遅延耐久性は、SQL Server 2014の最新の機能ですが、興味深い機能です。この機能の高レベルのエレベーターピッチは、非常に単純です。
- "耐久性とパフォーマンスのトレードオフ。"
最初にいくつかの背景。既定では、SQL Serverは先行書き込みログ(WAL)を使用します。これは、変更がコミットされる前にログに書き込まれることを意味します。トランザクションログの書き込みがボトルネックになり、データ損失に対する中程度の許容度があるシステム 、ログのフラッシュと確認応答を待機する要件を一時的に一時停止するオプションがあります。これは、少なくともデータのごく一部については、文字通りACIDからDを取り除くために発生します(これについては後で詳しく説明します)。
あなたはすでにこの犠牲を払っています。フルリカバリモードでは、データが失われるリスクが常にあります。サイズではなく時間で測定されます。たとえば、トランザクションログを5分ごとにバックアップする場合、何か壊滅的な事態が発生した場合、最大5分弱のデータが失われる可能性があります。ここでは単純なフェイルオーバーについて話しているのではありませんが、サーバーが文字通り発火したり、誰かが電源コードをつまずいたりするとします。データベースは回復不能であり、最後のログバックアップの時点に戻らなければならない場合があります。 。そして、それは、バックアップをどこかに復元してテストしていることを前提としています。重大な障害が発生した場合、自分が持っていると思うリカバリポイントがない可能性があります。もちろん、悪いこと™を期待することは決してないので、このシナリオについては考えない傾向があります。 起こる。
仕組み
耐久性の遅延により、ログがディスクにフラッシュされたかのように書き込みトランザクションを実行し続けることができます。実際には、ディスクへの書き込みはグループ化されて延期され、バックグラウンドで処理されます。トランザクションは楽観的です。ログフラッシュが実行されることを前提としています 起こる。システムはログバッファの60KBチャンクを使用し、この60KBブロックがいっぱいになると、ログをディスクにフラッシュしようとします(遅くとも、その前に発生する可能性があります)。このオプションは、データベースレベル、個々のトランザクションレベル、または–インメモリOLTPでネイティブにコンパイルされたプロシージャの場合–プロシージャレベルで設定できます。競合が発生した場合は、データベース設定が優先されます。たとえば、データベースが無効に設定されている場合、delayedオプションを使用してトランザクションをコミットしようとすると、エラーメッセージは表示されず、単に無視されます。また、一部のトランザクションは、データベース設定やコミット設定に関係なく、常に完全に永続的です。たとえば、システムトランザクション、データベース間トランザクション、FileTable、変更の追跡、変更データのキャプチャ、レプリケーションに関連する操作などです。
データベースレベルでは、次を使用できます。
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
ALLOWEDに設定した場合 、これは、個々のトランザクションで遅延耐久性を使用できることを意味します。 FORCED 遅延耐久性を使用できるすべてのトランザクションが使用されることを意味します(上記の例外はこの場合でも関連します)。 ALLOWEDを使用することをお勧めします FORCEDではなく –ただし、後者は、このオプションを全体で使用し、タッチする必要のあるコードの量を最小限に抑えたい既存のアプリケーションの場合に役立ちます。 ALLOWEDについて注意すべき重要なこと 完全に耐久性のあるトランザクションは、遅延した耐久性のあるトランザクションを最初に強制的にフラッシュするため、より長く待機する必要がある場合があります。
