Benjamin Nevarezは、カリフォルニア州ロサンゼルスを拠点とする独立コンサルタントであり、SQLServerクエリのチューニングと最適化を専門としています。彼は「SQLServer2014クエリの調整と最適化」および「SQLServerクエリオプティマイザーの内部」の著者であり、「SQLServer2012の内部」の共著者です。リレーショナルデータベースで20年以上の経験を持つベンジャミンは、PASSサミット、SQL Server接続、SQLBitsなどの多くのSQLServer会議でも講演を行ってきました。ベンジャミンのブログはhttps://www.benjaminnevarez.comにあります。また、メールでbenjaminnevarez dot comに、ツイッターで@BenjaminNevarezにアクセスすることもできます。
SQL Server 2014に関するほとんどの情報、ブログ、およびドキュメントは、Hekatonおよびその他の新機能に焦点を当てていますが、新しいカーディナリティ推定器については多くの詳細が提供されていません。現在、BOLは、What’s New(Database Engine)セクションで間接的にのみ説明しており、SQL Server 2014には、「クエリプランを作成および最適化するコンポーネントの大幅な改善が含まれている」、およびALTER DATABASE ステートメントは、その動作を有効または無効にする方法を示しています。幸い、Campbell Fraser etal。による研究論文「SQLServerでのカーディナリティ推定モデルのテスト」を読むことで、いくつかの追加情報を得ることができます。このホワイトペーパーでは、新しい推定モデルの品質保証プロセスに焦点を当てていますが、新しいカーディナリティ推定器の基本的な紹介と、その再設計の動機についても説明しています。
では、カーディナリティ推定量とは何ですか?カーディナリティ推定器は、クエリプロセッサのコンポーネントであり、そのジョブは、クエリのリレーショナル操作によって返される行数を推定することです。この情報は、他のいくつかのデータとともに、効率的な実行プランを選択するためにクエリオプティマイザによって使用されます。カーディナリティ推定は、統計情報に依存する数学的モデルであるため、本質的に不正確です。また、文書化されていませんが、長年にわたって知られているいくつかの仮定に基づいています。それらのいくつかには、均一性、独立性、封じ込め、包含の仮定が含まれます。これらの仮定の簡単な説明は次のとおりです。
- 均一性 。ヒストグラムステップの範囲行内やヒストグラムが利用できない場合など、属性の分布が不明な場合に使用されます。
- 独立性 。リレーション内の属性が独立している場合に使用されます。ただし、それらの間の相関関係がわかっている場合を除きます。
- 封じ込め 。 2つの属性が同じである可能性がある場合に使用され、それらは同じであると見なされます。
- 包含 。属性を定数と比較するときに使用され、常に一致するものと見なされます。
興味深いことに、PASSサミットでの前回の講演で、クエリオプティマイザーの制限を打ち負かすという、これらの仮定の制限のいくつかについて話しました。それでも、著者が実際の経験によれば、これらの仮定は「頻繁に正しくない」と認めていることを論文で読んで驚いた。
現在のカーディナリティ推定器は、1998年12月にリリースされたSQL Server 7.0のクエリプロセッサ全体とともに作成されました。明らかに、このコンポーネントは、数年の間に複数の変更に直面し、SQL Serverの複数のリリース(修正、調整、拡張など)に直面しています。新しいT-SQL機能のカーディナリティ推定に対応します。それで、あなたは考えているかもしれません、なぜ約15年間使用されてきたコンポーネントを交換するのですか?
