SQLServer2012とSQLServer2014には回帰バグがあり、インデックスをオンラインで並行して再構築し、ロックタイムアウトなどの致命的なエラーが発生すると、データの損失または破損 。これは比較的まれなシナリオであるはずです(Phil BrammerはConnect#795134で単純な再現を行っています)が、データ損失はデータ損失であり、私はギャンブルをする準備ができていません。修正については、KB#2969896で説明されています。修正:SQL Server 2012でオンラインビルドインデックスを実行すると、クラスター化インデックスのデータ損失が発生します。
誰もがこの問題について心配する必要はありません。 Enterprise(または同等の)Editionを実行していない場合、そもそも並列またはオンラインの再構築を実行できません(Enterpriseには、再構築しない、またはオンラインで再構築しない人がいる可能性があります)。インスタンス全体のMAXDOPがある場合 1に設定すると、ステートメントレベルでオーバーライドしない限り、並列化できません。ただし、2012年または2014年に適切なエディションを実行していて、オンラインでの再構築が並行して行われる可能性がある場合は、この問題に対して脆弱です。
上で触れたように、この問題はSQL Server 2012 RTM、Service Pack 1、さらには6月10日にリリースされたService Pack 2でも発生する可能性があります。このバグは、SP2コードが凍結されるまで修正されなかったため、SP2は修正されました。この修正またはSP1CU#10または#11からの修正は含めないでください。私はこれについてここでブログを書きました。 RTMブランチは正式にサポートされていないため、修正は表示されません。この問題はSQLServer2014でも発生する可能性があります。
現在、SQL Server 2012 Service Pack1および2とSQLServer2014で利用可能な累積的な更新プログラムがあります。推奨するオプションの概要:
ブランチ/@@VERSIONが…の場合
| …あなたは… | ||||
|---|---|---|---|---|---|
| | |
| |||
| | |
| |||
| | 何もしません。すでに修正があります。 | ||||
| | |
| |||
| 何もしません。すでに修正があります。 | |||||
| SQL Server 2014 RTM | |
| |||
| 何もしません。すでに修正があります。 | |||||
| * SP1ホットフィックスまたは累積アップデート#11をインストールしてからSP2をインストールすると、次のような変更を元に戻すことができます。この修正。 | |||||
ホットフィックス/CU嫌いの解決策
影響を受けるすべてのブランチ(2012 RTMを除く)には、オンデマンドの修正プログラムや問題に対処する累積的な更新プログラムがあるため、簡単な答えは、関連する更新プログラムをインストールすることです。ただし、会社のポリシーまたはテストサイクルにより、これらの更新を迅速に、または場合によっては展開できないシナリオが発生している可能性があります。では、他にどのようなオプションがありますか?
- ブランチで利用できる新しいサービスパックができるまで、再構築の実行を停止できます(おそらく、
REORGANIZEを使い続けることができます。 今のところ)。残念ながら、「サービスパックのみ」の会社にいる場合、選択肢は非常に限られています。そのポリシーを変更するために一生懸命戦うか、SQL Server 2012 Service Pack 3を待つことができます(これには時間がかかる場合があります。決して来ないでください–ここのFAQ#21を参照してください)またはSQL Server 2014 Service Pack 1(2015年がロールアラウンドする前におそらく表示されないでしょう)。 - インスタンス全体の
