データベースはさまざまな方法で設計されています。ほとんどの場合、「学校の例」を使用できます。データベースを正規化すると、すべてが正常に機能します。しかし、別のアプローチが必要になる状況があります。参照を削除して、柔軟性を高めることができます。しかし、すべてが本によって行われたときにパフォーマンスを改善する必要がある場合はどうなりますか?その場合、非正規化は考慮すべき手法です。この記事では、非正規化のメリットとデメリット、およびそれが正当化される可能性のある状況について説明します。
非正規化とは何ですか?
非正規化は、パフォーマンスを向上させるために以前に正規化されたデータベースで使用される戦略です。その背後にある考え方は、最も役立つと思われる場所に冗長データを追加することです。既存のテーブルで追加の属性を使用したり、新しいテーブルを追加したり、既存のテーブルのインスタンスを作成したりすることもできます。通常の目標は、クエリがデータにアクセスしやすくするか、個別のテーブルに要約レポートを生成することにより、選択したクエリの実行時間を短縮することです。このプロセスはいくつかの新しい問題を引き起こす可能性があり、後でそれらについて説明します。
正規化されたデータベースは、非正規化プロセスの開始点です。正規化されていないデータベースと、最初に正規化されてから後で非正規化されたデータベースとを区別することが重要です。 2つ目は大丈夫です。 1つ目は、多くの場合、データベースの設計が不適切であるか、知識が不足していることが原因です。
例:非常に単純なCRMの正規化されたモデル
以下のモデルが例として役立ちます:
表を簡単に見てみましょう:
-
user_accountテーブルには、アプリケーションにログインしたユーザーに関するデータが格納されます(モデル、ロール、およびユーザー権限を単純化すると、アプリケーションから除外されます)。 クライアント表には、クライアントに関するいくつかの基本データが含まれています。製品表は、クライアントに提供される製品の一覧です。タスクテーブルには、作成したすべてのタスクが含まれています。各タスクは、クライアントに対する一連の関連アクションと考えることができます。各タスクには、関連する電話、会議、および提供および販売された製品のリストがあります。電話および会議テーブルには、すべての通話と会議に関するデータが保存され、それらがタスクとユーザーに関連付けられます。- 辞書
task_outcome、Meeting_outcomeおよびcall_outcomeタスク、会議、または電話の最終状態について考えられるすべてのオプションが含まれています。 -
product_offeredproduct_sold の間に、特定のタスクでクライアントに提供されたすべての製品のリストを格納しますクライアントが実際に購入したすべての製品のリストが含まれています。 -
supply_orderテーブルには、行ったすべての注文とproducts_on_orderに関するデータが格納されます表には、特定の注文の製品とその数量がリストされています。 償却表は、事故などにより償却された製品のリストです(例:ミラーの破損)。
データベースは単純化されていますが、完全に正規化されています。冗長性は見当たらないので、それでうまくいくはずです。比較的少量のデータを処理する限り、どのような場合でもパフォーマンスの問題は発生しません。
非正規化を使用する時期と理由
ほとんどすべての場合と同様に、非正規化を適用する理由を確認する必要があります。また、それを使用することによる利益が害を上回っていることを確認する必要があります。非正規化を確実に検討する必要がある状況がいくつかあります:
- 履歴の維持: データは時間の経過とともに変化する可能性があるため、レコードの作成時に有効だった値を保存する必要があります。どのような変化を意味しますか?ええと、人の名前と名前は変わる可能性があります。クライアントは、会社名やその他のデータを変更することもできます。タスクの詳細には、タスクが生成された時点で実際の値が含まれている必要があります。これが行われなかった場合、過去のデータを正しく再作成することはできません。これらの変更の履歴を含むテーブルを追加することで、この問題を解決できます。その場合、タスクと有効なクライアント名を返すselectクエリはより複雑になります。たぶん、余分なテーブルは最善の解決策ではありません。
- クエリパフォーマンスの向上: 一部のクエリでは、複数のテーブルを使用して、頻繁に必要なデータにアクセスする場合があります。クライアントの名前と販売された製品を返すために10個のテーブルを結合する必要がある状況を考えてみてください。パスに沿った一部のテーブルには、大量のデータが含まれている場合もあります。その場合は、
client_idを追加するのが賢明かもしれません。products_soldに直接属性を付けるテーブル。 - レポートの高速化: 特定の統計が非常に頻繁に必要です。ライブデータからそれらを作成することは非常に時間がかかり、システム全体のパフォーマンスに影響を与える可能性があります。一部またはすべてのクライアントの特定の年にわたるクライアントの売上を追跡したいとします。ライブデータからこのようなレポートを生成すると、データベース全体のほぼ全体が「掘り下げ」られ、速度が大幅に低下します。そして、その統計を頻繁に使用するとどうなりますか?
- 一般的に必要な値を事前に計算する: リアルタイムで生成する必要がないように、いくつかの値をすぐに計算できるようにしたいのです。
パフォーマンスの問題がない場合は、非正規化を使用する必要がないことを指摘することが重要です アプリケーションで。ただし、システムの速度が低下していることに気付いた場合、またはこれが発生する可能性があることに気付いた場合は、この手法の適用を検討する必要があります。ただし、使用する前に、クエリの最適化や適切なインデックス作成などの他のオプションを検討してください。すでに本番環境にある場合は非正規化を使用することもできますが、開発フェーズで問題を解決することをお勧めします。
非正規化のデメリットは何ですか?