トランザクションレベルでは、次のように言うことができます:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
また、インメモリOLTPのネイティブにコンパイルされたプロシージャでは、次のオプションをBEGIN ATOMICに追加できます。 ブロック:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
よくある質問は、ロックと分離のセマンティクスで何が起こるかについてです。本当に何も変わりません。ロックとブロックは引き続き発生し、トランザクションは同じ方法で同じルールでコミットされます。唯一の違いは、ログがディスクにフラッシュされるのを待たずにコミットを実行できるようにすることで、関連するロックがはるかに早く解放されることです。
いつ使用するか
ログの書き込みが発生するのを待たずにトランザクションを続行できるという利点に加えて、サイズの大きいログへの書き込みも少なくなります。これは、システムに実際に60KB未満のトランザクションの割合が高い場合、特にログディスクが遅い場合に非常にうまく機能します(SSDと従来のHDDで同様の利点が見つかりました)。トランザクションの大部分が60KBを超える場合、通常は長時間実行される場合、またはスループットと同時実行性が高い場合は、うまく機能しません。ここで発生する可能性があるのは、フラッシュが終了する前にログバッファー全体をいっぱいにすることができるということです。これは、待機を別のリソースに転送することを意味し、最終的には、アプリケーションのユーザーが認識するパフォーマンスを向上させることはありません。
つまり、トランザクションログが現在ボトルネックになっていない場合は、この機能をオンにしないでください。トランザクションログが現在ボトルネックであるかどうかをどのように判断できますか?最初のインジケーターは高いWRITELOGになります 特にPAGEIOLATCH_**と組み合わせた場合は待機します 。 Paul Randal(@PaulRandal)には、トランザクションログの問題の特定と、最適なパフォーマンスのための構成に関する4部構成の優れたシリーズがあります。
- トランザクションログファットのトリミング
- トランザクションログのファットをさらにトリミングする
- トランザクションログ構成の問題
- トランザクションログの監視
Kimberly Tripp(@KimberlyLTripp)のこのブログ投稿、トランザクションログスループットを向上させるための8つのステップ、およびSQLCATチームのブログ投稿「トランザクションログのパフォーマンスの問題とログマネージャーの制限の診断」も参照してください。
この調査により、DelayedDurabilityは調査する価値があるという結論に至る可能性があります。そうではないかもしれません。ワークロードをテストすることは、確実に知るための最も信頼できる方法です。 SQL Serverの最近のバージョンでの他の多くの追加と同様に( * cough * Hekaton )、この機能はすべてのワークロードを改善するようには設計されていません。上記のように、実際には一部のワークロードを悪化させる可能性があります。パフォーマンスを向上させるために耐久性をいくらか犠牲にすることが可能かどうかを判断するために、ワークロードについて自問する必要があるその他の質問については、SimonHarveyによるこのブログ投稿を参照してください。
データ損失の可能性
