおりです
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
したがって、スタックトレースの名前を削除すると、文字列の比較に多くの時間がかかるように見えます。
このKB記事は、DeriveNormalizedGroupProperties クエリ処理の正規化段階と呼ばれていたものに関連付けられています
この段階は現在、バインディングまたは代数化と呼ばれ、前の解析段階から出力された式解析ツリーを取得し、代数化された式ツリー(クエリプロセッサツリー)を出力して最適化(この場合はトリビアルプランの最適化)に進みます[参照]。
元のテストを再実行するというもう1つの実験(スクリプト)を試しましたが、3つの異なるケースを調べました。
- 重複のない長さ10文字の名と名前の文字列。
- 重複のない長さ50文字の名と名前の文字列。
- 長さが10文字で、すべて重複している名前と名前の文字列。
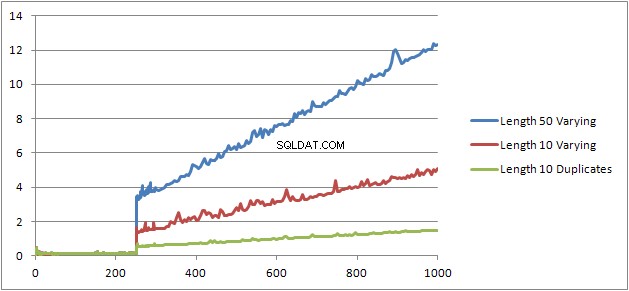
文字列が長くなるほど、状況は悪化し、逆に重複が増えると、状況は改善することがはっきりとわかります。前述のように、重複はキャッシュされたプランのサイズに影響を与えないため、代数化された式ツリー自体を構築するときに重複識別のプロセスが必要であると思います。
編集
この情報が活用される1つの場所は、@ Lieven here
によって示されています。SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
コンパイル時にNameであると判断できるためです。 列に重複がないため、セカンダリ1/ (ID - ID)による順序付けがスキップされます 実行時の式(プランの並べ替えにはORDER BYが1つだけあります 列)、ゼロ除算エラーは発生しません。重複がテーブルに追加されると、並べ替え演算子は列ごとに2つの順序を表示し、予期されるエラーが発生します。