明らかに、非正規化プロセスの最大の利点はパフォーマンスの向上です。ただし、料金を支払う必要があり、その価格は次の要素で構成されます。
- ディスク容量: データが重複するため、これは予想されることです。
- データの異常: 現在、データは複数の場所で変更される可能性があるという事実を十分に認識している必要があります。それに応じて、重複するすべてのデータを調整する必要があります。これは、計算値とレポートにも当てはまります。これは、一緒に完了する必要のあるすべての操作のトリガー、トランザクション、および/または手順を使用することで実現できます。
- ドキュメント: 適用したすべての非正規化ルールを適切に文書化する必要があります。後でデータベース設計を変更する場合は、すべての例外を調べて、それらをもう一度考慮する必要があります。問題を解決したので、もう必要ないかもしれません。または、既存の非正規化ルールに追加する必要があるかもしれません。 (例:クライアントテーブルに新しい属性を追加し、その履歴値を既に保存しているすべてのものと一緒に保存したい。これを実現するには、既存の非正規化ルールを変更する必要があります)。
- 他の操作を遅くする: データの挿入、変更、削除の操作が遅くなることが予想されます。これらの操作が比較的まれにしか発生しない場合、これは利点になる可能性があります。基本的に、1つの遅い選択をより多くの遅い挿入/更新/削除クエリに分割します。非常に複雑な選択クエリは、技術的にはシステム全体の速度を著しく低下させる可能性がありますが、複数の「より小さな」操作の速度を低下させても、アプリケーションのユーザビリティが損なわれることはありません。
- その他のコーディング: ルール2と3は追加のコーディングを必要としますが、同時にいくつかの選択クエリを大幅に簡素化します。既存のデータベースを非正規化する場合は、これらの選択したクエリを変更して、作業のメリットを得る必要があります。また、既存のレコードに新しく追加された属性の値を更新する必要があります。これももう少しコーディングが必要になります。
サンプルモデル、非正規化
以下のモデルでは、前述の非正規化ルールのいくつかを適用しました。ピンクのテーブルは変更されていますが、水色のテーブルは完全に新しいものです。
適用される変更とその理由

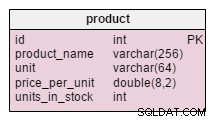
製品の唯一の変更点 表はunits_in_stockの追加です 属性。正規化されたモデルでは、このデータを注文されたユニット–販売されたユニット–(提供されたユニット)–償却されたユニットとして計算できます。 。クライアントがその製品を要求するたびに計算を繰り返しますが、これには非常に時間がかかります。代わりに、値を事前に計算します。お客様からの問い合わせがあれば、準備を整えます。もちろん、これにより選択クエリが大幅に簡素化されます。一方、 units_in_stock products_on_order で挿入、更新、または削除するたびに、属性を調整する必要があります 、償却 、 product_offered およびproduct_sold テーブル。
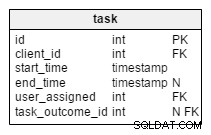
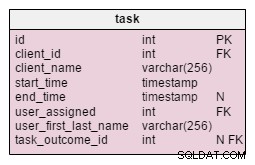
変更されたタスク テーブルには、2つの新しい属性があります: client_name およびuser_first_last_name 。どちらも、タスクの作成時に値を格納します。その理由は、これらの値の両方が時間の経過とともに変化する可能性があるためです。また、元のクライアントとユーザーIDに関連付ける外部キーも保持します。クライアントアドレス、VAT IDなど、保存したい値が他にもあります。




非正規化されたproduct_offered テーブルには、 price_per_unitという2つの新しい属性があります。 およびprice 。 price_per_unit 商品が提供されたときの実際の価格を保存する必要があるため、属性が保存されます。 。正規化されたモデルは現在の状態のみを表示するため、製品の価格が変更されると、「履歴」の価格も変更されます。私たちの変更は、データベースの実行を高速化するだけでなく、データベースの動作も向上させます。 価格 属性は計算値units_sold * price_per_unit 。提供されている製品のリストを確認するたびに計算を行わないようにするために、ここに追加しました。わずかなコストですが、パフォーマンスが向上します。
product_soldで行われた変更 テーブルは非常に似ています。テーブルの構造は同じですが、販売されたアイテムのリストが格納されます。
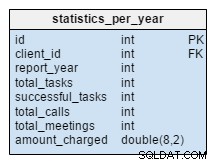
statistics_per_year テーブルは私たちのモデルにとって完全に新しいものです。すべてのデータは他のテーブルから計算できるため、非正規化テーブルと見なす必要があります。この表の背後にある考え方は、特定のクライアントに関連するタスク、成功したタスク、会議、および通話の数を保存することです。また、毎年の合計請求額も処理します。 タスクで何かを挿入、更新、または削除した後 、会議 、電話 およびproduct_sold テーブルの場合、そのクライアントと対応する年のこのテーブルのデータを再計算する必要があります。ほとんどの場合、今年のみ変更が行われると予想されます。過去数年間のレポートを変更する必要はありません。
この表の値は事前に計算されるため、計算結果が必要になった時点で費やす時間とリソースは少なくなります。頻繁に必要になる値について考えてください。たぶん、あなたはそれらすべてを定期的に必要とせず、それらのいくつかをライブで計算するリスクを冒す可能性があります。
非正規化は非常に興味深く強力な概念です。パフォーマンスを向上させるために最初に頭に入れておくべきことではありませんが、状況によっては、それが最善の解決策、または唯一の解決策になることもあります。
非正規化を使用することを選択する前に、それが必要であることを確認してください。分析を行い、パフォーマンスを追跡します。すでにライブになったら、おそらく非正規化を使用することにします。恐れずに使用してください。ただし、変更を追跡すれば、問題(つまり、恐ろしいデータの異常)が発生することはありません。