「カーソルをセットベースの操作に変更してください。そうすると高速になります」というアドバイスがたくさんあります。多くの場合そうなる可能性がありますが、常に正しいとは限りません。カーソルが典型的なセットベースのアプローチを繰り返し上回っているユースケースの1つは、現在の合計の計算です。これは、セットベースのアプローチでは通常、基になるデータの一部を複数回確認する必要があるためです。これは、データが大きくなるにつれて指数関数的に悪いことになる可能性があります。一方、カーソルは、聞こえるほど苦痛ですが、各行/値を1回だけステップスルーできます。
これらは、SQLServerの最も一般的なバージョンの基本的なオプションです。ただし、SQL Server 2012では、ウィンドウ関数とOVER句にいくつかの機能強化が加えられました。これは主に、MVPの仲間であるItzik Ben-Ganから提出されたいくつかの優れた提案に由来しています(彼の提案の1つです)。実際、Itzikには、「ウィンドウ関数を使用したMicrosoft SQLServer2012高性能T-SQL」というタイトルのこれらすべての拡張機能をより詳細にカバーする新しいMS-Pressブックがあります。
当然、私は興味がありました。新しいウィンドウ機能により、カーソルと自己結合の手法は廃止されますか?それらはコーディングが簡単でしょうか?どんな場合でも(すべてを気にしないで)速くなるでしょうか?他にどのようなアプローチが有効でしょうか?
セットアップ
テストを行うために、データベースを設定しましょう:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO 次に、テーブルに10,000行を入力します。これを使用して、いくつかの現在の合計を実行できます。それほど複雑なことはありません。各日付の行と、発行されたスピード違反切符の数を表す数値を含む要約テーブルだけです。数年前にスピード違反の切符を持っていなかったので、なぜこれが単純なデータモデルの潜在意識の選択だったのかわかりませんが、あります。
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
簡略化された結果:
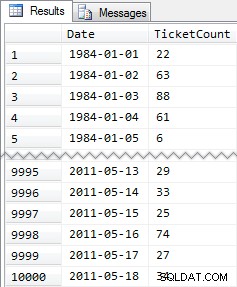
繰り返しになりますが、10,000行の非常に単純なデータ–小さなINT値と1984年から2011年5月までの一連の日付。
アプローチ
現在、私の割り当ては比較的単純で、多くのアプリケーションに典型的です。10,000の日付すべてを含む結果セットと、その日付までのすべてのスピード違反切符の累積合計を返します。ほとんどの人は最初にこのようなことを試みます(これを「内部参加」と呼びます) "方法):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
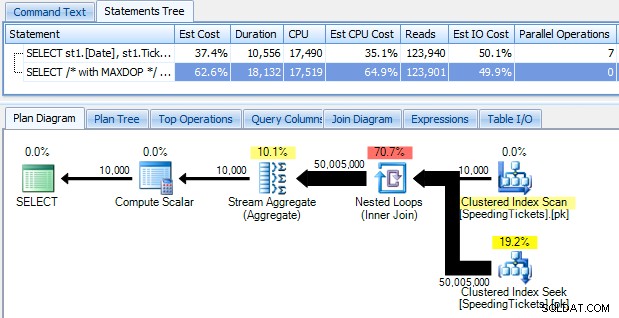
…そして、実行に10秒近くかかることを知ってショックを受けました。 SQL Sentryプランエクスプローラーを使用してグラフィカルな実行プランを表示することにより、その理由を簡単に調べてみましょう。

大きな太い矢印は、何が起こっているかを即座に示す必要があります。ネストされたループは、最初の集計で1行、2番目で2行、3番目で3行、そして10,000行のセット全体を繰り返し読み取ります。つまり、セット全体をトラバースすると、大まかに((10000 *(10000 + 1))/ 2)行が処理され、計画に示されている行数と一致するように見えます。
