SQL Server 2008では、null値のストレージを削減し、より拡張可能なスキーマを提供する方法として、スパース列が導入されました。トレードオフは、NULL以外の値を格納および取得するときに、追加のオーバーヘッドが発生することです。ステージング環境でこのデータ型を使用している顧客と話をした後、NULL以外の値を格納するためのコストを理解することに興味がありました。彼らは書き込みパフォーマンスを最適化しようとしています。彼らの方法ではテーブルに行を挿入してから更新する必要があるため、スパース列の使用が効果があるかどうか疑問に思いました。このデモの不自然な例を作成しました。これについては、以下で説明します。これが、彼らが使用するのに適した方法であるかどうかを判断します。
内部レビュー
簡単なレビューとして、NULL値を許可するテーブルの列を作成する場合、それが固定長の列(INTなど)である場合、列がヌル。可変長の列(例:VARCHAR)の場合、列が最後に入力された列の後にない限り、NULLの場合は列オフセット配列で少なくとも2バイトを消費します(Kimberlyのブログ投稿を参照してください列の順序は重要ではありません...一般的に、しかし–それは依存します)。スパース列は、固定長列であろうと可変長列であろうと、テーブルに入力されている他の列に関係なく、NULL値のためにページ上にスペースを必要としません。トレードオフは、スパース列にデータが入力されると、非スパース列よりも4バイト多くのストレージが必要になることです。例:
| 列タイプ | ストレージ要件 |
|---|---|
| BIGINT列、非スパース、なし 値 | 8バイト |
| BIGINT列、非スパース、 with 値 | 8バイト |
| BIGINT列、スパース、なし 値 | 0バイト |
| BIGINT列、スパース、 with 値 | 12バイト |
したがって、ストレージのメリットが、データに対する読み取りと書き込みのバランスに基づいて無視できる可能性のある、取得による潜在的なパフォーマンスの低下を上回ることを確認することが重要です。さまざまなデータタイプの推定スペース節約量は、上記のBooksOnlineリンクに記載されています。
テストシナリオ
以下に説明するように、テスト用に4つの異なるシナリオを設定しました。すべてのテーブルには、ID列(INT)、名前列(VARCHAR(100))、タイプ列(INT)、そして997個のNULL可能列がありました。
>| テストID | テーブルの説明 | DML操作 |
|---|---|---|
| 1 | INTデータ型の997列、NULL可能、非スパース | 一度に1行ずつ挿入し、ID、名前、タイプ、および10個のランダムなNULL可能列を入力します |
| 2 | INTデータ型の997列、NULLABLE、スパース | 一度に1行ずつ挿入し、ID、名前、タイプ、および10個のランダムなNULL可能列を入力します |
| 3 | INTデータ型の997列、NULL可能、非スパース | 一度に1行ずつ挿入し、ID、名前、タイプのみを入力してから、行を更新し、10個のランダムなNULL可能列の値を追加します |
| 4 | INTデータ型の997列、NULLABLE、スパース | 一度に1行ずつ挿入し、ID、名前、タイプのみを入力してから、行を更新し、10個のランダムなNULL可能列の値を追加します |
| 5 | VARCHARデータ型の997列、NULLABLE、非スパース | 一度に1行ずつ挿入し、ID、名前、タイプ、および10個のランダムなNULL可能列を入力します |
| 6 | VARCHARデータ型の997列、NULLABLE、スパース | 一度に1行ずつ挿入し、ID、名前、タイプ、および10個のランダムなNULL可能列を入力します |
| 7 | VARCHARデータ型の997列、NULLABLE、非スパース | 一度に1行ずつ挿入し、ID、名前、タイプのみを入力してから、行を更新し、10個のランダムなNULL可能列の値を追加します |
| 8 | VARCHARデータ型の997列、NULLABLE、スパース | 一度に1行ずつ挿入し、ID、名前、タイプのみを入力してから、行を更新し、10個のランダムなNULL可能列の値を追加します |
各テストは、1,000万行のデータセットを使用して2回実行されました。添付のスクリプトを使用してテストを複製できます。各テストの手順は次のとおりです。
- 事前にサイズ設定されたデータとログファイルを使用して新しいデータベースを作成します
- 適切なテーブルを作成する
- スナップショット待機統計とファイル統計
- 開始時刻に注意してください
- 1000万行のDML(1回の挿入または1回の挿入と1回の更新)を実行します
- 停止時間に注意してください
- スナップショット待機統計とファイル統計、および別のストレージ上の別のデータベースのログテーブルへの書き込み
- スナップショットdm_db_index_physical_stats
- データベースを削除します
テストは、64GBのメモリと12GBがSQLServer 2014SP1CU4インスタンスに割り当てられたDellPowerEdgeR720で行われました。 Fusion-IO SSDは、データベースファイルのデータストレージに使用されました。