これについては何度か言及し、毎回強調します。データの損失に耐える必要があります 。パフォーマンスの高いディスクでは、大災害で失うと予想される最大値、または計画的で適切なシャットダウンでさえ、最大1ブロック(60KB)です。ただし、I / Oサブシステムが追いつかない場合は、ログバッファ全体(約7MB)を失う可能性があります。
明確にするために、ドキュメントから(私の強調):
耐久性を遅らせるために、予期しないシャットダウンとSQLServerの予期されるシャットダウン/再起動の間に違いはありません 。壊滅的なイベントと同様に、データ損失を計画する必要があります 。計画されたシャットダウン/再起動では、ディスクに書き込まれていない一部のトランザクションが最初にディスクに保存される場合がありますが、計画しないでください。計画的であろうと計画外であろうと、シャットダウン/再起動が壊滅的なイベントと同じようにデータを失うかのように計画します。したがって、データ損失のリスクと、トランザクションログのパフォーマンスの問題を軽減する必要性を比較検討することが非常に重要です。銀行やお金を扱う何かを経営している場合、この機能を使用してサイコロを振るよりも、ログをより高速なディスクに移動する方がはるかに安全で適切な場合があります。 Web Gamerzチャットルームアプリケーションの応答時間を改善しようとしている場合は、リスクはそれほど深刻ではない可能性があります。
データ損失のリスクを最小限に抑えるために、この動作をある程度制御できます。次の2つの方法のいずれかで、遅延した永続トランザクションをすべて強制的にディスクにフラッシュできます。
- 完全に永続的なトランザクションをコミットします。
-
sys.sp_flush_logを呼び出します 手動で。
これにより、サイズではなく時間の観点からデータ損失の制御に戻ることができます。たとえば、5秒ごとにフラッシュをスケジュールできます。しかし、ここでスイートスポットを見つけたいと思うでしょう。フラッシュを頻繁に行うと、そもそも遅延耐久性のメリットが相殺される可能性があります。いずれの場合も、データの損失に耐える必要があります 、たとえそれが
CHECKPOINT ここで役立つかもしれませんが、この操作は実際にはログがディスクにフラッシュされることを技術的に保証するものではありません。
HA/DRとの相互作用
遅延耐久性が、ログ配布、レプリケーション、可用性グループなどのHA/DR機能でどのように機能するのか疑問に思われるかもしれません。これらのほとんどで、それは変わらずに動作します。ログの配布とレプリケーションでは、強化されたログレコードが再生されるため、データが失われる可能性も同じです。 AGが非同期モードの場合、とにかく2次確認応答を待機していないため、今日と同じように動作します。ただし、同期では、トランザクションがコミットされてリモートログに固定されるまで、プライマリでコミットすることはできません。そのシナリオでも、ローカルログが書き込まれるのを待つ必要がないため、ローカルでいくつかの利点がありますが、それでもリモートアクティビティを待つ必要があります。したがって、そのシナリオでは、メリットは少なく、潜在的にはありません。おそらく、プライマリのログディスクが本当に遅く、セカンダリのログディスクが本当に速いというまれなシナリオを除いて。同期/非同期ミラーリングにも同じ条件が当てはまると思いますが、非推奨の新機能で光沢のある新機能がどのように機能するかについて、私から公式のコミットメントは得られません。 :-)
パフォーマンスの観察
実際のパフォーマンスの観察結果を示さなければ、これはここではあまり投稿されません。次の属性を持つ2つの異なるワークロードパターンの影響をテストするために、8つのデータベースを設定しました。
