ユーザーフレンドリーな検索の実装は難しい場合がありますが、非常に効率的に実行することもできます。どうすればこれを知ることができますか?少し前まで、私はモバイルアプリに検索エンジンを実装する必要がありました。このアプリはIonicフレームワーク上に構築されており、CakePHP2バックエンドに接続します。アイデアは、ユーザーが入力しているときに結果を表示することでした。これにはいくつかのオプションがありましたが、すべてが私のプロジェクトの要件を満たしているわけではありませんでした。
この種のタスクに含まれるものを説明するために、曲とそれらの可能な関係(アーティスト、アルバムなど)を検索することを想像してみましょう。
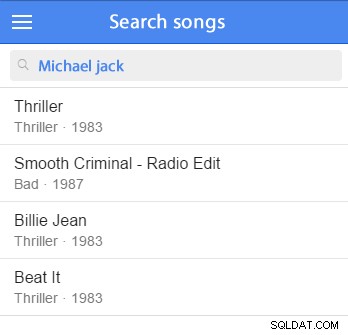
レコードは関連性でソートする必要があります。これは、検索語がレコード自体のフィールドと一致するか、関連するテーブルの他の列のフィールドと一致するかによって異なります。また、検索では、少なくともいくつかの基本的な単語のステミングを実装する必要があります。 (語幹は、単語の語根形式を取得するために使用されます。「語幹」、「語幹」、「語幹」、「語幹」はすべて同じ語根「語幹」を持ちます。)
ここで紹介するアプローチは、数十万のレコードでテストされ、ユーザーが入力しているときに有用な結果を取得することができました。
考慮すべき全文検索製品
この種の検索を実装する方法はいくつかあります。私たちのプロジェクトには時間とサーバーリソースに関していくつかの制約があったため、ソリューションを可能な限りシンプルに保つ必要がありました。最終的に2、3の候補が出現しました:
Elasticsearch
Elasticsearchは、ドキュメント指向のサービスで全文検索を提供します。大量の負荷を分散して管理するように設計されています。関連性によって結果をランク付けし、集計を実行し、単語の語幹を処理することができます 同義語。このツールは、リアルタイム検索を目的としています。彼らのウェブサイトから:
Elasticsearchは、Apache Luceneの上に分散機能を構築して、利用可能な最も強力な全文検索機能を提供します。強力で開発者に優しいクエリAPIは、多言語検索、ジオロケーション、コンテキストに応じた提案、オートコンプリート、結果スニペットをサポートします。
ElasticsearchはRESTサービスとして機能し、httpリクエストに応答し、非常に迅速にセットアップできます。ただし、エンジンをサービスとして起動するには、サーバーアクセス権限が必要です。また、ホスティングプロバイダーがElasticsearchをすぐにサポートしていない場合は、いくつかのパッケージをインストールする必要があります。
肝心なのは、この製品は堅実な検索ソリューションが必要な場合に最適なオプションであるということです。 (注:ハードウェア要件はかなり厳しいため、VPSまたは専用サーバーが必要になる場合があります。)
スフィンクス
Elasticsearchと同様に、Sphinxも非常に堅実な全文検索製品を提供します。Craigslistは1日あたり300,000,000を超えるクエリを提供します。 SphinxはネイティブのRESTfulインターフェースを提供していません。これはCで実装されており、Elasticsearch(Javaで実装され、jvmを使用する任意のOSで実行できます)よりもハードウェアフットプリントが小さくなっています。 Sphinxを正しく実行するには、専用のRAM/CPUを備えたサーバーへのルートアクセスも必要です。
MySQL全文検索
歴史的に、全文検索はMyISAMエンジンでサポートされていました。バージョン5.6以降、MySQLはInnoDBストレージエンジンでの全文検索もサポートしていました。これは、開発者がInnoDBの参照整合性、トランザクションを実行する機能、および行レベルのロックの恩恵を受けることができるため、すばらしいニュースです。
MySQLの全文検索には、基本的に2つのアプローチがあります。自然言語とブールモードです。 (3番目のオプションは、2番目の拡張クエリで自然言語検索を拡張します。)
自然モードとブールモードの主な違いは、ブールモードでは検索の一部として特定の演算子を使用できることです。たとえば、ブール演算子は、ある単語がクエリ内の他の単語よりも関連性が高い場合や、特定の単語が結果に含まれる必要がある場合などに使用できます。どちらの場合も、結果は次のように計算された関連性で並べ替えることができます。検索中のMySQL。
決定を下す
私たちの問題に最も適したのは、ブールモードでInnoDb全文検索を使用することでした。なんで?
