SQL Serverは、重要なシステムにサービスを提供するデータを可能な限り長い時間、可能な限り少ないダウンタイムで利用できるようにするのに役立つ、多数の高可用性および障害復旧ソリューションを提供します。 Microsoft SQL Serverが提供するこれらの高可用性および障害復旧ソリューションについては、SQLServerトランザクションログおよび高可用性ソリューションの記事で説明しています。
この記事では、可用性グループサイトをセットアップおよび構成し、会社の要件を満たすように構成する方法を示します。ただし、Always-onAvailabilityGroup機能の概要から始めましょう。
概要
SQLServer2012バージョンで導入されたSQLServerAlways-on Availability Groupは、Windows Serverフェールオーバークラスタリング機能上に構築されたエンタープライズレベルの高可用性および障害復旧ソリューションであり、1つまたは複数のデータベースが1つの可用性グループとして機能します。単一のユニットとしてフェイルオーバーしました。
可用性グループは、1つのプライマリレプリカでホストされ、データベースの読み取り/書き込みコピーを含み、最大8つのセカンダリレプリカと同期され、これらのデータベースの読み取り専用コピーを含む一連のデータベースのコンテナです。
データベースミラーリング機能の代わりに、Always on Availability Groupを使用して、読み取り専用のワークロードとバックアップ操作を処理するようにセカンダリレプリカを構成することにより、プライマリインスタンスの負荷を軽減できます。このように、Always-on Availability Groupを使用して、データベースの可用性を向上させ、すべてのレプリカのSQLServerリソース使用率を向上させることができます。
可用性グループのレプリカ間の同期プロセスは、サポートされている2つの可用性モードのいずれかで実行できます。
- 同期コミットモード :この可用性モードでは、プライマリレプリカは、セカンダリレプリカ(最大2つの同期セカンダリレプリカ)がデータベーストランザクションログファイルへのログの書き込みを確認するのを待ってから、プライマリレプリカでコミットします。この可用性モードは、トランザクションの待ち時間の価格よりもデータの可用性レベルを高めます。
- 非同期コミットモード :この可用性モードは主に、プライマリレプリカがセカンダリレプリカを待機しない遠隔データセンターに分散されているディザスタリカバリレプリカと同期するために使用され、ログを強化してプライマリ側でトランザクションをコミットし、提供するデータを減らします。可用性レベルとトランザクションの待ち時間の短縮。
レプリカ間で主要な役割が変更されるAlways-onAvailabilityGroupsフェイルオーバープロセスは、データベース管理者が手動で実行することも、サーバーレベルの障害が発生した場合はSQLServer自体が自動的に実行することもできます。データベースの破損など、データベースレベルの問題が発生した場合、フェイルオーバーは発生しません。
可用性グループごとにサーバー名を作成して、可用性グループ内の基になるSQL Serverインスタンス名と役割を呼び出すことなく、プライマリレプリカまたは読み取り専用レプリカに直接接続する機能をクライアントに提供できます。このサーバー名は、可用性グループリスナーと呼ばれます。 。
デモシナリオ
常時接続の可用性グループ機能について簡単に紹介した後、可用性グループを設定して適切に構成する準備が整いました。このデモでは、2つのSQLServerインスタンス間でAdventureWorks2017データベースを複製するための可用性グループを作成します。 SQL1およびSQL2、SQLServer2017はすでにこれらのサーバーにインストールされています。
テストとデモの目的で、SQL1インスタンスとSQL2インスタンスの両方のSQL Serverサービスは、これらのSQLServerインスタンスに対する適切なアクセス許可を持つay\sqladminサービスアカウントで実行されています。
はじめに
この記事の概要で説明したように、Always-on Availability Group機能は、WindowsServerフェールオーバークラスター機能の上に構築されています。そのため、可用性グループサイトを定義するフェールオーバークラスタリングサイトを作成する必要があります。
フェールオーバークラスターの作成
まず、フェールオーバークラスタリング機能が、可用性グループサイトに参加するすべてのレプリカにインストールされていることを確認する必要があります。これは、各レプリカでサーバーマネージャーダッシュボードを開き、[管理]メニューから[役割と機能の追加]オプションを選択してから、フェールオーバークラスタリングを確認してインストールすることで実行できます。 以下に示すように、そのウィザードの機能:

フェールオーバークラスタリング機能をインストールした後、フェールオーバークラスターマネージャーを開きます。 レプリカの1つでウィンドウを開き、ドメイン管理者権限を持つ承認されたローカル管理者アカウントを使用して、Active Directoryにそのクラスター名を作成できるようにし、クラスターの作成をクリックします。 オプション、以下のように:
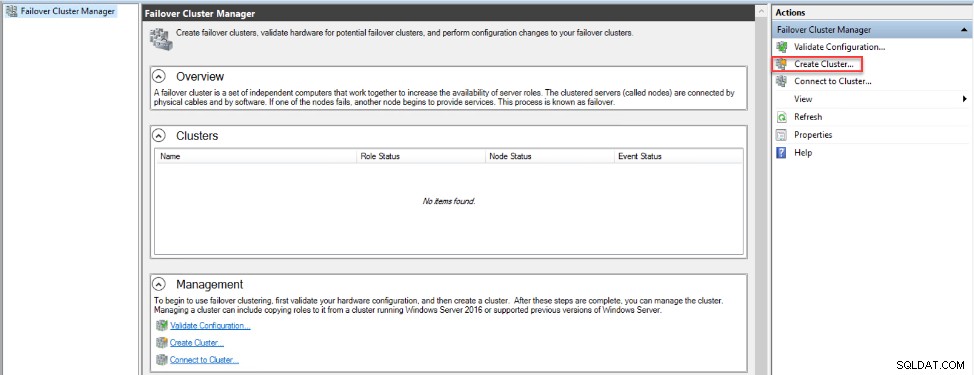
開いたクラスター作成ウィザードから 、始める前にに記載されている手順を確認してください ウィンドウをクリックし、次へをクリックします 続行するには:

次のページで、可用性グループに参加するレプリカの名前またはIPを入力し、[次へ]をクリックして続行します。

その後、フェールオーバークラスターを作成する前に、これらのサーバーで使用可能なリソースがフェールオーバークラスタリング機能と互換性があることを検証するために、クラスター検証テストを実行するかどうかを指定する必要があります。フェールオーバークラスターサイトを作成する前に、そのステップで検証テストを実行することを常にお勧めします。

これにより、構成ウィザードの検証に移動します。 。検証ウィザードの最初のページで、ウィザードの手順を確認し、[次へ]をクリックします 続行するには:

その後、推奨されるオプションであるすべてのフェールオーバークラスター検証を実行するか、特定のより高速なテストを選択するかを指定する必要があります。このデモでは、Microsoftが推奨するオプションを使用してすべての検証テストを実行し、[次へ]をクリックします。 続行するには:

また、この検証ウィザード内で実行される検証テストを確認し、次へをクリックして続行することを確認できます。 、次のように:

検証プロセスが完了したら、[レポートの表示]ボタンをクリックして検証テストの結果を確認するか、別のエンジニアにエクスポートして直面している問題を修正するか、[完了]をクリックしてクラスター作成プロセスを開始します。
>

今のところ、サーバーがフェールオーバークラスタリング機能の要件と互換性があることを確認し、フェールオーバークラスタリングサイトの作成を続行できます。 クラスタを管理するためのアクセスポイント ウィンドウで、フェールオーバークラスターの一意の名前とIPアドレスを入力し、[次へ]をクリックします。 続行するには:

その後、指定したクラスター作成設定を確認し、必ず削除してください。 対象となるすべてのストレージをクラスターに追加するの横にあるチェック 、Always on Availability Group機能は、各サーバーの専用ストレージを使用して機能し、使用しない 共有ストレージ。設定に問題がない場合は、[次へ]をクリックします 続行するには:

フェールオーバークラスタリングサイトが正常に作成されると、ウィザードは、以下のように、フェールオーバークラスタリングサイトが完全に作成されたことを通知します。

フェールオーバークラスターマネージャーを開くと、フェールオーバークラスターサイトが正常に作成されたことを確認できます。これにより、作成されたクラスターサイトと、そのクラスターのすべてのコンポーネントが次のように表示されます。

フェールオーバークラスターサイトを最高の可用性モードに保つには、フェールオーバークラスターをオンラインに保つタイミング、またはノードとリソースの投票に基づいてオフラインにするタイミングを制御するクラスタークォーラムを構成する必要があります。クラスタークォーラムを構成するには、フェールオーバークラスターマネージャーの下でクラスター名を右クリックし、クラスタークォーラム設定の構成を選択します。 その他のアクションのオプション 以下のようなメニュー。常時オンの可用性グループ機能に適したクォーラム設定の詳細については、SQLServerの常時オンの可用性グループのWindowsフェールオーバークラスタークォーラムモードを確認してください。