- リカバリーモデル:シンプルvs.フル
- ログの場所:SSDとHDD
- 耐久性:遅延vs.完全耐久性
私は本当に、本当に、本当に怠惰な この種のことについて効率的です。各データベース内で同じ操作を繰り返さないようにしたいので、modelで一時的に次のテーブルを作成しました :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
次に、データベースを個別に作成してから設定をいじくり回すのではなく、動的SQLコマンドのセットを作成してこれらの8つのデータベースを構築しました。
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
このコードを自分で自由に実行してください(EXECを使用) まだコメントアウトされています)これにより、遅延耐久性がオフの4つのデータベースが作成されることを確認します(完全リカバリで2つ、SIMPLEで2つ、低速ディスクにログオンするデータベースが1つ、SSDにログオンするデータベースが1つ)。 Delayed Durability FORCEDを使用して4つのデータベースに対してこのパターンを繰り返します。これは、実際に行うことを反映するのではなく、テストのコードを単純化するために行いました(一部のトランザクションをクリティカルとして扱い、一部のトランザクションを次のように扱いたい場合)。まあ、重要ではありません)。
健全性チェックのために、次のクエリを実行して、データベースに属性の正しいマトリックスがあることを確認しました。
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
結果:
| name | restorey_model | delayd_durability | log_disk |
|---|---|---|---|
| dd1 | フル | 強制 | SSD |
| dd2 | シンプル | 強制 | SSD |
| dd3 | フル | 強制 | HDD |
| dd4 | シンプル | 強制 | HDD |
| dd5 | フル | 無効 | SSD |
| dd6 | シンプル | 無効 | SSD |
| dd7 | フル | 無効 | HDD |
| dd8 | シンプル | 無効 | HDD |
8つのテストデータベースの関連する構成
また、テストを複数回クリーンに実行して、1GBのデータファイルと1GBのログファイルが、方程式に自動拡張イベントを導入せずにワークロードのセット全体を実行するのに十分であることを確認しました。ベストプラクティスとして、予期しないときに成長イベントが発生しないように、顧客のシステムに十分なスペースが割り当てられていること(および適切なアラートが組み込まれていること)を定期的に確認しています。現実の世界では、これが常に発生するとは限りませんが、理想的です。
SQL Sentryで監視するようにシステムを設定しました。これにより、強調したいパフォーマンスメトリックのほとんどを簡単に表示できるようになります。ただし、期間やsys.dm_io_virtual_file_statsからの非常に具体的な出力を含むバッチメトリックを格納するための一時テーブルも作成しました:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; これにより、個々のバッチの開始時刻と終了時刻を記録し、開始時刻と終了時刻の間のDMVのデルタを測定できます(この場合、システム上の唯一のユーザーであることがわかっているため、信頼できる場合のみです)。
たくさんの小さな取引