なぜ新しいカーディナリティ推定量
このペーパーでは、次のような再設計の理由のいくつかについて説明しています。
- カーディナリティ推定量を新しいワークロードパターンに対応させるため。
- カーディナリティ推定量に何年にもわたって加えられた変更により、コンポーネントの「デバッグ、予測、および理解」が困難になりました。
- 現在のアーキテクチャを使用して現在のモデルを改善することは困難であったため、(a)特定の見積もりの計算方法を決定し、(b)実際に計算を実行するタスクの分離に焦点を当てた新しい設計が作成されました。 。
新しいカーディナリティ推定量に関する詳細がMicrosoftによって公開されるかどうかはわかりません。結局のところ、15年間で、古いカーディナリティ推定量についての詳細はそれほど多く公開されていません。たとえば、特定のカーディナリティ推定がどのように計算されるか。一方、カーディナリティ推定の問題をトラブルシューティングするため、またはそれがどのように機能するかを調べるために使用できる新しい拡張イベントがあります。これらのイベントには、query_optimizer_estimate_cardinalityが含まれます 、inaccurate_cardinality_estimate 、query_optimizer_force_both_cardinality_estimation_behaviors およびquery_rpc_set_cardinality 。
計画の回帰
クエリオプティマイザ内のこのような大きな変更で頭に浮かぶ主な懸念は、プランの回帰です。プランのリグレッションの恐れは、クエリオプティマイザの改善に対する最大の障害と見なされてきました。リグレッションは、クエリオプティマイザーに修正が適用された後に発生する問題であり、古典的な「二つの間違いは正しい」と呼ばれることもあります。これは、たとえば1つは値を過大評価し、もう1つは値を過小評価するなど、2つの悪い見積もりが互いに打ち消し合い、幸運にも良い見積もりが得られた場合に発生する可能性があります。これらの値の1つだけを修正すると、誤った見積もりにつながる可能性があり、プラン選択の選択に悪影響を及ぼし、回帰を引き起こす可能性があります。
新しいカーディナリティ推定器に関連するリグレッションを回避するために、SQL Serverは、データベースの互換性レベルに依存するため、それを有効または無効にする方法を提供します。これは、ALTER DATABASEを使用して変更できます 前に示したように、ステートメント。データベースを互換性レベル120に設定すると、新しいカーディナリティ推定量が使用され、互換性レベルが120未満の場合は、古いカーディナリティ推定量が使用されます。さらに、特定のカーディナリティ推定量を使用すると、もう一方に変更するために使用できる2つのトレースフラグがあります。現時点では、トレースフラグはどこにも文書化されていませんが、query_optimizer_force_both_cardinality_estimation_behaviorsの説明の一部として記載されています。 拡張イベント。トレースフラグ2312を使用して新しいカーディナリティ推定器を有効にし、トレースフラグ9481を使用して無効にすることができます。 QUERYTRACEONを使用して、特定のクエリにトレースフラグを使用することもできます。 ヒント(ただし、これもサポートされるかどうかはまだ文書化されていません)。
例
最後に、このペーパーでは、過密な主キー、単純な結合、昇順のキーの問題など、テストされたシナリオについても説明しています。また、作成者が複数のシナリオ(またはモデルのバリエーション)を実験し、場合によっては、カーディナリティ推定量によって行われた仮定の一部を「緩和」した方法も示します。たとえば、独立性の仮定の場合、完全な独立から完全な相関に移行します。良い結果が見つかるまで、その間に何かがあります。
論文には詳細が記載されていませんが、新しいカーディナリティ推定量がどのように機能するかを理解するために、これらのシナリオのいくつかのテストを開始することにしました。ここでは、独立性の仮定と昇順キーを使用した例を示します。均一性の仮定もテストしましたが、これまでのところ、推定に違いは見られませんでした。
独立性の仮定の例から始めましょう。まず、現在の動作を見てみましょう。そのためには、AdventureWorks2012データベースで次のステートメントを実行して、古いカーディナリティ推定量を使用していることを確認してください。
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
次に実行します:
SELECT * FROM Person.Address WHERE City = 'Burbank';
次に示すように、推定196レコードを取得します。

同様の方法で、次のステートメントは194の推定値を取得します。
SELECT * FROM Person.Address WHERE PostalCode = '91502';
両方の述語を使用する場合、次のクエリがあります。これには、1.93862の推定行数があります(SQL Sentry Plan Explorerを使用している場合は2行に切り上げられます):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
この値は、式(196 * 194)/ 19614.0(19614はテーブルの行の総数)を使用して、両方の述部が完全に独立していると仮定して計算されます。郵便番号91502のすべてのレコードはバーバンクに属しているため、合計相関を使用すると、194の推定値が得られます。新しいカーディナリティ推定量は、完全な独立性または完全な相関を想定しない値を推定します。次のステートメントを使用して、新しいカーディナリティ推定量に変更します。
