簡単な要約
- サブクエリメソッドのパフォーマンスは、データの分散によって異なります。
- 条件付き集計のパフォーマンスは、データの分散に依存しません。
サブクエリの方法は、条件付き集計よりも高速または低速になる可能性があり、データの分散によって異なります。
当然、テーブルに適切なインデックスがある場合、インデックスではフルスキャンではなくテーブルの関連部分のみをスキャンできるため、サブクエリはその恩恵を受ける可能性があります。とにかく完全なインデックスをスキャンするため、適切なインデックスがあると、条件付き集計方法に大きなメリットが得られる可能性は低くなります。唯一の利点は、インデックスがテーブルよりも狭く、エンジンがメモリに読み込むページが少なくて済む場合です。
これを知っていると、どの方法を選択するかを決めることができます。
最初のテスト
500万行の大きなテストテーブルを作成しました。テーブルにインデックスはありませんでした。SQLSentryPlanExplorerを使用してIOとCPUの統計を測定しました。これらのテストには、SQL Server 2014 SP1-CU7(12.0.4459.0)Express64ビットを使用しました。
実際、元のクエリは説明どおりに動作しました。つまり、読み取りが3倍高くても、サブクエリの方が高速でした。
インデックスのないテーブルで数回試行した後、条件付き集計を書き直し、 DATEADDの値を保持するように変数を追加しました 式。
全体の時間が大幅に速くなりました。
次に、 SUMを置き換えました COUNTを使用 再び少し速くなりました。
結局のところ、条件付き集計はサブクエリとほぼ同じくらい高速になりました。
キャッシュをウォームアップ (CPU =375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
サブクエリ (CPU =1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
元の条件付き集計 (CPU =1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
変数を使用した条件付き集計 (CPU =1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
SUMの代わりに変数とCOUNTを使用した条件付き集計 (CPU =1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

これらの結果に基づいて、私の推測では CASE 呼び出されたDATEADD 各行に対して、 WHERE 一度計算するのに十分賢かった。プラスCOUNT SUMよりも少し効率的です 。
結局、条件付き集計はサブクエリよりもわずかに遅いだけです(1062対1031)。おそらく WHERE CASEよりも少し効率的です それ自体、さらには WHERE かなりの数の行を除外するため、 COUNT より少ない行を処理する必要があります。
実際には、読み取りの数がより重要であると思うので、条件付き集計を使用します。テーブルが小さくてバッファプールに収まる場合、エンドユーザーにとってクエリは高速になります。ただし、テーブルが使用可能なメモリよりも大きい場合は、ディスクからの読み取りによってサブクエリが大幅に遅くなると予想されます。
2番目のテスト
一方、行をできるだけ早く除外することも重要です。