常にオンの可用性グループ機能を有効にする
可用性グループが作成されるフェールオーバークラスターを作成したら、Always-on Availability Group機能を有効にして、使用するフェールオーバークラスターサイトに接続する必要があります。
常時接続の可用性グループ機能を有効にするには、SQLServer構成マネージャー->SQL Serverサービスを開き、SQL Serverサービスを右クリックして、[プロパティ]オプションを選択します。 SQL Serverサービスのプロパティウィンドウから、常時稼働に移動します ページを開き、「可用性グループで常に有効にする」を確認します 以下に示すように、自動的に検出されたフェールオーバークラスター名の下にある「」ボックス:

この変更は、可用性グループに参加するすべてのレプリカで実行する必要があり、以下のようにSQLServerサービスを再起動した後に有効になることを考慮してください。

新しい常時接続の可用性グループを作成する
常時オンの可用性グループ機能を有効にした後、SSMSオブジェクトエクスプローラーの下の[常時オンの高可用性]ノードを展開して新しい可用性グループの作成を開始し、[可用性グループ]ノードを右クリックして[新規]を選択します。可用性グループウィザード 、以下に示すように:

新しい可用性グループウィザードの最初のページ は[はじめに]ページで、このウィザードで新しい可用性グループを作成するために実行される手順の簡単な説明を見つけることができます。提供された概要を確認し、[次へ]をクリックします 続行するには:

可用性グループオプションの指定 ウィンドウでは、レプリカで使用されているSQL Serverのバージョンとオペレーティングシステムに基づいて、可用性グループの名前、クラスターのタイプを指定する必要があります。ここで、WindowsServerフェールオーバークラスタリングから選択できます。 、Windows以外の EXTERNAL クラスターまたはなし クラスターが使用されていない場合。
このページでは、データベースレベルのヘルス検出を有効にすることもできます オプション。データベースがオンライン状態でなくなったことを確認し、可用性グループの自動フェイルオーバーを実行して、以下に示すように、データベースごとに可用性グループで分散トランザクションを有効にします。

その後、その可用性グループに参加するデータベースを選択する必要があります。ウィザードは、データベースの完全復旧モデルを含む可用性グループに追加するためにデータベースの事前要求をチェックし、データベースを追加する前にそのデータベースから完全バックアップが取得されることを確認します。含めるデータベースの要件を満たしたら、データベースリストを更新し、データベースを確認して、[次へ]をクリックします。 続行するには:

次のページの返信の下 タブで、この可用性グループに参加するすべてのSQL Serverレプリカを追加し、含まれているデータベースからのコピーをホストする必要があります。レプリカを追加した後、最大3つのインスタンスを選択して、同期コミット可用性モードで構成し、これらのレプリカと、非同期コミットモードで構成される残りのレプリカとの間の自動フェイルオーバーを許可できます。以下に示すように、各レプリカを読み取り専用接続の読み取り可能なセカンダリとして構成するか、読み取り専用の読み取り可能なレプリカとして構成して、リスナーによって自動的に指示される読み取り専用のワークロードを処理するかを決定することもできます。

[エンドポイント]タブで、レプリカ間の通信に使用される接続エンドポイントの設定を確認します。ここで、使用されているTCPポートがすべてのレプリカのファイアウォールルールで有効になっていること、および提供されたサービスアカウントに以下のように、レプリカのエンドポイントでの接続許可:

[バックアップ設定]タブで、可用性グループでバックアップジョブが実行される場所を指定する必要があります。これにより、優先オプションとしてセカンダリレプリカから、マストとしてセカンダリ、マストとしてプライマリ、または任意のレプリカから自動バックアップを実行できます。このオプションに基づいて、以下のように、可用性グループに参加しているデータベースからバックアップを取るための保守計画を作成できます。

同じウィンドウから、[リスナー]ページで可用性グループのリスナー設定を定義することも、今のところリスナーを作成せずに続行して後で作成を実行することもできます。このデモでは、以下に示すように、可用性グループを作成した後にリスナーを構成します。

また、[読み取り専用ルーティング]ページを使用して、セカンダリ内の読み取り専用ワークロードを制御するために使用される読み取り専用ルーティングリストを定義できます。詳細については、SQLServer2016で可用性グループの読み取り専用ルーティングを構成する方法を確認してください。