私が実行したかった最初のテストは、たくさんの小さなトランザクションでした。データベースごとに、それぞれ1つのインサートの500,000の個別のバッチを作成したかったのです。
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
覚えておいてください、私は怠惰なになろうとしています この種のことについて効率的です。したがって、8つのデータベースすべてのコードを生成するために、これを実行しました:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
このテストを実行してから、#Metricsを確認しました 次のクエリを含むテーブル:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; これにより、次の結果が得られました(そして、複数のテストを通じて、結果が一貫していることを確認しました):
| データベース | 書き込み | バイト | バイト/書き込み | io_stall_ms | start_time | end_time | 期間(秒) |
|---|---|---|---|---|---|---|---|
| dd1 | 8,068 | 261,894,656 | 32,460.91 | 6,232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8,072 | 261,682,688 | 32,418.56 | 2,740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8,246 | 262,254,592 | 31,803.85 | 3,996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8,055 | 261,688,320 | 32,487.68 | 4,231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500,012 | 526,448,640 | 1,052.87 | 35,593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500,014 | 525,870,080 | 1,051.71 | 35,435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500,015 | 526,120,448 | 1,052.20 | 50,857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500,017 | 525,886,976 | 1,051.73 | 49,680 | | | 133 |
小さなトランザクション:sys.dm_io_virtual_file_statsからの期間と結果
ここで間違いなくいくつかの興味深い観察:
- Delayed Durabilityデータベースの場合、個々の書き込み操作の数は非常に少なかった(従来の場合は約60倍)。
- 遅延耐久性を使用して、書き込まれた合計バイト数が半分に削減されました(従来の場合のすべての書き込みには多くの無駄なスペースが含まれていたためだと思います)。
- 遅延耐久性の場合、書き込みあたりのバイト数ははるかに多かった。この機能の全体的な目的は、書き込みをより大きなバッチにまとめることであるため、これはそれほど驚くべきことではありませんでした。
- I / Oストールの合計時間は変動しましたが、遅延耐久性の場合はおよそ1桁低くなりました。完全に耐久性のあるトランザクションでのストールは、ディスクのタイプにはるかに敏感でした。
