良いこともありますが、悪いこともあります。
パラメータスニッフィングは、提供されたパラメータの値を使用して、可能な限り最良のクエリプランを見つけるクエリオプティマイザに関するものです。多くの選択肢の1つであり、非常に理解しやすいのは、テーブル全体をスキャンして値を取得する必要があるかどうか、またはインデックスシークを使用すると高速になるかどうかです。パラメータの値が非常に選択的である場合、オプティマイザはおそらくシークを使用してクエリプランを構築し、そうでない場合はクエリがテーブルのスキャンを実行します。
次に、クエリプランはキャッシュされ、異なる値を持つ連続したクエリに再利用されます。パラメータスニッフィングの悪い部分は、キャッシュされたプランがこれらの値の1つに最適ではない場合です。
サンプルデータ:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
T は、Valueにクラスター化されていないインデックスを持つ数千行のテーブルです。値が1である行が1つあります 残りの値は2です。 。
サンプルクエリ:
select *
from T
where Value = @Value;
クエリオプティマイザがここで選択できるのは、クラスタ化インデックススキャンを実行してすべての行に対してwhere句をチェックするか、インデックスシークを使用して一致する行を検索し、キールックアップを実行してで要求された列から値を取得することです。列リスト。
スニッフィングされた値が1の場合 クエリプランは次のようになります:

そして、スニッフィングされた値が2の場合 次のようになります:
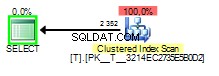
この場合のパラメータスニッフィングの悪い部分は、クエリプランが1をスニッフィングするように構築されている場合に発生します。 ただし、後で2の値で実行されます 。
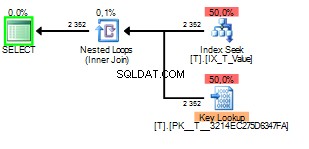
キールックアップが2352回実行されたことがわかります。スキャンは明らかに良い選択です。
要約すると、パラメータスニッフィングは、クエリにパラメータを使用して可能な限り実現するように努める必要がある良いことだと思います。うまくいかない場合もありますが、その場合は、データが歪んでいて統計が乱れている可能性があります。
更新:
これは、システムで最も高価なクエリを見つけるために使用できるいくつかのdmvに対するクエリです。探しているものに異なる基準を使用するには、orderby句に変更します。 TotalDurationだと思います 始めるのに良い場所です。
set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;