max degree of parallelismを設定できます ただし、これは残りのワークロードに悪影響を与える可能性があります。マルチスレッドDBCC、パーティションテーブルに対する、またはパーティションテーブル間の並列クエリ、並列処理を減らしたいが完全には排除したくないその他の操作について考えてみてください。また、この設定は、たとえば明示的なMAXDOP = 8を使用したオンライン再構築には影響しません。sp_configureを上書きするため、コマンドにハードコードされています 設定。
-
WITH (MAXDOP = 1)を追加できます すべての再構築コマンドに手動でオプションを追加します。 (注:XMLインデックスは本質的にシングルスレッドで実行されるため、これを行う必要はありませんが、一貫性を保ち、不要な条件付きロジックを回避するために、すべての再構築に適用します。)
- インデックスメンテナンスジョブを特定のログインとして実行するように設定してから、リソースガバナーを使用して、そのログインの
MAX_DOPを制限するワークロードグループを作成できます。 彼らが何をしているかに関係なく、1に。この例は、BorisBaryshnikovと一緒に書いた2008年のホワイトペーパー「リソースガバナーの使用」の「集中的なバックグラウンドジョブの並列処理の制限」というタイトルのセクションにあります。
- Ola Hallengrenのインデックスメンテナンスソリューションを使用している場合は、
@MaxDopを追加できます。dbo.IndexOptimizeへの呼び出しのパラメータ :
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - SQL Sentry Fragmentation Managerを使用している場合は、
MAXDOPのレベルを指定できます。 [設定]で使用するには–これは、企業全体、インスタンスごと、データベースごと、または個々のインデックスごとに行うことができます(この場合、修正が利用できないすべてのインスタンスに対して、インスタンスごとにこれを設定することをお勧めします)。
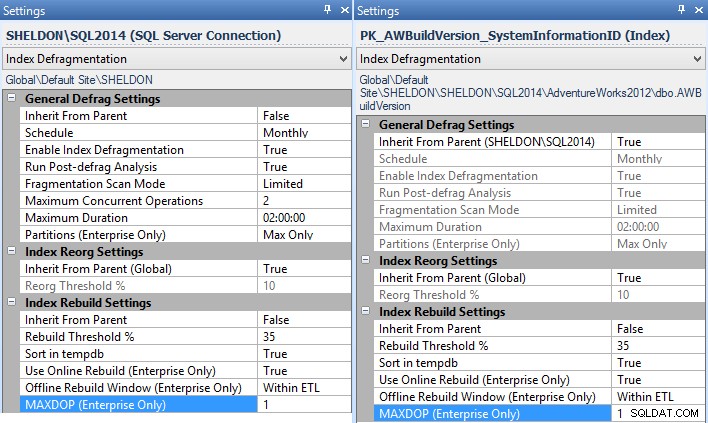
インスタンス(左)と個々のインデックスのフラグメンテーションマネージャーの設定(右) - インデックスの再構築にメンテナンスプランを使用している場合は、T-SQLステートメントタスクの実行を使用するようにメンテナンスプランを変更し、
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);手動でコマンドを実行します(自動化されたソリューションに切り替えることもできます)。インデックス再構築タスクには、MAXDOPの公開プロパティがありません。 、何度もリクエストされていますが(最近では、2012年にAlberto Morilloから、2006年まではLinchi Sheaから)。そして、AdvSortInTempdbのように、それらが公開する他のすべての便利なプロパティを見てください。 、ObjectTypeSelection、およびTaskAllowesDatbaseSelection[原文のまま!]:
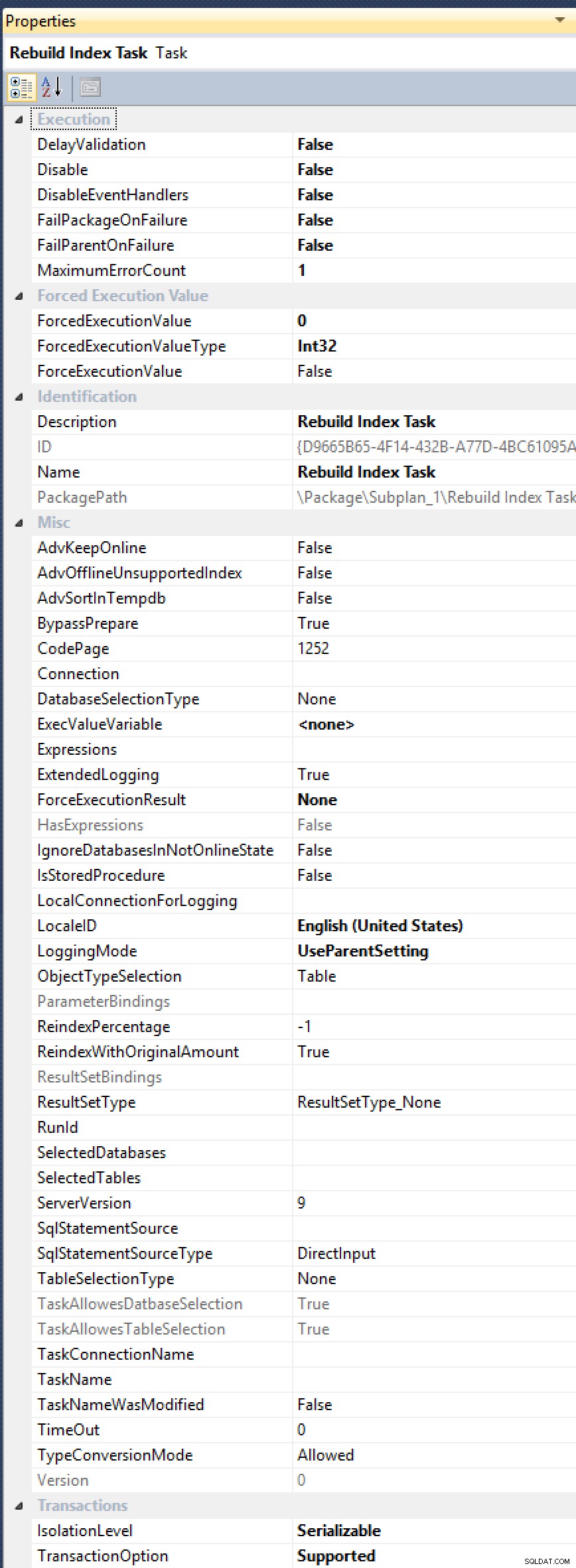
これらすべてのオプションですが、MAXDOPの治療法はありません。