- これまでのところ納得がいかない場合は、期間の列が非常にわかりやすくなっています。 2分以上かかる完全に耐久性のあるバッチは、ほぼ半分にカットされます。
開始/終了時間の列により、これらのトランザクションが発生した正確な期間のPerformance Advisorダッシュボードに焦点を当てることができました。ここで、多くの追加の視覚的インジケーターを描画できます。
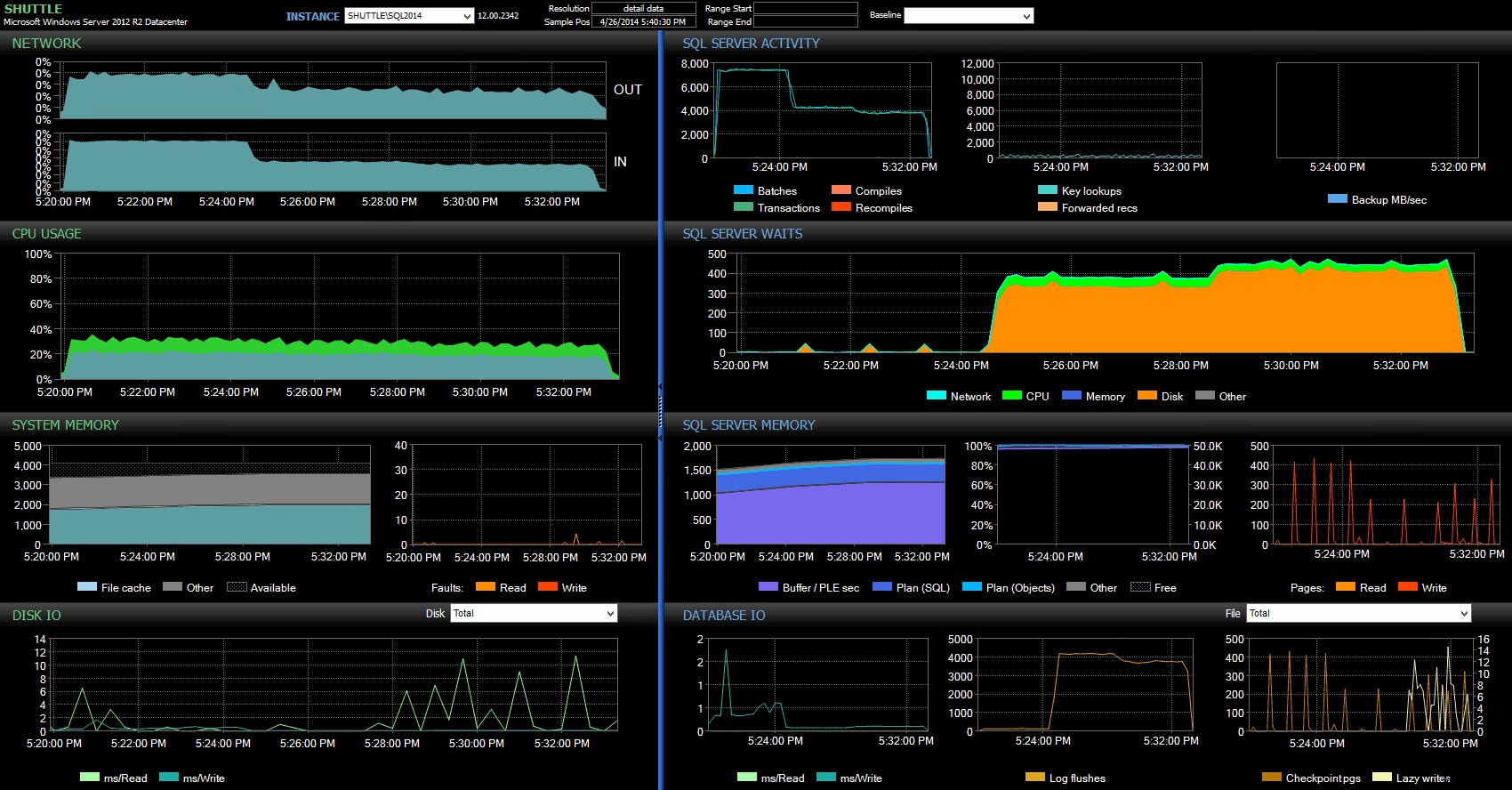
SQL Sentryダッシュボード–クリックして拡大
ここでのさらなる観察:
- いくつかのグラフで、バッチの非遅延耐久性部分がいつ引き継がれたかを正確に確認できます(〜5:24:32 PM)。
- Delayed Durabilityを使用しても、CPUやメモリに目に見える影響はありません。
- SQL Serverアクティビティの下の最初のグラフで、1秒あたりのバッチ/トランザクションに多大な影響を与えることがわかります。
- SQL Serverは、完全に耐久性のあるトランザクションが開始されると、屋根を通り抜けるのを待ちます。これらはほとんど
WRITELOGで構成されていました 少数のPAGEIOLOATCH_EXで待機します およびPAGEIOLATCH_UP適切な測定を待ちます。 - Delayed Durability操作全体でのログフラッシュの総数は非常に少なかった(100秒/秒と低い)が、これは従来の動作では4,000 /秒を超えました(テストのHDD期間ではわずかに少なくなりました)。
より少ない、より大きなトランザクション
次のテストでは、実行する操作を減らした場合にどうなるかを確認したかったのですが、各ステートメントが大量のデータに影響を与えることを確認しました。このバッチを各データベースに対して実行したかった:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); そこで、再び怠惰な方法を使用して、データベースごとに1つずつ、このスクリプトの8つのコピーを作成しました。
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
このバッチを実行してから、#Metricsに対してクエリを変更しました 上記では、最初のテストではなく2番目のテストを確認します。結果:
| データベース | 書き込み | バイト | バイト/書き込み | io_stall_ms | start_time | end_time | 期間(秒) |
|---|---|---|---|---|---|---|---|
| dd1 | 20,970 | 1,271,911,936 | 60,653.88 | 12,577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20,997 | 1,272,145,408 | 60,587.00 | 14,698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20,973 | 1,272,982,016 | 60,696.22 | 12,085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20,958 | 1,272,064,512 | 60,695.89 | 11,795 | | | 143 |