- 検索機能を実装する時間がほとんどありませんでした。
- この時点では、処理するビッグデータも、ElasticsearchやSphinxなどを必要とする大量の負荷もありませんでした。
- ElasticsearchまたはSphinxをサポートしない共有ホスティングを使用しましたが、この段階ではハードウェアがかなり制限されていました。
- 検索関数で単語のステミングが必要でしたが、それは取引を妨げるものではありませんでした。単純なPHPコーディングとデータの非正規化によって(制約内で)実装できました
- ブールモードでの全文検索では、ワイルドカードを使用して単語を検索し(単語の語幹)、関連性に基づいて結果を並べ替えることができます。
ブールモードでの全文検索
前述のように、自然言語検索は最も簡単なアプローチです。フルテキストインデックスを設定した列でフレーズまたは単語を検索するだけで、関連性で並べ替えられた結果が得られます。
正規化されたVertabeloモデルの場合
簡単な検索がどのように機能するか見てみましょう。最初にサンプルテーブルを作成します:
-- Created by Vertabelo (https://vertabelo.com) -- Last modification date: 2016-04-25 15:01:22.153 -- tables -- Table: artists CREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id) ) ENGINE InnoDB; CREATE FULLTEXT INDEX artists_idx_1 ON artists (name); -- End of file.
自然言語モードの場合
いくつかのサンプルデータを挿入して、テストを開始できます。 (サンプルデータセットに追加するとよいでしょう。)たとえば、マイケルジャクソンを検索してみます:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN NATURAL LANGUAGE MODE)
このクエリは、検索語に一致するレコードを検索し、関連性によって一致するレコードを並べ替えます。一致度が高いほど、関連性が高くなり、結果がリストに表示されます。
ブールモードの場合
ブールモードでも同じ検索を実行できます。クエリに演算子を適用しない場合、唯一の違いは、結果がないということです。 関連性でソート:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN BOOLEAN MODE)
ブールモードのワイルドカード演算子
語幹および部分的な単語を検索するため、ワイルドカード演算子(*)が必要になります。この演算子はブールモード検索で使用できるため、このモードを選択しました。
それでは、ブール検索の力を解き放ち、アーティストの名前の一部を検索してみましょう。ワイルドカード演算子を使用して、名前が「Mich」で始まるアーティストを照合します:
SELECT
*
FROM
artists
WHERE
MATCH (name) AGAINST ('Mich*' IN BOOLEAN MODE)
ブールモードでの関連性による並べ替え
次に、計算された検索の関連性を見てみましょう。これは、後でCakeで行う並べ替えを理解するのに役立ちます:
SELECT
*, MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE) AS rank
FROM
artists
WHERE
MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)
ORDER BY rank DESC
このクエリは、MySQLが各レコードに対して計算する検索一致と関連性の値を取得します。エンジンオプティマイザは、関連性を選択していることを検出するため、ランクを再計算する必要はありません。
全文検索での単語ステミング
検索に単語ステミングを組み込むと、検索がよりユーザーフレンドリーになります。結果自体が単語ではない場合でも、アルゴリズムは派生単語に対して同じルートを生成しようとします。たとえば、語幹「argu」は英語の単語ではありませんが、「argue」、「argued」、「argues」、「arguing」、「Argus」などの語幹として使用できます。
ステミングは、ユーザーが完全に一致しない単語を入力する可能性があるが、その「語幹」は一致するため、結果を改善します。 PHPステマーまたはSnowballのPythonステマーがオプションになる可能性がありますが(サーバーへのルートSSHアクセスがある場合)、PorterStemmer.phpクラスを使用します。
このクラスは、MartinPorterが提案した英語の単語の語幹アルゴリズムを実装します。著者が彼のウェブサイトで述べているように、それはあらゆる目的のために無料で使用できます。 CakePHP内のVendorsディレクトリ内にファイルをドロップし、モデルにライブラリを含め、静的メソッドを呼び出して単語をステミングするだけです:
//include the library (should be called PorterStemmer.php) within CakePHP’s Vendors folder
App::import('Vendor', 'PorterStemmer');
//stem a word (words must be stemmed one by one)
echo PorterStemmer::Stem(‘stemming’);
//output will be ‘stem’
私たちの目標は、検索を高速かつ効率的にし、結果を全文の関連性で並べ替えることができるようにすることです。これを行うには、次の2つの方法で単語ステミングを使用する必要があります。
- ユーザーが入力した単語
- 曲関連のデータ(列に保存し、関連性に基づいて結果を並べ替えます)
最初のタイプの単語ステミングは、次のように実行できます。
App::import('Vendor', 'PorterStemmer');
$search = trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));//remove undesired characters
$words = explode(" ", trim($search));
$stemmedSearch = "";
$unstemmedSearch = "";
foreach ($words as $word) {
$stemmedSearch .= PorterStemmer::Stem($word) . "* ";//we add the wildcard after each word
$unstemmedSearch = $word . "* " ;//to search the artist column which is not stemmed