並列処理なしでクエリを実行すると(OPTION(MAXDOP 1)クエリヒントを使用)、プランの形状が少し単純になりますが、実行時間とI/Oのどちらでもまったく役に立ちません。計画に示されているように、期間は実際にはほぼ2倍になり、読み取りはごくわずかな割合でしか減少しません。以前の計画との比較:
人々が効率的な現在の合計を得るために試みた他の多くのアプローチがあります。一例として、「サブクエリメソッド」があります。 "これは、上記の内部結合メソッドとほぼ同じ方法で相関サブクエリを使用します。
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
これら2つの計画の比較:
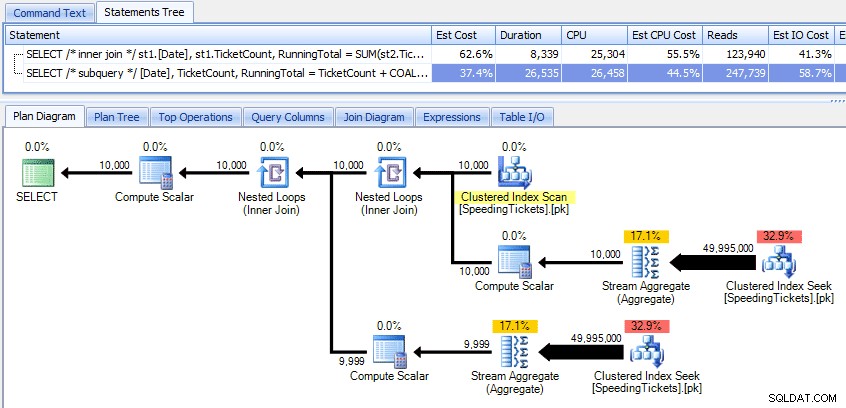
したがって、サブクエリメソッドの全体的な計画はより効率的であるように見えますが、重要な場合は、期間とI/Oの方が劣ります。計画をもう少し深く掘り下げることで、これに何が貢献しているかがわかります。 [トップ操作]タブに移動すると、内部結合メソッドで、クラスター化インデックスシークが10,000回実行され、他のすべての操作は数回しか実行されないことがわかります。ただし、サブクエリメソッドではいくつかの操作が9,999回または10,000回実行されます。
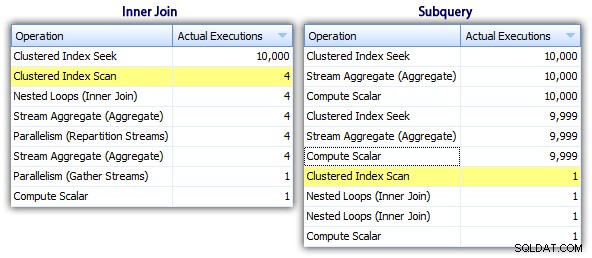
したがって、サブクエリのアプローチは悪く、良くはないようです。次に試す方法は、「風変わりな更新」と呼びます。 "メソッド。これは正確に機能することが保証されているわけではなく、本番コードにはお勧めしませんが、完全を期すために含めています。基本的に、風変わりな更新では、更新中に割り当てと計算をリダイレクトできるという事実を利用しています。各行が更新されると、変数は舞台裏で増分します。
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
「失敗することはない」という人々からの証言にかかわらず、このアプローチが本番環境で安全であるとは思わないことを改めて表明します。行動が文書化され保証されていない限り、私は観察された行動に基づく仮定から離れようとします。オプティマイザーの決定パスへの変更(統計の変更、データの変更、サービスパック、トレースフラグ、クエリヒント、何を使用しているかに基づく)がいつ計画を大幅に変更し、異なる順序につながる可能性があるかはわかりません。この直感的でないアプローチが本当に好きな場合は、クエリオプションFORCE ORDERを使用して少し気分を良くすることができます(これは、テーブル変数の唯一の適格なインデックスであるため、PKの順序付きスキャンを使用しようとします):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
わずかに高いI/Oコストでもう少し自信を持って、元のテーブルを元に戻し、ベーステーブルのPKが使用されていることを確認できます。
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
