頭のてっぺんから、私はあなたのために50%の解決策を持っています。
問題
SSIS本当に メタデータを考慮しているため、メタデータのバリエーションによって例外が発生する傾向があります。この意味で、DTSははるかに寛容でした。一貫性のあるメタデータに対するその強い必要性は、フラットファイルソースの利用を面倒にします。
クエリベースのソリューション
問題がコンポーネントである場合は、使用しないでください。このアプローチで私が気に入っているのは、概念的には、テーブルのクエリと同じであるということです。列の順序は重要ではなく、余分な列の存在も重要ではありません。
変数
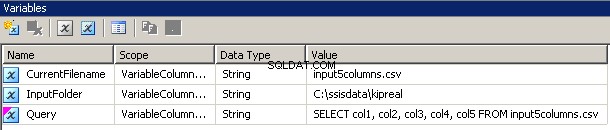
CurrentFileName、InputFolder、Queryの3つの変数を作成しました。すべて文字列型です。
- InputFolderはソースフォルダーに配線されています。私の例では、
C:\ssisdata\Kiprealです。 - CurrentFileNameはファイルの名前です。設計時は
input5columns.csvでした ただし、実行時に変更されます。 - クエリは式です
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
接続マネージャー
JET OLEDBドライバーを使用して、入力ファイルへの接続を設定します。リンク先の記事で説明されているように作成した後、名前をFileOLEDBに変更し、ConnectionManagerで"Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
制御フロー
私の制御フローは、Foreachファイル列挙子にネストされたデータフロータスクのように見えます
Foreachファイル列挙子
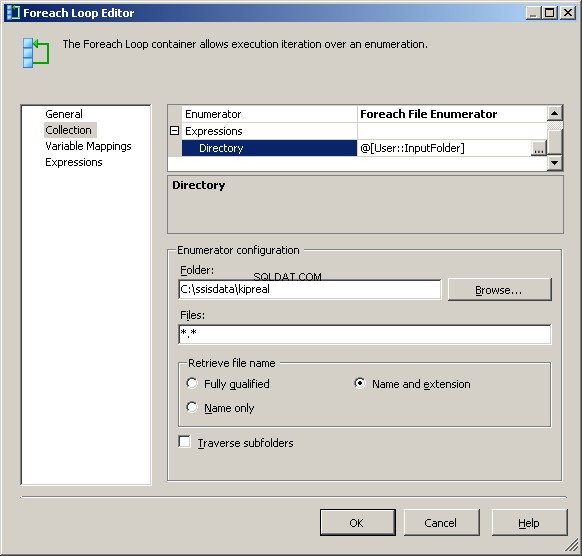
Foreachファイル列挙子はファイルを操作するように構成されています。 @[User::InputFolder]の式をディレクトリに配置しました この時点で、そのフォルダーの値を変更する必要がある場合は、接続マネージャーとファイル列挙子の両方で正しく更新されることに注意してください。 [ファイル名の取得]で、デフォルトの[完全修飾]ではなく、[名前と拡張子]を選択します
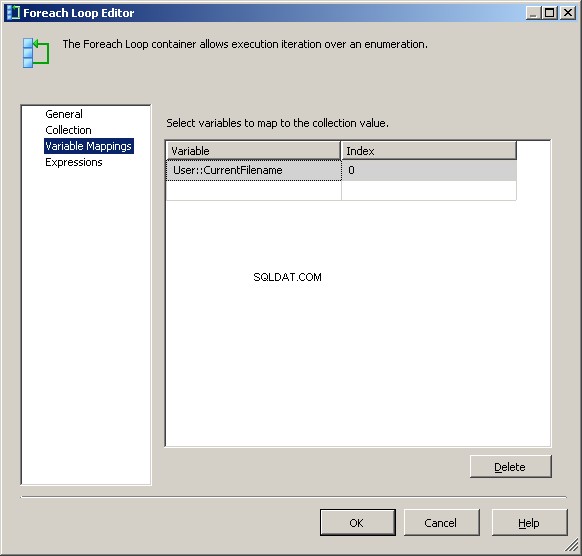
[変数マッピング]タブで、値を@[User::CurrentFileName]に割り当てます。 変数
この時点で、ループを繰り返すたびに、@[User::Queryの値が変更されます。 現在のファイル名を反映します。
データフロー
これは実際に最も簡単な作品です。 OLE DBソースを使用し、示されているように配線します。
FileOLEDB接続マネージャーを使用して、データアクセスモードを「変数からのSQLコマンド」に変更します。 @[User::Query]を使用します そこにある変数で、[OK]をクリックすると、作業の準備が整います。 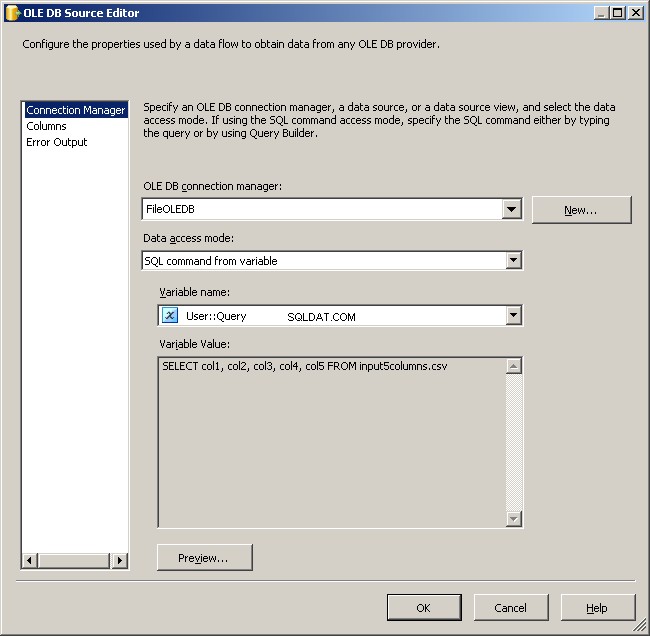
サンプルデータ
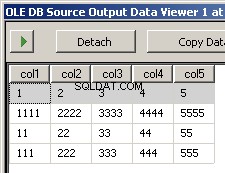
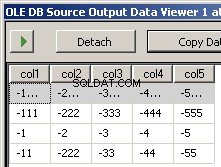
2つのサンプルファイルinput5columns.csvとinput7columns.csvを作成しました。5の列はすべて7ですが、7の順序は異なります(col2は序数の2と6です)。どのファイルが操作されているかがすぐにわかるように、7のすべての値を無効にしました。
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
および
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
パッケージを実行すると、これら2つのスクリーンショットが表示されます
不足しているもの
列が存在しなくても問題ないことをクエリベースのアプローチに伝える方法がわかりません。一意のキーがある場合は、必須の列のみを含むようにクエリを定義できると思います。 そこにいて、ファイルに対してルックアップを実行して、必要な列を取得しようとします。 そこにあり、列が存在しない場合でもルックアップに失敗しないようにします。でもかなり厄介です。