「自分を繰り返さない」という原則は、繰り返しを減らす必要があることを示唆しています。今週、私はDRYが窓の外に投げ出されるべきであるというケースに出くわしました。他のケース(たとえば、スカラー関数)もありますが、これはビット単位のロジックを含む興味深いケースでした。
次の表を想像してみましょう:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); 「WheelFlag」ビットは、次のオプションを表します。
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
したがって、可能な組み合わせは次のとおりです。
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
少なくとも今のところ、これを最初に単一のTINYINTにパックするか、個別の列として格納するか、EAVモデルを使用するかについての議論を脇に置いておきましょう...設計の修正は別の問題です。これはあなたが持っているものを扱うことについてです。
例を便利にするために、このテーブルに一連のランダムデータを入力してみましょう。 (簡単にするために、このテーブルにはまだ出荷されていない注文のみが含まれていると仮定します。)これにより、6つのオプションの組み合わせの間に50,000行のほぼ等しい分布が挿入されます。
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; 内訳を見ると、この分布がわかります。システム内のオブジェクトによっては、結果が私の結果とわずかに異なる場合があることに注意してください。
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
結果:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
火曜日だとしましょう。以前は在庫がなかった18インチのホイールが出荷されました。これは、タイヤをアップグレードしたものも含め、18インチのホイールを必要とするすべての注文に対応できることを意味します(6)。そしてそうでなかったもの(2)。したがって、次のようなクエリを作成できます。
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); もちろん、実際の生活では、それを実際に行うことはできません。ホイールロック、生涯ホイール保証、複数のタイヤオプションなど、後でさらにオプションが追加された場合はどうなりますか?考えられるすべての組み合わせに対して一連のIN()値を記述する必要はありません。代わりに、BITWISE AND演算を記述して、次のように2番目のビットが設定されているすべての行を検索できます。
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; これにより、IN()クエリと同じ結果が得られますが、SQL Sentry Plan Explorerを使用してそれらを比較すると、パフォーマンスはまったく異なります。

理由は簡単にわかります。 1つ目は、インデックスシークを使用して、WheelFlag列にフィルターを使用して、クエリを満たす行を分離します。
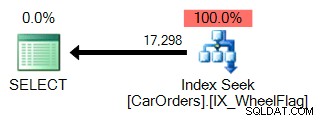

2つ目は、暗黙の変換と組み合わせたスキャンと、ひどく不正確な統計を使用します。すべてBITWISEAND演算子によるもの:
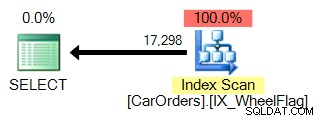


では、これはどういう意味ですか?その中心にあるのは、BITWISEAND演算は引数にできないということです。 。
しかし、すべての希望が失われるわけではありません。
DRYの原則を少し無視すると、WheelFlag列のインデックスを利用するために少し冗長にすることで、もう少し効率的なクエリを作成できます。 0を超えるWheelFlagオプション(アップグレードなし)を実行していると仮定すると、この方法でクエリを書き直して、WheelFlag値が少なくともフラグと同じ値(0と1を削除)でなければならないことをSQLServerに通知できます。 )、次に、そのフラグも含まれている必要があるという補足情報を追加します(したがって、5を削除します)。
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
この句の>=部分は、明らかにBITWISE部分でカバーされているため、ここでDRYに違反します。ただし、追加したこの句は仮可能であるため、BITWISE AND演算を2次検索条件に委任しても同じ結果が得られ、クエリ全体のパフォーマンスが向上します。上記のハードコードされたバージョンのクエリと同様のインデックスシークが見られます。見積もりはさらに離れていますが(別の問題として対処される可能性があります)、読み取りはBITWISEAND演算のみの場合よりも低くなります。

また、BITWISE AND演算を単独で使用した場合には見られなかった、インデックスに対してフィルターが使用されていることもわかります。

結論
繰り返すことを恐れないでください。この情報がオプティマイザーに役立つ場合があります。パフォーマンスを向上させるために基準を*追加*することは完全に直感的ではないかもしれませんが、オプティマイザーが正確な行を「簡単に」見つけるのではなく、追加の句がデータを絞り込んで最終結果を得るのに役立つ場合を理解することが重要です。単独で。