答えはもちろん「状況によって異なります」ですが、この目的のテストに基づいています...
仮定
- 100万個の製品
productproduct_idにクラスター化されたインデックスがあります- ほとんどの(すべてではないにしても)製品の
product_codeに対応する情報があります テーブル -
product_codeに存在する理想的なインデックス 両方のクエリに対して。
PIVOT バージョンには、理想的にはインデックスが必要ですproduct_code(product_id, type) INCLUDE (code) 一方、JOIN バージョンには、理想的にはインデックスが必要ですproduct_code(type,product_id) INCLUDE (code)
これらが実施されている場合は、以下の計画を示します
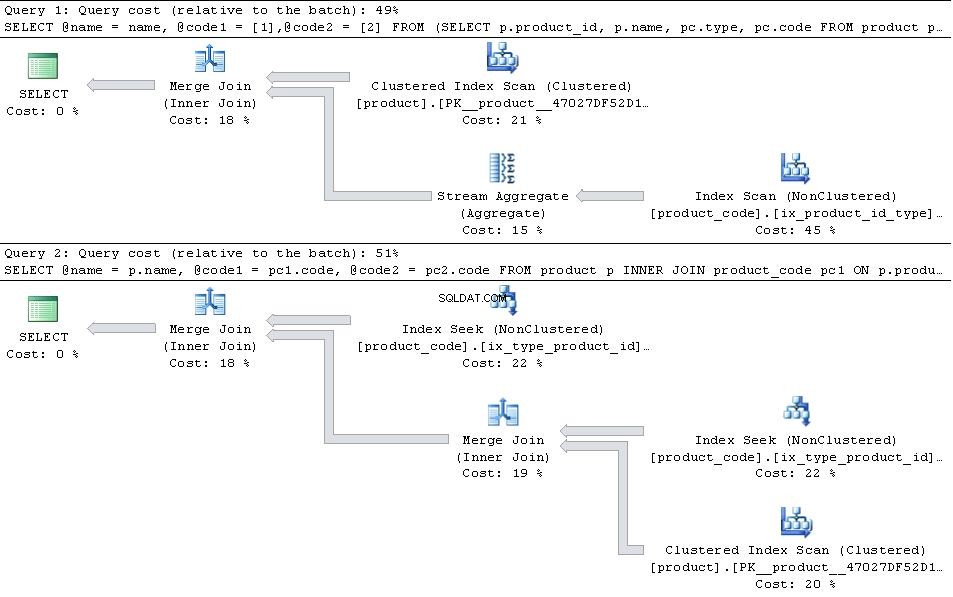
次に、JOIN バージョンはより効率的です。
type 1の場合 およびtype 2 typesは テーブル内でPIVOT バージョンは、product_codeを検索する必要がないため、読み取り数の点でわずかに優位性があります。 2回ですが、ストリーム集約演算子の追加のオーバーヘッドがそれを上回っています
PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
参加
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
追加のtypeがある場合 1以外のレコード および2 JOIN バージョンは、type,product_idの関連するセクションで結合をマージするだけなので、その利点が増えます。 PIVOTに対してインデックス プランはproduct_id, typeを使用します そのため、追加のtypeをスキャンする必要があります 1と混在している行 および2 行。