これは、テストのわずかなバリエーションであり、それを示しています。ここでは、しきい値をGETDATE()+ 100年に設定して、フィルター基準を満たす行がないことを確認します。
キャッシュをウォームアップ (CPU =344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
サブクエリ (CPU =500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
元の条件付き集計 (CPU =937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
変数を使用した条件付き集計 (CPU =750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
SUMの代わりに変数とCOUNTを使用した条件付き集計 (CPU =750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
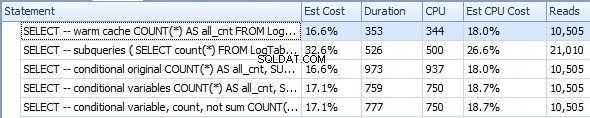
以下はサブクエリのあるプランです。 2番目のサブクエリで0行がStreamAggregateに入り、テーブルスキャンステップですべてが除外されたことがわかります。
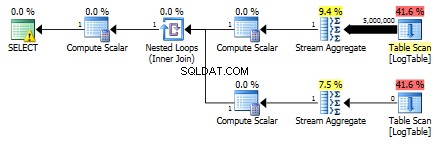
その結果、サブクエリは再び高速になります。
3番目のテスト
ここで、前のテストのフィルタリング基準を変更しました:すべての> <に置き換えられました 。その結果、条件付きの COUNT なしではなくすべての行をカウントしました。サプライズ、サプライズ!条件付き集計クエリは同じ750ミリ秒かかりましたが、サブクエリは500ではなく813になりました。

サブクエリの計画は次のとおりです。
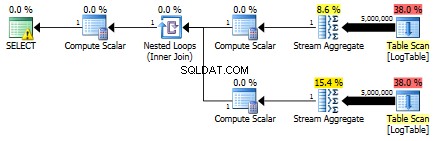
条件付き集計がサブクエリソリューションよりも著しく優れている例を教えてください。
ここにあります。サブクエリメソッドのパフォーマンスは、データの分散に依存します。条件付き集計のパフォーマンスは、データの分散に依存しません。
サブクエリメソッドは、条件付き集計よりも高速または低速になる可能性があり、データの分散によって異なります。
これを知っていると、どの方法を選択するかを決めることができます。
ボーナスの詳細
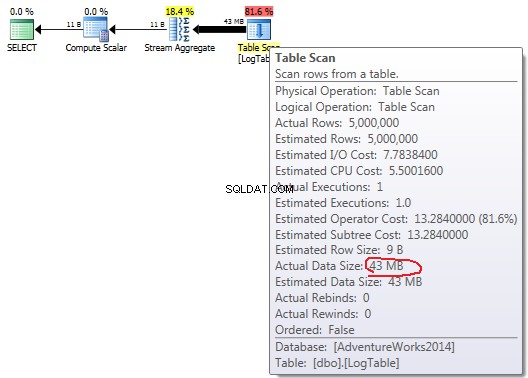
テーブルスキャンの上にマウスを置くと 演算子は、実際のデータサイズを確認できます さまざまなバリエーションで。
- シンプルな
COUNT(*):
- 条件付き集計:
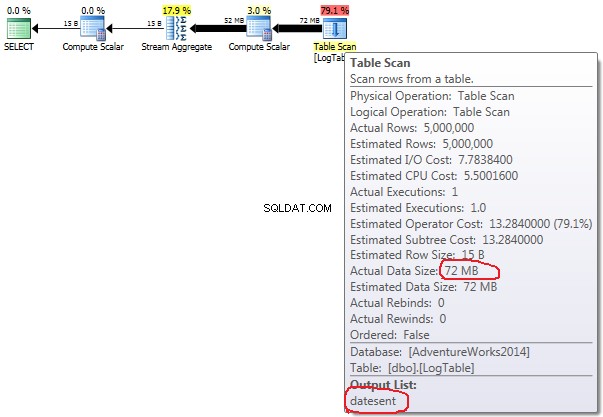
- テスト2のサブクエリ:
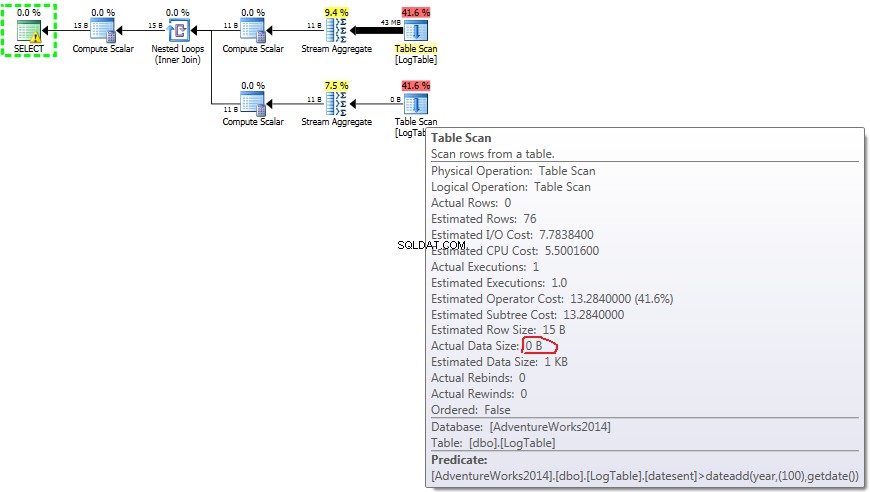
- テスト3のサブクエリ:
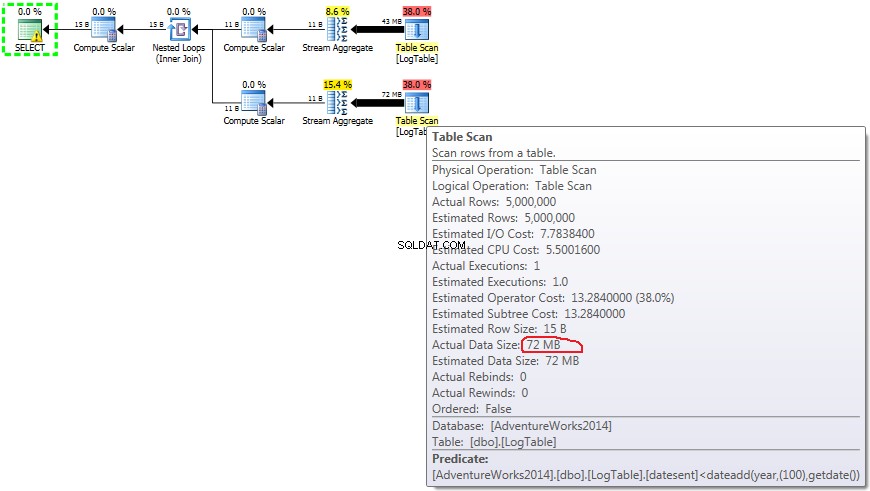
これで、パフォーマンスの違いは、プランを流れるデータの量の違いが原因である可能性が高いことが明らかになりました。
単純なCOUNT(*)の場合 出力リストはありません (列の値は必要ありません)、データサイズは最小(43MB)です。
条件付き集計の場合、この量はテスト2と3の間で変化せず、常に72MBです。 出力リスト datesentの列が1つあります 。
サブクエリの場合、この金額はあります データの分布に応じて変化します。