個人的には、操作のSET部分がクエリの残りの部分とは無関係にオプティマイザーに影響を与える可能性があるため、それほど保証されているとは思いません。繰り返しになりますが、このアプローチはお勧めしません。完全を期すための比較を含めているだけです。このクエリの計画は次のとおりです。
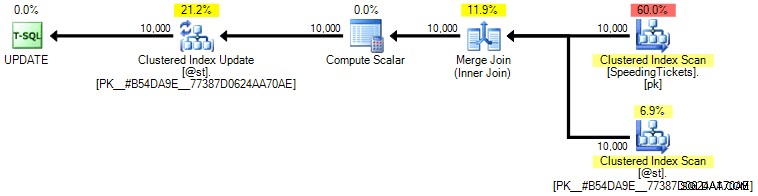
[トップ操作]タブに表示される実行数(スクリーンショットは割愛します。操作ごとに1つです)に基づいて、順序付けをより良くするために結合を実行しても、風変わりなことは明らかです。 updateを使用すると、データの1回のパスで現在の合計を計算できます。以前のクエリと比較すると、最初にデータをテーブル変数にダンプし、複数の操作に分割されている場合でも、はるかに効率的です。

これにより、「再帰CTE」が表示されます。 "メソッド。このメソッドは日付値を使用し、ギャップがないことを前提としています。上記のデータを入力したため、完全に連続したシリーズであることがわかりますが、多くのシナリオではそれを作成できません。したがって、完全を期すために含めましたが、このアプローチが常に有効であるとは限りません。いずれの場合も、テーブルの最初の(既知の)日付をアンカーとして再帰CTEを使用し、再帰CTEを使用します。 1日を追加することによって決定される部分(行数が正確にわかっているため、MAXRECURSIONオプションを追加する):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
このクエリは、風変わりな更新方法と同じくらい効率的に機能します。サブクエリおよび内部結合メソッドと比較できます:

風変わりな更新方法と同様に、キー列にギャップがないことを絶対的に保証できない限り、このCTEアプローチを本番環境で使用することはお勧めしません。データにギャップがある可能性がある場合は、ROW_NUMBER()を使用して同様のものを作成できますが、上記の自己結合メソッドよりも効率的ではありません。
そして、「カーソル」があります "アプローチ:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …これははるかに多くのコードですが、一般的な意見が示唆していることとは反対に、1秒で戻ります。上記の計画の詳細の一部から、理由がわかります。他のアプローチのほとんどは、同じデータを何度も読み取ることになりますが、カーソルアプローチは、すべての行を1回読み取り、合計を計算する代わりに、現在の合計を変数に保持します。そして何度も。これは、プランエクスプローラーで実際の計画を生成することによってキャプチャされたステートメントを見るとわかります。
20,000を超えるステートメントが収集されていることがわかりますが、推定行または実際の行を降順に並べ替えると、複数の行を処理する操作は2つしかないことがわかります。これは、新しい行ごとに同じ前の行を何度も読み取るために指数関数的な読み取りを引き起こす上記の方法のいくつかとはかけ離れています。
次に、SQL Server 2012の新しいウィンドウ拡張機能を見てみましょう。特に、SUM OVER()を計算して、現在の行を基準にした行のセットを指定できるようになりました。したがって、たとえば:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