結果
各テストシナリオのテスト結果を以下に示します。
期間
いずれの場合も、行が最初に挿入されてから更新された場合でも、スパース列が使用された場合、テーブルへの入力にかかる時間は短くなりました(平均11.6分)。行が最初に挿入されてから更新されたとき、実行されたデータ変更の数が2倍であったため、テストの実行には行が挿入されたときのほぼ2倍の時間がかかりました。
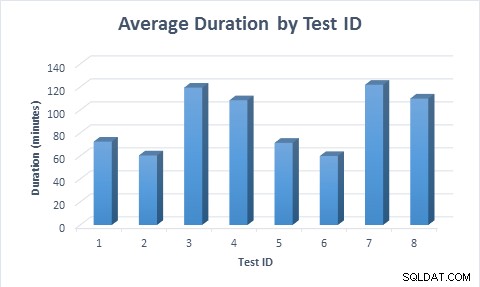
待機統計
| 平均パーセンテージ | 平均待機時間(秒) | |
|---|---|---|
| 1 | 16.47 | 0.0001 |
| 2 | 14.00 | 0.0001 |
| 3 | 16.65 | 0.0001 |
| 4 | 15.07 | 0.0001 |
| 5 | 12.80 | 0.0001 |
| 6 | 13.99 | 0.0001 |
| 7 | 14.85 | 0.0001 |
| 8 | 15.02 | 0.0001 |
待機統計はすべてのテストで一貫しており、このデータに基づいて結論を出すことはできません。ハードウェアは、すべてのテストケースでリソースの需要を十分に満たしていました。
ファイル統計
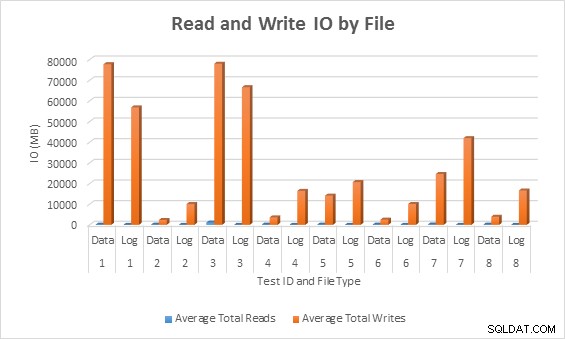
すべての場合において、スパース列を使用したテストでは、非スパース列と比較して、生成されるIO(特に書き込み)が少なくなりました。
インデックスの物理的統計
| テストケース | 行数 | 合計ページ数(クラスター化インデックス) | 合計容量(GB) | CIのリーフページに使用される平均スペース(%) | 平均レコードサイズ(バイト) |
|---|---|---|---|---|---|
| 1 | 10,000,000 | 10,037,312 | 76 | 51.70 | 4,184.49 |
| 2 | 10,000,000 | 301,429 | 2 | 98.51 | 237.50 |
| 3 | 10,000,000 | 10,037,312 | 76 | 51.70 | 4,184.50 |
| 4 | 10,000,000 | 460,960 | 3 | 64.41 | 237.50 |
| 5 | 10,000,000 | 1,823,083 | 13 | 90.31 | 1,326.08 |
| 6 | 10,000,000 | 324,162 | 2 | 98.40 | 255.28 |
| 7 | 10,000,000 | 3,161,224 | 24 | 52.09 | 1,326.39 |
| 8 | 10,000,000 | 503,592 | 3 | 63.33 | 255.28 |
非スパーステーブルとスパーステーブルの間のスペース使用には大きな違いがあります。これは、固定長データ型が使用されたテストケース1および3(INT)を見ると、可変長データ型が使用されたテストケース5および7(VARCHAR(255))と比較して最も顕著です。整数列は、NULLの場合でもディスク領域を消費します。 NULL列のオフセット配列で使用されるのは2バイトのみであり、行の最後に入力された列の後にあるNULL列にはバイトが使用されないため、可変長列はより少ないディスクスペースを消費します。
さらに、行を挿入してから更新するプロセスでは、単純に行を挿入する場合(ケース5)と比較して、可変長列テスト(ケース7)の断片化が発生します。行の更新時にページ分割が発生し、ページが半分いっぱいになるため(90%いっぱいになるのに対して)、挿入後に更新が続くと、テーブルサイズはほぼ2倍になります。
概要
結論として、スパース列を使用するとディスクスペースとIOが大幅に削減され、単純なデータ変更テストでは非スパース列よりもパフォーマンスがわずかに向上します(取得パフォーマンスも考慮する必要があることに注意してください。おそらく別の問題の対象です)。投稿)。
スパース列には非常に特殊な使用シナリオがあり、列のデータ型とテーブルに通常入力される列の数に基づいて、節約されたディスク容量を調べることが重要です。この例では、997個のスパース列があり、そのうち10個だけを設定しました。使用されるデータ型が整数の場合、クラスター化インデックスのリーフレベルの行は、最大で188バイト(IDの場合は4バイト、名前の場合は最大100バイト、タイプの場合は4バイト)を消費します。 10列で80バイト)。 997列がスパースでない場合、NULLの場合でも、すべての列に4バイトが割り当てられたため、各行はリーフレベルで少なくとも4,000バイトでした。このシナリオでは、スパース列は絶対に受け入れられます。ただし、500以上のスパース列にINT列の値を入力すると、スペースの節約が失われ、変更のパフォーマンスが向上しなくなる可能性があります。
列のデータ型、および合計で入力される列の予想数に応じて、同様のテストを実行して、スパース列を使用する場合に、挿入のパフォーマンスとストレージが非-まばらな列。すべての列が入力されていない場合は、まばらな列を検討する価値があります。