| dd5 | 30,138 | 1,282,231,808 | 42,545.35 | 7,402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30,138 | 1,282,260,992 | 42,546.31 | 7,806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30,129 | 1,281,575,424 | 42,536.27 | 9,888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30,130 | 1,281,449,472 | 42,530.68 | 11,452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
より大きなトランザクション:sys.dm_io_virtual_file_statsからの期間と結果
今回は、DelayedDurabilityの影響はそれほど目立ちません。書き込み操作の数はわずかに少なく、書き込みあたりのバイト数はわずかに多く、合計バイト数はほぼ同じです。この場合、実際には、遅延耐久性のI / Oストールが高くなっています。これは、期間もほぼ同じであるという事実を説明している可能性があります。
Performance Advisorダッシュボードから、前のテストとのいくつかの類似点と、いくつかの大きな違いもあります:
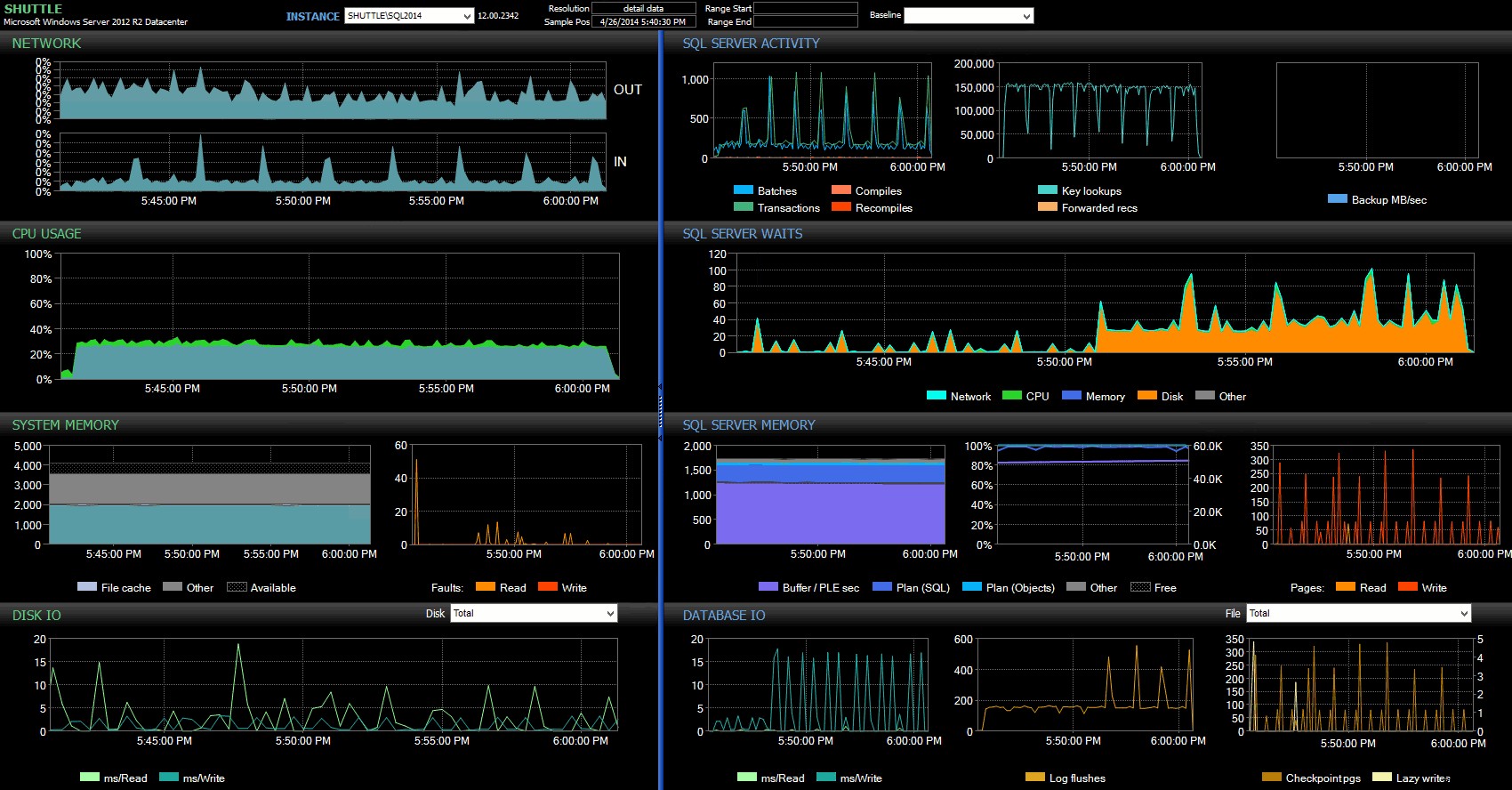
SQL Sentryダッシュボード–クリックして拡大
ここで指摘する大きな違いの1つは、待機統計のデルタが前のテストほど顕著ではないことです。それでも、WRITELOGの頻度ははるかに高くなります。 完全に耐久性のあるバッチを待ちますが、小規模なトランザクションで見られるレベルにはほど遠いです。すぐにわかるもう1つの点は、以前に観察された1秒あたりのバッチとトランザクションへの影響がなくなったことです。そして最後に、完全に耐久性のあるトランザクションでは、遅延した場合よりも多くのログフラッシュがありますが、この不一致は、小さなトランザクションよりもはるかに顕著ではありません。
結論
遅延耐久性の恩恵を受ける可能性のある特定のワークロードタイプがあることは明らかです。もちろん、データ損失に対する許容度がある場合 。この機能はインメモリOLTPに限定されず、SQL Server 2014のすべてのエディションで使用でき、コードをほとんどまたはまったく変更せずに実装できます。あなたのワークロードがそれをサポートできれば、それは確かに強力なテクニックになるでしょう。ただし、繰り返しになりますが、ワークロードをテストして、この機能のメリットがあることを確認し、これによってデータ損失のリスクが高まるかどうかを強く検討する必要があります。
余談ですが、これはSQL Serverの群衆には新鮮な新しいアイデアのように見えるかもしれませんが、実際には、Oracleはこれを2006年に「非同期コミット」として導入しました(COMMIT WRITE ... NOWAITを参照)。 ここに文書化され、2007年にブログに掲載されています)。そして、アイデア自体は30年近く前から存在しています。ハル・ベレンソンの歴史の簡単な記録を参照してください。
次回
私が考えたアイデアの1つは、tempdbのパフォーマンスを改善することです。 そこで遅延耐久性を強制することによって。 tempdbの1つの特別なプロパティ そのような魅力的な候補となるのは、それが本質的に一時的なものであるということです– tempdb内のすべて は、さまざまなシステムイベントが発生した後にトスできるように明示的に設計されています。私は今、これがうまくいくワークロードの形があるかどうかわからないままこれを言っています。しかし、私はそれを試してみるつもりです、そして私が何か面白いものを見つけたら、あなたは私がそれについてここに投稿することを確信することができます。