}
$stemmedSearch = trim($stemmedSearch);
$unstemmedSearch = trim($unstemmedSearch);
if ($stemmedSearch == "*" || $unstemmedSearch=="*") {
//otherwise mySql will complain, as you cannot use the wildcard alone
$stemmedSearch = "";
$unstemmedSearch = "";
}
2つの文字列を作成しました。1つはアーティスト名(ステミングなし)を検索するためのもので、もう1つは他のステミングされた列を検索するためのものです。これは、後で「に対して」を構築するのに役立ちます フルテキストクエリの一部。それでは、曲のデータをステム処理して並べ替える方法を見てみましょう。
曲データの非正規化
並べ替えの基準は、最初に曲のアーティストを(ステミングなしで)一致させることに基づいています。次は、曲の名前、アルバム、および関連するカテゴリです。ステミングは、すべての2次検索条件で使用されます。
これを説明するために、「nirvana」を検索し、「XYZ」による「Nirvana Games」という曲と、アーティスト「Nirvana」による「Polly」という別の曲があるとします。曲名の一致よりもアーティスト名の一致の方が重要であるため、結果には最初に「ポリー」が表示されます(私の基準に基づく)。
これを行うために、songs 表、必要な検索/並べ替え基準ごとに1つ:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER`denorm_trackname`, ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
完全なデータベースモデルは次のようになります:
CakePHPでadd/editを使用して曲を保存するときはいつでも、denorm_artist列にアーティスト名を保存する必要があります。 それをステミングせずに。次に、ステム化されたトラック名をdenorm_tracknameに追加します フィールド(検索されたテキストで行ったのと同様)を入力し、ステム処理されたアルバムの名前をdenorm_albumに保存します。 桁。最後に、曲のステム化されたカテゴリセットをdenorm_categoriesに保存します フィールド、単語を連結し、各語幹カテゴリ名の間に1つのスペースを追加します。
CakePHPでの全文検索と関連性の並べ替え
「ニルヴァーナ」を検索する例を続けて、これに似たクエリで何ができるか見てみましょう。
SELECT
trackname,
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank1,
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank2,
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank3,
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank4
FROM songs
WHERE
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE)
ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC
次の出力が得られます:
| トラック名 | ランク1 | ランク2 | ランク3 | ランク4 |
| ポリー | 0.0906190574169159 | 0 | 0 | 0 |
| ニルヴァーナゲーム | 0 | 0.0906190574169159 | 0 | 0 |
CakePHPでこれを行うには、 find メソッドは、「fields」、「conditions」、および「order」パラメータの組み合わせを使用して呼び出す必要があります。以前のPHPサンプルコードを続行します:
//within Song.php model file
$fields = array(
"Song.trackname",
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) as `rank1`",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank2`",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank3`",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank4`"
);
$order = "`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";
$conditions = array(
"OR" => array(
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)"
)
);
$results = $this->find(‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order);
$ results 先に定義した基準で並べ替えられた曲の配列になります。
このソリューションを使用すると、開発者の時間をかけすぎたり、コードを大幅に複雑にしたりすることなく、ユーザーにとって意味のある検索を生成できます。
CakePHP検索をさらに改善する
非正規化された列をより多くのデータで「スパイシング」すると、より良い結果が得られる可能性があることに注意してください。
「スパイシング」とは、非正規化された列に、結果をより関連性の高いものにする目的で役立つと思われる追加の列からのより多くのデータを含めることができることを意味します。たとえば、アーティストの国が検索用語で把握できることがわかっている場合は、 denorm_artistにアーティスト名とともに国を追加できます 桁。これにより、検索結果の品質が向上します。
私の経験から(使用する実際のデータと非正規化する列によって異なります)、最上位の結果は非常に正確になる傾向があります。長いリストを下にスクロールするとユーザーがイライラする可能性があるため、これはモバイルアプリに最適です。
最後に、曲に関連するテーブルからより多くのデータを取得する必要がある場合は、いつでも参加して、アーティスト、カテゴリ、アルバム、曲のコメントなどを取得できます。CakePHPの包含可能な動作フィルターを使用している場合は、結合を効率的に実行するためにEagerLoaderプラグインを追加することをお勧めします。
全文検索を実装する独自のアプローチがある場合は、以下のコメントで共有してください。私たちは皆、お互いの経験から学ぶことができます。