これらの2つのクエリは、正しい現在の合計で、たまたま同じ答えを出します。しかし、それらはまったく同じように機能しますか?計画はそうではないことを示唆しています。 ROWSを使用したバージョンには、追加の演算子である10,000行のシーケンスプロジェクトがあります。
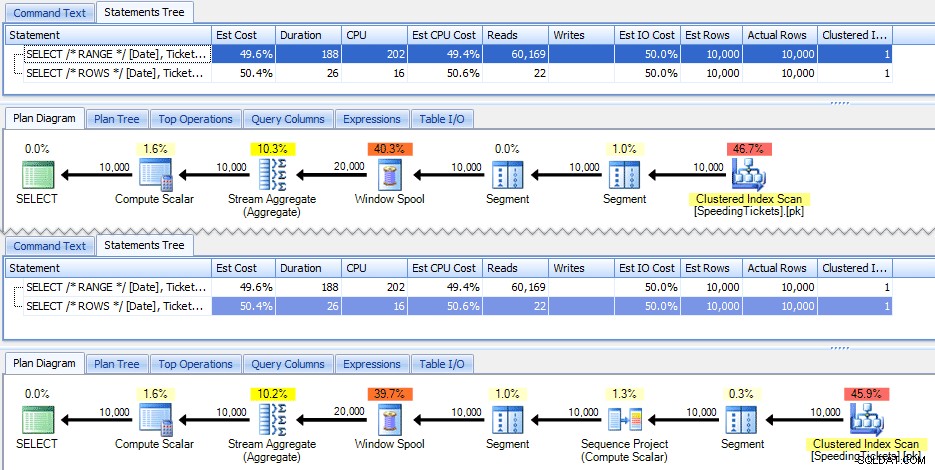
そして、それはグラフィカルな計画の違いの程度についてです。ただし、実際の実行時メトリックをもう少し詳しく見ると、期間とCPUにわずかな違いがあり、読み取りに大きな違いがあります。どうしてこれなの?これは、RANGEがディスク上のスプールを使用しているのに対し、ROWSはメモリ内のスプールを使用しているためです。セットが小さい場合、違いはおそらく無視できますが、セットが大きくなるにつれて、ディスク上のスプールのコストが明らかになる可能性があります。結末を台無しにしたくはありませんが、より徹底的なテストでは、これらのソリューションの1つが他のソリューションよりも優れていると思われるかもしれません。
余談ですが、次のバージョンのクエリでも同じ結果が得られますが、上記の遅いRANGEバージョンのように機能します。
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
したがって、新しいウィンドウ関数で遊んでいるときは、このようなちょっとした情報を覚えておく必要があります。クエリの短縮バージョン、または最初に作成したものは、必ずしも必要なものではありません。生産にプッシュします。
実際のテスト
公正なテストを実施するために、アプローチごとにストアドプロシージャを作成し、SQL Sentryで既に監視しているサーバーでステートメントをキャプチャして結果を測定しました(ツールを使用していない場合は、SQL:BatchCompletedイベントを収集できます)同様の方法でSQLServerProfilerを使用します)。
「公正なテスト」とは、たとえば、風変わりな更新方法では静的データを実際に更新する必要があることを意味します。つまり、基になるスキーマを変更するか、一時テーブル/テーブル変数を使用します。そこで、ストアドプロシージャを構造化して、それぞれ独自のテーブル変数を作成し、そこに結果を格納するか、そこに生データを格納してから結果を更新します。私が排除したかったもう1つの問題は、データをクライアントに返すことでした。そのため、各プロシージャには、結果を返さない(デフォルト)、上/下5、またはすべてを返すかどうかを指定するデバッグパラメータがあります。パフォーマンステストでは、結果を返さないように設定しましたが、もちろん、それぞれを検証して、正しい結果が返されることを確認しました。
ストアドプロシージャはすべてこのようにモデル化されています(データベースとストアドプロシージャを作成するスクリプトを添付したので、簡潔にするためにここにテンプレートを含めています):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO そして、私はそれらを次のようにまとめて呼び出しました:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
デフォルトのしきい値が5秒であるため、これらの呼び出しの一部がトップSQLに表示されていないことにすぐに気付きました。次のように、これを100ミリ秒に変更しました(本番システムではやりたくないことです!)。
繰り返します:この動作は本番システムでは容認されません!