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
同じステートメントを再度実行すると、19.3931行の推定値が得られます。これは、完全な独立性と完全な相関関係(Plan Explorerでは19行に切り上げ)を想定した値の間の値であることがわかります。使用される式は、最も選択的なフィルターの選択性* SQRT(次に最も選択的なフィルターの選択性)または(194 / 19614.0)* SQRT(196 / 19614.0)* 19614であり、19.393:

データベースレベルで新しいカーディナリティ推定量を有効にし、プランのリグレッションを回避するために特定のクエリに対して無効にしたい場合は、前に説明したようにトレースフラグ9481を使用できます。
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
注:QUERYTRACEONクエリヒントは、クエリレベルでトレースフラグを適用するために使用され、現在、限られた数のシナリオでのみサポートされています。 QUERYTRACEONクエリヒントの詳細については、http://support.microsoft.com/kb/2801413を参照してください。
次に、この投稿で詳しく説明したトピックである、昇順のキーの問題を見てみましょう。この問題を修正するためのMicrosoftの従来の推奨事項は、ここで説明するように、データのロード後に統計を手動で更新することです。これは、次のように問題を説明します。
IDENTITYやリアルタイムのタイムスタンプ列などの昇順または降順のキー列の統計では、クエリオプティマイザが実行するよりも頻繁に統計を更新する必要がある場合があります。挿入操作は、昇順または降順の列に新しい値を追加します。追加された行数が少なすぎて、統計の更新をトリガーできない可能性があります。統計が最新ではなく、クエリが最後に追加された行から選択された場合、現在の統計には、これらの新しい値のカーディナリティ推定が含まれません。これにより、カーディナリティの見積もりが不正確になり、クエリのパフォーマンスが低下する可能性があります。たとえば、最新の販売注文日のカーディナリティ推定値を含むように統計が更新されていない場合、最新の販売注文日から選択するクエリでは、カーディナリティの推定値が不正確になります。
私の記事での推奨事項は、トレースフラグ2389および2390を使用することでした。これらは、IanJoseの記事「昇順キーと自動クイック修正統計」で最初に公開されました。この問題を回避するためにこれらのトレースフラグを使用する方法の説明と例については、私の記事を読むことができます。これらのトレースフラグは、SQL Server2014CTP2でも引き続き機能します。ただし、さらに良いことに、新しいカーディナリティ推定量を使用している場合は、これらは不要になります。
私の投稿で同じ例を使用しています:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); データを挿入します:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
インデックスを作成したので、新しい統計があります。次のクエリを実行すると、35行の適切な見積もりが作成されます。
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
新しいデータを挿入する場合:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
次に示すように、古いカーディナリティ推定量を使用して推定値を確認できます。
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

挿入されたレコードの数が少ないため、統計オブジェクトの自動更新をトリガーするのに十分ではなかったため、現在のヒストグラムは追加された新しいレコードを認識せず、クエリオプティマイザーは推定1行を使用します。オプションで、トレースフラグ2389および2390を使用して、より適切な見積もりを取得することができます。ただし、新しいカーディナリティ推定量を使用して同じクエリを試行すると、次の推定値が得られます。
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
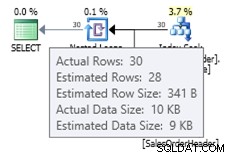
この場合、古いカーディナリティ推定器よりも優れた推定値が得られます(または、トレースフラグ2389または2390を使用した場合と同じ推定値が得られます)。 27.9631の推定値(ここでも、Plan Explorerによって28に丸められます)は、統計オブジェクトの密度情報にテーブルの行数を掛けて計算されます。つまり、0.0008992806 * 31095です。密度値は、次を使用して取得できます。
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); 最後に、この記事で言及されていることは何も文書化されていないことを覚えておいてください。これは、SQL Server2014CTP2でこれまでに観察した動作です。これらはいずれも、後のCTPまたはRTMバージョンの製品で変更される可能性があります。