次のページでは、プライマリレプリカとセカンダリレプリカ間の初期データ同期プロセスに使用されるメカニズムを指定する必要があります。セカンダリを可用性グループに参加させてデータベースを同期することにより、同期を自動または手動で実行できます。後で手動で。
このウィザードで使用できる自動同期方法は2つあります。最初の方法は、共有フォルダーを指定して、完全バックアップとトランザクションログバックアップを一時的にコピーし、自動的に復元を実行する方法です。これは、このデモで使用します。または、直接シード方法を使用せずに使用します。ダイレクトシードを使用したSQLServer2016のAlwaysOn可用性グループで説明されているバックアップの作成:

完全なデータベースとログのバックアップを使用するには この方法では、共有フォルダーを作成し、以下に示すように、そのフォルダーに対するレプリカの読み取りおよび書き込みアクセス許可のSQLServerサービスアカウントを提供する必要があります。

その後、新しい可用性グループウィザードは、可用性グループの作成プロセスに進む前に、すべての構成の検証チェックを実行します。エラーがある場合は、直接修正してからページを更新し、[次へ]をクリックします。 続行するには:

最終段階で、ウィザードはすべてのウィザード構成の概要を提供して確認し、[完了]をクリックします。 以下のように、可用性グループの作成を開始します。

ウィザードが完了すると、各ステップの結果と、エラーが発生したかどうかが表示されます。それ以外の場合は、以下に示すように、可用性グループが問題なく正常に作成されたことを示すメッセージが表示されます。

また、SSMS Object Explorerを使用して、Always on可用性グループが正常に作成および構成されていることを検証できます。これには、参加しているデータベースがすべてのレプリカで同期状態にあり、レプリカとデータベースがAlways-onでオンラインになっていることを確認します。以下に示すように、高可用性ノード:

また、可用性グループ名の横にプライマリワードを付けてプライマリレプリカに接続し、[可用性グループのプロパティ]ページを確認して、新しいレプリカの追加など、新しい可用性グループウィザードで実行したのと同じタスクを実行することもできます。 、新しいデータベースの追加、各レプリカ構成の変更、バックアップ設定の変更、および読み取り専用ルーティングリストの定義を以下に示します。

常時接続の可用性グループリスナーを作成する
可用性グループを構成する最後のステップは、レプリカ名を指定せずにプライマリレプリカとセカンダリレプリカに接続するときに使用される可用性グループリスナーを作成することです。
可用性グループリスナーを作成するには、作成した可用性グループノードの下にある可用性グループリスナーノードを右クリックし、リスナーの追加を選択します。 オプション。開かれた新しい可用性グループリスナーから ウィンドウで、そのリスナーの名前、そのリスナーへの接続に使用されるTCPポート、およびリスナーに割り当てられる静的IPアドレスを入力し、[ OK]をクリックします。 それを作成します。リスナーが正常に作成されると、ウィンドウが自動的に閉じられ、以下に示すように、リスナー名がリスナーノードの下に表示されます。

リスナー名を使用して可用性グループに接続するには、以下に示すように、サーバーへの接続でリスナーの名前またはIPにTCPポート番号を指定すると、プライマリノードに直接接続されます。

フェイルオーバープロセスのテスト
可用性グループリスナーとレプリカへの接続をテストした後、フェイルオーバーの重要なテストを実行して、主要な役割が問題なくレプリカ間で移動され、データベースに到達可能であり、フェイルオーバー後の同期状態。
手動フェイルオーバーを実行するには、可用性グループ名を右クリックして、フェイルオーバーを選択します。 オプション、以下のように:

フェイルオーバー可用性グループの最初のページ ウィザードは、そのウィザードで実行できるアクションの概要を提供する[概要]ページです。紹介を確認し、[次へ]をクリックします 続行するには:

次のページで、新しいプライマリレプリカとして機能するノードを選択し、フェイルオーバー操作の実行時にデータ損失が発生しないことを確認してから、[次へ]をクリックして続行します。

その後、以下に示すように、このレプリカがオンラインで到達可能であることを確認するために、選択した新しいプライマリレプリカに接続する必要があります。

次に、概要ページのフェイルオーバーウィザード内で選択内容を確認し、[完了]をクリックしてフェイルオーバープロセスを開始します。

フェイルオーバーが完了したら、結果ページを確認して、以下のように、フェイルオーバープロセス中に問題が発生していないことを確認します。

以下に示すように、SSMS Object Explorerから、SQL1レプリカの役割が直接セカンダリに変更されます。

この記事では、可用性グループサイトの作成を準備するために実行する必要のある手順と、Always-on可用性グループサイトを作成および構成する方法について詳しく説明しました。次の記事では、既存の可用性グループサイトで直面する可能性のある問題のトラブルシューティング方法を説明します。しばらくお待ちください。