上記のコマンドの1つがSQLの上位しきい値に捕らえられていないことがまだわかりました。それはWindowed_Rowsバージョンでした。そのため、そのバッチにのみ以下を追加しました:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
そして今、私はトップSQLで7行すべてが返されるようになりました。ここでは、CPU使用率の降順で並べ替えられています:
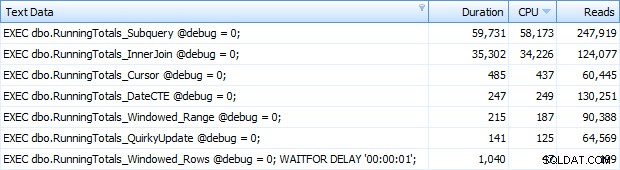
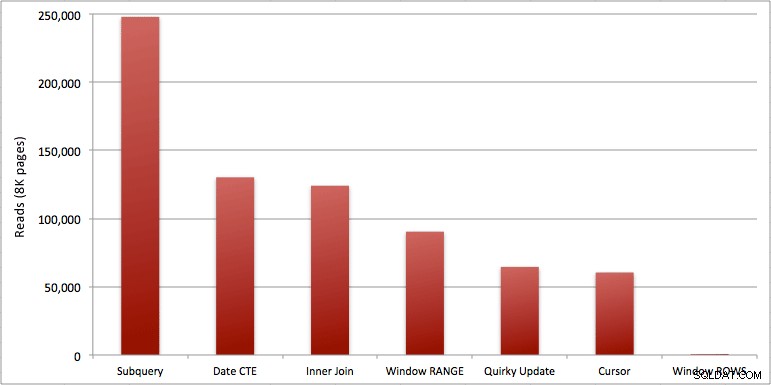
Windowed_Rowsバッチに追加した余分な秒を確認できます。わずか40ミリ秒で完了したため、SQLの上位しきい値に捕らえられませんでした。これは明らかに私たちの最高のパフォーマンスであり、SQL Server 2012を利用できる場合は、それを使用する方法にする必要があります。残りのソリューションのパフォーマンスまたはその他の問題を考えると、カーソルも半分悪くはありません。期間をグラフにプロットすることは、まったく意味がありません。2つの高いポイントと5つの区別できない低いポイントです。ただし、I / Oがボトルネックである場合は、読み取りの視覚化が興味深いと感じるかもしれません。
結論
これらの結果から、いくつかの結論を導き出すことができます。
- SQL Server 2012のウィンドウ化された集計により、現在の合計の計算に関するパフォーマンスの問題(および他の多くの次の行/前の行の問題)が驚くほど効率的になります。読み取り回数が少ないのを見て、何か間違いがあるのではないかと思い、実際に作業をするのを忘れていたに違いありません。ただし、いいえ、ストアドプロシージャがSpeedingTicketsテーブルから通常のSELECTを実行するだけの場合は、同じ数の読み取りが行われます。 (STATISTICS IOを使用して、これを自分で自由にテストしてください。)
- RANGEとROWSについて先に指摘した問題では、実行時間がわずかに異なります(期間の差は約6倍です。WAITFORで追加した秒を無視することを忘れないでください)が、ディスク上のスプールのため、読み取りの差は天文学的なものです。ウィンドウ化された集計がROWSを使用して解決できる場合は、RANGEを避けますが、両方が同じ結果をもたらすことをテストする必要があります(または、少なくともROWSが正しい答えを与えること)。同様のクエリを使用していて、RANGEもROWSも指定しない場合、プランはRANGEを指定した場合と同じように動作することにも注意してください。
- サブクエリと内部結合メソッドは比較的ひどいものです。これらの現在の合計を生成するために35秒から1分?そして、これはクライアントに結果を返さずに、単一の細いテーブルにありました。これらの比較を使用して、純粋にセットベースのソリューションが常に最良の答えであるとは限らない理由を人々に示すことができます。
- より高速なアプローチのうち、SQL Server 2012の準備がまだできておらず、風変わりな更新方法(サポートされていない)とCTE日付方法(連続したシーケンスを保証できない)の両方を破棄すると仮定すると、カーソルのみが実行されます許容できる。 「より高速な」ソリューションの期間は最も長くなりますが、読み取りの量は最も少なくなります。
これらのテストが、MicrosoftがSQL Server 2012に追加したウィンドウ拡張機能をよりよく理解するのに役立つことを願っています。オンラインまたは直接会った場合は、Itzikがこれらの変更の原動力であったため、必ず感謝してください。さらに、これが、カーソルが常に描かれている邪悪で恐ろしい解決策であるとは限らないという心を開くのに役立つことを願っています。
(補足として、Pavel Pawlowskiが提供するCLR機能をテストしました。パフォーマンス特性は、ROWSを使用したSQL Server 2012ソリューションとほぼ同じでした。読み取りは同じで、CPUは78対47で、全体の期間は73ではなく73でした。 40.したがって、近い将来SQL Server 2012に移行しない場合は、テストにPavelのソリューションを追加することをお勧めします。)
添付ファイル:RunningTotals_Demo.sql.zip(2kb)